一种基于机器学习的患者服药依从性预测方法
本方法属于医学领域数据挖掘方向,涉及一种基于机器学习的患者服药依从性预测方法。
背景技术:
1、近年来,各种医疗卫生信息系统得到广泛应用,医院系统存储的数据越来越多。随着移动医疗的兴起,医疗信息越来越数字化,这些医学数据对疾病的诊断和治疗极具价值,医疗行业进入了名副其实的大数据时代。结核病简称tb(tuberculosis),是全球十大致命疾病之一。结核病在20世纪90年代“死灰复燃”,许多国家结核病发病率以每年1.1%的速度增长,成为全球需要面对和解决的公共卫生问题。我国结核病负担沉重,位居世界第二。目前,我国结核病的年发病率占全球的14.3%,这意味着每年大约有130万人诊断为结核病,患者基数仅次于印度。2011-2016年,中国年报告结核病患者数均在90万人左右,国家结核病疫情分布不均匀,患者分布西部高于中、东部,农村高于城市。结核病疫情有以下几个特点:易感染、易患病、易变异和易死亡。
2、服药依从性是指患者的服药行为是否遵守医生要求。在调查中发现,由于结核病治疗周期长、疾病治愈慢、医疗费用高昂、服药方式复杂等问题,部分患者会私自中断服药或漏服药,导致服药依从性差,最终影响治疗效果。具体表现为治疗疗程延长或病情恶化,给临床医生、医疗行业和其他利益相关者造成不必要的经济负担。据统计,服药不依从已经影响超过50%的慢性病患者。因此,人们逐渐意识到,预测和提高患者的依从性是非常有必要的。换句话说,将医护资源优先分配给最有可能不遵医嘱的患者,提高当前医疗体系干预措施的效率非常重要。对于患者依从性的研究,是一种二分类问题。医学领域患者疾病预测方法有很多种,传统的预测方法包括机器学习算法,如逻辑回归、k近邻、随机森林、支持向量机等。随着深度学习的不断发展,也出现了很多研究方法,如多层前馈神经网络(bp)、卷积神经网络(cnn)等等。
3、传统的研究方法大多通过问卷调查或自我报告的形式收集用户数据,使用量表打分机制评估患者服药依从性,并基于统计学方法,进行单因素和多因素分析建模。但是调查问卷无法保证数据的真实性,且医学数据集存在特征间高度相关和高度冗余的问题,当数据集存在非线性和不平衡问题时,很难迅速的找到合适的模型结构,模型的可解释性也较差。
技术实现思路
1、本发明的目的是提供一种能够预测肺结核患者服药依从性的方法,解决传统方法中存在的数据集存在非线性和不平衡导致的预测结果不准确的问题。
2、本发明所采用的技术方案是:
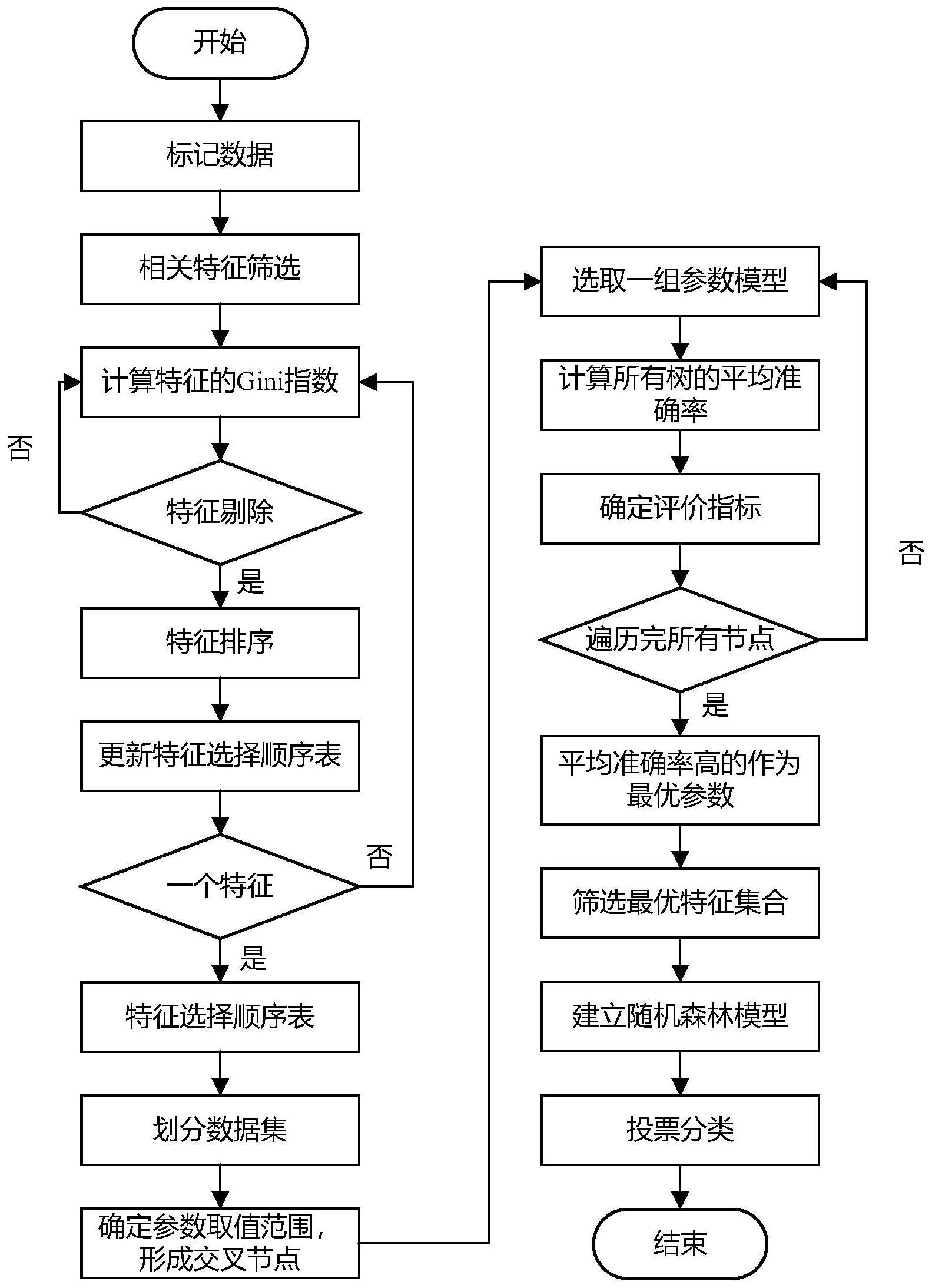
3、一种基于机器学习的患者服药依从性预测方法,包括以下步骤:
4、步骤1,收集患者数据信息,依据患者服药数据计算规则服药率,并依据规则服药率对患者的服药依从性进行定义,标签高依从性和低依从性;
5、步骤2,计算特征变量间的相关性,过滤掉相关性低的特征;
6、步骤3,以随机森林的重要性分数作为度量方式获取服药依从性特征x1,x2...xc;
7、步骤4,基于步骤3得到的服药依从性特征x1,x2...xc,利用网格搜索算法对随机森林模型超参数进行最优化,得到最优超参数;
8、步骤5,对最优超参数利用基于循环估计算法,对随机森林模型进行训练得到最终分类模型;
9、步骤6,采用步骤5训练好的最终的分类模型对数据进行分类,输出分类结果。
10、本发明的特点还在于:
11、患者数据信息含年龄、性别、户籍、不良反应得分、治疗方案治疗月份、治疗方案药品种类、服药管理方式、抽烟频率、饮酒频率、单独居室、通风情况、患者类型、健康教育得分、并发症、本次查痰15个特征属性和一个目标属性服药依从性,依据患者服药数据计算规则服药率,并依据规则服药率对患者的服药依从性进行定义,大于80%的定义为依从性高,标签设置为1,小于80%的定义为依从性低,标签设置为0。
12、步骤2具体的为:首先将样本数据的所有数据集经过one-hot编码和标准化处理,然后计算各个特征之间的相关系数,最后将结果可视化,输出相关矩阵图;pearson相关系数是一种统计学方法,机器学习中我们通常使用pearson系数表示两个变量之间的线性关系;计算公式表示为:
13、
14、其中cov(x,y)表示x和y的协方差,σx、σy表示x和y的标准差;通过计算变量和目标之间的相关系数,来确定变量间的相关性强弱;相关系数绝对值越大,说明相关性越强;通过相关系数绝对值大小对特征变量进行过滤,筛掉不相关的特征减少干扰。
15、步骤3包括:步骤3.1,使用z-score算法进行数据标准化,数据标准化公式为:
16、
17、其中x'表示标准化后的数据,x表示原始数据;
18、步骤3.2,将经过标准化处理的数据作为输入,以gini系数作为度量方式,输出特征变量的重要性排序,gini系数计算特征的重要性分数原理为:
19、假设m个特征变量表示为x1,x2...xm,每个变量的gini指数用vimj(gini)表示;则gini指数表示为:
20、
21、其中k表示样本有k个类别,pmk表示类别k在节点m中占有的比重;那么xj在m节点分支前后,gini指数变化量为:
22、
23、其中gil和gir表示m节点分裂后产生的左节点的gini指数和右节点的gini指数;那么xj的重要性分数表示为:
24、
25、假设随机森林有n个基分类器,那么重要性评分为:
26、
27、步骤3.3,将重要性评分做归一化处理,得到特征xj的重要性分数:
28、
29、设置0.05设为阈值,重要性评分大于0.05的特征视为影响患者服药依从性的因素,通过该步骤去除不相关无意义的特征,保留影响患者服药依从性的特征,剩余的特征向量表示为x1,x2...xc。
30、步骤4具体的为:首先确定需要优化的参数范围,考虑主要优化决策树个数n_estimators、分裂标准citerion、分裂节点数min_sample_split、决策树最大深度max_depth和最大特征数目max_features;接着迭代选取任意k-1份数据训练样本,迭代十次,并选择平均准确率最高的模型对应的参数为最优参数组合,输出最优参数后判定输出的最优参数是否到达参数范围边界,如果到达参数边界,则重新调整参数范围,重复以上步骤;最终输出模型的最优超参数。
31、步骤5具体的为:
32、步骤5.1,对最优超参数应用bootstrap抽样有放回的抽取样本子集,并构建多棵决策树,每次采用未被抽到的样本组成了袋外数据,这些袋外数据作为测试样本;
33、步骤5.2,对随机森林模型进行训练,得到训练好的最终分类模型;
34、步骤5.2具体的为:
35、步骤5.2.1,利用步骤4得到的随机森林中的决策树数目m创建决策树;
36、步骤5.2.2,通过有放回的随机采样方法将样本集划分为n个规模相同的训练集;
37、步骤5.2.3,所有属性集合中随机选取k个特征,使用决策树算法对选择的样本和特征集合建立训练模型;
38、步骤5.2.4,重复步骤5.2.2和步骤5.2.3两个步骤k次,生成m棵决策树;
39、步骤5.2.5,针对每个预测样本,每棵决策树都会产生预测的分类结果,最终通过投票或加权机制,输出随机森林模型的预测结果,保存预测结果最好的模型参数。
40、本发明的有益效果是:
41、1)医学数据往往存在数据不平衡、共线性、强相关性的问题,同时包含线性和非线性数据。传统的研究方法对患者依从性的预测效果不佳,而我们的模型不仅能够解决线性数据,而且在面对非线性问题时,能够获得较高的预测效果,预测模型具有良好的适用性。
42、2)医学数据挖掘技术往往需要模型有一定的可解释性。提出的发明方法能够在预测结果输出的同时,输出特征变量的重要性排序,通过阈值的设定,可以识别影响患者服药依从性的因素,使得实验结果具有可解释性。发明方法的提出,对于制订相应的治疗方案、改善患者的服药依从性、以及对结核病患者的治愈具有非常重要的意义。
43、3)本方法适用于结核病患者管理系统,通过模型对患者依从性进行提前预测,可以帮助我们筛选出低依从性人群,通过对这部分人群重点关注,以此来提高治愈率。
- 还没有人留言评论。精彩留言会获得点赞!