一种病例异常检测方法及设备与流程
1.本发明涉及病例异常检测技术领域,具体涉及一种病例异常检测方法及设备。
背景技术:
2.在2021年5月21日国家远程医疗与互联网医学中心和健康界联合发布了《2021中国互联网医院发展报告》,其中指出,近年来我国互联网医院发展较为迅速,服务模式逐步丰富,“互联网”和“医院”两大元素的融合进一步加速。
3.不论是心脏病、胃癌或是其他高发生率的疾病,它们都具有较高的研究价值。随着互联网的发展,医院更趋向于智能化建设。电子化存储的医学病例是一种十分宝贵的资源,电子医学病例的填报内容可以被再次利用,一定的异常检测和可解释性分析有助于医生诊断病情和深入研究病理。以往的异常病例判断更依赖于医生的专业能力,对病症进行分析,根据自己掌握的专业知识,对前来问诊的患者给出自己的判断;而对于致病因素复杂的病例,需要研讨商榷给出解释。当经验不足的医生面对没有充分把握的病况或者医生在疲劳状态下,面对患者刚刚做好的一份体检报告,对于病情的诊断可能会产生偏差,从而造成或大或小的误诊。用于存档的电子病例,包括医生给出的诊断结果、病症等,可以通过人工智能的方法,采用特定的处理流程,对诊断结果进核实。
4.现有技术具有以下缺陷:首先,现有技术只能预测某种具体病种的受伤部位或患病情况,不具有普适性;其次,现有技术给出的可解释性方案存在不够具体准确,如不具备时序特征等问题;最后,现有技术不能精确到医生对于病例误诊是由哪一部分病症误判而造成的。
技术实现要素:
5.本发明的目的是针对现有技术存在的不足,提供一种病例异常检测方法及设备。
6.为实现上述目的,在第一方面,本发明提供了一种病例异常检测方法,包括:
7.基于症状提取模型从病例中提取医生给出的症状集合,所述症状集合包括若干症状,并将所述症状识别成症状实体及其对应的症状状态;
8.对每一症状实体的症状状态分别进行文本情感分析,以获得每一症状实体的正异常倾向结果;
9.基于异常检测模型对体检报告的各项指标进行异常检测,以获得每一症状的异常检测结果;
10.判断每一症状实体的正异常倾向结果与异常检测结果是否一致;
11.基于判别模型对体检报告的各项指标进行判别,以获得判别结果;
12.判断所述判别结果与病例中的诊断结果是否一致;
13.若任一症状实体的正异常倾向结果与异常检测结果不一致或所述判别结果与病例中的诊断结果不一致,则输出检测结果为病例异常,否则输出检测结果为病例正常。
14.进一步的,还基于异常检测模型从每一症状实体获得支持度最高的可解释性序
列;
15.将所述支持度最高的可解释性序列与利用专家知识预先构建的知识图谱进行对比,以判断所述支持度最高的可解释性序列与知识图谱是否一致,如不一致,则重构异常检测模型,并重新对每一症状实体进行异常检测。
16.进一步的,若所述支持度最高的可解释性序列与知识图谱一致,且经专家证实确认该症状实体的最佳可解释性序列可靠,对所述知识图谱进行知识融合。
17.进一步的,所述支持度最高的可解释性序列的获取方式如下:
18.导入单个病例样本经由随机森林模型预测为异常的决策树路径集合paths
ab
,其中,paths
ab
=[path0,path1,
……
pathm],每条路径path
x
来自随机森林中不同的决策树,0≤x≤m,m为大于1的自然数;
[0019]
对paths
ab
的特征使用fp-growth算法挖掘频繁项集fre_items,所述频繁项集fre_items包括支持度support、具体项itemsets、长度length等信息,得到可解释性序列的雏形;
[0020]
将fre_items按指定优先级排序,使用shap对该样本进行预测,获得各特征featurey的特征重要性,y为特征的序号,过滤掉fre_items中的不含有最重要特征的子集,然后根据异常路径间强弱联系更新fre_items中各特征值范围,再使用频繁模式下的prefixspan算法从该病例样本中抽取频繁子序列fre_subseqs,并对比fre_subseqs和fre_items中的特征,若无共同特征,则fre_items保持原序;否则,按照fre_subseqs中特征的顺序遍历找出两者间的共同特征放入新建的sort_index列表中,若sort_index长度为1,则fre_items保持原序;否则,根据sort_index调整fre_items中各特征顺序。
[0021]
进一步的,根据异常路径间强弱联系更新fre_items中各特征值范围具体包括:
[0022]
对排名靠前的若干fre_items分别进行初始化;
[0023]
判断每一fre_items是否在相应的路径中,若不在,则直接过滤此路径,若在,则判断该fre_items中的特征是否在相应的路径中出现多次,若是,则将此路径中该特征的不同值取交集作为该特征的特征范围,否则,将初始化后的特征范围与上一次得到的特征范围取并集,若该过程产生冲突,则直接过滤此路径。
[0024]
进一步的,对每一症状实体的症状状态分别进行文本情感分析具体包括:
[0025]
根据每一症状实体的症状状态定义两个态度极性的词列表;
[0026]
识别每一症状实体的每个症状状态的态度极性;
[0027]
计算每一症状实体的所有症状状态两种态度极性出现的次数,若积极词出现次数大于消极词出现次数,则判断该症状实体的正异常倾向结果为正常,否则,判断该症状实体的正异常倾向结果为异常。
[0028]
在第二方面,本发明提供了一种病例异常检测设备,包括:
[0029]
提取模块,用以基于症状提取模型从病例中提取医生给出的症状集合,所述症状集合包括若干症状,并将所述症状识别成症状实体及其对应的症状状态;
[0030]
情感分析模块,用以对每一症状实体的症状状态分别进行文本情感分析,以获得每一症状实体的正异常倾向结果;
[0031]
异常检测模块,用以基于异常检测模型对体检报告的各项指标进行异常检测,以获得每一指标的异常检测结果;
[0032]
第一比对模块,用以判断每一症状实体的正异常倾向结果与异常检测结果是否一致;
[0033]
判别模块,用以基于判别模型对体检报告的各项指标进行判别,以获得判别结果;
[0034]
第二比对模块,用以判断所述判别结果与病例中的诊断结果是否一致;
[0035]
输出模块,用以在任一症状实体的正异常倾向结果与异常检测结果不一致或所述判别结果与病例中的诊断结果不一致时,输出检测结果为病例异常,否则输出检测结果为病例正常。
[0036]
进一步的,所述异常检测模块还用以基于异常检测模型从每一症状实体获得支持度最高的可解释性序列;
[0037]
还包括第三比对模块,用以将所述支持度最高的可解释性序列与利用专家知识预先构建的知识图谱进行对比,以判断所述支持度最高的可解释性序列与知识图谱是否一致,如不一致,则触发重构异常检测模型,并重新对每一症状实体进行异常检测。
[0038]
进一步的,若所述支持度最高的可解释性序列与知识图谱一致,且经专家证实确认该症状实体的最佳可解释性序列可靠,则触发对所述知识图谱进行知识融合。
[0039]
进一步的,所述支持度最高的可解释性序列的获取方式如下:
[0040]
导入单个病例样本经由随机森林模型预测为异常的决策树路径集合paths
ab
,其中,paths
ab
=[path0,path1,
……
pathm],每条路径path
x
来自随机森林中不同的决策树,0≤x≤m,m为大于1的自然数;
[0041]
对paths
ab
的特征使用fp-growth算法挖掘频繁项集fre_items,所述频繁项集fre_items包括支持度support、具体项itemsets、长度length等信息,得到可解释性序列的雏形;
[0042]
将fre_items按指定优先级排序,使用shap对该样本进行预测,获得各特征featurey的特征重要性,y为特征的序号,过滤掉fre_items中的不含有最重要特征的子集,然后根据异常路径间强弱联系更新fre_items中各特征值范围,再使用频繁模式下的prefixspan算法从该病例样本中抽取频繁子序列fre_subseqs,并对比fre_subseqs和fre_items中的特征,若无共同特征,则fre_items保持原序;否则,按照fre_subseqs中特征的顺序遍历找出两者间的共同特征放入新建的sort_index列表中,若sort_index长度为1,则fre_items保持原序;否则,根据sort_index调整fre_items中各特征顺序。
[0043]
进一步的,根据异常路径间强弱联系更新fre_items中各特征值范围具体包括:
[0044]
对排名靠前的若干fre_items分别进行初始化;
[0045]
判断每一fre_items是否在相应的路径中,若不在,则直接过滤此路径,若在,则判断该fre_items中的特征是否在相应的路径中出现多次,若是,则将此路径中该特征的不同值取交集作为该特征的特征范围,否则,将初始化后的特征范围与上一次得到的特征范围取并集,若该过程产生冲突,则直接过滤此路径。
[0046]
进一步的,对每一症状实体的症状状态分别进行文本情感分析具体包括:
[0047]
根据每一症状实体的症状状态定义两个态度极性的词列表;
[0048]
识别每一症状实体的每个症状状态的态度极性;
[0049]
计算每一症状实体的所有症状状态两种态度极性出现的次数,若积极词出现次数大于消极词出现次数,则判断该症状实体的正异常倾向结果为正常,否则,判断该症状实体
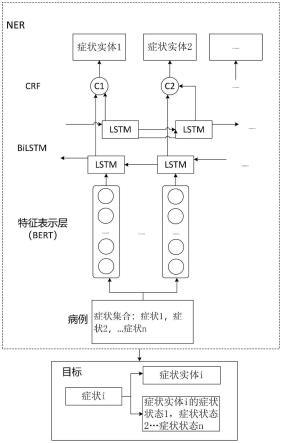
memory,双向长短是记忆网络模型)提取文本全局特征和局部特征,在bilstm网络的隐藏层后加一层线性层,即crf(conditional random fields,条件随机场),考虑标签序列全局信息,选择概率最大的实体。该基于attention方法的ner有助于重点表示和高概率提取实体,最终将病例由非结构化数据转换为结构化数据。具体呈现形式为:症状集合包括若干症状,每个症状被识别为症状实体和症状状态。原始数据形式:症状集合={症状1,症状2,
……
,症状n};目标数据形式:症状i—》{症状实体i+症状状态1+症状状态2+
……
+症状状态g},1≤i≤n,n、g均为大于2的自然数。
[0063]
参见图2,对每一症状实体的症状状态分别进行文本情感分析,以获得每一症状实体的正异常倾向结果。正异常倾向结果有两种,一种是正常,另一种是异常。参见图7,本发明采用的是基于规则的情感分析,具体的,对每一症状实体的症状状态分别进行文本情感分析包括:根据每一症状实体的症状状态定义两个态度极性(积极、消极)的词列表,识别每一症状实体的每个症状状态的态度极性。计算每一症状实体的所有症状状态两种态度极性出现的次数,若积极词出现次数大于消极词出现次数,则判断该症状实体的正异常倾向结果为正常,否则,判断该症状实体的正异常倾向结果为异常。
[0064]
基于异常检测模型对体检报告的各项指标进行异常检测,以获得每一指标的异常检测结果。异常检测结果包括异常和正常。具体的,以体检报告为样本针对每个症状独立构建基于随机森林(random forest,rf)的异常检测模型,最终得到森林中得每棵树的训练结果和路径。若该树检测结果为异常,则将预测为异常的路径取出,放入到该病例样本的异常路径集合中;否则,不予考虑。
[0065]
判断每一症状实体的正异常倾向结果与异常检测结果是否一致。当正异常倾向结果和异常检测结果均为正常或均为异常时,就判断为一致,否则判断为不一致。当出现不一致时,可视为出现小误诊现象。
[0066]
医生对于症状集合中的所有症状的诊断是正确的,也不能说明就不存在误诊现象,还须从大方向上把握是否发生更加严重的误诊,即对于诊断结果的误诊,这是最为致命的错误。因此,本发明还对医生在病例中给出的诊断结果进行检测,从而在一定程度上规避大误诊风险。具体可参见图6,将病例中的体检报告的各项指标输入至判别模型中,基于判别模型对体检报告的各项指标进行判别,以获得判别结果。然后再将判别模型的输出结果与病例中的诊断结果进行对比,从而判断判别结果与病例中的诊断结果是否一致。具体的,为了充分利用结构化数据,即存档的体检报告,包括有限个指标项{指标1,指标2,指标3,
……
,指标j},j为大于3的自然数,使用sigmoid激活函数+交叉熵损失函数+随机梯度下降算法训练一个深度神经网络(deep neural networks,dnn)作为判别模型,可定义dnn输出大于0.7为异常,将新的体检报告输入其中,得到一个判别结果。然后,进行大误诊的判别。具体如下,将病例中的诊断结果与dnn给出的判别结果进行对比,若一致,则医生对于诊断结果的判断正确;否则,判断错误,发生大误诊。
[0067]
综合以上小误诊和大误诊的判断结果,输出检测结果。具体的,若任一症状实体的正异常倾向结果与异常检测结果不一致或所述判别结果与病例中的诊断结果不一致,则输出检测结果为病例异常,否则输出检测结果为病例正常。在出现检测结果为病例异常时,可同时反馈最佳可解释性序列和医生做出的病因解释给相关人员,方便其及时纠正改错,加深其相关病种知识的积累,引起足够的重视,从而降低该病种的误诊率。
[0068]
为了提高异常检测模型的可信度和完善知识图谱做准备,作为优选实施例,本发明还基于异常检测模型获取针对每一症状实体的支持度最高的可解释性序列,并将支持度最高的可解释性序列与利用专家知识预先构建的知识图谱进行对比,以判断支持度最高的可解释性序列与知识图谱是否一致,如不一致,则重构异常检测模型,并重新对每一症状实体进行异常检测。若支持度最高的可解释性序列与知识图谱一致,且经专家证实确认该症状实体的最佳可解释性序列可靠,对知识图谱进行知识融合。不断重复上述过程,直至病例中症状实体被检测完毕,从而不断更新迭代知识图谱。
[0069]
参见图3和图4,上述支持度最高的可解释性序列优选基于fp-growth提取,先得到一系列准确的、具体的、时序的可解释性序列,然后取支持度最高的可解释性序列为最佳可解释性序列,为进行模型可信度的判断和知识融合做准备。具体包括:导入单个病例样本经由随机森林模型预测为异常的决策树路径集合paths
ab
,其中,paths
ab
=[path0,path1,
……
pathm],每条路径path
x
来自随机森林中不同的决策树,0≤x≤m,m为大于1的自然数。对paths
ab
的特征使用fp-growth算法挖掘频繁项集fre_items,频繁项集fre_items包括支持度support、具体项itemsets、长度length等信息,得到可解释性序列的雏形。将fre_items按指定优先级排序,保证可解释性特征数目优先,弱化随机森林多棵决策树对可解释性的干扰。使用shap对该样本进行预测,获得各特征featurey的特征重要性,y为特征的序号,取值为大于0的自然数,根据特征的重要性可得到一个最重要特征,过滤掉fre_items中的不含有该最重要特征的子集,然后根据异常路径间强弱联系更新fre_items中各特征值范围,再使用频繁模式下的prefixspan算法从该病例样本中抽取频繁子序列fre_subseqs,并对比fre_subseqs和fre_items中的特征,若无共同特征,则fre_items保持原序;否则,按照fre_subseqs中特征的顺序遍历找出两者间的共同特征放入新建的sort_index列表中,若sort_index长度为1,则fre_items保持原序;否则,根据sort_index调整fre_items中各特征顺序。至此,可以将频繁子结构具有的时序属性赋予频繁项集fre_items,将原本无序的频繁项集特征按照时间排序,更加贴合医疗领域对于病症出现的先后顺序的一贯认知,最后一步优化可解释性方案。
[0070]
参见图5,上述根据异常路径间强弱联系更新fre_items中各特征值范围具体包括:
[0071]
对排名靠前的若干fre_items分别进行初始化。判断每一fre_items是否在相应的路径中,若不在,则直接过滤此路径,若在,则判断该fre_items中的特征是否在相应的路径中出现多次,若是,则将此路径中该特征的不同值取交集作为该特征的特征范围,否则,将初始化后的特征范围与上一次得到的特征范围取并集,若该过程产生冲突,则直接过滤此路径。以fre_items[0]=[feature0,feature1,feature2]为例说明,在初始化以后,该频繁项集的范围scope0={feature0:[0,inf],feature1:[0,inf],feature2:[0,inf]},inf为预设的范围上限,可取值为无穷大。然后判断fre_items[0]是否在path0中,若不在,则直接过滤此路径;若在,以特征feature0为例,则判断feature0是否在path0中出现多次。若是,则将此路径中该特征的不同值取交集得到feature0新的特征范围scope0_feature0_new;否则,与上一次得到的feature0的特征范围scope0_feature0_old取并集(若是第1遍迭代则取feature0的初始化值scope0_feature0)。若该过程产生冲突,则直接过滤此条路径path0。同理,对fre_items[0]中每个特征进行遍历判断。每次过滤路径path
x
后,都需要重新更新
fre_items。重复上述步骤直至遍历全部的异常路径paths
ab
。
[0072]
结合图1至图8,基于以上实施例,本领域技术人员可以轻易理解,本发明还提供了一种病例异常检测设备,包括提取模块1、情感分析模块2、异常检测模块3、第一比对模块4、判别模块5、第二比对模块6和输出模块7。
[0073]
其中,提取模块1用以基于症状提取模型从病例中提取医生给出的症状集合,症状集合包括若干症状,并将症状识别成症状实体及其对应的症状状态。电子病例中医生所写的症状经常以文本(即非结构化数据形式)呈现,因此,需要采用症状提取模型来挖掘病例中的可用信息实体。该方法可以充分利用病例这种非结构化数据资源,不遗漏任何一种医学方面的异常检测,为后续检测病症实体是否异常做数据支持。
[0074]
具体可参见图1,首先,使用基于attention方法的命名实体识别方法(named-entity recognition,ner),即使用bert+bilstm+crf的模型来训练一个ner模型。使用具有更强文本特征表示能力的预训练模型bert(bidirectional encoder representation from transformers,基于变换器的双向编码器)作为特征表示层,对大规模的文本数据训练,深度挖掘文本序列之间的潜在特征,结合bilstm(bi-directional long short-term memory,双向长短是记忆网络模型)提取文本全局特征和局部特征,在bilstm网络的隐藏层后加一层线性层,即crf(conditional random fields,条件随机场),考虑标签序列全局信息,选择概率最大的实体。该基于attention方法的ner有助于重点表示和高概率提取实体,最终将病例由非结构化数据转换为结构化数据。具体呈现形式为:症状集合包括若干症状,每个症状被识别为症状实体和症状状态。原始数据形式:症状集合={症状1,症状2,
……
,症状n};目标数据形式:症状i—》{症状实体i+症状状态1+症状状态2+
……
+症状状态g},1≤i≤n,n、g均为大于2的自然数。
[0075]
参见图2,情感分析模块2用以对每一症状实体和症状状态进行文本情感分析,以获得正异常倾向结果。正异常倾向结果有两种,一种是正常,另一种是异常。参见图7,本发明采用的是基于规则的情感分析,具体的,对每一症状实体的症状状态分别进行文本情感分析包括:根据每一症状实体的症状状态定义两个态度极性(积极、消极)的词列表,识别每一症状实体的每个症状状态的态度极性。计算每一症状实体的所有症状状态两种态度极性出现的次数,若积极词出现次数大于消极词出现次数,则判断该症状实体的正异常倾向结果为正常,否则,判断该症状实体的正异常倾向结果为异常。
[0076]
异常检测模块3用以基于异常检测模型对体检报告的各项指标进行异常检测,以获得每一指标的异常检测结果。异常检测结果包括异常和正常。具体的,以体检报告为样本针对每个症状独立构建基于随机森林(random forest,rf)的异常检测模型,最终得到森林中得每棵树的训练结果和路径。若该树检测结果为异常,则将预测为异常的路径取出,放入到该病例样本的异常路径集合中;否则,不予考虑。
[0077]
第一比对模块4用以判断每一症状实体的正异常倾向结果与异常检测结果是否一致。当正异常倾向结果和异常检测结果均为正常或均为异常时,就判断为一致,否则判断为不一致。当出现不一致时,可视为出现小误诊现象。
[0078]
医生对于症状集合中的所有症状的诊断是正确的,也不能说明就不存在误诊现象,还须从大方向上把握是否发生更加严重的误诊,即对于诊断结果的误诊,这是最为致命的错误。因此,本发明还对医生在病例中给出的诊断结果进行检测,从而在一定程度上规避
大误诊风险。具体可参见图6,将病例中的体检报告的各项指标输入至判别模型中,判别模块5基于判别模型对体检报告的各项指标进行判别,以获得判别结果。然后第二比对模块6再将判别模型的输出结果与病例中的诊断结果进行对比,从而判断判别结果与病例中的诊断结果是否一致。具体的,为了充分利用结构化数据,即存档的体检报告,包括有限个指标项{指标1,指标2,指标3,
……
,指标j},j为大于3的自然数,使用sigmoid激活函数+交叉熵损失函数+随机梯度下降算法训练一个深度神经网络(deep neural networks,dnn)作为判别模型,可定义dnn输出大于0.7为异常,将新的体检报告输入其中,得到一个判别结果。然后,进行大误诊的判别。具体如下,将病例中的诊断结果与dnn给出的判别结果进行对比,若一致,则医生对于诊断结果的判断正确;否则,判断错误,发生大误诊。
[0079]
输出模块7用以综合以上小误诊和大误诊的判断结果,输出检测结果。具体的,若任一症状实体的正异常倾向结果与异常检测结果不一致或所述判别结果与病例中的诊断结果不一致,则输出检测结果为病例异常,否则输出检测结果为病例正常。在出现检测结果为病例异常时,可同时反馈最佳可解释性序列和医生做出的病症解释给相关人员,方便其及时纠正改错,加深其相关病种知识的积累,引起足够的重视,从而降低该病种的误诊率。
[0080]
为了提高异常检测模型的可信度和完善知识图谱做准备,作为优选实施例,本发明的异常检测模块3还基于异常检测模型从每一症状实体获得支持度最高的可解释性序列,还包括第三比对模块8,第三比对模块8用以将支持度最高的可解释性序列与利用专家知识预先构建的知识图谱进行对比,以判断支持度最高的可解释性序列与知识图谱是否一致,如不一致,则重构异常检测模型,并重新对每一症状实体进行异常检测。若支持度最高的可解释性序列与知识图谱一致,且经专家证实确认该症状实体的最佳可解释性序列可靠,对知识图谱进行知识融合。不断重复上述过程,直至病例中病症实体被检测完毕,从而不断更新迭代知识图谱。
[0081]
参见图3和图4,上述支持度最高的可解释性序列优选基于fp-growth提取,先得到一系列准确的、具体的、时序的可解释性序列,然后取支持度最高的可解释性序列为最佳可解释性序列,为进行模型可信度的判断和知识融合做准备。具体包括:导入单个病例样本经由随机森林模型预测为异常的决策树路径集合paths
ab
,其中,paths
ab
=[path0,path1,
……
pathm],每条路径path
x
来自随机森林中不同的决策树,0≤x≤m,m为大于1的自然数。对paths
ab
的特征使用fp-growth算法挖掘频繁项集fre_items,频繁项集fre_items包括支持度support、具体项itemsets、长度length等信息,得到可解释性序列的雏形。将fre_items按指定优先级排序,保证可解释性特征数目优先,弱化随机森林多棵决策树对可解释性的干扰。使用shap对该样本进行预测,获得各特征featurey的特征重要性,y为特征的序号,取值为大于0的自然数,根据特征的重要性可得到一个最重要特征,过滤掉fre_items中的不含有该最重要特征的子集,然后根据异常路径间强弱联系更新fre_items中各特征值范围,再使用频繁模式下的prefixspan算法从该病例样本中抽取频繁子序列fre_subseqs,并对比fre_subseqs和fre_items中的特征,若无共同特征,则fre_items保持原序;否则,按照fre_subseqs中特征的顺序遍历找出两者间的共同特征放入新建的sort_index列表中,若sort_index长度为1,则fre_items保持原序;否则,根据sort_index调整fre_items中各特征顺序。至此,可以将频繁子结构具有的时序属性赋予频繁项集fre_items,将原本无序的频繁项集特征按照时间排序,更加贴合医疗领域对于病症出现的先后顺序的一贯认知,最
后一步优化可解释性方案。
[0082]
参见图5,上述根据异常路径间强弱联系更新fre_items中各特征值范围具体包括:
[0083]
对排名靠前的若干fre_items分别进行初始化。判断每一fre_items是否在相应的路径中,若不在,则直接过滤此路径,若在,则判断该fre_items中的特征是否在相应的路径中出现多次,若是,则将此路径中该特征的不同值取交集作为该特征的特征范围,否则,将初始化后的特征范围与上一次得到的特征范围取并集,若该过程产生冲突,则直接过滤此路径。以fre_items[0]=[feature0,feature1,feature2]为例说明,在初始化以后,该频繁项集的范围scope0={feature0:[0,inf],feature1:[0,inf],feature2:[0,inf]},inf为预设的范围上限,可取值为无穷大。然后判断fre_items[0]是否在path0中,若不在,则直接过滤此路径;若在,以特征feature0为例,则判断feature0是否在path0中出现多次。若是,则将此路径中该特征的不同值取交集得到feature0新的特征范围scope0_feature0_new;否则,与上一次得到的feature0的特征范围scope0_feature0_old取并集(若是第1遍迭代则取feature0的初始化值scope0_feature0)。若该过程产生冲突,则直接过滤此条路径path0。同理,对fre_items[0]中每个特征进行遍历判断。每次过滤路径path
x
后,都需要重新更新fre_items。重复上述步骤直至遍历全部的异常路径paths
ab
。
[0084]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,其它未具体描述的部分,属于现有技术或公知常识。在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1