基于超图表征与狄利克雷分布的多组学关联表型预测方法
1.本发明属于生物信息技术领域,具体涉及一种基于超图表征与狄利克雷分布的多组学关联表型预测方法。
背景技术:
2.近年来,生物学相关技术得到了飞速发展,尤其是高通量测序在数量、速度、准确性、多样性和应用价值方面都有了突破性进展。人们能够以较以往更加高效低成本的方法获得相关组学数据,如dna、mrna和meth的研究可广泛地分为基因组学、转录组学和表观组学,这些数据的整合为各种人体表型的研究提供了多组学(multi-omics)集成研究的基础。另一方面,生物体的复杂性往往蕴含在这多种类型的数据中,由于针对每种组学的研究只能局限的发现生物复杂性的一部分,通过整合多组学数据,可以更好地理解生物体的复杂性,也可以更全面地观察生命科学过程。
3.表型是生物活动过程中可量化的特征表现,即在生物特定状态下可客观测评的某种特征性生化指标,如身高、肤色、疾病等等。传统统计学方法可利用人体血液、尿液等体液或组织中含有的基因、蛋白质等物质的检测结果,进行数据统计值的计算分析,对比设置好的阙值,得到相应组学的生物标志物推测,再根据生物标志物去推理待测数据的表型。如对样本数据使用gwas方法比对p值,研究与疾病相关的基因组学中的dna基因片段、snp位点等等。但是传统统计学方法挖掘的生物组学-表型关联性质有明显的局限性,一方面因为这种方法只针对每种组学内的单一标志物进行统计计算,然而多个低统计值的标志物也可能对表型起到决定性影响作用,因此并不能排除统计值低的标志物与表型的关联影响性。另一方面由于生物的调节过程是多层次的动态表达过程,因此,只针对单一组学的研究方法从根本上具有局限性,无法考虑到该组学的上下层次调控带来的影响性。
4.综上所述,生物信息研究有必要采用多组学综合的方法来充分利用这些数据以深入了解生物系统。随着计算机可承受计算能力和高通量组学数据的不断增加,以及人工智能技术在各个领域的成功,机器学习在生物领域的应用也变得流行。机器学习可以用来挖掘隐藏在实验数据中的信息。相比之下,传统的基于统计学的模型通常是使用统计假设设计而成,并从给定的数据集中对特定现象做出推断,而机器学习方法的目标是从历史或现有的数据中学习知识,并利用这些知识对未知的新数据进行预测或选择。例如,xu等人开发了hi-dfnforest(分层集成深度柔性神经森林)框架,它使用堆叠式自动编码器从三个组学数据集中学习高级特征表示,这些表示同时被整合来预测癌症亚型。wang等人提出的mogonet针对每个组学数据构造图结构,利用图卷积神经网络进行初始预测,再通过多视图集成网络vcdn进行整合实现了多组学集成表型分类。然而,上述方法无论从预测准确度还是模块设计构成方面都仍有提升空间。
技术实现要素:
5.为了解决上述问题,本发明提出了一种基于超图与狄利克雷分布的人体表型与组
学数据的关联预测方法。该方法首先通过预处理模块对原始数据进行清洗筛选,其次通过多个组学数据集组成的联合数据矩阵开发了基于超图结构表征的神经网络模型,针对多个组学数据集进行超图结构表征,表征过程采用了基于余弦相似度的knn(k-nearest neighbor)算法,深入挖掘了组学内不同位置信息间的关联性。然后表征数据通过超图卷积神经网络进行高效的特征提取,同时该超图神经网络也支持实现单组学与表型间的关联预测。最后以此特征矩阵为基础组成多组学联合矩阵构建基于狄利克雷分布的多组学(两种及两种以上)融合算法,利用狄利克雷分布构建损失函数完成各个组学间的信息集成,并以此为逻辑基础,实现组学间的信息共享从而对人体表型情况进行精准预测。
6.为了达到上述目的,本发明的具体技术方案如下:
7.一种基于超图表征与狄利克雷分布的多组学关联表型预测方法,步骤如下:
8.步骤(1)组学数据清洗与预处理
9.各组学数据需要通过常规预处理方法剔除原始数据中的冗余噪声,如针对mirna组学数据仅保留芯片检测成功率至少为95%的数据;对于meth组学数据计算归一化的beta值作为每个甲基化位点的表达水平。筛选后的数据仍可能包含对预测性能产生负面影响的冗余特征或噪声。为了解决这个问题,通过以下方法进行特征的预选择。
10.首先,过滤掉数据集中方差小于阙值α的特征。
11.其次,针对每种表型标签依次执行公式(1)的t假设检验同类标签的各样本组学数据间是否存在显着差异,t值大于阙值γ的样本做删除处理,其中为样本均值,μ代表样本期望,σ(x)表示样本的标准差,n表示样本数。
[0012][0013]
最后,因为不同的组学数据类型具有不同的表达范围,通过线性变换将表达值进行缩放至[0,1],以便模型进行运算处理,该步骤输出为预处理的特征矩阵x。
[0014]
步骤(2)构建组学数据的超图结构
[0015]
(2.1)一个超图定义为g=(v,e,w),由顶点集v={v1,v2,
…
,vm}和超边集e={e1,e2,
…
,e
l
}组成,w是超边的权矩阵,代表每条超边的重要程度。在超图中,每个顶点对应于一个样本,每个超边包含了v的任意子集。通过对步骤(1)输出的特征矩阵x进行余弦相似度运算来衡量组学内特征间关系。
[0016]
传统超图结构的构建方法往往采用公式(2)的欧氏距离计算向量间直线距离,以此衡量不同样本间接近程度,由于欧氏距离更适合体现数值上的绝对差异,并不完全契合组学数据中特征间隐含的关联作用。在本发明中,将不同样本视为不同向量,并使用公式(3)获得余弦相似度度量矩阵以向量间角度差异衡量其近似程度。其中,xi代表特征矩阵x中第i例样本的具体特征向量,x
ir
代表特征矩阵x中第i例样本的第r项特征数值,r代表特征数量总数。这种方法理论上更符合组学内的作用规律,并且通过对照实验已证明了这一方法的应用效果。
[0017]
[0018][0019]
(2.2)根据得到的余弦相似度度量矩阵对样本进行knn聚类。由于向量间的余弦值随着角度增大而减小。因此,在本发明中的knn聚类过程会返回相似度矩阵中每行最大的k个值的索引,这些索引构成该超图顶点的超边集合e,并将这k个索引在矩阵中置为1,其余索引则置为0。以此构造出矩阵h可以表示为超图g的关联矩阵,定义为:
[0020][0021]
以此延伸,顶点的度dv定义为:
[0022][0023]
其中w(e)为该超边在权矩阵中所占权重,超边的度de定义为:
[0024][0025]
步骤(3)搭建超图卷积神经网络进行单组学的特征提取:
[0026]
(3.1)首先根据拉普拉斯标准化公式构建超图关联矩阵的拉普拉斯矩阵,将超图内的抽象节点关系转化为能够作为神经网络输入的矩阵类型,传统图结构的拉普拉斯矩阵构造方法为:
[0027][0028]
其中i为单位阵,d为图中顶点的度,a为图结构的邻接矩阵。
[0029]
同理,针对步骤(2)所构成的超图结构的拉普拉斯矩阵定义为:
[0030][0031]
其中dv为公式(5)得到的超图的顶点度矩阵,de为公式(6)得到的超边度矩阵,h为公式(4)得到的关联矩阵,对于没有给出特定权值矩阵w的数据集默认将其定义为单位阵i,意味着所有超边的权值相等。
[0032]
(3.2)将单种组学数据的超图拉普拉斯矩阵与预处理过的特征数据作为输入到超图卷积神经网络以执行初始预测任务。每个超图卷积神经网络的训练目标是学习输入数据与对应标签的关联关系,具体来说,模型需要以下两个输入:其中一个输入是步骤(1)的结果即预处理的特征矩阵,x∈n
×
d,其中n是样本数量,d是组学特征的数量。另一个输入是超图结构的描述,即公式(8)得到的超图拉普拉斯矩阵lh∈n
×
n。
[0033]
超图卷积神经网络(hypergraph convolutional network,hgcn)模型结构通过堆叠3个卷积层与1个全连接层来构建,卷积层的维数根据特征矩阵x的维数设立,全连接层的输出维度为标签类别数。卷积层的具体定义为:
[0034]
hgconv
(l+1)
=f(hgconv
(l)
,lh)
[0035]
=σ(lh(hgconv
(l)
)z
(l)
)
ꢀꢀꢀ
(9)
[0036]
式中hgcconv
(l)
为第l层的输出,z
(l)
为第l层的权矩阵,当l=0时,hgconv
(l)
=x。σ(
·
)为该隐藏层的激活函数,在本方法中设置为leakyrelu函数,其中k为该激活函数的负斜率参数,用来解决神经元失效导致的梯度消失问题:
[0037][0038]
前两层卷积层后添加了dropout机制,以降低模型过拟合的可能性。第三个卷积层后连接的全连接层实现特征整合。模型的输出fo作为特征提取结果,fo∈n
×
b,其中n是样本数,b为标签种类数量。
[0039]
同时,本发明还支持通过hgcn对单组学数据进行对应表型的预测,即通过单个hgcn的反向传播过程,利用交叉熵损失函数训练该网络:
[0040][0041]
其中loss
ce
(
·
)表示交叉熵损失函数,y为样本标签。根据损失值loss
hgcn
计算梯度,并更新网络权重z完成反向传播过程,经过数次迭代训练过程后保存的模型可实现对单组学数据与表型的关联预测。
[0042]
步骤(4)基于狄利克雷分布的多组学集成算法:
[0043]
对每种组学数据分别使用步骤(3)构造对应的hgcn,针对每个神经网络输出的特征结果矩阵fo∈n
×
b,结合公式(12)首先构造fo的狄利克雷分布参数矩阵αo,α
ijo
代表αo的每个元素。据此参数计算fo中每个元素f
ijo
的可信度p
ijo
组成矩阵po,以及该组学下预测结果的不确定性参数u
io
组成向量uo:
[0044][0045][0046]
αo=fo+1
ꢀꢀꢀ
(12)
[0047]
基于上述步骤得到的单组学预测结果的可信分布矩阵po与不确定性向量uo进行多组学的融合预测。该过程采用经典d-s证据理论,即公式(13)的方式,实现组学间的两两信息融合:
[0048][0049][0050]
式中pi代表矩阵p的第i行,m设置为不小于0的值,具体来说当m=0时,公式实现的是p0、u0(第一种组学预测结果)与p1、u1(第二种组学预测结果)的融合,得到p2、u2作为两种
组学的融合结果;当m=1时,公式实现的是p2、u2(前两种组学融合结果)与p3、u3(第三种组学预测结果)的融合,得到p4、u4作为三种组学的融合结果。多组学融合方式以此类推,直到完成所有组学的融合得到p
2m+2
、u
2m+2
。
[0051]
待所有种类组学融合完成后,根据公式(12)反向推导出多组学融合条件下的狄利克雷分布参数α及融合预测结果f。
[0052]
最后进行多组学融合预测的训练学习,与公式(11)的计算交叉熵方法不同,采用公式(14)计算融合损失。
[0053]
loss
moia
=loss
right
+λ
epoch
loss
wrong
[0054][0055][0056][0057][0058][0059]
其中,loss
right
为正确标签损失函数,loss
wrong
为错误标签损失函数,loss
moia
为总损失函数;λ
epoch
为根据当前已训练次数动态变化的损失权重,取值在(0,1)之间;k代表标签的某一具体种类的编号;yi代表样本标签的one hot编码中第i例样本的标签集合,y
ij
代表one hot编码中第i例样本的第j种标签代表的元素;αi为第i个样本的狄利克雷分布参数集合,α
ij
代表第i个样本的第j种分类结果的狄利克雷分布参数估计值;γ(
·
)为伽马函数,式中t为定积分参数。这种方法充分利用了狄利克雷分布参数估计α,通过计算loss
right
使得模型对正确标签的预测根据尽量增大,计算loss
wrong
能够使错误标签的预测根据进一步减少,loss
moia
从两方面优化提升模型精度。损失值用来进行梯度计算,完成反向传播过程,更新超图卷积神经网络的神经元权重。训练好的模型能够既基于特定组学信息,又基于跨组学关联学习进行表型的精准预测。
[0060]
本发明的有益效果:
[0061]
(1)设计的超图数据结构作为输入数据类型,与传统图结构相比能够对包含多向关系的数据进行更高保真度的表示,并据此构建超图卷积神经网络,充分结合原始特征与超图表征对组学内不同特征之间的关联性进行挖掘。
[0062]
(2)提出基于狄利克雷分布的多组学集成算法,有效的利用不同层次下生物特征的互补关系,进一步提升人体组学-表型潜在未知的关联关系。可以帮助人们更好地理解生物动态调节地过程,并且在疾病检测、分型以及风险预测方面都可以提供更加全面的理论支撑。
附图说明
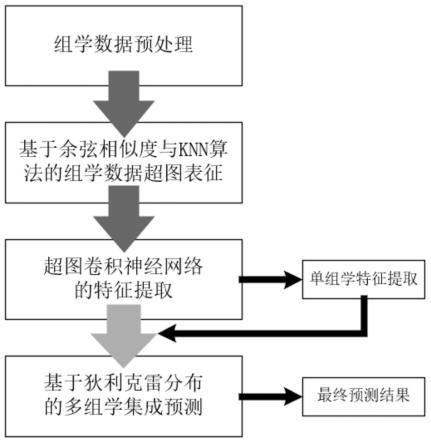
[0063]
图1是本发明的整体架构图。
[0064]
图2是本发明实现多组学表型关联预测的框架图。
[0065]
图3是本发明的整体流程图。
具体实施方式
[0066]
以下结合附图和技术方案,进一步说明本发明的具体实施方式。
[0067]
如图1所示,本发明的一种基于超图表征与狄利克雷分布的多组学关联表型预测方法,大致可分为:组学数据预处理、组学数据超图表征、超图神经网络的特征提取和多组学集成预测四个模块;
[0068]
(1)预处理模块涉及原始组学数据清洗与特征预筛选:针对每种类型的组学数据分别进行预处理操作,以去除可能影响关联挖掘性能的噪声、错误和冗余特征,为后续模型算法起到更好地理解与支撑作用。首先,对于各个组学数据过滤没有探针信号或低差异(平均值接近0)的特征。因为不同的组学数据类型具有不同的表达范围,选择通过线性变换将表达值进行缩放,以便模型进行运算处理。
[0069]
(2)组学数据超图表征模块涉及余弦相似度计算与knn聚类过程:针对每种组学预处理后的特征数据,首先计算不同样本间特征数据的余弦相似度矩阵,随后根据knn算法筛选出与每个超图节点的余弦值最大的k例样本,最后将输出的最相似样本索引在矩阵中置1,其余索引置0完成超图关联矩阵的构建。
[0070]
(3)超图神经网络的特征提取模块实现神经网络的搭建与特异性训练过程:根据超图拉普拉斯标准化公式构建超图结构的拉普拉斯矩阵,实现将超图内的抽象节点关系转化为能够作为神经网络输入的矩阵类型。结合预处理过的特定组学特征矩阵分别搭建超图卷积神经网络(hgcn),以组学预处理特征矩阵及相应的超图拉普拉斯矩阵作为hgcn的输入,进行组学与表型相关联的特异性学习。hgcn的主要优点在于可以很好的结合组学数据中样本之间的潜在相关性来实现更高效的特征提取。
[0071]
(4)多组学集成预测模块根据每个hgcn模型的输出构造狄利克雷分布参数,从而设计不同于传统交叉熵的损失函数进行最终标签预测学习。多组学集成算法(moia)首先为每个组学的狄利克雷分布参数计算其不确定性,并通过经典d-s组合规则挖掘不同组学间的潜在相关性,有效地集成了每个组学特定网络提取的特征。
[0072]
如图3所示,以tcga的brca多组学数据集进行乳腺癌亚型的关联预测为例,步骤如下:
[0073]
(1)首先按照预处理步骤的路线针对各组学数据进行特征筛选,保留与表型标签高度相关的特征,以tcga开源数据库中获得的brca表型相关的三种组学数据(甲基化、mrna与mirna数据)为例,过滤mirna与mrna数据中样本调用保留率小于5%的特征;对于甲基化数据,计算归一化的beta值作为每个甲基化位点的甲基化水平。其次,过滤掉训练数据集中方差小于0.3的特征。
[0074]
同时,对于每个标签预测任务,依次执行公式(1)中的t检验评估该样本数据是否与其他同标签数据间存在显着差异,差异过大的样本做删除处理,并通过线性变换来将每种类型的组学数据缩放到[0,1]的范围内。
[0075]
(2)将预处理筛选过的组学数据表征为超图结构。如图2所示,即对特征矩阵数据进行关联矩阵与超图拉普拉斯矩阵的构建,根据公式(3)计算单组学数据的余弦相似度矩阵,并筛选矩阵每行中余弦值最大的k=10个索引,以此构建超图g的关联矩阵,并通过公式(8)得到该超图的拉普拉斯矩阵。
[0076]
(3)将单个组学的特征矩阵与拉普拉斯矩阵分别输入到超图卷积神经网络(hgcn)进行特征提取。如图2所示,为每种组学分别搭建hgcn,每个hgcn利用每种组学节点的特征和节点间的关联关系来学习超图表征的特征,在该实例中原始特征的维数为1000*612,分类标签数为5种,因此将隐藏层维数分别设为400,400,200,输入层维数为1000,输出层维数为5。具体神经网络的运算过程参考公式(9-10),同时,前两层卷积层后添加参数为0.5的dropout机制,以降低模型过拟合的可能性。
[0077]
(4)上述步骤中每个组学对应hgcn的结果再作为输入到多组学集成算法(moia)进行最终整合预测,moia可以揭示潜在的跨组学标签相关性,首先基于公式(12)构造狄利克雷分布参数,引用如公式(13)的经典d-s证据理论,实现组学之间的两两信息融合。所有种类的组学数据融合结束后,利用公式(14)的损失函数以反向传播方式训练超图卷积神经网络。最终输出的关联预测结果既基于特定组学信息,又基于跨组学关联学习进行预测。得到的结果如图2最终输出所示,为n*5的张量(n为样本数),每行的5个参数分别代表该样本患brca的五种亚型(normal-like、basal-like、her2-enriched、luminal a与luminal b)的概率分布,概率最大的数值代表最终预测结果。
[0078]
(5)在相同数据集下进行了多组对照试验进行效率对比,证明了该发明方法优于其他现存方法。部分对照实验如下:
[0079]
i、与2021年发表在nature communication的mogonet方法进行对比,单组学预测准确率(acc)超过该方法0.06-0.09,多组学集成预测准确率(acc)超过该方法0.04(该方法为0.8289,本发明为0.8670),同时参考mogonet论文中的实验部分内容,可知本发明准确率远超其他常规机器学习方法。
[0080]
ii、在hgnn上的单组学预测准确率分别为:mrna(0.8517)、meth(0.7871)、mirna(0.8061),采用moia集成后的预测准确率为0.8670,证明了moia模块的集成有效性。
[0081]
iii、在超图构造方法上作对比实验,与传统欧氏距离方法构造的超图结构相比,本发明采用的余弦相似度方法构造的超图结构使最终预测准确率提升了0.02-0.04,证明了采用余弦相似度方法的有效性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1