一种基于多尺度交叉注意力模型的RNA修饰位点预测方法
一种基于多尺度交叉注意力模型的rna修饰位点预测方法
技术领域
1.本发明涉及生物信息学rna转录后修饰位点预测领域,特别涉及一种基于多尺度交叉注意力模型的rna中n
1-甲基腺苷修饰位点预测方法。
背景技术:
2.研究表明,通过转录后rna修饰的表观转录组调控对于所有种类的rna都是必不可少的,所以,准确识别rna修饰对于理解其目的和调控机制至关重要。
3.传统的rna修饰位点识别实验方法相对复杂、费时、费力。机器学习方法已经应用于rna序列特征提取和分类的计算过程中,可以更有效地补充实验方法。近年来,卷积神经网络(convolutional neural networks,cnn)和长时记忆(long short-term memory,lstm)由于在表征学习方面的强大功能,在修饰位点预测方面取得了显著的成就。
4.然而,卷积神经网络(cnn)可以从空间数据中学习局部响应,但不能学习序列相关性;长时记忆(lstm)专门用于序列建模,可以同时访问上下文表示,但与cnn相比缺乏空间数据提取。由于以上原因,使用自然语言处理(natural language processing,nlp)、其他深度学习(deeplearn,dl)构建预测框架的动力十分强烈。
5.现有技术中,在构建预测框架时,使用注意力机制虽然可以关注到句子上下文的重要特征,但是单个注意力序列之间缺乏信息交互,难以描述复杂方面词的上下文关系;且没有充分联系上下文,加强文本中重要词汇对甲基化位点预测的影响。
技术实现要素:
6.基于此,有必要针对上述技术问题,提供一种基于多尺度交叉注意力模型的rna修饰位点预测方法。
7.本发明实施例提供一种基于多尺度交叉注意力模型的rna修饰位点预测方法,包括:
8.对包含n
1-甲基腺苷修饰位点的rna碱基序列为正样本和不包含n
1-甲基腺苷修饰位点的rna碱基序列为负样本,每个样本取3组不同尺度的rna碱基序列作为输入序列;
9.对3组输入序列均依次进行word2vec词嵌入编码和位置编码;
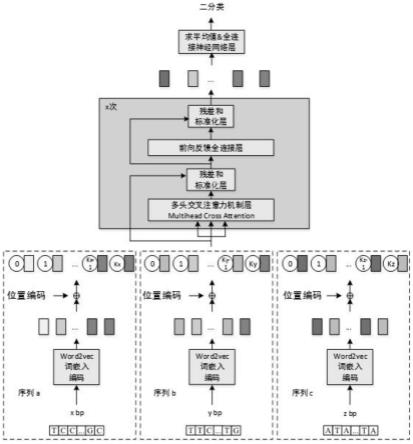
10.将编码后的3组序列编码模块中,获得特征序列;其中,所述编码模块包括:多个依次串联的编码块;所述编码块包括:一个多头交叉注意力层和一个前向反馈全连接层,且每层之间通过残差连接和标准化层;
11.将经过编码模块的输出结果求平均值,后经过全连接神经网络层和两分类器,预测人类物种rna碱基序列中是否包含n
1-甲基腺苷修饰位点。
12.进一步地,构建数据集;所述数据集包括:rna碱基序列为正样本、rna碱基序列为负样本和类别标签,且样本长度是41bp;输入序列设为序列a、序列b和序列c,其分别是长度为xbp、ybp、zbp不同尺度序列组成的集合;
13.所述数据集的训练集与测试集表示为:
[0014][0015]
其中,yn∈{0,1},分别表示样本长度为xbp、ybp、zbp不同尺度的辅助序列,辅助序列是以序列中心为中心点左右截取不同尺度的序列。
[0016]
进一步地,所述每个样本取3组不同尺度的rna碱基序列作为输入序列,包括:
[0017]
数据集中样本序列是以共同基序a为中心,前后取值窗口为大小不同的bp,以x1bp、y1bp、z1bp共3个不同为例,即每个m1a正样本/负样本由xbp、ybp、zbp组成,当样本序列在某些位置不存在碱基时,缺少碱基使用
‘‑’
字符填充;此处设x1=10,y1=15,z1=20,因此,x=21,y=31,z=41。
[0018]
进一步地,所述word2vec词嵌入编码,具体包括:
[0019]
利用大小为3个碱基的窗口,每次滑动1个碱基的形式,在每条样本序列上滑动,直到窗口碰到序列最末端时滑动结束,由此会获得105种不同的子序列和唯一的整数序列组成的字典;
[0020]
针对不同尺度的样本序列,分别使用word2vec的cbow模型编码rna序列;对于41个碱基的样本,利用大小为3个碱基的窗口,每次滑动1个碱基的形式,在每条样本序列上滑动,直到窗口碰到序列最末端时滑动结束,由此,得到39个由3个碱基组成的子序列,使用word2vec的cbow模型编码rna序列,因此,每个子序列被转换成表征语义的词向量,再利用得到的词向量将rna碱基序列中长度为41bp转换成39*100的矩阵,其中,39为预处理时词的个数,100为词向量维度。
[0021]
进一步地,所述编码模块包括:3个依次串联编码块。
[0022]
进一步地,所述编码模块包括:
[0023]
模型输出的维度d
model
=64,多头数h=8,前向反馈网络维度d_ff=256,暂时从网络中丢弃的概率为dropout=0.1。
[0024]
进一步地,所述多尺度交叉注意力层,包括:
[0025]
序列a进行自注意力计算的同时,序列a分别与序列b、序列c进行交叉注意力计算,交叉注意力是指第一个序列用作查询query输入,另一个序列用做键key输入和值value输入,进行注意力计算;将3种注意力的输出结果加起来作为交叉注意力层的输出,实现多尺度交叉注意力层。
[0026]
进一步地,所述多尺度交叉注意力层中的交叉注意力机制算法,包括:
[0027]
多个相同维度不同尺度的独立序列,其中,第一个序列用作查询query输入,剩下序列分别与第一个序列进行注意力计算,即剩下序列在进行注意力计算时,用做键key输入和值value输入;其具体包括:
[0028]
一个序列为序列a,另一个序列为序列b,序列a做查询输入,序列b中每个键与值对应;将序列a的查询与序列b的键之间先做矩阵相乘再做放缩,产生一个注意力得分;使用softmax函数对注意力得分做归一化处理,得到每个键的权重,将权重矩阵相乘序列b的值得到交互注意力输出,其对应的等式如下:
[0029][0030]
其中,softmax的作用是对向量做归一化,即对相似度的归一化,得到了一个归一
化之后的权重矩阵,矩阵中,某个值的权重越大,表示相似度越高。qa是序列a查询向量、kb是序列b键向量、vb是序列b值向量,dk为序列b键向量的维度大小,k
bt
为序列b键向量的转置;当输入序列为x时,首先使用线性投影将序列x转换成q
x
、k
x
、v
x
,它们们都是从同样的输入序列x线性变换而来的,通过以下等式表示:
[0031]qx
=xwq[0032]kx
=xwk[0033]vx
=xwv[0034]
上式中,wq,wk,wv是对应的投影矩阵,其值最初随机初始化,最终值由网络自己学习得到。
[0035]
进一步地,所述多头交叉注意力层的算法,包括:
[0036]
将多尺度交叉注意力机制中的不同序列的查询、键和值分别h次线性投影到dk、dk和dv维度上,其中dv为值向量v的维度大小,在每个查询、键和值的投影版本上,并行执行交叉注意力机制,产生dv维度的输出值;将以上h次集成交叉注意力的输出值拼接起来,再次投影到线性网络,产生最终值;即所述多头多尺度交叉注意力层对应的数学公式形式如下:
[0037]
multihead(q,k,v)=concat(head1,...,headh)wo[0038][0039]
其中,concat为对多个多尺度交叉注意力的输出headi拼接,i取值正整数,代表第i头数,wo为多个多尺度交叉注意力拼接的权重,qa是序列a查询向量,ka、kb、kc分别是序列a键向量、序列b键向量、序列c键向量、va、vb、vc是序列a值向量、序列b值向量、序列c值向量;
[0040]
一个序列为序列a,另一个序列为相同序列a,序列a做查询输入,序列a中每个键与值对应,此时做自注意力机制,代表此时查询向量qa的权重,代表此时键向量ka的权重,代表此时值向量va的权重,三个权重最初随机初始化,最终值由网络自己学习得到;一个序列为序列a,另一个序列为相同序列b,序列a做查询输入,序列b中每个键与值对应,此时做注意力机制,代表此时查询向量qa的权重,代表此时键向量kb的权重,代表此时值向量vb的权重,三个权重最初随机初始化,最终值由网络自己学习得到;一个序列为序列a,另一个序列为相同序列c,序列a做查询输入,序列c中每个键与值对应,此时做注意力机制,代表此时查询向量qa的权重,代表此时键向量kc的权重,代表此时值向量vc的权重,三个权重最初随机初始化,最终值由网络自己学习得到,且r为代表集合实数集,实数集是包含所有有理数和无理数集,此处dk=8;dv为值向量v的维度大小,此处dv=8;d
model
为输出维度,此处d
model
=64;
[0041]
以上公式,使用h=8个并行注意力层或头,对于其中的每一个,使用dk=dv=d
model
/h=8。
[0042]
进一步地,所述前向反馈全连接层,包括:
[0043]
两个线性变换,中间有一个relu激活函数;所述前向反馈全连接层对应的数学公式形式如下:
[0044]
ffn(x)=max(0,xw1+b1)w2+b2[0045]
公式中,w1、w2、b1和b2分别为反馈全连接层的参数;max()即代表了relu激活函数。
[0046]
本发明实施例提供的上述基于多尺度交叉注意力模型的rna修饰位点预测方法,与现有技术相比,其有益效果如下:
[0047]
本发明将待预测的序列确定为3组不同尺度的输入序列,再均依次进行词嵌入编码和位置编码,然后将处理后的3个序列分别送入编码模块,即串联的3个编码块中,最后对编码处理后的值累加求平均值后经过全连接神经网络层和两分类器、以预测人类物种rna碱基序列中是否包含n
1-甲基腺苷修饰位点。其中,多尺度交叉注意力层,包括:序列a进行自注意力计算的同时,序列a分别与序列b、序列c进行交叉注意力计算,交叉注意力是指第一个序列用作查询(query)输入,另一个序列用做键(key)输入和值(value)输入,进行注意力计算,然后将3种注意力的输出结果加起来作为交叉注意力层的输出,实现多尺度交叉注意力层。
附图说明
[0048]
图1为一个实施例中提供的基于多尺度交叉注意力模型的示意图;
[0049]
图2为一个实施例中提供的交叉注意力机制示意图;
[0050]
图3为一个实施例中提供的三路交叉注意力机制结构图。
具体实施方式
[0051]
为了使本技术的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本技术进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本技术,并不用于限定本技术。
[0052]
本发明实施例提供的一种多尺度交叉注意力模型的rna修饰位点预测方法,该方法具体包括:
[0053]
1)收集正负样本数据集:获得人类物种rna的n
1-甲基腺苷(n1
–
methyladenosine,m1a)修饰位点数据集,数据集包括正负数据集的rna样本序列以及所对应的类别标签,样本长度是41bp(base pair,bp),本模型要求每个样本取3组不同尺度的rna碱基序列作为输入序列,分别设序列a、序列b和序列c分别是长度为xbp、ybp、zbp不同尺度序列组成的集合,因此,本模型的训练集与测试集可以表示为以下这种形式其中,yn∈{0,1},表示第i个样本长度为xbp、ybp、zbp不同尺度的辅助序列(side sequence),辅助序列是以序列中心为中心点左右截取不同尺度的序列;
[0054]
1-1)训练集和测试集中含有n
1-甲基腺苷修饰位点的rna作为正样本,不含有n
1-甲基腺苷修饰位点的rna作为负样本。
[0055]
其中,正负样本规定:正样本序列(m1a甲基化位点序列)是以n1-甲基腺苷修饰位点(碱基a)为中心的前后取共同长度(或共同个碱基)的序列。负样本序列中心的碱基也是
a,但它不是n
1-甲基腺苷修饰位点,负样本序列也是以这个碱基a为中心前后取共同长度(或共同个碱基)的序列。以上正负样本共同长度一致,长度为41bp(base pair,bp)。
[0056]
1-2)数据集样本序列是以共同基序a为中心,前后取值窗口为20bp,当样本序列在某些位置不存在碱基时,缺少碱基使用
‘‑’
字符填充;可以得到每个m1a正样本/负样本由41bp组成,训练集包括593个正样本以及5930个负样本,测试集包括114个正样本以及1140个负样本。如表1所示:
[0057]
表1两个rna修饰数据集的统计
[0058][0059]
2)处理样本,将正负样本序列以共同基序a为中心,前后取值窗口为大小不同的bp,可以前后取值窗口为5的整数倍,即:10bp,15bp,20bp,这样就可以取21bp,31bp,41bp,且当样本序列在某些位置不存在碱基时,缺少碱基使用
‘‑’
字符填充。
[0060]
3)特征编码:利用大小为3个碱基的窗口,每次滑动1个碱基的形式,在每条样本序列上滑动,直到窗口碰到序列最末端时滑动结束,由此会获得105种不同的子序列和唯一的整数序列组成的字典。
[0061]
针对不同尺度的样本序列,分别使用word2vec的cbow模型编码rna序列。以样本长度为41个碱基的样本为例:样本有41个碱基,利用大小为3个碱基的窗口,每次滑动1个碱基的形式,在每条样本序列上滑动,直到窗口碰到序列最末端时滑动结束,由此,得到39个由3个碱基组成的子序列,使用word2vec的cbow模型编码rna序列,因此,每个子序列被转换成表征语义的词向量,再利用得到的词向量将rna碱基序列中长度为41bp转换成39*100的矩阵,其中,39为预处理时词的个数,100为词向量维度。word2vec模型作用是希望在高维空间捕捉词汇间的关系。
[0062]
4)引入位置编码:因为序列中的碱基位置之间存在着关联性,使用位置嵌入来引入位置信息。
[0063]
5)设计多视角分类学习模型:经过多头交叉注意机制层来学习多个不同尺度的词向量序列,接着进入前馈网络(ffn)。最后,对编码模块输出的值求平均值,之后,经过全连接神经网络层和两分类器、以预测人类物种rna碱基序列中是否包含n
1-甲基腺苷修饰位点。
[0064]
需要说明的是,编码模块输入=嵌入式编码输入+位置编码。
[0065]
嵌入式编码输入是通过常规embedding层,将每一个词的向量维度从词向量维度映射到d
model
,由于是相加关系,因此,这里的位置编码也是一个d
model
维度的向量。
[0066]
位置编码不是单一的一个数值,而是包含句子中特定位置信息的d维向量(非常像词向量),这种编码没有整合进模型,而是用这个向量让每个词具有它在句子中的位置的信息。换句话说,通过注入词的顺序信息来增强模型输入。给定一个长度为m的输入序列,让s表示词在序列中的位置,表示s位置对应的向量,表示s位置向量里的第i个元素,d
model
是编码模块的输入和输出的维度,也是位置编码的维度。是生成位置向量的函数,定义如下:
[0067][0068]
其中把d
model
维的向量两两一组,每组都是一个sin和一个cos,这两个函数共享同一个频率ωk,一共有d
model
/2组,由于我们从0开始编号,所以最后一组编号是d
model
/2-1。sin和cos函数的波长(由ωi决定)则从2π增长到2π*10000。
[0069]
对于上述步骤的具体说明如下:
[0070]
数据集样本序列是以共同基序a为中心,前后取值窗口为大小不同的bp,以x1bp、y1bp、z1bp共3个不同为例,即每个m1a正样本/负样本由xbp、ybp、zbp组成,当样本序列在某些位置不存在碱基时,缺少碱基使用
‘‑’
字符填充,本专利设x1=10,y1=15,z1=20,因此,x=21,y=31,z=41;碱基序列先经过word2vec词嵌入编码,然后直接经过位置编码,经过编码模块,编码模块由3个编码块组成,每个编码块包括多头交叉注意力机制层、前向反馈传播网络,每层之间通过残差连接(residual connection)和标准化层(layer normalization),残差连接用于防止网络退化,可以避免梯度消失的问题。标准化层用于对每一层的激活值进行归一化。如图1所示。
[0071]
其中,编码模块的输入和输出的维度d
model
=64,多头数h=8,前向反馈网络维度d_ff=256,dropout=0.1,dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。
[0072]
输入分别是有标签的碱基序列,从编码器输入的句子首先会经过一个多头交叉注意力层,多头代表执行多次。设序列a、序列b和序列c分别是长度为xbp、ybp、zbp不同尺度序列组成的集合,因此,编码块中的交叉注意力是指第一个序列用作查询(query)输入,另一个序列用做键(key)输入和值(value)输入,进行注意力计算,如图2所示。最终,将3种注意力的输出结果加起来作为交叉注意力层的输出,如图3所示。
[0073]
交叉注意力输入是两个不同的序列,其中一个序列用作查询输入,而另一个用作键和值输入。
[0074]
交叉注意力机制的具体算法,如图2所示,一个序列为序列a,另一个序列为序列b,序列a做查询输入(query),为了捕捉序列b中每个值(value),需要序列b中每个键(key)与值(value)对应。
[0075]
将序列a的查询(query)与序列b的键(key)之间先做矩阵相乘(matmul)再做放缩(scale),可以得到一个注意力得分,使用softmax函数对注意力得分做归一化处理,得到每个键的权重,将权重矩阵相乘序列b的值得到交互注意力输出,其对应的等式如下所示:
[0076][0077]
其中,公式中softmax的作用是对向量做归一化,那么就是对相似度的归一化,得到了一个归一化之后的权重矩阵,矩阵中,某个值的权重越大,表示相似度越高。qa是序列a查询向量(query vector)、kb是序列b键向量(key vector)、vb是序列b值向量(value vector),dk为kb的维度大小,k
bt
为序列b键向量的转置。以输入序列x为例,首先使用线性投
影将序列x转换成q
x
、k
x
、v
x
,它们都是从同样的输入序列x线性变换而来的,通过以下等式表示:
[0078]qx
=xwq[0079]kx
=xwk[0080]vx
=xwv[0081]
上式中,wq,wk,wv是对应的投影矩阵,其值最初随机初始化,最终值由网络自己学习得到。输入序列x与wq经过序列乘法得到q
x
,同理的方法得到k
x
,v
x
。
[0082]
如图3所示,将3路注意力层的输出结果相加,实现交叉注意力层的作用,将以上多尺度交叉注意力机制中的不同序列的查询、键和值分别h次线性投影到dk、dk和dv维度上,其中dv为值向量v的维度大小,然后,分别在每个查询、键和值的投影版本上,并行执行交叉注意力机制,产生dv维度的输出值。将以上h次集成交叉注意力的输出值拼接起来,再次投影到线性网络,产生最终值,所述多头多尺度交叉注意力层对应的数学公式形式如下:
[0083]
multihead(q,k,v)=concat(head1,...,headh)wo[0084][0085]
其中,concat为对多个多尺度交叉注意力的输出headi拼接,i取值正整数,代表具体第i头数,wo为多个多尺度交叉注意力拼接的权重,qa是序列a查询向量,ka、kb、kc分别是序列a键向量、序列b键向量、序列c键向量、va、vb、vc是序列a值向量、序列b值向量、序列c值向量。
[0086]
一个序列为序列a,另一个序列为相同序列a,序列a做查询输入,序列a中每个键与值对应,此时做自注意力机制,代表此时查询向量qa的权重,代表此时键向量ka的权重,代表此时值向量va的权重,三个权重最初随机初始化,最终值由网络自己学习得到。一个序列为序列a,另一个序列为序列b,序列a做查询输入,序列b中每个键与值对应,此时做交叉注意力机制,代表此时查询向量qa的权重,代表此时键向量kb的权重,代表此时值向量vb的权重,三个权重最初随机初始化,最终值由网络自己学习得到。一个序列为序列a,另一个序列为序列c,序列a做查询输入,序列c中每个键与值对应,此时做交叉注意力机制,代表此时查询向量qa的权重,代表此时键向量kc的权重,代表此时值向量vc的权重,三个权重最初随机初始化,最终值由网络自己学习得到。其中,r为代表集合实数集,实数集是包含所有有理数和无理数的集合;dk为键向量k的维度大小,此处dk=8;dv为值向量v的维度大小,此处dv=8;d
model
为输出维度,此处d
model
=64。
[0087]
以上公式,使用h=8个并行注意力层或头。对于其中的每一个,我们使用dk=dv=d
model
/h=8。
[0088]
然后经过残差连接(residual connection)和标准化层(layer normalization),残差连接用于防止网络退化,可以避免梯度消失的问题。标准化层用于对每一层的激活值
进行归一化。
[0089]
进一步进入前向反馈全连接层,包括:
[0090]
两个线性变换组成,中间有一个relu激活函数;即所述前向反馈全连接层对应的数学公式形式如下,其中max即代表了relu激活函数。
[0091]
ffn(x)=max(0,xw1+b1)w2+b2[0092]
公式中w1、w2、b1和b2分别为反馈全连接层的参数。
[0093]
需要说明的是,前向反馈全连接层的作用:单纯的多头注意力机制并不足以提取到理想的特征,因此增加全连接层来提升网络的能力。
[0094]
然后再经过残差连接(residual connection)和标准化层(layer normalization),残差连接用于防止网络退化,可以避免梯度消失的问题。标准化层用于对每一层的激活值进行归一化。
[0095]
进一步地,将经过编码模块输出的值求平均值,后经过全连接神经网络层和两分类器,预测人类物种rna碱基序列中是否包含n
1-甲基腺苷修饰位点。
[0096]
本发明实施例中,利用训练集,通过5折的方式验证模型的有效性:
[0097]
表2训练集5折预测结果
[0098]
classifiersaurocaccsenprecisionmccspef-1auprcbilstm0.924294.1155.1473.4860.6198.0163.000.701cnn0.898293.1662.3962.39586396.2462.390.6707bilstm+attlayer0.927094.2857.8473.6162.2597.9364.780.7069cnn+attlayer0.902693.3460.5464.2258.7196.6362.330.6644msca(21-31-41)0.946594.1061.672.6463.7197.5466.670.75
[0099]
msca(21-31-41)代表序列长度为21bp、31bp、41bp的样本作为输入,使用多尺度交叉注意力模型(multi-scale cross-attention model,msca)的模型。
[0100]
考虑到测试集正负样本是1:10,属于不平衡样本集,因此,通过精确召回曲线下面积(auprc)比较性能,通过表1所示,多尺度交叉注意力模型(multi-scale cross-attention model,msca)的精确召回曲线下面积(auprc)远远高于通过bilstm分类模型(bi-directional long short-term memory,bilstm)、cnn(convolutional neural network,cnn)、bilstm+attlayer(bilstm layer+bahdanau attention layer)、cnn+attlayer(convolutionalneuralnetwork layer+bahdanauattention layer)。
[0101]
其他,当精确度acc等关键指标比较时,msca也高于其他已知的优秀的分类。
[0102]
本发明实施例中,利用测试集验证模型的有效性:
[0103]
表3独立数据集评价
[0104]
classifiersaurocaccsenprecisionmccspef-1auprcbilstm0.903894.2555.2675.061.4393.3063.630.7253cnn0.910694.7358.7777.9064.9593.1467.000.7066bilstm+attlayer0.927694.9754.3884.9365.5894.1766.310.7642cnn+attlayer0.920794.8963.1576.5966.8492.5069.220.7538msca(21-31-41)0.940595.2162.2880.6868.4198.5170.300.7751
[0105]
以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并
不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1