物种特异性蛋白质翻译后修饰位点预测方法及系统与流程
1.本发明涉及涉及蛋白质翻译后修饰位点预测算法,属于生物信息学领域,具体涉及物种特异性蛋白质翻译后修饰位点预测方法及系统。
背景技术:
2.蛋白质翻译后修饰是当前蛋白质组学研究的重要领域之一,其对蛋白质的结构和功能具有十分重要的影响。到目前为止,已经鉴定出超过四百种不同类型的翻译后修饰,其中最为常见的修饰类型有磷酸化、泛素化和乙酰化等。翻译后修饰是增加蛋白质多样性的关键机制,在细胞分化和发育、新陈代谢、信号传导、肌肉收缩和基因表达等多个过程中都发挥着重要作用。早期蛋白质翻译后修饰位点的鉴定方法主要依靠低通量实验,但是受限于实验环境以及繁杂的实验过程,该方法仍然低效、昂贵且耗时。因此,基于计算的蛋白质翻译后修饰位点预测方法逐渐收到关注。
3.尽管目前已有多种蛋白质翻译后修饰位点预测方法,例如,wang等人(wang d,zeng s,xu c,et al.musitedeep:a deep-learning framework for general and kinase-specific phosphorylation site prediction[j].bioinformatics,2017,33(24):3909-16)基于多层卷积神经网络构建了磷酸化位点预测器。chen等人(chen z,liu x,li f,et al.large-scale comparative assessment of computational predictors forlysine post-translational modification sites[j].briefings in bioinformatics,2019,20(6):2267-90)基于双向长短期记忆神经网络设计了面向赖氨酸的多种翻译后修饰位点预测工具muscadel。但当这些方法仍然存在如下缺陷:现有研究大多基于深度学习算法开发通用翻译后修饰位点预测模型,忽略了不同物种翻译后修饰数据的分布差异,导致模型难以在不同物种上取得较好的预测结果。此外,目前除了人类、小家鼠等几种较为常见的物种外,大多数物种的翻译后修饰位点数据较少,而现有预测方法中采用的模型微调策略易出现过拟合问题,给物种特异性翻译后修饰位点预测研究带来了挑战。因次,需要发展更为有效的领域自适应方法,实现不同物种间的翻译后修饰知识迁移,从而提高预测精度。
[0004]
申请号为cn201910253412.9的发明专利《蛋白质编码方法及蛋白质翻译后修饰位点预测方法及系统》收集修饰位点信息、位置权重训练和待编码肽段的编码。蛋白质翻译后修饰位点预测方法包括收集修饰位点信息、特征编码、模型训练和蛋白质翻译后修饰位点预测。该发明申请利用深度神经网络和惩罚逻辑回归分别对不同类别的阳性位点和阴性位点的数字向量特征构建预测模型,得到多个预测模型;将每个预测模型的预测结果作为新的特征并利用惩罚逻辑回归构建最终模型。该现有专利可以捕获更多蛋白信息从而有助于提高预测的准确度,可以快速的大规模鉴定蛋白质修饰位点。然而前述现有专利分别构建模型过程采用的逻辑为利用深度神经网络和惩罚逻辑回归,同时该现有专利中对样本的标签分类采用的逻辑及参数也与本技术技术方案不同,故该现有发明披露的技术方案与本技术存在显著区别,该申请在实施方式中仅披露了针对人类、大鼠及小鼠的预测实例,无法减
小人类与其他物种翻译后修饰数据的分布差异。
[0005]
综上,现有技术存在预测方式低效、昂贵、耗时、拟合以及预测精度低的技术问题。
技术实现要素:
[0006]
本发明所要解决的技术问题在于如何解决现有技术中存在的预测方式低效、昂贵、耗时、拟合以及预测精度低的技术问题。
[0007]
本发明是采用以下技术方案解决上述技术问题的:物种特异性蛋白质翻译后修饰位点预测方法包括:
[0008]
s1、从预置数据库中收集整理差异物种的泛素化、乙酰化翻译后修饰位点,并利用滑动窗口技术提取所述翻译后修饰位点的局部序列,以构建数据集,独热编码所述数据集中的蛋白质局部序列,以获取翻译后修饰位点及差异物种训练样本;
[0009]
s2、在卷积神经网络的基础上增加密集连接,以使每个卷积层都接收前面所有的所述卷积层的特征图,据以构建出序列特征提取网络并设置分类器及领域类别判别器;
[0010]
s3、利用语义对抗策略配对处理所述差异物种训练样样本,以得到人类翻译后修饰样本及其他物种翻译后修饰样本的样本配对组;
[0011]
s4、使用所述人类翻译后修饰样本训练所述序列特征提取网络及分类器,根据所述样本配对组训练领域类别判别器,以区分输入样本对的组别信息,利用交替的方式分别训练序列特征提取网络和领域类别判别器,直至损失函数收敛,以使所述序列特征提取网络、所述分类器及所述领域类别判别器学习到领域不变性判别特征空间;
[0012]
s5、从所述翻译后修饰位点中划分得到独立测试集,据以评估所述序列特征提取网络、所述分类器及所述领域类别判别器的性能。
[0013]
本发明中的序列特征提取网络是在卷积神经网络的基础上增加密集连接,增强序列特征在模型中的传播,提取更为有效的序列特征。本发明基于语义对抗实现领域自适应,有效迁移人类翻译后修饰知识以辅助其他物种的位点预测,实现高精度的物种特异性翻译后修饰位点预测。
[0014]
在更具体的技术方案中,所述步骤s1包括:
[0015]
s11、从hprd、plmd、dbptm、phosphositeplus及mubisida数据库中收集赖氨酸乙酰化位点,以作为正例样本;
[0016]
s12、将相应蛋白质中未被报道发生乙酰化的其他赖氨酸位点视为反例样本;
[0017]
s13、利用cd-hit工具去除数据集中相似性大于40%的蛋白质;
[0018]
s14、利用滑窗方式截取每个所述翻译后修饰位点的上下游各15个氨基酸,以构成长度为31的氨基酸序列;
[0019]
s15、将所述氨基酸序列独热编码为特征矩阵;
[0020]
s16、按8:1:1的比例将所述数据集划分成训练集、验证集和测试集。
[0021]
在更具体的技术方案中,所述步骤s2包括:
[0022]
s21、为所述卷积神经网络的卷积模块设置密集连接,以下述逻辑使每个所述卷积层都接收前面所有的所述卷积层的特征图:
[0023]
,
[0024]
式中,表示对特征图进行拼接操作,wi为卷积核权重;
[0025]
s22、以下述逻辑在每个所述卷积模块后增加一瓶颈层,以降低特征的通道数:
[0026]
hb=αb(wbhm+bb),
[0027]
式中,hm为所述卷积模块的输出,wb,bb和αb分别表示所述瓶颈层中卷积核的权重、偏置项和激活函数;
[0028]
s23、设置所述分类器及所述领域类别判别器。
[0029]
本发明中的序列特征提取网络由多个密集连接模块构成,每个密集连接模块连接一个有1*1卷积构成的瓶颈层,用于降低特征的通道数,减小模型负担。
[0030]
在更具体的技术方案中,所述步骤s3包括:
[0031]
s31、将两个均来自人类乙酰化数据集且标签相同的所述差异物种训练样本构建为样本配对组p1;
[0032]
s32、将两个分别来自人类和其他物种乙酰化数据集但标签相同的所述差异物种训练样本构建为样本配对组p2;
[0033]
s33、将两个均来自人类乙酰化数据集但标签不同的所述差异物种训练样本构建为样本配对组p3;
[0034]
s34、将两个分别来人类和其他物种的乙酰化数据集且标签不同的所述差异物种训练样本构建为样本配对组p4。
[0035]
在模型训阶段提出的语义对抗训练策略:将人类训练样本与其他物种的训练样样本进行配对,以缓解其他物种数据不足的问题。可有效减小人类与其他物种翻译后修饰数据的分布差异,使得模型可有效迁移人类翻译后修饰知识用于辅助其他物种的位点预测,从而有效避免了模型的过拟合问题,使得模型更适用于小数据量物种,提高了模型的应用范围。
[0036]
在更具体的技术方案中,所述步骤s4包括:
[0037]
s41、冻结所述序列特征提取网络及所述分类器的参数,更新所述领域类别判别器的参数;
[0038]
s42、冻结所述领域类别判别器参数、所述训练特征提取网络及所述分类器,使得所述领域类别判别器不区分所述样本配对组;
[0039]
s43、以所述步骤s41及s42持续训练所述序列特征提取网络、所述分类器及所述领域类别判别器直至所述损失函数收敛,以对齐各物种乙酰化的语义。
[0040]
相比现有翻译后修饰位点预测方法,本发明提出的物种特异性预测方案可针对不同物种分别建立预测模型,提高了模型在不同物种上的预测精度。本发明对物种特异性翻译后修饰位点预测提供新思路,预测结果可以为蛋白质分子机制的研究提供依据,对揭示蛋白质的功能具有指导意义。
[0041]
在更具体的技术方案中,所述步骤s43中采用标准交叉熵损失函数优化所述领域类别判别器:
[0042]
,
[0043]
式中,e[
·
]表示统计期望,表示样本对pi的标签,φ表示将样本对pi中两个样
本的特征进行拼接。
[0044]
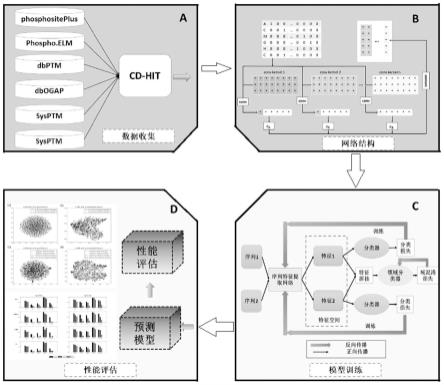
在更具体的技术方案中,所述步骤s43中采用下述损失函数优化所述特征提取网络:
[0045]
在更具体的技术方案中,所述步骤s43中采用下述逻辑结合分类损失,以保证ptm位点预测精度:
[0046][0047]
其中λ表示平衡分类损失和域混淆损失的权重系数,xs和x
t
分别表示人类和其他物种样本,gs和g
t
分别表示人类和其他物种的序列特征提取网络,hs和h
t
分别表示人类和其他物种的分类器,l表示标准二值交叉熵损失函数。
[0048]
本发明通过交替训练序列特征提取网络和领域类别判别器,模型最终学习到领域不变性的判别特征空间,在该特征空间中既能有效迁移人类乙酰化知识,同时可以实现多物种高精度乙酰化位点预测。
[0049]
在更具体的技术方案中,所述步骤s5包括:
[0050]
s51、将训练集中的样本对送入构建好的深度神经网络进行迭代训练;
[0051]
s52、循环遍历所述训练集;
[0052]
s53、每遍历一次训练集中的数据,就在验证集上以下述逻辑计算评价指标,据以保留适用的所述序列特征提取网络、所述分类器及所述领域类别判别器:
[0053][0054][0055][0056][0057]
,
[0058]
其中,tp表示被正确预测出的乙酰化位点总数,tn表示被正确预测的非乙酰化位点的总数,fp表示被误预测为乙酰化位点的样本总数,fn表示未被预测出的乙酰化位点总数。
[0059]
在更具体的技术方案中,物种特异性蛋白质翻译后修饰位点预测系统包括:
[0060]
数据预处理模块,用以从预置数据库中收集整理差异物种的泛素化、乙酰化翻译后修饰位点,并利用滑动窗口技术提取所述翻译后修饰位点的局部序列构建数据集,独热编码所述数据集中的蛋白质局部序列,以获取翻译后修饰位点及差异物种训练样本;
[0061]
网络构建模块,用以在卷积神经网络的基础上增加密集连接,以使每个卷积层都
接收前面所有的所述卷积层的特征图,据以构建出序列特征提取网络并设置分类器及领域类别判别器,所述网络构建模块与所述数据预处理模块连接;
[0062]
训练样本构建模块,用以利用语义对抗策略配对处理所述差异物种训练样样本,以得到人类翻译后修饰样本及其他物种翻译后修饰样本的样本配对组,所述训练样本构建模块与所述数据预处理模块连接;
[0063]
对抗训练模块,用以使用所述人类翻译后修饰样本训练所述序列特征提取网络及分类器,根据所述其他物种翻译后修饰样本训练领域类别判别器,以区分输入样本对的组别信息,利用交替的方式分别训练序列特征提取网络和领域类别判别器,直至损失函数收敛,以使所述序列特征提取网络、所述分类器及所述领域类别判别器学习到领域不变性判别特征空间,所述对抗训练模块与所述训练样本构建模块及所述网络构建模块连接;
[0064]
性能评估模块,用以根据翻译后修饰位点评估所述序列特征提取网络、所述分类器及所述领域类别判别器的性能,所述性能评估模块与所述对抗训练模块连接。
[0065]
本发明相比现有技术具有以下优点:本发明中的序列特征提取网络是在卷积神经网络的基础上增加密集连接,增强序列特征在模型中的传播,提取更为有效的序列特征。本发明基于语义对抗实现领域自适应,有效迁移人类翻译后修饰知识以辅助其他物种的位点预测,实现高精度的物种特异性翻译后修饰位点预测。
[0066]
本发明中的序列特征提取网络由多个密集连接模块构成,每个密集连接模块连接一个有1*1卷积构成的瓶颈层,用于降低特征的通道数,减小模型负担。
[0067]
在模型训阶段提出的语义对抗训练策略:将人类训练样本与其他物种的训练样样本进行配对,以缓解其他物种数据不足的问题。可有效减小人类与其他物种翻译后修饰数据的分布差异,使得模型可有效迁移人类翻译后修饰知识用于辅助其他物种的位点预测,从而有效避免了模型的过拟合问题,使得模型更适用于小数据量物种,提高了模型的应用范围。
[0068]
相比现有翻译后修饰位点预测方法,本发明提出的物种特异性预测方案可针对不同物种分别建立预测模型,提高了模型在不同物种上的预测精度。本发明对物种特异性翻译后修饰位点预测提供新思路,预测结果可以为蛋白质分子机制的研究提供依据,对揭示蛋白质的功能具有指导意义。
[0069]
本发明通过交替训练序列特征提取网络和领域类别判别器,模型最终学习到领域不变性的判别特征空间,在该特征空间中既能有效迁移人类乙酰化知识,同时可以实现多物种高精度乙酰化位点预测。本发明解决了现有技术中存在的预测方式低效、昂贵、耗时、拟合以及预测精度低的技术问题。
附图说明
[0070]
图1为本发明方法deepace-pred流程图;
[0071]
图2为本发明方法构建的序列特征提取网络结构图;
[0072]
图3-a为本发明方法与现有其他方法在乙酰化修饰上的第一roc曲线比较结果示意图;
[0073]
图3-b为本发明方法与现有其他方法在乙酰化修饰上的第二roc曲线比较结果示意图;
[0074]
图3-c为本发明方法与现有其他方法在乙酰化修饰上的第三roc曲线比较结果示意图;
[0075]
图3-d为本发明方法与现有其他方法在乙酰化修饰上的第四roc曲线比较结果示意图;
[0076]
图3-e为本发明方法与现有其他方法在乙酰化修饰上的第五roc曲线比较结果示意图;
[0077]
图3-f为本发明方法与现有其他方法在乙酰化修饰上的第六roc曲线比较结果示意图;
[0078]
图3-g为本发明方法与现有其他方法在乙酰化修饰上的第七roc曲线比较结果示意图;
[0079]
图3-h为本发明方法与现有其他方法在乙酰化修饰上的第八roc曲线比较结果示意图;
[0080]
图3-i为本发明方法与现有其他方法在乙酰化修饰上的第九roc曲线比较结果示意图;
[0081]
图4-a为本发明方法与现有其他方法在乙酰化修饰上的第一性能指标对比结果示意图;
[0082]
图4-b为本发明方法与现有其他方法在乙酰化修饰上的第二性能指标对比结果示意图;
[0083]
图4-c为本发明方法与现有其他方法在乙酰化修饰上的第三性能指标对比结果示意图;
[0084]
图4-d为本发明方法与现有其他方法在乙酰化修饰上的第四性能指标对比结果示意图;
[0085]
图4-e为本发明方法与现有其他方法在乙酰化修饰上的第五性能指标对比结果示意图;
[0086]
图4-f为本发明方法与现有其他方法在乙酰化修饰上的第六性能指标对比结果示意图;
[0087]
图4-g为本发明方法与现有其他方法在乙酰化修饰上的第七性能指标对比结果示意图;
[0088]
图4-h为本发明方法与现有其他方法在乙酰化修饰上的第八性能指标对比结果示意图。
具体实施方式
[0089]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0090]
实施例1
[0091]
如图1所示,下面结合附图和具体实施例对本发明进行详细说明。本发明实施例提供一种针对物种特异性乙酰化位点预测方法,其主要包括如下步骤:
[0092]
步骤1、数据预处理。
[0093]
首先,将从各数据库中收集的赖氨酸乙酰化位点作为正例样本,将相应蛋白质中未被报道发生乙酰化的其他赖氨酸位点视为反例样本。其次,为防止因蛋白质同源性造成的性能过优化问题,本发明采用cd-hit工具,去除数据集中相似性大于40%的蛋白质。对于每个位点,采用滑窗方式截取其上下游各15个氨基酸,构成长度为31的氨基酸序列。再采用独特编码方法将氨基酸序列编码为31*21的特征矩阵。最后,将数据集按8:1:1的比例划分成训练集、验证集和测试集三部分。
[0094]
步骤2、构建深度神经网络。
[0095]
如图2所示,本发明实施例中,序列特征提取网络按如图2中的方式构建:序列特征提取网络由多个级联的卷积模块构成,该模块在卷积神经网络的结构基础上设计了密集连接,使得模块内每个卷积层都与前面所有层相连。对于模块中第i个卷积层,相应的输出为其中表示对特征图进行拼接操作。为避免网络层数增多给模型带来过大负担,在每个模块后增加一个瓶颈层,以降低特征的通道数。瓶颈层是用利用1*1卷积来实现特征压缩:
[0096]
hb=αb(wbhm+bb)
ꢀꢀ
(1)
[0097]
其中hm为模块的输出,wb,bb和αb分别表示瓶颈层中卷积核的权重、偏置项和激活函数。
[0098]
样本经序列特征提取网络后转换为特征向量输入分类器进行分类。分类器由两层全连接神经网络构成,其中第一层包含6160个神经元,第二层包含2个神经元,激活函数为softmax输出预测打分。
[0099]
模型还包含一个领域类别判别器,其输入由样本对经过序列特征提取网络后的特征拼接构成。领域类别判别器由三层卷积神经网络构成,其中第一层包含12320个神经元,第二层包含64个神经元,第三层包含4个神经元,输出分类结果。
[0100]
步骤3、训练样本构建。
[0101]
为实现对抗训练,本发明构建四组样本对:1)两个样本均来自人类乙酰化数据集且标签相同(p1);2)两个样本分别来自人类和其他物种乙酰化数据集但标签相同(p2);
[0102]
3)两个样本均来人类乙酰化数据集但标签不同(p3);4)两个样本分别来人类和其他物种的乙酰化数据集且标签不同(p4)。
[0103]
步骤4、采用语义对抗训练策略对网络模型进行训练。
[0104]
采用交替的方式分别训练序列特征提取网络和领域类别判别器。首先使用人类乙酰化数据对序列特征提取网络和分类器进行预训练。然后使用构建的四组样本对训练领域类别判别器,使之可有效区分输入样本对属于哪一类。领域类别判别器拟采用标准交叉熵损失函数进行优化:
[0105][0106]
其中e[
·
]表示统计期望,表示样本对pi的标签,φ表示将样本对pi中两个样本的特征进行拼接。在对领域类别判别器进行训练时,冻结特征提取网络以及分类器的参数。接下来训练特征提取网络,使得领域类别判别器无法有效区分数据对的类别,相应的损失函数如下:
[0107][0108]
通过这样的训练可以混淆领域类别判别器,从而实现人类和其他物种乙酰化的语义对齐,有效减小不同物种间的分布差异。此外,为确保ptm位点预测的精度,本项目进一步在公式(3)基础上结合分类损失:
[0109][0110]
其中λ表示平衡分类损失和域混淆损失的权重系数,xs和x
t
分别表示人类和其他物种样本,gs和g
t
分别表示人类和其他物种的序列特征提取网络,hs和h
t
分别表示人类和其他物种的分类器,l表示标准二值交叉熵损失函数。
[0111]
通过交替训练序列特征提取网络和领域类别判别器,模型最终学习到领域不变性的判别特征空间,在该特征空间中既能有效迁移人类乙酰化知识,同时可以实现多物种高精度乙酰化位点预测。
[0112]
步骤5、性能评估
[0113]
本发明实施例中,将训练集中的样本对送入构建好的深度神经网络进行迭代训练,每遍历一次训练集中的数据,就在验证集上计算一次评价指标,保留其中性能最好的网络。
[0114]
示例性的,评价指标定义如下:
[0115][0116][0117][0118][0119][0120]
其中,tp表示被正确预测出的乙酰化位点总数,tn表示被正确预测的非乙酰化位点的总数,fp表示被误预测为乙酰化位点的样本总数,fn表示未被预测出的乙酰化位点总数。
[0121]
实施例2
[0122]
1)数据收集整理:首先从hprd、plmd、dbptm、phosphositeplus和mubisida等数据库中收集整理多个物种的泛素化、乙酰化等翻译后修饰位点,并利用滑动窗口技术提取翻译后修饰位点的局部序列构建数据集。然后对数据集中的蛋白质局部序列进行独热编码,序列中的每个氨基酸都被编码成21维的特征向量,向量中对应该氨基酸的位置为1其他位置均为0。
[0123]
2)网络结构设计:序列特征提取网络是在卷积神经网络的基础上增加密集连接,
使每个卷积层都能够接收前面所有卷积层的特征图,从而增强序列特征在模型中的传播,提取更为有效的序列特征。序列特征提取网络由多个密集连接模块构成,每个密集连接模块连接一个有1*1卷积构成的瓶颈层,用于降低特征的通道数,减小模型负担。分类器由两层全连接网络构成,用于输出样本类别。领域类别判别器由两个全连接层构成,用于判断输入数据所属的领域类别。
[0124]
3)语义对抗训练策略:将人类训练样本与其他物种的训练样样本进行配对,以缓解其他物种数据不足的问题。配对共分为4种情况:两个样本均来自人类且标签相同(p1),两个样本分别来自人类和其他物种但标签相同(p2),两个样本均来人类但标签不同(p3),两个样本分别来人类和其他物种且标签不同(p4)。
[0125]
配对完成后,第一步使用人类翻译后修饰样本训练对序列特征提取网络和分类器进行预训练。第二步,训练领域类别判别器以区分输入样本对属于上述四组配对中的哪一组。此时,冻结序列特征提取网络和分类器的参数,仅更新领域类别判别器的参数。第三步,冻结领域类别判别器参数,训练特征提取网络和分类器,使得领域类别判别器无法区分组1和组2以及组3和组4。然后再循环进行第二步和第三步的训练,直至损失函数收敛。
[0126]
4)性能评估:从收集到的翻译后修饰位点中随机划分10%的数据作为独立测试集,采用准确率、召回率、精确率等指标对预测结果进行评估。
[0127]
如图2所示,在本实施例中,评估本技术的准确性和稳健性。本发明实施例计算了其在测试集上的评价指标,并与现有其他乙酰化位点预测方法进行对比。从结果可以看出,本发明deepace-pred优于现有其他乙酰化修饰位点预测方法pail和capsnet-ptm。相较于现有方法中性能最高的模型capsnet-ptm,本发明在小家鼠上乙酰化位点预测的auc值从0.695提高到0.759,相对提升超过6.4%。此外,在酵母上,本发明相较于pail和capsnet-ptm也分别取得了5.1和24.7的auc值提升。
[0128]
如图4所示,除auc值之外,我们还评估了各种方法的acc值、pre值、f1值等多种性能指标及结果。从图4中可以看出,在多个物种上本发明相较于现有乙酰化位点方法均取得了更高的预测性能。例如在小家鼠上,本发明deepace-pred的pre值为0.795,相较于capsnet-ptm和pail分别提升了13.1%和27.0%。上述结果说明,本发明提出的语义对抗策略可有效减小人类与其他物种间的乙酰化数据分布差异,有利于知识的迁移,从而显著提升了模型在其他物种上的预测性能。
[0129]
综上,本发明中的序列特征提取网络是在卷积神经网络的基础上增加密集连接,增强序列特征在模型中的传播,提取更为有效的序列特征。本发明基于语义对抗实现领域自适应,有效迁移人类翻译后修饰知识以辅助其他物种的位点预测,实现高精度的物种特异性翻译后修饰位点预测。
[0130]
本发明中的序列特征提取网络由多个密集连接模块构成,每个密集连接模块连接一个有1*1卷积构成的瓶颈层,用于降低特征的通道数,减小模型负担。
[0131]
在模型训阶段提出的语义对抗训练策略:将人类训练样本与其他物种的训练样样本进行配对,以缓解其他物种数据不足的问题。可有效减小人类与其他物种翻译后修饰数据的分布差异,使得模型可有效迁移人类翻译后修饰知识用于辅助其他物种的位点预测,从而有效避免了模型的过拟合问题,使得模型更适用于小数据量物种,提高了模型的应用范围。
[0132]
相比现有翻译后修饰位点预测方法,本发明提出的物种特异性预测方案可针对不同物种分别建立预测模型,提高了模型在不同物种上的预测精度。本发明对物种特异性翻译后修饰位点预测提供新思路,预测结果可以为蛋白质分子机制的研究提供依据,对揭示蛋白质的功能具有指导意义。
[0133]
本发明通过交替训练序列特征提取网络和领域类别判别器,模型最终学习到领域不变性的判别特征空间,在该特征空间中既能有效迁移人类乙酰化知识,同时可以实现多物种高精度乙酰化位点预测。本发明解决了现有技术中存在的预测方式低效、昂贵、耗时、拟合以及预测精度低的技术问题。
[0134]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1