一种血压测量装置的制作方法
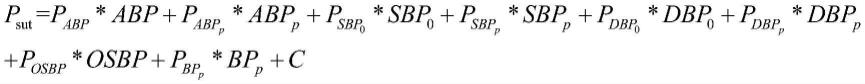
1.本发明涉及血压测量装置,具体为一种基于回归模型的血压测量装置。
背景技术:
2.血压是人体的一项重要生理参数,在临床诊断中具有十分重要的价值。
3.目前,市面上的大多数电子血压计都是通过示波法进行血压测量,再通过识别平均压(abp)进而利用系数公式推导出相应的舒张压(dbp)与收缩压(sbp)。对于不同的电子血压计,这个推算公式可以进行各种演变,最终得到一个更加适用于当前电子血压计的数学关系。
4.但是在实际应用中,上述数学关系并不只是单一线性变换公式,从脉搏波信号中提取的特征值不同,经过相同逻辑的变换公式得到的血压值也会大不相同,需要考虑多种因素的不同影响,因此如何处理获取的原始信号并从原始信号中得到准确的血压值变得更加难和更加必要。
技术实现要素:
5.本发明的目的是为了提供一种血压测量装置,通过建立合适的回归模型,兼顾脉搏波信号中多种形态特征的影响,保证血压测量装置得到的测量结果更加准确。
6.为了实现上述发明目的,本发明采用了以下技术方案:一种血压测量装置,包括压力气囊、压力传感器和数据处理器,压力气囊压迫血管的同时,所述压力传感器采集原始压力信号,并将所述原始压力信号传递给所述数据处理器;所述数据处理器采用如下方法处理原始压力信号并获得血压值:从所述原始压力信号中分离出脉搏波信号;从所述脉搏波信号中提取特征值;将所述特征值作为回归模型的输入,得到血压值。
7.原始压力信号是由直流压力信号与交流的脉搏波信号叠加而成的,通过滤波处理将二者分离,直流部分用于实际压力值的对照,交流部分用于脉搏波特征提取。脉搏波信号提取出来后从所述脉搏波信号中获取特征值,将所述特征值作为回归模型的输入,得到血压值。
8.优选的,特征值从脉搏波信号中提取,主要为脉搏波特征、压力特征以及时间位置特征,具体的,包括但不限于以下任意一种或多种的组合:
9.(a)abp:最大压力值,脉搏波信号中震荡幅值最大时对应的压力值;
10.(b)abp
p
:最大压力值的位置,abp所在的时间点abp
t
和采样频率fs的乘积,即abp
p
=abp
t
*fs;
11.(c)sbp0:收缩压参考压力值,为脉搏波信号中最大压力值abp的比例振幅对应压力值,即sbp0=abp*s
sbp
,其中,s
sbp
为收缩压比例系数;
12.(d)sbp
p
:收缩压参考压力值的位置,在脉搏波信号中位于最大压力值abp后的下降段中,sbp0所在的时间点sbp
t
和采样频率fs的乘积,即sbp
p
=sbp
t
*fs;
13.(e)dbp0:舒张压参考压力值,为脉搏波信号中最大压力值abp的比例振幅对应压
力值,即dbp0=abp*s
dbp
,其中,s
dbp
为舒张压比例系数;
14.(f)dbp
p
:舒张压参考压力值的位置,脉搏波信号中位于最大压力值abp前的上升段中,dbp0所在的时间点dbp
t
和采样频率fs的乘积,即dbp
p
=dbp
t
*fs;
15.(g)osbp:对称参考压力值,在脉搏波信号中位于最大压力值abp前的上升段中,最大压力值abp的比例振幅对应的压力值;
16.(h)bp
p
:气囊补偿气压值,当压力气囊达到补偿点时的压力值,所述补偿点的位置通过脉搏波信号中的脉搏波数量和振幅确定。
17.优选的,所述回归模型采用多元线性回归模型。多元线性回归是针对一个因变量由多个自变量决定的情况,即
18.h
θ
(x1,x2,...xn)=θ0+θ1x1+...+θnxn19.在本模型中,采用均方误差作为损失函数,即
[0020][0021]
其中m为样本的个数,n为样本的特征数,为真实值。
[0022]
优选的,所述回归模型也可以采用支持向量机回归模型。使用支持向量机回归模型(svm回归模型)寻找一个超平面使得样本点尽量拟合到一个线性模型上,即
[0023]
yi=ω
t
xi+b
[0024]
在本模型中,采用误差函数ε作为损失函数,如果预测值yi与真实值之间的差值则不产生损失;否则损失代价为
[0025]
优选的,所述回归模型采用随机森林回归模型。随机森林回归模型通过决策树作为弱学习器,经过多次迭代后,输出最终的强学习结果。
[0026]
假设输入数据集d={(x1,y1),(x2,y2),...(xj,yj)},弱分类器多次迭代,次数为t,进而输出为最终的强分类器。
[0027]
在本模型中,对于t=1,2,
…
,t时,对训练集进行第t次随机采样,共采集j次,得到包含j个样本的采样集dj;用采样集dj训练第j个决策树模型gj(x),在训练决策树模型的节点的时候,在节点上所有的样本特征中选择一部分样本特征,在这些随机选择的部分样本特征中选择一个最优的特征来做决策树的左右子树划分。如果本模型采用分类算法预测,则t个弱学习器投出最多票数的类别或者类别之一为最终类别。如果是回归算法,t个弱学习器得到的回归结果进行算术平均得到的值为最终的模型输出。随机森林回归模型的算法可以根据实际需求进行选择。
[0028]
优选的,所述回归模型采用以下训练方法:
[0029]
数据采集:通过所述血压测量装置获取测试数据,通过水银血压计获取参考数据;一测试数据和相对应的一参考数据为组合数据,采集组合数据s组;
[0030]
其中,一组组合数据内的测试数据和参考数据来自同一血压测量者,所述测试数据为原始压力信号,所述参考数据包括参考舒张压值和参考收缩压值;
[0031]
数据处理:从所述测试数据中分离,得到每组测试数据中的脉搏波信号;
[0032]
特征值提取:从s组脉搏波信号中,分别提出单个或者多个所述特征值;
[0033]
数据集筛选:将所述参考数据中的舒张压值和收缩压值作为标签值,所述标签值与组合数据中相应的特征值相对应,将在s组相应的特征值与标签值按比例筛选出训练集和测试集。
[0034]
优选的,所述训练方法中的所述数据集筛选后,还包括预测效果验证:将每组组合数据中的特征值作为回归模型的输入,得到预测血压值,所述预测血压值包括预测舒张压值和预测收缩压值;根据不同组中预测血压值和所述参考血压值判断所述回归模型的预测效果。
[0035]
优选的,所述预测效果验证还包括:通过s组数据得出s组血压误差值:所述预测血压值与所述参考数据的差值为血压误差值,其中,所述预测舒张压和所述参考舒张压的差值为舒张压误差值,所述预测收缩压和所述参考收缩压的差值为收缩压误差值;根据所述误差值的平均值和/或标准差判断回归模型的预测效果。
附图说明
[0036]
图1为本发明血压测量流程图。
[0037]
图2为原始压力信号分解图。
[0038]
图3为多元线性回归模型的训练效果图。
[0039]
图4为多元线性回归模型的预测效果图。
[0040]
图5为支持向量机回归模型的训练效果图。
[0041]
图6为支持向量机回归模型的预测效果图。
[0042]
图7为随机森林回归模型的训练效果图。
[0043]
图8为随机森林回归模型的预测效果图。
具体实施方式
[0044]
下面结合附图对本发明做进一步描述。
[0045]
第一部分:血压测量过程中的数据处理
[0046]
如图1所示的血压测量装置,包括压力气囊、压力传感器和数据处理器,压力气囊压迫血管的同时,压力传感器采集原始压力信号,并将原始压力信号传递给数据处理器;数据处理器采用如下方法处理原始压力信号并获得血压值:原始压力信号是由直流压力信号与交流的脉搏波信号叠加而成的,通过滤波处理将二者分离,如图2所示,直流部分用于实际压力值的对照,交流部分用于脉搏波特征提取。
[0047]
脉搏波信号中获取特征值,将特征值作为回归模型的输入,所提取的特征主要包括以下八个特征值中的一种或者任意多种的组合。特征值如下:
[0048]
(a)abp:最大压力值,脉搏波信号中震荡幅值最大时对应的压力值;
[0049]
(b)abp
p
:最大压力值的位置,abp所在的时间点abp
t
和采样频率fs的乘积,即abp
p
=abp
t
*fs;
[0050]
(c)sbp0:收缩压参考压力值,为脉搏波信号中最大压力值abp的比例振幅对应压力值,即sbp0=abp*s
sbp
,其中,s
sbp
为收缩压比例系数;
[0051]
(d)sbp
p
:收缩压参考压力值的位置,在脉搏波信号中位于最大压力值abp后的下
降段中,sbp0所在的时间点sbp
t
和采样频率fs的乘积,即sbp
p
=sbp
t
*fs;
[0052]
(e)dbp0:舒张压参考压力值,为脉搏波信号中最大压力值abp的比例振幅对应压力值,即dbp0=abp*s
dbp
,其中,s
dbp
为舒张压比例系数;
[0053]
(f)dbp
p
:舒张压参考压力值的位置,脉搏波信号中位于最大压力值abp前的上升段中,dbp0所在的时间点dbp
t
和采样频率fs的乘积,即dbp
p
=dbp
t
*fs;
[0054]
(g)osbp:对称参考压力值,在脉搏波信号中位于最大压力值abp前的上升段中,最大压力值abp的比例振幅对应的压力值;
[0055]
(h)bp
p
:气囊补偿气压值,当压力气囊达到补偿点时的压力值,补偿点的位置通过脉搏波信号中的脉搏波数量和振幅确定。
[0056]
将上述特征值输入回归模型中,回归模型可以采用多元线性回归模型、支持向量机回归模型和随机森林回归模型中的一个模型单独或者多个模型结合的方式对特征值进行处理,得到相应的计算结果。
[0057]
上述三个不同的回归模型对特征值的处理公式或者基本处理原理如下:
[0058]
多元线性回归模型:
[0059][0060]
其中,p
xx
为各特征对应的权重系数(如:p
abp
为abp对应的权重系数),c为常数项。
[0061]
支持向量机回归模型:
[0062]
(1)为模型寻找最佳参数,包括惩罚函数c以及rbf核参数g;
[0063]
(2)通过训练集和最佳参数训练出svm回归模型,将模型保存用于预测。模型中包含svm的重要参数,如支持向量及其系数、决策函数、核函数类型、迭代次数等;
[0064]
(3)将预测集数据与模型参数用于预测函数中,最终输出预测结果。
[0065]
随机森林回归模型:
[0066]
(1)利用训练集数据训练随机森林模型,并且可以自定义树的数目ntree以及每一个分裂节点处样本预测器的个数mtry;
[0067]
(2)训练好模型后,随机森林模型会对特征的重要性进行评估,得出重要性因子,以便模型对样本数据进行更好的评估;
[0068]
(3)最后将测试集数据放入模型中进行预测,得到最后的回归结果。
[0069]
以上为本实施例中的血压测量装置在实际血压检测过程中,对原始压力信号的处理和计算方法。
[0070]
第二部分:回归模型的训练方法
[0071]
下面对本实施例中的回归模型的训练方法进行描述。
[0072]
回归模型的训练方法主要包括数据采集、数据处理、特征值提取、数据集筛选和预测效果验证。
[0073]
数据采集:通过血压测量装置获取测试数据,通过水银血压计获取参考数据;一测试数据和相对应的一参考数据为组合数据,采集组合数据s组;其中,一组组合数据内的测试数据和参考数据来自同一血压测量者,测试数据为原始压力信号,参考数据包括参考舒张压值和参考收缩压值。
[0074]
在本实施例中,有88名血压测量者的血压数值参与模型的训练,测量时对同一血压测量者进行三组数据的采集,即每位血压测量者需要分别进行三次水银血压计测量和三次的本实施例的血压测量装置测量,最终采集数据264组。
[0075]
数据处理:对每组组合数据中的测试数据,也就是原始压力数据进行滤波等处理,得到脉搏波信号。
[0076]
特征值提取:从脉搏波信号中提出去上述8个特征值。
[0077]
数据集筛选:一组数据包含8个特征值和相对应的标签值,标签值为组合数据中的参考数据,利用kennard-stone算法对本实施例的264组数据进行筛选,同时结合在数据采集过程中的未经处理的264组组合数据,以2:1选择训练集与测试集,故60%为训练集,40%为测试集对回归模型进行训练。
[0078]
预测效果验证:为了保证回归模型的预测值的有效性以及特征的相关性,需要对预测结果进行验证。将数据集中每组数据中的特征值作为回归模型的输入,得到预测血压值,预测血压值包括预测舒张压值和预测收缩压值;根据不同组中预测血压值和参考血压值判断回归模型的预测效果。
[0079]
其中,预测效果验证还包括:通过s组数据得出s组血压误差值:预测血压值与参考数据的差值为血压误差值,其中,预测舒张压和参考舒张压的差值为舒张压误差值,预测收缩压和参考收缩压的差值为收缩压误差值;根据误差值的平均值和/或标准差判断回归模型的预测效果。
[0080]
收缩压为sbp,舒张压为dbp。
[0081]
下面针对不同的回归模型,分别进行预测效果验证的详细描述。
[0082]
在多元线性回归模型中,使用上述数据集进行拟合,多元线性回归模型中sbp的验证的结果如下:
[0083]
r2=0.5999;
[0084]
f=27.9283;
[0085]
p=3.788152001481342e-26
[0086]
其中,r2表征拟合优度,可以表现回归函数学到样本参考值的学习率,其值越接近1,说明拟合效果越好,在该回归模型中约为60%,程度较好;f表示显著性检验,其值越大,说明回归越显著;p值表征接受回归方程后,出错的概率的大小,在该回归模型中p值极小,说明拟合效果很好。
[0087]
多元线性回归模型中dbp的验证的结果如下:
[0088]
r2=0.5381;
[0089]
f=21.6964;
[0090]
p=1.230098291834975e-21
[0091]
此三个参数意义同上所述,在该回归模型中,r2约为54%,学习率适中;p值极小,拟合较好。
[0092]
为第i组数据中的参考数据中的血压值,为第i组数据的预测血压值,则第i组的血压误差值xi为以误差值的平均值和标准差作为回归模型预测效果的验证标准。
[0093]
其中,平均值计算公式如下:
[0094][0095]
标准差的计算公式如下:
[0096][0097]
根据上述公式,计算出多元线性回归模型的预测效果如下:
[0098]
mean_sbp_train:-1.7359e-14;std_sbp_train:8.48
[0099]
mean_dbp_train:-2.6983e-15;std_dbp_train:7.44
[0100]
mean_sbp_test:1.63;std_sbp_test:7.39
[0101]
mean_dbp_test:1.35;std_dbp_test:6.53
[0102]
其中,mean_sbp_train为训练集sbp误差平均值;std_sbp_train为训练集sbp误差标准差;mean_dbp_train为训练集dbp误差平均值;std_dbp_train为训练集dbp误差标准差;mean_sbp_test为测试集sbp误差平均值;std_sbp_test为测试集sbp误差标准差;mean_dbp_test为测试集dbp误差平均值;std_dbp_test为测试集dbp误差标准差。
[0103]
图3为多元线性回归模型在训练集数据中的学习效果,图4为多元线性回归模型在测试集数据中的预测效果。从上述结果可以看出,在多元线性回归模型中,其平均误差很小,具有较好的血压值的预测效果。
[0104]
在支持向量机回归模型(svm回归模型)中,需要先将数据进行归一化处理,再进一步筛选最佳参数(c和g)。其中c表示惩罚参数,g表示核函数参数。默认惩罚参数c的范围是[2^(-8),2^8],默认rbf核参数g的范围是[2^(-8),2^8]。
[0105]
sbp的svm回归模型中,最佳参数c=0.5,g=0.25;dbp的svm回归模型中,最佳参数c=8,g=0.25。
[0106]
确定好最佳参数后,利用训练集数据进行模型训练,再将模型用于测试集上验证。
[0107]
sbp模型训练的结果:mse=0.0167(regression);r2=0.5970(regression);
[0108]
dbp模型训练的结果:mse=0.0159(regression);r2=0.6426(regression);
[0109]
sbp模型预测的结果:mse=0.0131(regression);r2=0.5452(regression);
[0110]
dbp模型预测的结果:mse=0.0160(regression);r2=0.4304(regression)。
[0111]
其中,mse为均方误差(mean squared error),r2为平方相关系数(squared correlation coefficient),相关公式如下:
[0112][0113][0114]
其中,n为样本量,f(xi)为第i个样本的预测值,yi为第i个样本的参考值。
[0115]
从上述数据可得出,svm回归模型在训练集数据中的相关性更高,其平方相关系数
在0.6左右甚至以上,具体结果如图5所示。而测试集数据中的相关性略低。但均方误差均较小,说明模型拟合效果较好,具体结果如图6所示。
[0116]
同时,与多元线性回归方程相同,以平均值和标准差作为分析标准,其结果如下:
[0117]
mean_sbp_train:-0.31;std_sbp_train:8.56
[0118]
mean_dbp_train:-0.64;std_dbp_train:6.55
[0119]
mean_sbp_test:1.42;std_sbp_test:7.46
[0120]
mean_dbp_test:0.80;std_dbp_test:6.57
[0121]
对于训练集的训练过程,平均误差较小,sbp标准误差8.6,dbp标准误差6.6;在测试集中的验证结果显示,其平均误差也较小,标准误差均在7.5以内,得到一个较好的预测结果。
[0122]
在随机森林回归模型(rf回归模型)中,有关sbp,经过参数寻优,最佳决策树数目为50,且二叉树的变量个数为2,所用8个特征的重要性分别为:
[0123]
18.81;20.58;18.79;19.67;19.62;18.43;18.01;18.94
[0124]
其对应的特征顺序为:
[0125]
abp,sbp0,dbp0,osbp,bp
p
,sbp
p
,abp
p
,dbp
p
(下同)。
[0126]
在dbp的回归模型中,经过参数寻优,最佳决策树数目为100,且二叉树的变量个数为2,所用8个特征的重要性分别为:
[0127]
16.82;20.06;19.98;21.00;19.46;17.21;17.85;19.62
[0128]
可以看出,利用rf回归模型,每一个特征的重要性系数比较平均,说明在该模型中,特征的重要性相当,且都为较好的回归特征。因此该回归模型在训练集上表现出很好的学习效果,如图7所示。
[0129]
在测试集中就出现了较大的偏差,这也是rf回归模型存在的一个主要缺点,即可能产生过拟合现象,主要原因可能是受到特征共线性的影响且总体数据量较小。即便在数据归一化处理后,该现象仍然存在,如图8所示,回归结果在测试集中的表现不如训练集。其平均误差与标准误差如下所示:
[0130]
mean_sbp_test:1.64;std_sbp_test:9.65
[0131]
mean_dbp_test:1.68;std_dbp_test:8.11
[0132]
在实际建立回归模型的过程中,可以采用上述方法对不同的回归模型的预测效果进行检验。针对使用不同的特征值,可以通过相应的误差值的平均值和/或标准差来进行验证,以选择最优选的回归模型用于预测血压值。
[0133]
在本实施例的上述计算结果中可以看出,多元线性回归模型与svm回归模型均表现出较好的预测结果,而rf回归模型容易出现过拟合现象。同时多元线性回归模型与svm回归模型中,对于特征值与标签值之间的相关性基本接近,并且在建立rf回归模型时,各个特征也表现出十分接近的特征重要性。因此,也可以通过回归模型的验证过程中看出,上述8个特征值在血压计算中起着十分重要的作用,与血压之间存在一定的相关性,且与sbp的相关性高于其与dbp的相关性。
[0134]
第三部分:血压测量结果
[0135]
在本实施例中,将多元线性回归模型运用到实际测试中,测试过程按照前期回归模型训练时的采集标准,同一人采集3组组合数据,通过血压测量装置获取测试数据,通过
水银血压计获取参考数据。85人一共测得255组完整数据。
[0136]
采用前述公式进行最终测试结果为:
[0137]
sbp平均误差:1.88;sbp标准误差:8.76;dbp平均误差:2.02;dbp标准误差:7.36。
[0138]
测试结果与前期建立的模型预测结果基本一致,所选特征值与参考血压值存在一定的相关性。故在本技术实施例中利用所选取的8个特征,能够预测出较为准确的血压值。
[0139]
以上是本发明的优选实施方式,对于本领域的普通技术人员来说不脱离本发明原理的前提下,还可以做出若干变型和改进,这些也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1