基于复习网络的内窥镜影像报告生成方法及存储介质与流程
本发明涉及人工智能,具体涉及一种基于复习网络的内窥镜影像报告生成方法及存储介质。
背景技术:
1、如何通过医疗科技和人工智能减轻医生的负担,改善患者就医体验,是医疗科技企业孜孜以求的目标。内窥镜可以经口腔进入胃内或经其他天然孔道进入体内,可以看到x射线不能显示的病变,对常规肠胃疾病的治疗乃至早期癌症的诊断有重要意义。通常在患者进行影像扫描后,医生会出具一份包含患者基本信息,病史,影像学表现、影像学诊断的影像报告,对于经验丰富的医生,一天书写数百份报告无疑是巨大负担,而对于占大部分人口的经济较为落后区域,难以找到优秀的医生书写详尽的报告,为患者治疗提供足够的进一步治疗指导。
技术实现思路
1、本发明提出的一种基于复习网络的内窥镜影像报告生成方法,提供一种能够自动读取内窥镜检查图像并生成语义通顺、描述较为准确符合医疗行业语言的影像报告的生成方法、装置、计算机设备和存储介质。它能够很好地适应于肠胃等不同的内窥镜检查环境,从而实现在各种环境下依然可以进行准确的影像报告自动生成。
2、为实现上述目的,本发明采用了以下技术方案:
3、一种基于复习网络的内窥镜影像报告生成方法,包括以下步骤,
4、s1、下载并处理预训练数据,获取他们的标签;
5、s2、利用前述数据集预训练骨干分类resnet网络,获得适合内窥镜图像的初始参数;
6、s3、用正式数据集和前步获得的骨干分类resnet网络,训练目标检测与特征提取网络n1;
7、s4、利用目标检测与特征提取网络n1训练加入了复习网络模块的自注意力文本生成网络;
8、s5、训练文本特征提取网络与注意力机制网络及视觉门控网络;
9、s6、将步骤s4,s5的网络联合,形成完整模型在新的内窥镜数据上进行生成报告。
10、进一步的,所述预训练的骨干分类resnet网络采用残差神经网络resnet-50,包含了49个卷积层、一个全连接层;resnet50网络结构分成七个部分,第一部分不包含残差块,对输入进行卷积、正则化、激活函数、最大池化的计算;
11、第二、三、四、五部分结构都包含了残差块,在resnet50网络结构中,残差块都有三层卷积,网络的输入为224×224×3,经过前五部分的卷积计算,输出为7×7×2048,第六部分池化层会将其转化成一个特征向量,最后一部分分类器会对这个特征向量进行计算并输出类别概率。
12、进一步的,所述正式训练集来自系统配套的存储系统,图片被重新压缩为224×224的彩色图像,其文本将经过包括去除数字,特殊符号这些处理,最后采用词嵌入技术获得各个单词的向量表示。
13、进一步的,所述目标检测与特征提取网络n1采用faster-rcnn网络,它包括:
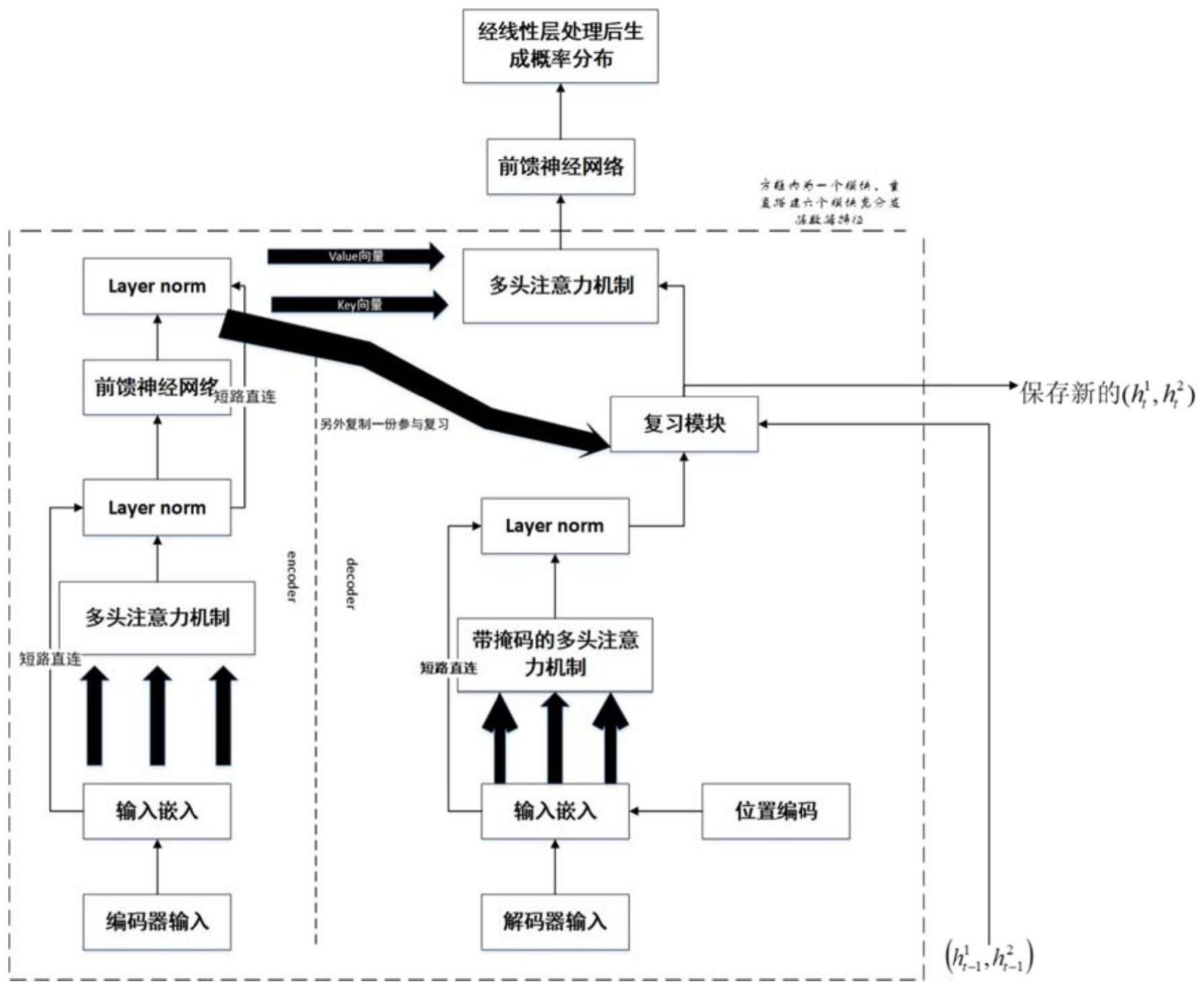
14、卷积特征提取层骨架网络,采用前述resnet 50作为卷积层骨干,它将使用一系列卷积,relu函数非线性输出以及池化生成该图像的特征图,该特征图被共享用于后续建议层和全连接层;
15、区域建议网络;该网络用于生成目标所在区域的建议;该层首先通过全连接层和逻辑回归函数判断该区域有没有目标,而后进行精细调整获得目标位置;
16、池化层;该层收集输入的特征图和区域讲义,综合这些信息后送入后续全连接层判定目标类别;
17、分类层,利用池化层传来的信息计算这个区域的类别,同时再次使用全连接层精修目标位置,获得精确的位置四元组(xi,yi,zi,ti)。
18、进一步的,所述步骤s4中复习网络模块包括一个双层长短期记忆网络为核心融合两个注意力模块与视觉门控模块,而后整合到一套以全连接层为基础的复杂网络中,为每一个句子设置一个特殊的结束标志sstop,当第二层遇到sstop时生成结束,在训练网络之前,预先将训练文本集中的单词经过词嵌入转化为词向量,训练时lstm1子模块负责在每一步接收编码器输出的图像特征与解码器输出的本次文本特征,lstm1子模块的初始化也通过全局平均图像特征完成;
19、还包括lstm2子模块负责接收来自低层子模块带有权重的,视觉、文本综合向量,来自复习模块下方的自注意力网络解码器输出经由全连接层的softmax函数处理后生成一个新的权重向量作为自注意力解码阶段的实际输出,与编码的输入结合构成自注意力三个分量进行下一步运算。
20、进一步的,所述s1、下载并处理预训练数据,获取他们的标签,具体包括:
21、接收任一内窥镜检测图像输入i,并经由一系列算法生成语义通顺满足设定要求的报告y=(y1,y2,...yt),其中t为报告长度,使用arch数据集进行预训练,从专业的医学期刊和医学教科书中提取的涵盖内容广泛的图片及其配套说明的多实例图像注释、多标签分类,专为计算机辅助病理学设计的数据集,并将所有图像尺寸调整为224*224,将对应文本抽取去除所有文本的非英文单词词汇和特殊符号,并将数据集以80%、10%、10%的比例分为训练集、验证集与测试集。
22、进一步的,所述s2、利用前述数据集预训练骨干分类resnet网络,获得适合内窥镜图像的初始参数,具体包括:
23、首先将每张图片配套的文本使用nlm medical text indexer提取其关键词,而后筛选出频率最高的1000个关键词充当分类标签,将对应的图片分到该类别下构建多类别分类预训练数据集,同时保证同一张图片不出现在不同类别里,这样预训练集构建完成,而后用resnet50在预训练集上基于前述生成的标签类别在输出端使用进行单标签分类训练,获得resnet50适用于医学图像的参数权重存于存储器中用于后续特征提取的预训练参数。
24、进一步的,所述s3、用正式数据集和前步获得的骨干分类resnet网络,训练目标检测与特征提取网络n1,具体包括:
25、进行视觉特征的提取,规格化为224×224×3的正式训练集图像i首先经过faster-rcnn网络生成一系列目标区域框,将图片在各自目标区域框内的各个像素点数字化后经平均池化到统一的固定维度d,表示为向量组v=(v1,v2,...vi),i为最终视觉特征的数量,在resnet50与目前的输入尺寸下,其为49,成为视觉特征,同时faster-rcnn还将生成各个目标的几何位置,分别为目标的左上角相对坐标值与中心坐标值(xi,yi,zi,ti);
26、采用目前的标准方案训练faster rcnn,用非极大值抑制方法,将重合度高于设定要求的候选目标区域框删除,最终的的损失函数是:
27、
28、其中
29、
30、
31、
32、这里pi表示第i个目标框预测为真实标签的概率,当训练数据是正样本时为1,负样本时为0,ti表示第i个目标框预测出来的位置参数,表示第i个目标框的真实位置参数,ncls表示一个小批量训练中所有的样本数量,nreg表示待选择目标框的数量;
33、获得这些数据后在输入自注意力网络之前先进行一次几何注意力训练,将经过几何注意力的结果作为自注意力网络输入层嵌入的一部分参与整个自注意力网络的训练,这里对于两个视觉目标(m,n),有:
34、m=(xm,ym,wm,hm),n=(xn,yn,wn,hn),位置相关系数为:矩阵ω为n×n矩阵,保存了每个目标与其他目标的几何位置;
35、it=softmax(wω+b)其中w与b都是可训练的参数最终生成的参数向量i维度与视觉目标个数相同,最后生成一系列基于几何位置注意力权重的新输入向量组(t1v1,t2v2,...tivi),而后令q,k,v=(t1v1,t2v2,...tivi),输入自注意力网络训练,其中dk是矩阵q,k的维度,而后进行多头注意力运算:
36、multihead(q,k,v)=concat(head1,head2,...headn)wo,这里首先将q,k,v通过线性变换映射至较低维空间,学习特征后再组合,即concat拼接操作,最后映射回原维度,都是可学习的参数,用于转换空间。
37、进一步的,所述s4中复习网络模块包括联合注意力模块:即全局的平均向量,xt为本次的输入词向量,为第二层atten2子模块的前次状态输出,采用标准的长短期记忆网络生成第一层的输出参与第二层运算即记忆单元ct=f⊙ct-1+g⊙i,在这里其中w1,w2,w3,b为可学习的参数;
38、在attend模块中首先生成文本指导的视觉注意力参数,有而后将它归一化得:生成权重后,注意力函数为:而后是视觉门控注意力,记忆单元保存了从头到现在的信息,利用它代表视觉门控所依赖的语言模型则有:st=gt⊙tan(ct),st即为视觉门控的语言模型部分,故有最终进入lstm2生成文本的注意力结果为:是可学习的参数,而后将被用于进行下一步运算;
39、然后采用一个外置矩阵将保存作为下一次回顾复习使用。
40、另一方面,一种计算机可读存储介质,存储有计算机程序,所述计算机程序被处理器执行时,使得所述处理器执行如上述方法的步骤。
41、由上述技术方案可知,本发明的基于复习网络的内窥镜影像报告生成方法,应用于服务器系统中,该系统连接有医学影像存储库与内窥镜检查系统,包括以下步骤:获取并处理预训练数据;预训练分类模型获得适合内窥镜图像的初始参数;用正式数据集训练目标检测与特征提取网络,训练加入了复习网络模块的自注意力文本生成网络,模型在新的内窥镜数据上进行推理生成。这里本装置直接连接内窥镜影像设备,并通过usb实时将数据发送到处理器中。
42、与千奇百怪的自然图像不同,内窥镜图像模式较为单调,他们的影像报告也在很大程度上较为相似,因此可以认为图像之间存在一些相对固定的模式,复习网络就是发掘利用这些模式,在生成本次报告时适当参考以往信息,结合文发明和图像,利用一个注意力机制实现特征融合,利用长短期记忆网络实现对以往生成过程的复习,最后将复习模块融入自注意力网络的解码器中,实现端到端学习。
43、所述模型在预训练阶段采用多标签分类方式,学习、集成了性能优良的多实例医学图像标注数据集,这是一个从权威的医学期刊和医学教科书中提取的包含一系列染色、组织类型和病理的密集诊断和形态学描述,提供多角度密集监督,专为计算机辅助病理学设计的数据集,本数据集包含15164个图片-文本对,有的文本对应了多张图片。同时对于所有处理后的文本,采用词嵌入技术获得各个单词的向量表示。视觉特征提取器基于预训练过的resnet 50为骨架构建faster rcnn目标检测网络提取视觉特征向量,文本特征提取器则每次都同时接收来自下层解码器的本次输入和整体的上次输出,这个输出可以使跨图片的,训练循环神经网络学会医学影像报告这种特殊文本的内在语言逻辑。融合器的融合思路是利用注意力机制在语言模型的基础上指导模型下一步应当关心哪些视觉特征,同时采用采用视觉门控机制让模型在适当的情况下忽略视觉特征而更关注语言模型本身。
44、总的来说,本发明在生成报告方面采用了深度学习目前最流行的框架transformer用于充分发掘输入图像特征的关系,在视觉特征提取方面则采用了经相关领域数据集预训练过,获得良好初始权重的faster-rcnn检测框架用于提取高质量的视觉概念并采用了复习模块用于兼顾当前正在查看的图片与过去查看的图片间的关系,在复习模块中使用了注意力机制动态调整过去的知识与现在输入模型的新知识的权重关系,从而更加智能的模仿专业医生的学习、检测过程,生成质量更高的内窥镜报告。
- 还没有人留言评论。精彩留言会获得点赞!