一种基于层次基团构建的纯组分炼化性质的预测方法与流程
1.本发明涉及炼化工业数据分析领域,特别涉及一种基于层次基团构建的纯组分炼化性质的预测方法。
背景技术:
2.传统的炼化单元模型,碍于分析化学与计算机硬件的限制,多使用集总动力学模型,原料和产品常依据宏观性质如沸点或溶解度划分成集总。如催化裂化单元所广泛采用的十集总、十一集总模型。但基于宏观层次划分的集总天然具有多组分属性,无法详细表征组分信息,导致此类集总模型难以扩展到新的原料与催化剂体系。然而分子层次的集总模型可从纯组分层面计算原料的组成、性质,建立反应网络,进而精准预测炼化加工单元产物的性质。配合以纯组分性质预测模型与混合规则模型,分子动力学模型不但可预测炼化单元产物的分布即定性分析,更可实现定量预测产物相应的炼化性质。这一进展可使决策者定向地设计产物中纯组分的化学结构,优化单元操作条件,进而为炼化理论研究和工业生产指引方向。其中对于纯组分炼化性质预测的精度直接关系对产物质量评估的准确性,进而影响各操作单元的优化方向,是分子动力学模型的关键点,同时关系到分子管理技术能否顺利应用于炼厂优化。
技术实现要素:
3.本发明要解决的技术问题,在于提供一种基于层次基团构建的纯组分炼化性质的预测方法,针对石油产物中纯组分的如汽油产物各组分的辛烷值、柴油产物中各组分的十六烷值进行预测,通过组分特征集分层构建,在加入组分描述符进行特征集合时,引入贝叶斯规则,从而可以对其进行后验概率分布估计,在此基础上,引入层次基团构建,对基团片段进行分层构建,避免最终预测的过拟合风险。
4.本发明具体包括如下步骤:
5.步骤10、采用可编码的简化组分表达方式smiles,将复杂组分结构用二维编码表示,构建预定义基团片段组分库,包括一级基团、二级基团以及三级基团;所述一级基团为包含组分结构的基本基团;所述二级基团为基本基团的链接位置组合,用于区分芳烃与链烷烃以及相应的同分异构体;所述三级基团为描述组分拓扑结构的描述符;
6.步骤20、根据目标组分的分子结构从所述预定义基团片段组分库中筛选出一级基团和二级基团,再根据目标组分待预测的炼化性质利用与所述一级基团和二级基团保持最小的相关性,同时与待预测性质保持最大信息量的原则筛选得到多个三级基团,随机选取任意数量的三级基团与出的一级基团和二级基团构成多个组分特征集,然后筛选得到后验概率最大的组分特征集;
7.步骤30、采用线性累加函数将不同层次的基团结合进行建模然后通过训练集对系数求解,得到层级基团模型;
8.步骤40、根据所述后验概率最大的组分特征集生成多个候选模型,基于所述层级
基团模型,通过再次使用贝叶斯规则,得到全部候选模型的置信区间,结合每一所述候选模型的精度,根据多目标优化的原则筛选出适用于炼化厂实际情况的辛烷值、十六烷值模型。
9.进一步地,所述步骤20中,筛选得到后验概率最大的组分特征集,具体包括:
10.单一模型m属于候选模型集合m每个模型服从已知数据集y的分布,f(y|m,βm),其中参数向量βm∈bm,bm为模型m系数可能取值的集合,设模型m的先验概率为f(m),则后验概率为:
[0011][0012]
其中,f(y|m)为边缘相似性,由f(y|m)=∫f(y|m,βm)f(βm|m)dβm与f(βm|m)计算得到,用马尔科夫蒙特卡洛随机抽样法近似估计其值,抽样范围为(m,βm)所在空间:
[0013][0014]
其中,其中p为全体特征数量。
[0015]
进一步地,所述步骤30包括数据预处理过程与建模验证过程;
[0016]
所述数据预处理过程为:通过概率统计方法将数据集进行正态化转换,然后采用无监督学习方法直接对数据集进行聚类分析,对数据集中特征空间的稀疏空洞进行近似估计,得到训练集;
[0017]
所述建模验证过程中,层次基团的建模采用线性累加函数,公式如下:
[0018][0019]
其中,函数f(y)为待预测性质的函数,ci为一级基团中第i基团的贡献度,ni为i基团出现次数,δ为一级基团系数;w为二级基团系数,dj为二级基团中j基团的贡献度,mj为其出现次数;λ为三级组分描述符基团系数,f(y*)为三级描述符对给定性质的总贡献度;
[0020]
计算层级基团系数δ,w,λ和基团贡献度ci,dj时,采用层次方法依次回归,通过训练集回归得到ci;之后回归得到二级基团贡献度dj;f(y*)由组分描述符计算得到,不需回归计算,最后统一回归得到基团系数δ,w,λ,即权重的大小,代表所属层级基团片段对给定性质的影响力。
[0021]
本发明具有如下优点:
[0022]
基于机理挑选基团片段,并结合不依赖数据回归系数的组分描述符,减少了所需回归计算系数的数量,在相当程度上降低了对数据集规模的依赖性,同时给出了特征子集模型的后验分布概率,实现“软”约束,适用于数据量有限的纯组分炼化性质的预测研究;在此基础上,再次引入贝叶斯规则,从而可对最终模型进行后验概率分布估计,避免最终预测模型的过拟合风险。
附图说明
[0023]
下面参照附图结合实施例对本发明作进一步的说明。
[0024]
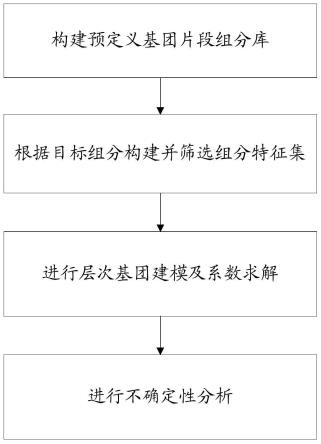
图1为本发明方法的流程示意图;
[0025]
图2为本发明层次基团示意图;
[0026]
图3为本发明组分特征集构建筛选流程示意图;
[0027]
图4为本发明层次基团的建模流程示意图;
[0028]
图5为本发明候选模型不确定性分析流程示意图之一;
[0029]
图6为本方法候选模型不确定性分析流程示意图之二。
具体实施方式
[0030]
本发明实施例通过提供一种基于层次基团构建的纯组分炼化性质的预测方法,针对石油产物中纯组分的如汽油产物各组分的辛烷值、柴油产物中各组分的十六烷值进行预测,通过组分特征集分层构建,在加入组分描述符进行特征集合时,引入贝叶斯规则,从而可以对其进行后验概率分布估计,在此基础上,引入层次基团构建,对基团片段进行分层构建,避免最终预测的过拟合风险。
[0031]
如图1所示,本发明的总体思路如下:
[0032]
s1:构建预定义基团片段组分库。
[0033]
针对已有基团片段构建方法的缺陷,提出崭新的一套组分特征集,以表征石油产物中组分的炼化性质。此组分特征集结合机理的特征基团与机器学习筛选出的组分描述符,用以表征组分炼化性质。构建基团与描述符的同时,将其划分层次,越高层次的基团包含对组分更为细致的描述。
[0034]
一级基团包含组分结构的基本基团如-ch,-ch3,-co等,简单结构的组分如链烷烃可以通过该层次基团进行拆解表征。然而该层次基团只能代表组分的基本组成,不能表征基团在组分中的链接位置,而链接位置的不同对组分炼化性质具有举足轻重的影响。
[0035]
因此,二级基团着重建立基团块,即基本基团的组合,以区分芳烃与链烷烃以及相应的同分异构体。如图2所示,一级基本基团中包括代表芳环a6基团与ch2的r基团。而其中的-ch2基团因其链接在苯环上,因此与其所连接的苯环上的碳组成新的基团块ac-ch,在二级基团块表示以表征该组分。
[0036]
三级基团采用组分描述符,由于组分描述符数量众多,基于量子化学计算的描述符,其准确性在科学界还有一定争议,因此将着重关注描述组分拓扑结构的描述符,如连接性指数(connectivity index)。
[0037]
s2、根据目标组分构建并筛选组分特征集。
[0038]
如图3所示,当需要对目标组分的炼化性质进行预测时,采用可编码的,简化组分表达方式smiles,将复杂组分结构用二维编码表示,将给定组分分子结构自动拆解成符合组分库中的基团片段,从而进行定量化分析。
[0039]
先根据目标组分的分子结构从基团库里筛选一级基团和二级基团,可以采用模拟退火、遗传算法等全局优化算法进行筛选。接着向筛选出来的特征集合中加入三级基团,然而三级基团的加入难免会与一级,二级基团相重叠,从而造成特征集冗余。因此,结合信息理论与机器学习,引入最小相关度-最大信息量概念,保证加入三级基团与已有的低级别基团保持最小的相关性,同时与待预测性质保持最大信息量,即最大化表征待预测性质。
[0040]
接着引入贝叶斯规则进行特征选择计算候选模型后验概率。单一模型m属于候选模型集合m每个模型服从已知数据集y的分布,f(y|m,βm),其中参数向量βm∈bm,bm为模型m系数可能取值的集合。设模型m的先验概率为f(m),则后验概率为:
[0041][0042]
其中,f(y|m)为边缘相似性,可由f(y|m)=∫f(y|m,βm)f(βm|m)dβm与f(βm|m)计算得到。但此积分绝大多数情况下无法得到解析解,因此用马尔科夫蒙特卡洛(mcmc)随机抽样法近似估计其值。抽样范围为(m,βm)所在空间:
[0043][0044]
特征选择为模型选择的分支问题,即用二项分布表示候选模型,其中p为全体特征数量。由此得到每个特征子集所代表模型的基于已知数据集y的后验分布概率,从而实现“软”约束。此基于贝叶斯规则特征选择方法的核心为mcmc抽样方法。
[0045]
基于机理挑选基团片段,并结合不依赖数据回归系数的组分描述符,减少了所需回归计算系数的数量,在相当程度上降低了对数据集规模的依赖性,同时给出了特征子集模型的后验分布概率,实现“软”约束,适用于数据量有限的纯组分炼化性质的预测研究。
[0046]
s3:进行层次基团建模及系数求解。
[0047]
层级基团建模与系数求解过程如图4所示,总体可分为数据预处理与建模验证两部分。由于组分炼化性质已有数据集稀疏性强,因此在数据预处理阶段需引入先进的统计学与机器学习方法,力求提升小样本数据建模的精度。
[0048]
数据库中组分的特征值与实验值的分布难以满足正态分布要求,在建模过程中将会影响模型效果,需通过概率统计方法即box-cox对数似然函数法,将其进行正态化转换。由于特征空间的稀疏性,随机选取的训练集难以涵盖测试集的特征空间,导致基于训练集模型过于外推,降低模型预测效果。因此第二步采用无监督学习方法,即只针对数据集的特征集而不通过对建模效果的评估,直接对数据集进行聚类分析,对数据集中特征空间的稀疏空洞进行近似估计,基于此选取的训练集,可在最大程度上涵盖测试集样本的特征空间,提高模型预测效果。
[0049]
层次基团的建模优先考虑传统的线性累加函数,因其运算量较小,并能给出相应基团的贡献度系数,其在一定程度上提供更为丰富的机理信息。其公式形式如下式所示:
[0050][0051]
其中,函数f(y)为待预测性质的函数,ci为一级基团中第i基团的贡献度,ni为i基团出现次数,δ为一级基团系数;w为二级基团系数,dj为二级基团中j基团的贡献度,mj为其出现次数;λ为三级组分描述符基团系数,f(y*)为三级描述符对给定性质的总贡献度。
[0052]
计算层级基团系数δ,w,λ和基团贡献度ci,dj时,采用层次方法依次回归。通过训练集回归得到ci;之后回归得到二级基团贡献度dj;由于f(y*)由组分描述符计算得到,不需回归计算,从而大大减少对训练集规模的需求。最后统一回归得到基团系数δ,w,λ。计算得到的基团系数δ,w,λ,即权重的大小,可代表所属层级基团片段对给定性质的影响力。
[0053]
s4:进行不确定性分析。
[0054]
如图5和图6所示,预测值的不确定性分析即置信区间的估计,对模型的实际应用至关重要。由于层级基团模型具有显性的数学表达式,同时又包括各候选模型的概率分布,通过再次使用贝叶斯规则,可得全部候选模型的置信区间,结合各自模型的精度,综合考虑
模型的精确性与实用性,得到更适用于炼厂实际情况的辛烷值、十六烷值模型。
[0055]
需要说明的是,本领域的相关技术人员在进行良品率预测计算的过程中,可以根据相关的原理进行适当变形及相应的参数设置。以上所述实施例仅表达了本发明的一种实施方式,其描述已经较为具体和详细,但是不能因此理解为对发明专利范围的限制。
[0056]
本发明一具体实施例如下:
[0057]
步骤10、采用可编码的简化组分表达方式smiles,将复杂组分结构用二维编码表示,构建预定义基团片段组分库,包括一级基团、二级基团以及三级基团;所述一级基团为包含组分结构的基本基团;所述二级基团为基本基团的链接位置组合,用于区分芳烃与链烷烃以及相应的同分异构体;所述三级基团为描述组分拓扑结构的描述符;
[0058]
步骤20、根据目标组分的分子结构从所述预定义基团片段组分库中筛选出一级基团和二级基团,再根据目标组分待预测的炼化性质利用与所述一级基团和二级基团保持最小的相关性,同时与待预测性质保持最大信息量的原则筛选得到多个三级基团,随机选取任意数量的三级基团与出的一级基团和二级基团构成多个组分特征集,然后筛选得到后验概率最大的组分特征集;
[0059]
步骤30、采用线性累加函数将不同层次的基团结合进行建模然后通过训练集对系数求解,得到层级基团模型;
[0060]
步骤40、根据所述后验概率最大的组分特征集生成多个候选模型,基于所述层级基团模型,通过再次使用贝叶斯规则,得到全部候选模型的置信区间,结合每一所述候选模型的精度,根据多目标优化的原则筛选出适用于炼化厂实际情况的辛烷值、十六烷值模型。
[0061]
所述步骤20中,筛选得到后验概率最大的组分特征集,具体包括:
[0062]
单一模型m属于候选模型集合m每个模型服从已知数据集y的分布,f(y|m,βm),其中参数向量βm∈bm,bm为模型m系数可能取值的集合,设模型m的先验概率为f(m),则后验概率为:
[0063][0064]
其中,f(y|m)为边缘相似性,由f(y|m)=∫f(y|m,βm)f(βm|m)dβm与f(βm|m)计算得到,用马尔科夫蒙特卡洛随机抽样法近似估计其值,抽样范围为(m,βm)所在空间:
[0065][0066]
其中,其中p为全体特征数量。
[0067]
所述步骤30包括数据预处理过程与建模验证过程;
[0068]
所述数据预处理过程为:通过概率统计方法将数据集进行正态化转换,然后采用无监督学习方法直接对数据集进行聚类分析,对数据集中特征空间的稀疏空洞进行近似估计,得到训练集;
[0069]
所述建模验证过程中,层次基团的建模采用线性累加函数,公式如下:
[0070][0071]
其中,函数f(y)为待预测性质的函数,ci为一级基团中第i基团的贡献度,ni为i基团出现次数,δ为一级基团系数;w为二级基团系数,dj为二级基团中j基团的贡献度,mj为其
出现次数;λ为三级组分描述符基团系数,f(y*)为三级描述符对给定性质的总贡献度;
[0072]
计算层级基团系数δ,w,λ和基团贡献度ci,dj时,采用层次方法依次回归,通过训练集回归得到ci;之后回归得到二级基团贡献度dj;f(y*)由组分描述符计算得到,不需回归计算,最后统一回归得到基团系数δ,w,λ,即权重的大小,代表所属层级基团片段对给定性质的影响力。
[0073]
本发明基于机理挑选基团片段,并结合不依赖数据回归系数的组分描述符,减少了所需回归计算系数的数量,在相当程度上降低了对数据集规模的依赖性,同时给出了特征子集模型的后验分布概率,实现“软”约束,适用于数据量有限的纯组分炼化性质的预测研究;在此基础上,再次引入贝叶斯规则,从而可对最终模型进行后验概率分布估计,避免最终预测模型的过拟合风险。
[0074]
虽然以上描述了本发明的具体实施方式,但是熟悉本技术领域的技术人员应当理解,我们所描述的具体的实施例只是说明性的,而不是用于对本发明的范围的限定,熟悉本领域的技术人员在依照本发明的精神所作的等效的修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1