基于强化学习的高剂量率近距离放射治疗剂量优化算法
1.本发明涉及放射治疗剂量优化技术领域,特别是涉及一种基于强化学习的高剂量率近距离放射治疗剂量优化算法。
背景技术:
2.肿瘤是威胁人类生命健康和导致人类死亡的重大疾病之一,高剂量率近距离放射治疗是治疗肿瘤的一种重要手段。剂量规划技术是高剂量率近距离放射治疗的核心,对治疗效果起着决定性作用。剂量规划的目的是为放射源设置合理的驻留位置及对应的驻留时间,使肿瘤靶区受到足够的照射剂量,同时尽量减少周围正常组织和危及器官所受到的辐射,实现适形放疗。
3.剂量规划方法主要分为正向优化和逆向优化两种。正向优化是人为地设定放射源的驻留位置和驻留时间,使生成的剂量场符合临床治疗的要求。这种方法操作效率较低,且高度依赖医生的经验。逆向优化是通过将临床的剂量要求构造为目标函数,然后采用一定的优化算法对目标函数进行优化求解,以直接生成放射源最优的驻留位置及相应的驻留时间。这种方法无需临床医生进行手动调整,速度快、精度高、重复性好,降低了规划过程对于医生经验的要求,成为如今放射治疗领域的研究热点。
4.在当前提出的剂量优化算法中,几乎全都依靠物理剂量构造目标函数。其没有考虑剂量照射时产生的生物效应,同时也忽略了剂量不均匀性对治疗结果的影响,阻碍了优化质量的提高。同时,对于目标函数的优化求解,普遍基于和谐搜索算法、遗传算法、模拟退火算法和粒子群优化算法等传统算法建立,这些算法均属于基于概率的随机搜索算法,其全局最优解的搜索过程是随机、无方向的,且容易陷入局部最优解中,导致最终解不一定为可行解。
技术实现要素:
5.本发明的目的是针对现有技术中存在的技术缺陷,而提供一种基于强化学习的高剂量率近距离放射治疗剂量优化算法。
6.为实现本发明的目的所采用的技术方案是:
7.一种基于强化学习的高剂量率近距离放射治疗剂量优化算法,包括:
8.采用结合生物等效均匀剂量eud和物理剂量约束的目标函数模型以及基于ppo算法的剂量优化网络实现:所述结合生物等效均匀剂量eud和物理剂量约束的混合目标函数的数学模型为:
9.min f
hyb
=α
·fctv
+βf
oar
+λf
time
10.上式为目标函数的总体表达式,f
ctv
是针对靶区的目标函数项,f
oar
是针对危及器官的目标函数项,f
time
是针对驻留时间梯度的目标函数项,α、β、λ分别是各自对应的权重;
11.12.f
ctv
的计算表达式中,wi是对靶区内每个剂量计算点的惩罚值,n
t
是靶区内剂量计算点的总数;
[0013][0014]
上式为靶区剂量计算点惩罚值的计算表达式,d
ij
为第j个驻留点对第i个剂量计算点的剂量率,为驻留时间,d
min
、d
max
分别为对靶区剂量限制的最小值和最大值,m
min
、m
max
分别为权重因子;
[0015][0016]foar
的计算表达式中,为第i个危及器官的处方eud值,eudi为第i个危及器官的实际eud值,n
s,i
为第i个危及器官的剂量计算点总数,为权重因子;
[0017][0018]
eud的计算表达式中,di为第i个eud计算点的剂量,nk为eud计算点的总数,σ为生物特性参数;
[0019][0020]ftime
的计算表达式中,t
m,n
为第m个驻留通道上第n个驻留点的驻留时间,n(m)为第m个驻留通道的驻留点总数,nc为驻留通道总数,n
p
为驻留点总数,tk为第k个驻留点的驻留时间;
[0021]
所述基于ppo算法的剂量优化网络包括状态空间、动作空间和奖励函数;其中,以每个驻留位置的驻留时间作为状态空间,利用数组的形式对其进行存储;动作空间为对各驻留时间的调整动作;奖励函数以优化目标函数作为评价指标,当目标函数值减小则给予正奖励,当目标函数值增大则给予负奖励,目标函数值不变则不给予奖励,其表达形式如下:
[0022]
[0023]
式中,f
hyb
(s
t
)是状态s
t
下的目标函数;为保证优化开始前初始时间t0的设置尽可能接近最终的优化结果,提出如下时间初始化方案:
[0024][0025]
式中,d
i,j
是第j个驻留点对第i个剂量计算点的剂量率;n
p
是驻留点总数;n是剂量计算点的总数;d
min
是对靶区剂量限制的最小值,τ是一个放缩因子。
[0026]
进一步的,为加速模型的训练过程,除依靠网络的自身学习能力外,建立先验知识引导的优化策略,具体为:在优化过程中,以90%的概率基于强化学习网络自主优化驻留时间,以10%的概率依靠制定的先验规则调整时间。
[0027]
其中,先验规则的具体内容为:若当前计算得的剂量学指标v100小于90%时,选取离靶区低剂量区最近的k个放射源,将此k个放射源的驻留时间分别加1秒;若当前计算得的剂量学指标v200大于35%时,选取离靶区高剂量区最近的k个放射源,将此k个放射源的驻留时间分别减1秒。
[0028]
本发明通过设计结合物理剂量约束和生物等效均匀剂量eud约束的目标函数模型,使优化目标函数充分反映临床治疗实际需求,同时建立基于强化学习的剂量优化神经网络,对提出的目标函数进行优化求解,实现对优化过程中驻留时间的调整策略自主学习,进行有方向、有策略的优化,提高剂量优化的质量。
附图说明
[0029]
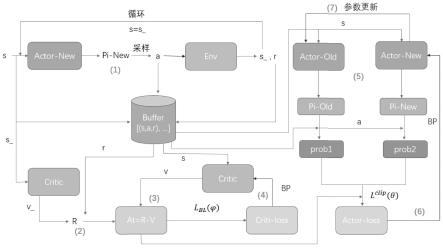
图1是本发明的基于强化学习的高剂量率近距离放射治疗剂量优化算法的ppo剂量优化算法的处理流程示意图。
具体实施方式
[0030]
以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0031]
本发明实施例的基于强化学习的高剂量率近距离放射治疗剂量优化算法,包括如下步骤:
[0032]
首先,建立基于生物eud(equivalent uniform dose,等效均匀剂量)和物理剂量的混合目标函数模型,其中对靶区进行eud约束,对危及器官进行物理剂量约束。
[0033]
通过研究发现,单纯基于生物eud的目标函数在保证照射剂量肿瘤覆盖率条件下,可有效改善危及器官的剂量分布。然而,靶区的过量照射对eud的影响很小,eud对靶区的剂量不足却十分敏感,这容易导致靶区内出现较大的剂量热区,影响治疗效果。而基于物理剂量的目标函数可在靶区内产生更均匀和适形的剂量分布。因此,本发明建立一种基于生物eud和物理剂量的混合目标函数,以综合应用各自的特点和优势。
[0034]
其中,目标函数的具体形式如式(1)-(6)。
[0035]
min f
hyb
=α
·fctv
+β
·foar
+λf
time
ꢀꢀ
(1)
[0036]
[0037][0038][0039][0040][0041]
式(1)为目标函数的总体表达式,f
ctv
是针对靶区的目标函数项,f
oar
是针对危及器官的目标函数项,f
time
是针对驻留时间梯度的目标函数项,α、β、λ分别是各自对应的权重;
[0042]
式(2)f
ctv
的计算表达式,wi是对靶区内每个剂量计算点的惩罚值,n
t
是靶区内剂量计算点的总数;
[0043]
式(3)为靶区剂量计算点惩罚值的计算表达式,d
ij
为第j个驻留点对第i个剂量计算点的剂量率,为驻留时间,d
min
、d
max
分别为对靶区剂量限制的最小值和最大值,m
min
、m
max
分别为权重因子;
[0044]
式(4)为f
oar
的计算表达式,为第i个危及器官的处方eud值,eudi为第i个危及器官的实际eud值,n
s,i
为第i个危及器官的剂量计算点总数,为权重因子;
[0045]
式(5)为eud的计算表达式,di为第i个eud计算点的剂量,nk为eud计算点的总数,σ为生物特性参数;
[0046]
式(6)为f
time
的计算表达式,t
m,n
为第m个驻留通道上第n个驻留点的驻留时间,n(m)为第m个驻留通道的驻留点总数,nc为驻留通道总数,n
p
为驻留点总数,tk为第k个驻留点的驻留时间;
[0047]
其次,构建强化学习剂量优化网络。
[0048]
设计强化学习网络的状态空间、动作空间和奖励函数,其中以每个驻留位置的驻留时间作为状态空间s,将对各驻留时间的调整动作设置作为动作空间a,奖励r的函数形式如式(7)。
[0049][0050]
基于式(8)对状态空间初始化。
[0051][0052]
之后,基于ppo(proximal policy optimization)算法建立剂量优化网络,算法的流程如图1所示,算法各步骤的具体内容为:
[0053]
(1)将状态空间s输入到actor-new网络,得到动作空间a的概率分布,再根据动作空间a的概率分布和先验知识引导的优化策略采样得到动作空间a;将动作空间a输入到环境env中得到奖励r和下一步的状态空间s_;将a、s和r存储到经验池buffer中;将s_输入到actor-new网络,循环步骤1,直至经验池buffer的存储量达一定值;
[0054]
(2)将上述步骤(1)循环完最后一步得到的s_输入到critic网络中,得到状态空间的价值v_,并结合存储的奖励r计算折扣奖励值r;
[0055]
(3)将存储的状态空间s输入到critic网络中,得到所有状态空间的v值,并计算a
t
=r-v;
[0056]
(4)根据l
bl
(θ)计算得critic网络的损失critic-loss,然后反向传播更新critic网络,l
bl
(θ)的表达式如下;
[0057][0058]
式中,γ
t
′‑
t
是t
′
时刻相对于t时刻的累计折扣因子,r
t
′
是t
′
时刻的奖励值,v
φ
(s
t
)是t时刻对应状态空间的价值,表示求均值;
[0059]
(5)将存储的所有状态空间s输入actor-new和actor-old网络,分别得到动作空间a的概率分布pi-new和pi-old,将存储的动作空间a输入到动作空间的概率分布中,得到每个动作空间a对应的概率prob1和prob2。
[0060]
(6)根据l
clip
(θ)计算得actor的损失actor-loss,并反向传播,更新actor-new网络,l
clip
(θ)的计算表达式如下:
[0061][0062]
式中,r
t
(θ)为pi-new与pi-old的比例,clip为裁剪函数,ε为裁剪因子,
[0063][0064]
(7)循环步骤(5)-(6),一定步后循环结束,用actor-new网络权重来更actor-old网络;
[0065]
(8)循环步骤(1)-(7),直至达到终止条件,优化完成。
[0066]
为验证本发明提出的基于强化学习的剂量优化算法的优化效果,利用20例宫颈癌
患者病例进行了回顾性实验,以比较本算法和模拟退火逆向优化算法(inverse planning simulated annealing,ipsa)的优化效果,比较结果如表1(ipsa与ppo剂量优化算法优化质量对比)。
[0067]
表1
[0068][0069]
由表1可以看出,相比于ipsa算法,ppo算法在保证靶区剂量覆盖率的同时,可以明显减少靶区的剂量热区,降低危及器官的剂量受量,提高剂量的均匀性和适形度,计划质量得以显著提升。
[0070]
以上显示和描述了本发明的基本原理和主要特征和本发明的优点,对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明;
[0071]
因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内,不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
[0072]
此外,应当理解,虽然本说明书按照实施方式加以描述,但并非每个实施方式仅包含一个独立的技术方案,说明书的这种叙述方式仅仅是为清楚起见,本领域技术人员应当将说明书作为一个整体,各实施例中的技术方案也可以经适当组合,形成本领域技术人员可以理解的其他实施方式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1