一种基于MADDPG的城市传染病控制方法
一种基于maddpg的城市传染病控制方法
技术领域
1.本发明涉及疫情传播与控制仿真领域,尤其是涉及一种基于maddpg的城市传染病控制方法。
背景技术:
2.现代城市人群密集,人口流动量大,高速发展的城市化进程让传染病疾病传播速度更快、传播持续时间更长,尤其特大城市更容易成为疾病传播中心。同时,城市的经济、技术、信息网络,也影响着传染病的扩散和防控形势。因此,现代城市在推进城市化进程时,要加入公共卫生管理体系,提前建立城市传染病传播控制系统,做到及时发现,快速响应、综合协调、实时调整,能够尽可能地遏制传染病扩散,保证居民生命安全,减少社会经济损失。
3.传染病控制是通过限制感染人群的移动、降低人群接触,进而限制病毒传播。目前的传染病控制策略存在控制保守、响应不及时、策略僵化等诸多难点。虽然可以达到抑制病毒传播的效果,但是会影响群众正常活动、浪费城市公共卫生资源、增加社会经济损失,不利于城市发展和群众幸福安全。
4.现有传染病控制方法存在以下问题:1)经典sir传染病模型在细节上存在很多局限性,人群划分简单粗糙,忽略了地域差异,忽略了传染病感染机制的复杂性和城市人口密集、交通发达的特点;2)传染病传播过程复杂多变,控制策略存在时延和不精确性。
5.如何高效制定传染病控制策略,对城市不同区域环境传染病情况因地制宜,灵活变通是现代城市传染病传播控制过程中亟需解决的问题。
技术实现要素:
6.本发明的目的就是为了提供一种基于maddpg的城市传染病控制方法,利用城市人口和交通流量数据,针对城市的不同区域,灵活控制出行流量,控制传染病的传播。
7.本发明的目的可以通过以下技术方案来实现:
8.一种基于maddpg的城市传染病控制方法,包括以下步骤:
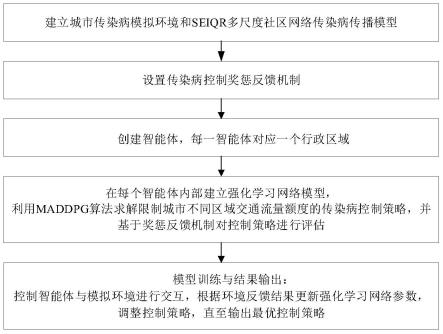
9.建立城市传染病模拟环境和seiqr多尺度社区网络传染病传播模型;
10.设置传染病控制奖惩反馈机制;
11.创建智能体,每一智能体对应一个行政区域;
12.在每个智能体内部建立强化学习网络模型,利用maddpg算法求解限制城市不同区域交通流量额度的传染病控制策略,并基于奖惩反馈机制对控制策略进行评估;
13.模型训练与结果输出:控制智能体与模拟环境进行交互,根据环境反馈结果更新强化学习网络参数,调整控制策略,直至输出最优控制策略。
14.所述seiqr多尺度社区网络传染病传播模型考虑到感染者和感染者的密切接触者都是孤立的这一要素,在传统的seir传播模型的易感态s、暴露态e、感染态i和恢复态r这四个状态的基础上新增两个状态:隔离暴露态qe和隔离感染态qi。
15.所述seiqr多尺度社区网络传染病传播模型中,如果一个易感个体s接触到另一个
暴露的个体,该个体有β的可能性变为暴露态e,每个暴露态的个体有θe的可能性变为隔离暴露态qe,暴露态和隔离暴露态的个体分别有σ和σe的可能性变为感染态i和隔离感染态qi,感染态的个体有θi的可能性变为隔离感染态,感染态和隔离感染态的个体分别有γ和γq的可能性变为康复者r,模型方程如下:
[0016][0017][0018][0019][0020][0021][0022]
n=s+e+i+qe+qi+r
[0023]
其中,β为个体传播率,βq为隔离状态下传染性个体的传播率,n为一个区域内总人数,γ为感染态个体的康复率,γq为隔离感染态个体的康复率,σ为暴露态e个体转移为感染态的概率,σe为隔离暴露态qe个体转移为感染态的概率,分别为τ时刻对应状态的导数。
[0024]
所述seiqr多尺度社区网络传染病传播模型在多尺度社区网络下计算偶然传播和密切传播感染率,所述社区网络由行政区网、乡镇区网、住宅小区网组成,每层网络都有对应的接触概率ba、b
t
和br,易感态s转移为暴露态e的感染方式分为偶然接触感染和密切接触感染,根据感染方式和对应的传播概率确定易感态转移为暴露态的概率。
[0025]
假定节点间接触的可能性相等,偶然接触感染的传播概率tg为:
[0026][0027]
其中,β为个体传播率,βq为隔离状态下传染性个体的传播率,n为一个区域内总人数。
[0028]
将个体的密切接触者定义为接触网络中与给定节点相邻的节点,密切接触感染的传播概率t
l
为:
[0029][0030]
其中,cg(i)表示个体i的密切接触者集合,即接触网络图g中节点i相邻的节点的集合;|cg(i)|表示集合的大小,即个体i所拥有的密切接触者的数量;xi表示第i个节点的状态;是xi的指示函数,表示具有指定状态的节点状态。
[0031]
个体i从易感态s转移为暴露态e的概率p(i)(s
→
e)为:
[0032]
[0033]
根据城市防控策略和不同区域间疾病传播特性动态变化感染概率,模拟城市人群传染病传播环境,具体为:
[0034]
将城市按照行政区域划分为多个区域,控制每个区域当前时刻的人口流动百分比pi,τ表示第τ时刻,每个区域当前实际移动人数为移动需求人数与人口流动额度乘积:
[0035][0036]
通过计算当前时刻区域间人口流动数量预测下一时刻传染病人数;
[0037]
区域通过观察当前时刻城市内所有区域的传染病状态和人口流动情况,确定当前的控制策略下感染者在感染期内平均直接传染人数r(τ),用泊松分布来拟合其感染过程,计算τ时刻感染率模拟传播过程:
[0038][0039][0040][0041]
其中,表示在τ时刻第i个节点的感染率,表示在τ时刻第i个节点的新增感染人数;
[0042]
利用连续时间人口流动时空数据集od获取当前时间段内区域的人群流入流出情况,计算区域当前时刻的传染病感染率,得到下一时刻区域的传染病状态
[0043]
所述强化学习网络模型的三要素为动作、状态和奖励,其中,所述动作为每个区域下一时刻的交通流量限制额度,限制区域间的交通需求,所述状态为区域内当前时刻的seiqr模型各状态人数、历史策略影响值和医疗资源使用情况,所述奖励为基于奖惩反馈机制对控制策略进行评估的衡量指标,取惩罚的负数,惩罚包括感染情况、区域内医院资源使用情况和市民限制出行程度。
[0044]
所述强化学习网络模型在进行决策时考虑控制策略执行延迟和执行不准确两个扰动因素,其中,所述执行延迟通过在智能体输出动作后,设定智能体以预设的概率继续保持上一阶段的动作来进行模拟,所述执行不准确通过为执行的动作添加随机偏差来进行模拟。
[0045]
与现有技术相比,本发明具有以下有益效果:
[0046]
(1)本发明提出了更符合实际的seiqr模型,并提出多尺度社区网络下计算偶然传播和密切传播感染率方法,动态计算不同控制策略下的感染率,感染模型更拟合现实传染病传播规律,建模更真实,得到的传播数据更可靠。
[0047]
(2)本发明考虑区域的地域差异性和感染过程的复杂性,考虑城市区域间流动人
群感染风险大于区域内停留人群,区域不同状态和地理特性需要动态调整感染率,根据控制策略和当前时刻区域传染病状态,结合区域下一时刻的交通流量需求,计算出城市所有区域下一时刻的传染病状态,动态性强,能够更精确的模拟传染病动态传播。
[0048]
(3)本发明考虑了传染病传播过程复杂多变,在控制策略执行时加入扰动因素:策略延迟因素和策略实施的不精确性因素,使得模型更具有健壮性和普适性。
[0049]
(4)本发明的控制策略不会完全禁止有传染病的区域的市民交通需求,通过对高风险的交通流量区域分配较低的额度,对低风险的区域交通流量分配较多的额度,能有效地降低疫情传播并保留尽量多的经济活动。
[0050]
(5)本发明通过多智能体强化学习的城市传染病控制方法,为每个区域制定符合区域特性且可以动态调整的控制策略,策略考虑区域差异性,将每一个区域作为一个智能体,输出符合自身情况的策略动作,能够针对城市不同区域灵活控制出行流量。
[0051]
(6)本发明的奖惩反馈机制同时考虑移动限制惩罚和感染惩罚,还考虑了区域内医院资源使用情况,通过计算当前时刻区域内医院治疗能力,显示传染病传播控制过程中医院资源使用变化情况,更具有实用性。
[0052]
(7)本发明通过记录从传染病开始,累计限制区域交通需求差额总量,得到在控制策略下,城市人群行动受限和经济受限情况,反映现实控制效果。
附图说明
[0053]
图1为本发明的方法流程图;
[0054]
图2为seiqr多尺度社区网络传染病传播模型控制原理示意图;
[0055]
图3为seiqr传播动力学模型图;
[0056]
图4为智能体内部结构示意图。
具体实施方式
[0057]
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
[0058]
一种基于maddpg的城市传染病控制方法,如图1所示包括以下步骤:
[0059]
1)建立城市传染病模拟环境和seiqr多尺度社区网络传染病传播模型,其控制原理示意图如图2所示。
[0060]
seiqr多尺度社区网络传染病传播模型考虑到感染者和感染者的密切接触者都是孤立的这一要素,在传统的seir传播模型的易感态s、暴露态e、感染态i和恢复态r这四个状态的基础上新增两个状态:隔离暴露态qe和隔离感染态qi。在这个模型中,如果一个易感个体接触到一个暴露的个体,该个体有暴露的机会。每个暴露的个体都有转移到非隔离感染期的机会。非隔离的个体有一定的机会被隔离。每个被感染的个体都有机会成为被隔离的感染,并且被隔离的接触也有一定的机会转向被隔离的感染。最后,被感染和被隔离的感染分别有不同的恢复机会,并且假设每个康复的人都不会被再次感染。
[0061]
具体的,如果一个易感个体s接触到另一个暴露的个体,该个体有β的可能性变为暴露态e,每个暴露态的个体有θe的可能性变为隔离暴露态qe,暴露态和隔离暴露态的个体
分别有σ和σe的可能性变为感染态i和隔离感染态qi,感染态的个体有θi的可能性变为隔离感染态,感染态和隔离感染态的个体分别有γ和γq的可能性变为康复者r,模型方程如下:
[0062][0063][0064][0065][0066][0067][0068]
n=s+e+i+qe+qi+r
[0069]
其中,β为个体传播率,βq为隔离状态下传染性个体的传播率,n为一个区域内总人数,γ为感染态个体的康复率,γq为隔离感染态个体的康复率,σ为暴露态e个体转移为感染态的概率,σe为隔离暴露态qe个体转移为感染态的概率,分别为τ时刻对应状态的导数。
[0070]
seiqr多尺度社区网络传染病传播模型在多尺度社区网络下计算偶然传播和密切传播感染率,所述社区网络由行政区网、乡镇区网、住宅小区网组成,每层网络都有对应的接触概率ba、b
t
和br,即每层网络有自己的接触概率,每个网络的接触概率不同,可以更好的根据区域的自身情况进行模拟。
[0071]
易感态s转移为暴露态e的感染方式分为偶然接触感染和密切接触感染,根据感染方式和对应的传播概率确定易感态转移为暴露态的概率。密切接触是指经常重复、持续或近距离接触的人:家人、朋友或其他亲密关系。与之相反,偶然接触是指在不频繁的基础上偶然的或简短的接触,这种接触可能因为不同区域划分而产生跨行政区接触、跨乡镇接触和跨小区接触不同的接触概率。
[0072]
假定节点间接触的可能性相等,偶然接触感染的传播概率tg为:
[0073][0074]
其中,β为个体传播率,βq为隔离状态下传染性个体的传播率,n为一个区域内总人数。
[0075]
将个体的密切接触者定义为接触网络中与给定节点相邻的节点,密切接触感染的传播概率t
l
为:
[0076][0077]
其中,cg(i)表示个体i的密切接触者集合,即接触网络图g中节点i相邻的节点的集合;|cg(i)|表示集合的大小,即个体i所拥有的密切接触者的数量;xi表示第i个节点的状
态;是xi的指示函数,表示具有指定状态的节点状态。
[0078]
个体i从易感态s转移为暴露态e的概率p(i)(s
→
e)为:
[0079][0080]
seiqr传播动力学模型如图3所示。
[0081]
城市传染病开始传播后,存在防控措施干预的条件,传染病的实际感染率会因为控制策略、环境、偶然因素等随时间变化,本发明通过计算当前时刻控制策略下感染者在感染期内平均直接传染人数r(τ),用泊松分布来拟合其感染过程,得到当前时刻的感染率μ(τ)。
[0082]
本发明根据城市防控策略和不同区域间疾病传播特性动态变化感染概率,模拟城市人群传染病传播环境,具体为:
[0083]
将城市按照行政区域划分为多个区域,控制每个区域当前时刻的人口流动百分比pi,τ表示第τ时刻,每个区域当前实际移动人数为移动需求人数与人口流动额度乘积:
[0084][0085]
通过计算当前时刻区域间人口流动数量预测下一时刻传染病人数;
[0086]
区域通过观察当前时刻城市内所有区域的传染病状态和人口流动情况,确定当前的控制策略下感染者在感染期内平均直接传染人数r(τ),用泊松分布来拟合其感染过程,计算τ时刻感染率模拟传播过程:
[0087][0088][0089][0090]
其中,表示在τ时刻第i个节点的感染率,表示在τ时刻第i个节点的新增感染人数;
[0091]
利用连续时间人口流动时空数据集od获取当前时间段内区域的人群流入流出情况,计算区域当前时刻的传染病感染率,得到下一时刻区域的传染病状态
[0092]
2)设置传染病控制奖惩反馈机制。
[0093]
本发明中,奖惩反馈机制用于评价和反馈环境对智能体动作的响应,通过反馈的结果来更新智能体强化学习网络的参数,实现模型训练和更新。
[0094]
3)创建智能体,每一智能体对应一个行政区域。
[0095]
本发明将城市按行政区域划分,每个区域作为一个智能体,使用多智能体强化学习maddpg算法,控制城市传染病动态传播过程,获到每个时刻每个区域人群移动限制额度,
作用于城市动态传染病传播环境,根据环境反馈结果,优化控制策略。智能体间为无竞争、完全合作状态,共享全局奖励。
[0096]
智能体内部结构如图4所示。因为智能体均为城市区域,存在较大相似性,所以全局采用一个critic网络对所有智能体的actor网络输出动作进行评价和优化,每个智能体内部各有一个actor网络,输出每个区域下一时刻的控制动作。为了使得学习过程更加稳定,收敛更有保障,加入target网络和经验回放机制,从估计的目标和目标网络学习更新,并且存储元组列表(状态、动作、奖励、下一个状态),而不是仅仅从最近的经验中学习,而是从取样中学习到迄今为止积累的所有经验,从而保持它估计的目标稳定。
[0097]
4)在每个智能体内部建立强化学习网络模型,利用maddpg算法求解限制城市不同区域交通流量额度的传染病控制策略,并基于奖惩反馈机制对控制策略进行评估。
[0098]
强化学习通过与环境进行交互获得的奖赏指导行为,以“试错”的方式进行学习,不断调整改进动作策略,使智能体获得最大的奖赏。强化学习网络模型的三要素为动作、状态和奖励,其中,所述动作为每个区域下一时刻的交通流量限制额度,限制区域间的交通需求,所述状态为区域内当前时刻的seiqr模型各状态人数、历史策略影响值和医疗资源使用情况,所述奖励为基于奖惩反馈机制对控制策略进行评估的衡量指标,取惩罚的负数,惩罚包括感染情况、区域内医院资源使用情况和市民限制出行程度。在当前时刻,智能体向环境获取状态信息,根据强化学习maddpg算法得到各自的动作,环境对动作做出反馈,生成下一时刻智能体的状态信息和动作奖励值。
[0099]
强化学习网络模型在进行决策时考虑控制策略执行延迟和执行不准确两个扰动因素,其中,所述执行延迟通过在智能体输出动作后,设定智能体以预设的概率继续保持上一阶段的动作来进行模拟,所述执行不准确通过为执行的动作添加随机偏差来进行模拟。
[0100]
5)模型训练与结果输出:控制智能体与模拟环境进行交互,根据环境反馈结果更新强化学习网络参数,调整控制策略,直至输出最优控制策略。
[0101]
本实施例采用上海市2020年7月1日至2020年7月31日出租车gps数据集模拟城市人口流动。通过数据处理将上海市按照乡镇、街道级行政区划分为215个区域,统计7月31天共744个小时的gps数据得到od数据集,表示每小时每个区域去所有区域的人群数量矩阵。
[0102]
将上海市按照乡镇、街道行政区域划分为215个区域,第i个区域内人群总数为ni设区域传染病状态在传染病场景中,城市区域间人群流动会大大增加感染风险,因此,在计算区域新增感染人数时,将新增感染人群分为两部分,一部分为区域间移动感染者,另一部分为区域内停留感染者。
[0103]
在τ时刻,第i个区域人群总数为6类人群和:
[0104][0105]
设人群接触传染率为在τ时刻人群向第i区域移动过程中产生的新感染者人数为:
[0106]
[0107]
为第τ时刻区域j向区域i的移动人数,为第τ时刻区域j的总人数,k为区域总个数。
[0108]
当前区域内停留人群产生的新感染者人数为:
[0109][0110]
此时当前区域的传染病发病率为新增感染者数占易感者数比例:
[0111][0112]
根据τ时刻城市人口流动矩阵m
τ
可得,第i区域中6类人群增加人数为人群流入流出差:
[0113][0114]
第i区域内人群在τ+1时刻的传染病状态为:
[0115][0116]
其中,表示求解下一时刻区域i状态的函数。
[0117]
强化学习网络模型开始训练后,(1)先初始化传染病传播环境,根据城市实际情况设置传染病基本再生数r0、城市住院率和城市治愈率等相关超参数,搭建所有智能体的强化学习网络模型。(2)每4个小时作为一个阶段,每个智能体根据这一阶段的状态输出移动控制额度,将所有智能体动作整合作用于环境,得到环境反馈值和下一阶段的全部智能体状态。(3)将每一次智能体的状态、动作、奖励、下一状态作为一条记录存储于经验库。(4)从经验库中采样,输入maddpg强化学习网络模型,进行训练,优化网络参数,每隔1000步同步更新target网络。(5)根据环境反馈值判断控制情况,当感染人数和住院人数非常小时认为控制完成,传染病灭绝;当感染人数或住院人数大于设定阈值时,认为控制失败,结束此次训练。
[0118]
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思做出诸多修改和变化。因此,凡本技术领域中技术人员依据本发明的构思在现有技术的基础上通过逻辑分析、推理、或者有限的实验可以得到的技术方案,皆应在权利要求书所确定的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1