一种糖尿病视网膜病变智能诊断模型的构建方法
1.本发明涉及深度学习技术领域,具体涉及一种糖尿病视网膜病变智能诊断模型的构建方法。
背景技术:
2.糖尿病视网膜病变(diabetic retinopathy,简称dr)是一种最常见的糖尿病眼科疾病并发症,是一种可预防的疾病。临床中,主要依赖于经验较高的眼科专家对彩色视网膜图像进行观察评估以确定疾病分期等级,其中病理分期等级多采用dr国际五分期标准来制定最优化的诊疗方案。深度学习可以有效地根据标注的数据中提取图像中的病理特征,并取得较好的诊断结果,但是实际情况会面临很多挑战。
3.在深度神经网络训练过程中,现有的方法多是以大数据驱动的方式来训练神经网络,因现有的眼底图像开源数据集存在设备差异和疾病的地域性差异等问题,面向大规模开源数据的模型训练方法会导致模型分类结果不准,不适用于将其扩展并应用于某些标签数据不足的医疗机构或不同的国家地域。
技术实现要素:
4.针对现有技术的不足,本发明旨在提供一种糖尿病视网膜病变智能诊断模型的构建方法。
5.为了实现上述目的,本发明采用如下技术方案:
6.一种糖尿病视网膜病变智能诊断模型的构建方法,具体过程如下:
7.s1、图像预处理:对眼底图像数据进行降噪与归一化处理;
8.s2、模型训练:主要包含两个阶段:基于对比自监督学习的前置任务,以及基于卷积神经网络的下游任务;
9.所述前置任务的具体过程如下:
10.2.1.1、数据增强:在训练过程中,给定一个批量的输入眼底图像集合为x={xk}
k=1,2,
…
,n
,n为输入眼底图像集合的图像数量;对每一张输入的眼底图像数据xk进行随机变换,生成正样本眼底图像数据对:(xi,xj);因此,集合x在数据增强后生成了集合xi={xi}
i=1,3,
…
,2n-1
和xj={xj}
j=2,4,
…
,2n
;
11.2.1.2、编码器:编码器f(
·
)利用两个权值共享的卷积神经网络,同时将输入集合xi和xj编码为相应的2048维度的特征表示序列hi和hj,如公式(3)所示:
12.hi=f(xi)
13.hj=f(xj)
ꢀꢀꢀ
(3)
14.2.1.3、投影网络projection net:投影网络p(
·
)包含两个权值共享的多层感知机网络模块,即mlp模块,每个mlp模块由两个通过relu激活函数层相连的全连接网络层f1、f2组成;通过投影网络中的多次非线性变化后,将特征表示hi和hj进一步转换为zi和zj;投影过程如公式(4)所示:
15.zi=p(hi)=w2σ(w1hi)
16.zj=p(hj)=w2σ(w1hj)
ꢀꢀꢀ
(4)
17.在公式(4)中,w1和w2分别表示mlp中两个全连接层f1、f2网络参数,σ表示relu非线性变换;
18.2.1.4、对比损失函数:选用对比损失函数nt-xent作为损失函数;每个批量输入n张眼底图像数据,在经过数据增强过程后,批量的大小会扩大至2n;每个批量的数据的nt-xent损失计算流程如下:
19.首先,计算所有2n张眼底图像中每两张眼底图像之间的余弦相似度,计算过程如公式(5)所示:
[0020][0021]
在公式(5)中,m∈{1,2,
…
,2n}、n∈{1,2,
…
,2n};然后,使用softmax函数归一化余弦相似度sim(zm,zn),得到两张眼底图像之间相似的概率;而后,取其对数的负值作为这一对眼底图像的损失,称之为噪声对比估计损失;正样本对(zi,zj)之间的损失计算过程如公式(6)所示:
[0022][0023]
在公式(6)中,k≠i表示除zi外的所有图像,而τ表示的是一个可调节的温度参数,作用是缩放输入,扩大余弦相似度的范围为[-1,1];最后,包括(xi,xj)和(xj,xi)在内所有正样本对的最终损失,即整个网络的最终损失计算过程如公式(7)所示:
[0024][0025]
通过上述前置任务训练,利用无标记数据的自监督对比学习训练方法,将学习到的先验知识通过网络迁移,把前置任务中编码器学习到的参数迁移至下游任务的特征提取网络当中,作为初始化网络参数;
[0026]
所述下游任务包括三个组成部分(1)编码器;(2)分类器;(3)目标函数:
[0027]
2.2.1、编码器:下游任务中的cnn编码器结构与前置任务编码器结构相同;将前置任务中编码器学习的参数加载到下游任务的编码器中;将眼底图像数据x输入编码器得到高维特征图表示序列,而后经过编码器的输出层对其进行降维处理,得到特征向量h,之后将其输入分类器进行分类;计算过程如下所示:
[0028]
h=gap(f(x))
ꢀꢀꢀ
(8)
[0029]
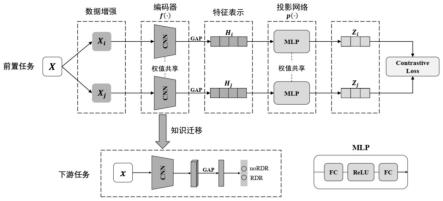
在公式(8)中,f(
·
)卷积池化过程,gap表示全局平均池化层,h表示编码器最终输出的特征向量;
[0030]
2.2.2、分类器:编码器的输出层之后是一个softmax分类器,由fc层和softmax函数组成,用于计算样本属于阳性的概率计算过程如下所示:
[0031]
{z1,z2}=fc(h)
ꢀꢀꢀ
(9)
[0032]
[0033]
在公式(9)中,fc表示输出有两个节点的全连接网络,z1和z2分别表示两个输出值;在公式(10)中,使用softmax函数将输出归一化,得到样本属于阳性的概率在公式(10)中,使用softmax函数将输出归一化,得到样本属于阳性的概率
[0034]
2.2.3、目标函数:基于softmax分类器,采用二分类交叉熵损失函数作为此任务中的目标函数;对于给定的一个批量的输入序列{(x1,y1),(x2,y2),
…
,(xn,yn)},损失函数计算过程如下:
[0035][0036]
在公式(11)中,yi为样本的真实标签,此任务中将阳性样本标签设置为1,阴性样本标签设置为0,因此yi∈{0,1},表示样本预测为阳性的概率。
[0037]
进一步地,步骤s1的具体过程:
[0038]
首先,需要对眼底图像中多余的黑色边界像素进行裁剪,以去除信息冗余噪声;
[0039]
然后,对眼底图像的尺寸进行归一化处理,将所有眼底图像的分辨率统一调整为256
×
256;
[0040]
最后,对眼底图像的亮度与对比度进行改善,过程如公式(1)和公式(2)所示:
[0041][0042]ienhance
=α
·
i(x,y)+β
·igaussian
+γ
ꢀꢀꢀ
(2)
[0043]
在公式(1)中,输入尺寸归一化后的图像i(x,y),对其进行标准偏差为σ的高斯滤波器卷积处理后得到i
gaussian
,然后通过公式(2)加权求和得到增强后的眼底图像i
enhabce
,其中α、β、σ、γ的值分别设为4、-4、10、128。
[0044]
进一步地,步骤2.1.1中,数据增强包括:对眼底图像进行随机剪裁、随机翻转至某个角度、随机转为灰度图,以及随机修改眼底图像的亮度、对比度或饱和度。
[0045]
进一步地,步骤2.1.2中,选用包含imagenet预训练参数的resnet50网络为编码器的基础网络结构。
[0046]
本发明的有益效果在于:本发明将自监督对比学习和监督深度学习结合,改进dnn的训练过程,提出了一种糖尿病视网膜病变智能诊断模型的构建方法。所述构建方法包括数据的预处理、前置任务和下游任务。预处理是为了提升数据的质量,将图像进行降噪与归一化处理。前置任务是一个无监督的模型预训练过程,作用是从无标记的数据集中挖掘先验知识,以此辅助模型训练。下游任务是一个有监督的分类模型微调过程,利用先验知识提升模型训练质量,进而提升模型在少量标记数据训练下的dr分类性能。
附图说明
[0047]
图1为本发明实施例方法中数据增强效果示意图;
[0048]
图2为本发明实施例方法的流程示意图。
具体实施方式
[0049]
以下将结合附图对本发明作进一步的描述,需要说明的是,本实施例以本技术方案为前提,给出了详细的实施方式和具体的操作过程,但本发明的保护范围并不限于本实施例。
[0050]
本实施例提供一种糖尿病视网膜病变智能诊断模型的构建方法,其中,如何利用数据库中无标记数据和少量标注图像数据进行模型的训练是重点。
[0051]
卷积神经网络(dnn)作为提取图像特征的最佳技术之一,目前已经成为该领域中最有效的深度学习模型,模型通常使用有标注数据进行有监督的训练,但在无标注数据和少量标注数据中的特征挖掘能力是不够的。
[0052]
针对dr的疾病分期等级特点,为了使模型能在无标注数据下挖掘出先验知识辅助智能诊断模型,并用于早期的糖尿病视网膜病变检测,本实施例将自监督对比学习和监督深度学习结合,改进dnn的训练过程,提出了一种糖尿病视网膜病变智能诊断模型(dr模型)的构建方法。所述构建方法包括数据的预处理、前置任务(pretext task)和下游任务(downstream task)。预处理是为了提升数据的质量,将图像进行降噪与归一化处理。前置任务是一个无监督的模型预训练过程,作用是从无标记的数据集中挖掘先验知识,以此辅助模型训练。下游任务是一个有监督的分类模型微调过程,利用先验知识提升模型训练质量,进而提升模型在少量标记数据训练下的dr分类性能。
[0053]
本实施例方法的技术路线为:将数据库中的原始图片进行预处理,将处理后的数据输入到模型中,通过前置任务和下游任务的训练后,通过训练优化后得到糖尿病视网膜病变智能诊断模型。具体过程如下:
[0054]
s1、图像预处理:
[0055]
由于眼底图像数据来源及成像设备不同,个体之间差异较大。数据集中会存在以下几种现象:尺寸颜色差异较大、曝光过度、信息冗余等。为了提升数据的质量,需要对数据库中的眼底图像进行降噪与归一化处理。首先,需要对眼底图像中多余的黑色边界像素进行裁剪,以去除信息冗余噪声;然后,对眼底图像的尺寸进行归一化处理,将所有眼底图像的分辨率统一调整为256
×
256;最后,对眼底图像的亮度与对比度进行改善,过程如公式(1)和公式(2)所示:
[0056][0057]ienhance
=α
·
i(x,y)+β
·igaussian
+γ
ꢀꢀꢀ
(2)
[0058]
在公式(1)中,输入尺寸归一化后的图像i(x,y),对其进行标准偏差为σ的高斯滤波器卷积处理后得到i
gaussian
,然后通过公式(2)加权求和得到增强后的眼底图像i
enhance
,其中α、β、σ、γ的值分别设为4、-4、10、128,原图与预处理结果如图1所示,图1中(a)和(c)为原图,(b)和(d)分别为对应的预处理结果。
[0059]
s2、模型训练:
[0060]
临床医学图像数据库存储了大量的眼底图像,由于没有标注而没有得到充分的利用。对比学习在挖掘未标注的数据样本以提高模型泛化能力方面具有重要作用。
[0061]
如图2所示,本实施例的模型训练主要包含两个阶段:基于对比自监督学习的前置任务,以及基于卷积神经网络的下游任务。前置任务是一个无监督的模型预训练过程,作用是从无标记的数据集中挖掘先验知识,以此辅助模型训练。下游任务是一个有监督的分类模型微调过程,利用先验知识提升模型训练质量,进而提升模型在少量标记数据训练下的dr分类性能。
[0062]
本实施例方法中,模型训练的重点在于如何利用前置任务从无标记的数据中挖掘到先验知识,通过知识迁移的方法转移到下游任务中,从而提升模型的分类性能。
[0063]
2.1、前置任务包括数据增强、编码器、投影网络和对比损失四个阶段。其中的编码器f(
·
)利用两个权值共享的卷积神经网络,在训练完之后会迁移至下游任务的特征提取网络中。
[0064]
所述前置任务的具体过程如下:
[0065]
2.1.1、数据增强:在训练过程中,给定一个批量的输入眼底图像集合为x={xk}
k=1,2,
…
,n
,n为输入眼底图像集合的图像数量;对每一张输入的眼底图像数据xk进行随机变换,生成正样本眼底图像数据对(xi,xj);因此,集合x在数据增强后生成了集合xi={xi}
i=1,3,
…
,2n-1
和xj={xj}
j=2,4,
…
,2n
。最终,编码器一个批量的输入为集合{(xi,xj)}
i=1,3,
…
,2n-1;j=i+1
,其中,(x1,x2)是由x1∈x生成的。本实施例选用了几种数据增强的方法,包括:对眼底图像进行随机剪裁、随机翻转至某个角度、随机转为灰度图,以及随机修改眼底图像的亮度、对比度或饱和度。
[0066]
2.1.2、编码器base encoder:编码器f(
·
)利用两个权值共享的卷积神经网络,同时将输入集合xi和xj编码为相应的2048维度的特征表示序列hi和hj,如公式(3)所示。
[0067]hi
=f(xi)
[0068]hj
=f(xj)
ꢀꢀꢀ
(3)
[0069]
resnet50网络被证明在提取高级语义信息方面十分有效,这对医学图像分析至关重要。因此,本实施例方法选用包含imagenet预训练参数的resnet50网络为编码器的基础网络结构,如此可以使编码器网络具有较好的初始化参数,加快其在训练过程中的收敛速度。此外,网络结构中编码器位置设计是通用的,即可将resnet50替换为其他种类的编码器。
[0070]
2.1.3、投影网络projection net:投影网络p(
·
)包含两个权值共享的多层感知机(mlp)网络模块,每个mlp模块由两个通过relu激活函数层相连的全连接网络层f1、f2组成,如图2所示。通过投影网络中的多次非线性变化后,将步骤2.1.2得到的特征表示序列hi和hj进一步转换为zi和zj。投影过程如公式(4)所示。
[0071]
zi=p(hi)=w2σ(w1hi)
[0072]
zj=p(hj)=w2σ(w1hj)
ꢀꢀꢀ
(4)
[0073]
在公式(4)中,w1和w2分别表示mlp中两个全连接层f1、f2网络参数,σ表示relu非线性变换。
[0074]
2.1.4、对比损失函数:与监督学习任务不同,在自监督学习的过程中没有手工标签的参与。因此,在前置任务中,模型训练的关键是利用未标注训练数据来构造伪标签,并设计相应的损失函数对网络进行伪有监督训练。本实施例方法所选的损失函数为对比损失函数nt-xent,此函数的原理是,利用正负实例间的距离来计算损失。然后优化损失,使正例之间距离更近,负例之间距离更远。
[0075]
在此任务中,训练网络模型时,每个批量输入n张眼底图像数据,在经过数据增强过程后,批量的大小会扩大至2n。每个批量的数据的nt-xent损失计算流程如下。首先,计算所有2n张眼底图像中每两张眼底图像之间的余弦相似度,计算过程如公式(5)所示:
[0076][0077]
在公式(5)中,m∈{1,2,
…
,2n}、n∈{1,2,
…
,2n}。然后,使用softmax函数归一化
余弦相似度sim(zm,zn),得到两张眼底图像之间相似的概率。而后,取其对数的负值作为这一对眼底图像的损失,称之为噪声对比估计损失(简称nce损失)。正样本对(zi,zj)之间的损失计算过程如公式(6)所示:
[0078][0079]
在公式(6)中,k≠i表示除zi外的所有图像,而τ表示的是一个可调节的温度参数,作用是缩放输入,扩大余弦相似度的范围为[-1,1]。最后,包括(xi,xj)和(xj,xi)在内所有正样本对的最终损失,即整个网络的最终损失计算过程如公式(7)所示:
[0080][0081]
通过上述前置任务训练,利用无标记数据的自监督对比学习训练方法,将学习到的先验知识通过网络迁移,把前置任务中编码器学习到的参数迁移至下游任务的特征提取网络当中,作为初始化网络参数,如图2所示。
[0082]
2.2、因为模型通过前置任务已经学习到了一些先验知识,因此,只需要使用少量的标记数据对编码器和分类器进行微调训练,就可以获得良好的分类性能,下游任务包括三个组成部分(1)编码器;(2)分类器;(3)目标函数。
[0083]
2.2.1、编码器:下游任务中的cnn编码器结构与前置任务编码器结构相同,同为resnet50网络结构。将前置任务中编码器学习的参数加载到下游任务的编码器中。将眼底图像数据x输入编码器得到高维特征图表示序列,而后经过编码器的输出层(gap层)对其进行降维处理,得到特征向量h,之后将其输入分类器进行分类。计算过程如下所示。
[0084]
h=gap(f(x))
ꢀꢀꢀ
(8)
[0085]
在公式(8)中,f(
·
)卷积池化过程,gap表示全局平均池化层,h表示编码器最终输出的特征向量。
[0086]
2.2.2、分类器:编码器的输出层之后是一个softmax分类器,由fc层和softmax函数组成,用于计算样本属于rdr(referable rdr)的概率,即样本属于阳性的概率计算过程如下所示。
[0087]
{z1,z2}=fc(h)
ꢀꢀꢀ
(9)
[0088][0089]
在公式(9)中,fc表示输出有两个节点的全连接网络,z1和z2分别表示两个输出值。在公式(10)中,使用softmax函数将输出归一化,得到样本属于阳性的概率
[0090]
2.2.3、目标函数:基于softmax分类器,采用二分类交叉熵损失函数作为此任务中的目标函数。对于给定的一个批量的输入序列{(x1,y1),(x2,y2),
…
,(xn,yn)},损失函数计算过程如下:
[0091][0092]
在公式(11)中,yi为样本的真实标签,此任务中将阳性样本标签设置为1,阴性样本标签设置为0,因此yi∈{0,1}。表示样本预测为阳性的概率。
[0093]
对于本领域的技术人员来说,可以根据以上的技术方案和构思,给出各种相应的改变和变形,而所有的这些改变和变形,都应该包括在本发明权利要求的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1