一种基于机器学习算法的胆管癌诊断模型及其构建方法和应用
1.本发明涉及人工智能技术领域,具体涉及一种基于机器学习算法的胆管癌诊断模型及其构建方法和应用。
背景技术:
2.胆管癌(cca)是一种高度侵袭性的恶性肿瘤,起源于胆管上皮细胞,可发生在从肝内胆管到胆总管末端的任何部位。根据病变的解剖部位,cca可分为肝内胆管癌(icca)和肝外胆管癌(ecca),肝外胆管癌又可分为肝门部胆管癌(pcca)和远端胆管癌(dcca)
1.。胆管癌是继肝细胞癌后肝胆系统中第二常见的恶性肿瘤,约占所有胃肠道肿瘤的3%
1.。胆管癌预后不良,其中一个重要原因是诊断困难,胆管癌患者临床确诊时往往已经处于晚期
2.。由于其临床特征不明显并且解剖位置较深,早期诊断胆管癌比较困难,目前的诊断方法主要包括放射学、内窥镜和实验室分析。胆管癌最常用的诊断方法是影像学检测,如计算机断层扫描、磁共振成像和内窥镜检查,但这些检查的准确性均不高,灵敏度约为60%。血清ca19-9可用于胆管癌诊断,但其敏感性和特异性仅为60%~65%
3.。此外,细菌性胆管炎或胆总管结石等良性狭窄患者的血清ca19-9水平也会升高。在胆管癌的临床鉴别诊断中,一个巨大的困难是准确的区分胆管癌与良性胆管狭窄,例如胆管结石和胆管炎,他们也会导致胆管壁增厚和胆管扩张。
3.胆汁主要由肝细胞和胆管上皮细胞分泌,胆汁成分的变化可以直接反应胆道疾病引起的胆道环境变化。胆管癌源于胆管上皮细胞恶性转化,胆管癌中的肿瘤相关蛋白可分泌到胆汁中,因此胆汁中的这些分泌蛋白具有成为诊断生物标志物的巨大潜力
4.。近年来,蛋白质组学通过分析生物样品中蛋白质的变化,被广泛用于寻找新的疾病标志物。并且胆汁中的大部分蛋白质都可以通过肽序列鉴定,例如发明专利cn114990216a公开了微小rna分子作为生物标记物在胆管癌预后中的应用,是通过检测胆管癌与非胆管癌患者胆汁外泌体中的has-mir-182-5p的表达水平,可以对胆管癌患者的预后做出判断,准确率达95%以上;发明专利cn114717319a公开了用于胆管癌预后评估的基因标志物,包括kras、tp53、smad4和tert,可以对胆管癌手术组织样本、活检组织样本、血浆样本、胆汁样本或者腹水样本的进行检测。胆管癌胆汁中异常高表达或低表达的蛋白质可用于鉴别胆管癌与良性疾病。
4.机器学习是人工智能的一个子组,可用于通过使用数学算法分析海量数据来学习逻辑模式并制作预测模型
5.。机器学习已广泛应用于癌症诊断和预后预测模型,并已被证明可以提高癌症复发和生存预测的准确性
6.。随机森林算法是一类专门为建立分类决策树所设计的信息处理统计技术。多样的在分类器构造中通过引入随机性投票分散来创建分类集。对于有限或没有编程背景的临床医生及患者可提供合适的易用的可靠临床预测模型。机器学习在大数据的处理、统计、计算学习过程的标准化和预测结局的区分度及准确度等方面具有优势,其此前在胸外科肺癌手术领域的诊断及分期识别、手术方案制定及预后预
测等方面均具有重要应用。临床预测模型本质上是借助已有的目标病例少量的、真实的、易于收集的常规的临床检验数据作为预测因子来构建临床统计模型,以用于预测疾病的诊断概率和给予治疗后的预后情况。
5.胆汁中差异表达的蛋白质谱主要反映局部变化,血清标志物主要反映胆管癌患者的全身系统性变化,所以我们猜想利用机器学习联合胆汁和血液中的标志物可以提高鉴别胆管癌和良性疾病的准确性。但是,在胆管癌发展过程中,血清中众多的标志物水平也会发生变化,例如碱性磷酸酶和胆红素水平,但它们在良性疾病中也可以发生变化,因此不能单独用于胆管癌诊断
7.,在本发明中,发明人利用机器学习算法,建立胆管癌预测模型,以便于更好的预测和诊断胆管癌患者。
技术实现要素:
6.本发明的首要目的是提供一种基于机器学习算法的胆管癌诊断模型的构建方法,包括如下步骤:
7.(1)获取样本集:收集胆管癌和胆道良性狭窄患者的胆汁和血清标志物数据,组成样本集;(2)构建随机森林模型:
8.s1.初始模型构建:建立具有所有特征的初始分类模型,根据步骤(1)得到样本集构建决策树,对初始模型进行优化,根据优化后的模型,计算所有特征的重要性排序;
9.s2.特征选择及模型二次优化:根据s1得到的所有特征的重要性排序,将用于建模的特征按照重要性从高到低添加到分类器中重新进行随机森林建模,并经由十折交互检验评价获取每个模型的最优参数值,并对每个特征进行排序;
10.(3)构建lasso模型获取最优模型:以最少的标志物数量具备最大的诊断效能为准则,利用lasso模型,随机组合初筛出的特征,按照组合数量递增的方法筛选出不同标志物数量下的最佳组合,当添加的特征不再能够增加模型的auc评价指标值时,即结束特征添加,当前添加的特征个数为最终选择的特征个数,使用当前特征个数进行机器学习建模,并进行交叉检验参数优化,根据auc指标评价结果选择最优参数,并在该参数基础上建立最优模型;(4)模型验证:使用交互检验获取的最优模型对外部测试集进行模型验证。
11.优选的,步骤(1)所述的胆汁标记物为clu;所述的血清标志物包括37个血液生化指标、24个常规血液指标和两个肿瘤生物标志物。
12.优选的,步骤(2)所述的模型通过python(3.7.1版)中的sci-kit-learn库(0.19.2版)构建。
13.优选的,步骤(2)s1计算所有特征的重要性排序是通过下述方法得到:初始模型依据决策树回归检验结果,确定标志物与结局指标胆管癌相关性,依据相关性排序确定特征重要性排序。
14.优选的,所述的初始模型优化超参数的评估标准是十折交叉验证的平均auc值,优化参数包括树的数量(n_estimators),寻找最佳分割时要考虑决策树的特征数量(max_features),最大深度树的(max_depth)和类的权重(class_weight);
15.优选的,所述的最优参数通过下述方法得到:依据决策树回归检验结果,确定特征与结局指标胆管癌相关性,依据相关性排序确定特征排序。
16.本发明的第二目的是提供一种基于机器学习算法的胆管癌诊断模型的构建系统,
其应用于所述的构建方法,其包括:
17.数据采集模块,至少用于数据采集,获取样本数据集;
18.数据处理模块,至少用于从样本数据集中提取可用于构建评估模型的有效样本;
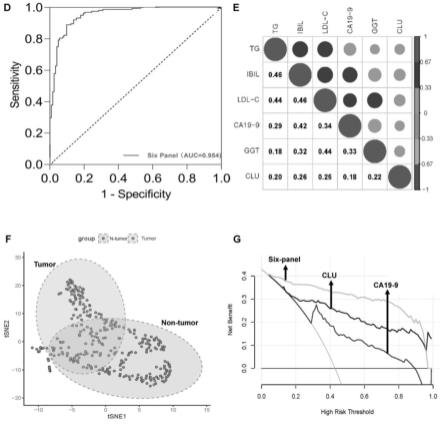
19.模型构建模块,至少用于将所述有效样本的不完整数据集随机分割为训练集和验证集,并使用随机森林的方法拟合训练集,根据袋外误差,记录最优模型参数;
20.阈值计算模块,至少用于根据roc曲线使用验证集计算模型分类阈值。
21.本发明的第三目的是提供一种基于机器学习算法的胆管癌诊断系统,包括:
22.为评价模型的预输入模块,至少用于输入待诊断数据;
23.由所述方法构建得到的胆管癌诊断模型,至少用于对该待评估数据进行评估;
24.显示模块,至少用于显示诊断结果。
25.本发明的第四目的是提供一种存储在计算机可读介质上的计算机程序产品,包括计算机可读程序,供于电子装置上执行时,提供用户输入接口以应用所述基于机器学习算法的胆管癌诊断系统。
26.本发明的第五目的是提供一种计算机可读存储介质,储存有指令,当所述指令在计算机上运行时,使得计算机应用所述基于机器学习算法的胆管癌诊断系统。
27.本发明的有益效果是:(1)本发明通过对1项胆汁标志物和常用的63项血清标志物进行筛选,通过机器学习模型筛选出6项最优参数,最优参数包括簇集蛋白(clu),间接胆红素(ibil),低密度脂蛋白胆固醇(ldlc),γ-谷氨酰基转移酶(ggt),糖类抗原19-9(ca19-9),甘油三酯(tg),预测测试样本患胆管癌风险概率,以及预测患者患有胆管癌的风险概率,为临床医生的诊断及治疗提供依据;(2)采用服务器-浏览器模式,网页界面友好,操作简单,实现了一键式快速分析,并可快速预测样本并输出结果;(3)采用自建数据库构建预测模型,该数据库样本量庞大且信息完备,所构建的预测模型预测性能准确、可靠,此模型的预测区分度指标包括敏感度、特异度和总acc、auc,分别为90.2%、89.0%、89.5%和0.954;临床决策曲线和tsne分析也显示该模型预测准确度良好。此外,将完全独立的218例组外验证患者纳入机器学习模型并验证该模型的准确性,结果显示外部验证组的auc为0.926,而临床决策曲线和tsne分析也验证了组外验证中该机器学习模型的预测准确度。
附图说明
28.图1病例筛选和收集流程图
29.图2随机森林模型筛选出排名前30的标志物注:按照准确率(左)和基尼指数(右)排序,越靠近右上方的特征越重要。
30.图3lasso模型筛选的多标志物联合诊断模型的准确性注:b:lasso模型筛选的的不同生物标志物组合的多标志物联合诊断模型的auc和准确度(acc)值;c:多标志物联合诊断模型的敏感性和特异性。
31.图4six-panel联合诊断模型的准确性分析注:d:six-panel及其成员的roc曲线;e:six-panel的六个标志物之间的相关矩阵,包括clu、ibil、ldl-c、ca19-9、ggt和tg,数字代表两个特征之间的相关系数(r);f:six-panel的tsne分析;g:six-panel、clu和ca19-9的dca分析,auc是曲线下的面积。r≥0.8表示高相关,0.5≤r《0.8表示强相关,0.3≤r《0.5表示弱相关,r《0.3表示无相关。图5cca six-panel模型及在线预测平台建立的总体流程
32.图6胆管癌的诊断网页示意图注:a:胆道狭窄患者寻求医疗帮助。b:用于输入六个标志物的网络界面。c:在线网站的结果页面,胆管癌的风险以百分比概率表示。
33.图7 预测病例示例1
34.图8 预测病例示例2
具体实施方式
35.为了使本技术领域的人员更好地理解本技术方案,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
36.本技术的说明书和权利要求书及上述附图中的术语“第一”、“第二”、“第三”、“第四”等(如果存在)是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
37.在本发明中,随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。该分类器最早由leo breiman和adele cutler提出,并被注册成了商标。在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。leo breiman和adele cutler发展出推论出随机森林的算法。而"random forests"是他们的商标。这个术语是1995年由贝尔实验室的tin kam ho所提出的随机决策森林(random decision forests)而来的。这个方法则是结合breimans的"bootstrap aggregating"想法和ho的"random subspace method"以建造决策树的集合。
38.随机森林的优点有:
39.1)对于很多种资料,它可以产生高准确度的分类器;
40.2)它可以处理大量的输入变数;
41.3)它可以在决定类别时,评估变数的重要性;
42.4)在建造森林时,它可以在内部对于一般化后的误差产生不偏差的估计;
43.5)它包含一个好方法可以估计遗失的资料,并且,如果有很大一部分的资料遗失,仍可以维持准确度;
44.6)它提供一个实验方法,可以去侦测variable interactions;
45.7)对于不平衡的分类资料集来说,它可以平衡误差;
46.8)它计算各例中的亲近度,对于数据挖掘、侦测离群点(outlier)和将资料视觉化非常有用;
47.9)使用上述。它可被延伸应用在未标记的资料上,这类资料通常是使用非监督式聚类。
48.也可侦测偏离者和观看资料;
49.10)学习过程是很快速的。
50.以下实施例中的十折交叉验证,英文名叫做10-fold cross-validation,用来测
试算法准确性。是常用的测试方法。将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率(或差错率)。10次的结果的正确率(或差错率)的平均值作为对算法精度的估计,一般还需要进行多次10折交叉验证(例如10次10折交叉验证),再求其均值,作为对算法准确性的估计。十折交叉验证之所以选择将数据集分为10份,是因为通过利用大量数据集、使用不同学习技术进行的大量试验,表明10折是获得最好误差估计的恰当选择,而且也有一些理论根据可以证明这一点。但这并非最终诊断,争议仍然存在。而且似乎5折或者20折与10折所得出的结果也相差无几。
51.交叉验证集用于通过机器学习建立诊断模型,外部验证集是用于验证模型诊断价值的独立队列。
52.在以下实施例中,连续变量表示为中位数(四分位间距)或平均值
±
sd(标准差),并使用mann-whitney u检验或t检验进行比较。分类变量表示为比率,并通过卡方检验相互比较。roc曲线和auc面积主要用于评估诊断性能。通过标准的2
×
2列联表计算灵敏度、特异性和准确性。p值小于0.05被认为具有统计学意义。所有分析均使用spss statistics20、graphpad prism 7.0版和r 4.1.0版(r foundation for statistical computing;http://www.r-project.org)进行。
53.实施例一、一种基于随机森林胆管癌诊断模型的构建方法
54.包括如下步骤:
55.(1)获取样本集:收集胆管癌和胆道良性狭窄患者的胆汁和血清标志物数据,组成样本集;
56.所述的胆汁标记物为clu;所述的血清标志物包括37个血液生化指标、24个常规血液指标和两个肿瘤生物标志物。
57.37个血液生化指标包括:总胆红素,间接胆红素,直接胆红素,碱性磷酸酶,总胆汁酸,γ-谷氨酰基转移酶,谷丙转氨酶,谷草转氨酶,谷丙转氨酶/谷草转氨酶,总蛋白,球蛋白,白蛋白,白蛋白/球蛋白,淀粉酶,肌酸激酶,胆固醇,甘油三酯,同型半胱氨酸,肌酸激酶同工酶,乳酸脱氢酶,尿酸,尿素,钙离子,镁离子,钠离子,α羟丁酸脱氢酶,低密度脂蛋白胆固醇,高密度脂蛋白胆固醇,葡萄糖,渗透压,阴离子间隙,无机磷,钾离子,氯离子,肌酐,尿素/肌酐,二氧化碳等。24个血液常规指标包括:白细胞,红细胞,血红蛋白,红细胞压积,平均红细胞压积,平均血红蛋白含量,平均血红蛋白浓度,血小板,淋巴百分比,单核细胞百分比,中性粒细胞百分比,噬酸细胞百分比,噬碱细胞百分比,淋巴细胞绝对值,单核细胞绝对值,中性粒细胞绝对值,噬酸细胞绝对值,噬碱细胞绝对值,红细胞宽度(sd),红细胞宽度(cv),血小板宽度,血小板体积,血小板比积,大血小板比率。两个肿瘤标志物包括:癌胚抗原,糖类抗原19-9。
58.(2)构建随机森林模型:
59.s1.初始模型构建:建立具有所有特征的初始分类模型,根据步骤(1)得到样本集-构建决策树,对初始模型进行优化,根据优化后的模型,计算所有特征的重要性排序;计算所有特征的重要性排序是通过下述方法得到:初始模型依据决策树回归检验结果,确定标志物与结局指标胆管癌相关性,依据相关性排序确定特征重要性排序。
60.s2.特征选择及模型二次优化:根据s1得到的所有特征的重要性排序,将用于建模的特征按照重要性从高到低添加到分类器中重新进行随机森林建模,并经由十折交互检验
评价获取每个模型的最优参数值,并对每个特征进行排序;所述的初始模型优化超参数的评估标准是十折交叉验证的平均auc值,优化参数包括树的数量(n_estimators),寻找最佳分割时要考虑决策树的特征数量(max_features),最大深度树的(max_depth)和类的权重(class_weight);(3)构建lasso模型获取最优模型:以最少的标志物具备最大的诊断效能为准则,利用lasso模型,随机组合初筛出的特征,按照组合数量递增的方法筛选出不同标志物数量下的最佳组合,当添加的特征不再能够增加模型的auc评价指标值时,即结束特征添加,当前添加的特征个数为最终选择的特征个数,使用当前特征个数进行机器学习建模,并进行交叉检验参数优化,根据auc指标评价结果选择最优参数,并在该参数基础上建立最优模型;所述的模型通过python(3.7.1版)中的sci-kit-learn库(0.19.2版)构建。所述的最优参数通过下述方法得到:依据决策树回归检验结果,确定特征与结局指标胆管癌相关性,依据相关性排序确定特征排序。
61.(4)外部验证分析
62.依据同样标准纳入本中心后续2021年1月至2022年3月胆管癌患者87例,对照组131例,用于验证机器学习预测模型的预测性能。我们收集患者机器学习模型中的六个指标数据来进行胆管癌预测,依据网页工具计算输出预测值及患者发病情况,绘制roc曲线模型,通过计算模型约登指数,评估模型敏感性、特异性和auc,以验证机器学习模型预测区分度。此外,通过计算绘制临床决策曲线和tsne分析以验证模型预测准确性。
63.实施例二、一种基于随机森林胆管癌诊断模型的应用
64.本研究经兰州大学第一医院人类研究伦理委员会(ldyyll2022-381)批准,豁免知情同意,并按照赫尔辛基原则宣言进行。
65.临床标本来自两个中心。共有505名患者被分为交叉验证集和外部验证集进行研究。在交叉验证集中,2019年1月至2022年3月兰州大学第一医院普外科招募了287例患者,其中胆管癌患者123例,胆道良性狭窄患者164例。良性胆道狭窄主要分为三类,一类是胆总管(cbd)结石合并胆管炎,一类是肝内胆管(ibd)结石合并胆管炎,另一类是cbd和ibd结石合并胆管炎。胆管癌患者主要通过病理结果确诊。两组患者的基本信息见表1。
66.交叉验证集和外部验证集中所有患者的血常规和血生化指标均通过临床信息收集。胆汁主要在ercp或ptcd或手术期间收集。胆汁样品在获得后立即冰上运输,然后在4℃以3000
×
g离心15分钟,收集上清液并储存在-80℃直至实验。
67.表1病人基本信息
68.[0069][0070]
bbs:良性胆道梗阻;cbd:胆总管结石
[0071]
ibd:肝内胆管结石;tbil:总胆红素;ggt:γ-谷氨酰转移酶
[0072]
对所有纳入临床资料参数进行分析,纳入随机森林建模,建立决策树进行分析。建立随机森林模型,本模型包含数据获取及运算处理,rf建模及logistic对比建模验证,组外验证评估,网络预测平台构建。
[0073]
在rf模型中,纳入总体样本以5:1的比例随机划分为训练建模集和交叉验证集。为评价模型的预测可靠性,采用灵敏度、特异度、准确度、auc等4个常用评价标准对两种方法进行比较。初步划分训练集与测试集,经数据不平衡处理后,本研究样本量增至287例,采用十倍交叉验证以8:2的比例划分训练集和测试集,其中训练集包含230例样本,用于模型的构建及参数调整,测试集包含57例样本,用于对所建立的模型进行检测和评价。
[0074]
随机森林(rf)和lasso在glment版本4.1-3中进行。
[0075]
通过将生物标志物与不同类型的循环生物标志物相结合,可以提高其诊断性能。用于机器学习的每位患者的数据包含胆汁clu和常见的63个血液指标,包括37个血液生化指标、24个常规血液指标和两个肿瘤生物标志物。在交叉验证集中,使用随机森林(rf)模型对上述特征进行分类。
[0076]
如图2所示,根据其准确性(左)和基尼指数(右)进行筛选,前30个标志物被筛选出来。
[0077]
为了选择最合适的特征,选择了12个基尼指数≥0.25的标志物进行进一步研究,包括clu、dbil、tbil、ca19-9、ibil、ldlc、ggt、alp、tg、ast、cl和alt。并且它们的auc值大约均等于或高于0.7。选择最合适的标志物数量对于建立最终分类模型至关重要。基于上述12个选定的标志物,应用lasso方法进行筛选。当组合包含不同数量的标志物时,lasso筛选出了最佳组合。roc分析结果如表2和图3b所示,five-panel的auc值最高(0.958)。six-ten panel的auc值相同,均为0.954,但acc值最高。故在后续实验中,选择six-ten panel进行相关实验。
[0078]
表2标志物和标志物组合的诊断价值
[0079][0080]
为了评价lasso模型筛选的多标志物联合诊断模型的准确性,选择six-ten panel检测其灵敏度和特异性,实验结果如图3c所示,可知six-ten panel的灵敏度和特异性均比较理想(灵敏度:90.2%,特异性:89.0%)。综上所述,six-panel模型在复杂性和准确性之间表现出良好的平衡,因此被确定为诊断胆管癌的最佳模型。
[0081]
six-panel模型的auc值显著对照组(图4d)。并且六种生物标志物之间几乎没有相关性(r《0.5),表明它们可以形成一个很好的诊断模型(图4e)。six-panel的tsne结果显示,胆管癌组和对照组形成了不同的聚类(图4f),表明即使在可视化条件下,six-panel也能很好地区分胆管癌。dca结果表明,six-panel在鉴别胆管癌和良性胆道狭窄方面提高了更多的临床整体益处(图4g)。
[0082]
为了进一步评估six-panel的稳定性和可靠性,我们将其应用于独立的外部验证集。在外部验证集中,six-panel表现出良好的的预测能力,auc为0.926,灵敏度为86.2%,特异性为85.3%,明显高于单独的clu(auc为0.840)。tsne和dca分析也显示出很好的诊断能力。综上所述,这些结果表明six-panel可以准确预胆管癌的发生,满足临床决策的实际
需要。
[0083]
实施例三、基于six-panel的胆管癌预测网站建立
[0084]
为了方便用户快速使用该模型诊断胆管癌,我们基于中心数字疾病预测平台(cppdd)建立了一个方便用户的在线网络公开预测平台,(该平台包含此rf模型应用网络计算服务器,以此6项独立危险因素作为预测计算因子,访问网址为http://cppdd.cn/cca/)。cca six-panel模型及在线预测平台建立的总体流程如图5所示。
[0085]
该网站主要由六个选定的标志物组成,用户只需在相应的文本框中输入标志物的具体数值,然后点击“提交”按钮即可切换到结果页面,方便且实用,如图6所示。经过计算和分析,模型会在结果页面上以百分比概率的形式得出该患者是否患有胆管癌的结论。使用模型时要特别注意的是,输入指标的单位应该与相应文本框后面的单位相同。
[0086]
预测病例示例如图7所示,某胆管癌患者的6项指标为:ca19-9:1000u/ml,clu:1948.5ng/ml,ibil:89μmol/l,ggt:1563u/ml,ldlc:3.8mmol/l,tg:2.58mmol/l。将该6个指标的数据输入网页后得到如下结果:“this sample is identified with cca with 92%probability”。即就是说,经rf模型网络预测平台预测,患者得胆管癌的概率为92%。
[0087]
预测病例示例如图8所示,某胆管结石患者的6项指标为:ca19-9:17.7u/ml,clu:165.8ng/ml,ibil:10.3μmol/l,ggt:34u/ml,ldlc:2.4mmol/l,tg:1.25mmol/l。将该6个指标的数据输入网页后得到如下结果:“this sample is identified without ccawith85%probability.”。即就是说,经rf模型网络预测平台预测,患者不得胆管癌的概率为85%。
[0088]
综上所述,本发明通过对常用的1项胆汁标志物和63项血清标志物进行筛选,通过随机森林模型筛选出6项最优参数,最优参数包括簇集蛋白(clu),间接胆红素(ibil),低密度脂蛋白胆固醇(ldlc),γ-谷氨酰基转移酶(ggt),糖类抗原19-9(ca19-9),甘油三酯(tg),预测测试样本患胆管癌风险概率,以及预测患者患有胆管癌的风险概率,为临床医生的诊断及治疗提供依据;采用服务器-浏览器模式,网页界面友好,操作简单,实现了一键式快速分析,并可快速预测样本并输出结果;采用自建数据库构建预测模型,该数据库样本量庞大且信息完备,所构建的预测模型预测性能准确、可靠,此模型的预测区分度指标包括敏感度、特异度和总acc、auc,分别为90.2%、89.0%、89.5%和0.954;临床决策曲线和tsne分析也显示该模型预测准确度良好。此外,将完全独立的218例组外验证患者纳入机器学习模型并验证该模型的准确性,结果显示外部验证组的auc为0.926,而临床决策曲线和tsne分析也验证了组外验证中该机器学习模型的预测准确度。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1