一种食管癌患者免疫治疗预后生存预测方法
本发明涉及癌症预后生存预测,特别是一种食管癌患者免疫治疗预后生存预测方法。
背景技术:
1、近年来,随着智能医疗的发展和现代医学技术的进步,机器学习技术在疾病预测中已有广泛应用。使用机器学习构建预测模型对数据的类型和分布状态要求较低,可以同时处理分类变量和连续变量,结果简单、直观,便于临床诊断与预后分析。但是,基于机器学习和人工智能的食管癌医疗研究还处在初始发展阶段,特别是在食管癌免疫治疗预后生存预测领域。因此,在食管癌智能医疗研究中,还存在着许多亟待解决的问题,面临着诸多挑战。
2、食管癌病理复杂,其免疫治疗效果不仅需要考虑患者的多项体检指标、血液指标外,还要考虑到其恶性肿瘤病史,是否有局部治疗参与等因素。在实际的随访和记录的过程中,有些数据指标可能会存在记录误差或者删失、数据杂乱和数据量小等问题。因此,如何使用机器学习的智能算法在有限的预后随访数据下挖掘数据的内在规律,智能化地预测食管癌免疫治疗的预后效果是一个亟待解决的问题。
3、另一方面,真实世界的食管癌免疫治疗预后数据通常的特征规模较大,并且有时候会出现类别不平衡的情况。然而,在构建预测模型的时候巨大的特征维数,以及不平衡的类别数据都会严重影响模型的性能和复杂度。因此,建立适用于食管癌免疫治疗预后数据的大规模多目标进化特征提取方法,解决不平衡数据下,既要满足分类效果,又要尽可能降低特征数目的问题,是一个重要的研究方向。
技术实现思路
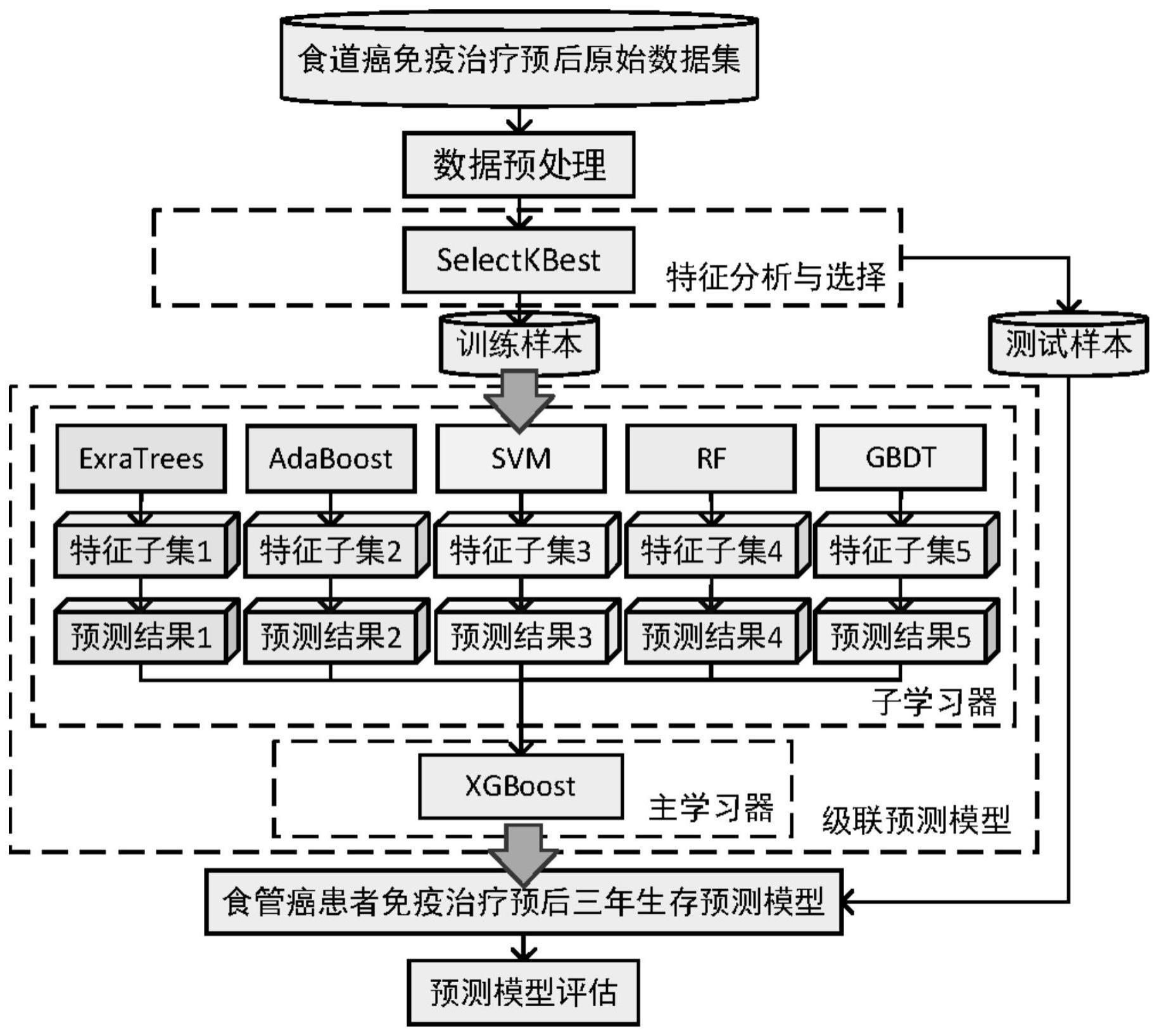
1、有鉴于此,本发明的目的在于提供一种食管癌患者免疫治疗预后生存预测方法,可以有效地预测食管癌患者免疫治疗预后的三年生存状况。
2、为实现上述目的,本发明采用如下技术方案:一种食管癌患者免疫治疗预后生存预测方法,包括以下步骤:
3、步骤1:收集食管癌患者的基本信息、疾病信息以及免疫治疗预后随访信息,作为原始数据集,并将数据传输至数据预处理模块,进行下一步处理;
4、步骤2:对原始数据进行预处理,通过初步加工、处理和过滤,清除无法直接利用的指标,同时根据各个指标的缺失率进行数据删除与补齐,并且将各个指标进行归一化处理,以消除不同指标间不同维度造成的信息不一致,接着将预处理后的数据传输至特征分析和选择模块,进行下一步处理;
5、步骤3:对预处理后的数据分析其的内在结构,找出数据的结构特征信息,并对数据的特征信息进一步的可视化分析,获得这些特征之间的相关性;根据特征相关性的结果,首先筛选出相关性较高的特征指标,然后筛选出与预后生存显著相关并且有预测价值的特征指标,最后基于所筛选出来的两组特征指标与特征相关性的结果进行特征选择,从中筛选出与生存状态最相关的若干个指标,确定为最终的指标体系,并用作训练预测模型的特征数据集;
6、步骤4:将步骤三中选择的食管癌患者各个生存指标信息作为训练样本,三年生存状态信息作为标签,输入训练模型进行训练,其中将原始数据的70%作为训练样本,其余作为测试样本;
7、步骤5:采用级联预测模型框架,将极度随机分类算法exra trees classifier、自适应提升算法ada boost、支持向量机support vector machine、随机森林算法randomforest和梯度提升决策树gradient boosting decision tree5个学习器并联,组成子学习器,并且设置模型参数,接着将训练样本数据分别输入5个学习器当中分别进行特征提取与训练;
8、步骤6:获得每个子学习器对应的预测结果,并将五个子学习器输出的预测结果与原始数据的标签输入主学习器进行进一步训练预测,xgboost模型作为主学习器;
9、步骤7:输出最终预测结果,使用测试样本数据对预测模型进行评估。
10、在一较佳的实施例中,步骤1中,收集接受免疫治疗的食管癌患者的一般情况信息、疾病情况信息、血液指标信息、免疫治疗情况信息和预后随访情况信息,作为原始数据集;原始数据集为92组数据;患者的基本信息包括患者的年龄、性别、五年内其他恶性肿瘤病史;所述疾病信息包括为ecog评分、原发灶部位、疾病分期、是否寡转移、治疗前饮食、是否支持治疗;患者的血液指标信息包括:基线白细胞计数、基线中性粒细胞计数、基线单核细胞计数、基线淋巴细胞计数、基线血小板计数、基线白蛋白、基线ldh;免疫治疗情况信息分别为免疫药物、免疫治疗周期数、免疫延迟情况、是否有局部治疗参与、局部治疗范围、局部治疗时间、治疗过程中的血液指标信息;预后随访情况信息包括是否出现疾病进展和患者的三年生存状态。
11、在一较佳的实施例中,步骤2中,首先将具有缺失值的指标进行预处理,具体如下:(1)从原始数据集中移除缺失率大于50%的指标变量;(2)对于缺失率小于50%的指标变量,使用平均值估算法对缺失数据进行补齐;其次,在构建预测模型之前对指标变量进行归一化,使用最大值最小值归一化方法,具体而言,对于第n组样本的第z个指标变量xn(z),根据以下公式进行处理:
12、
13、其中,x′n(z)表示归一化处理后的第n组样本的第z个指标变量。
14、在一较佳的实施例中,步骤3中,进行特征分析,根据已处理后的数据中的特征指标,分析各个指标之间的相关性,分别计算特征之间的相关系数,相关系数用来衡量定距变量间的线性关系;相关系数小于0.5;
15、进行特征选择,指的是从采集到的高维数据特征中选择最优的特征集合;使用selectkbest特征分析法分析食管癌患者的一般情况信息、疾病情况信息、血液指标信息与预后随访情况信息中的三年生存情况的相关性,确定指标是否与生存显著相关,得到各个指标与生存状态相关性的结果,度量各个指标的重要性程度,对其进行特征选择;通过特征选择最终保留特征重要性前10的特征指标,其中包括年龄、性别、ecog评分、疾病分期、治疗前饮食、基线单核细胞计数、基线淋巴细胞计数、基线血小板计数、基线白蛋白及基线ldh。
16、在一较佳的实施例中,构建预测模型包括如下步骤:
17、步骤s1:获得与食管癌患者生存显著相关的10个指标;将这10个指标确定为最终的指标体系,并用作训练预测模型的特征数据集;
18、步骤s2:将特征数据集中随机选取的70%作为训练集对模型进行训练,原始数据集另外的30%作为测试集对模型性能进行测试;首先选取5个机器学习算法作为子学习器,分别为极度随机分类算法exra trees c l ass i f i er、自适应提升算法ada boost、支持向量机support vector mach i ne、随机森林算法random forest和梯度提升决策树grad i ent boost i ng deci s ion tree,其中支持向量机support vector machine属于线性分类算法,其他4个属于基于决策树的分类算法,这些算法使用相同的训练数据集进行训练;接着对训练模型的参数进行设置,提取4个基于决策树的分类算法对应的模型特征重要性;将每个5个预测模型的预测结果作为新的特征子集输入至主学习器,训练一个新的预测模型,该预测模型融合5个子学习器的特征重要性;
19、步骤s3:将5个子学习器的预测结果输入至主学习器中使用级联的方式进行级联预测,级联预测的主要思想是将多个子学习器输出的预测结构作为主学习器的特征子集,与原始数据的标签数据进行二次训练;使用xgboost模型作为主学习器;xgboost模型的核心思想就是将许多基分类器集成在一起形成一个强分类器;由于xgboost模型是一种提升树模型,所以它将每个基分类器构建成树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数,去拟合上次预测的残差;当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数,最后只需要将每棵树对应的分数加起来就是该样本的预测值;具体方法为:
20、将每个子学习模型的预测结果与原始数据的标签作为xgboost模型的输入训练样本,训练最终的预测模型;假设输入n组数据,数据集合为d={(xn,yn)},其中|d|=n,xn表示第n组训练样本的特征子集,yn表示第n组数据的标签,最终预测函数如下:
21、
22、其中,fk(xn)表示第k个基分类器对特征样本xn的预测模型,fk-1(xn)为训练完已经固定的前k-1个基模型,fk(xn)表示xgboost模型对样本xn集成k个基分类器预测结果训练的最终预测值;
23、xgboost模型的目标函数由两部分构成,一部分为损失函数,用来衡量预测分数和真实分数的差距,另一部分为正则化惩罚项,这样做的目的一定程度上防止过拟合,具体目标函数为:
24、
25、
26、其中,l[.]是对单个样本的损失函数,用来度量一次预测的性能;假设它为凸函数,ω(·)为正则项;c为常数;正则化项定义模型的复杂程度,由如下公式所示:
27、
28、其中,j为基分类器fk的节点个数,ωj为节点j的节点权重;γ和λ为惩罚系数;
29、将目标函数在fk-1(xn)处进行二阶泰勒公式展开,得到如下函数:
30、
31、其中,gn和hn分别为损失函数在fk-1(xn)处的一阶和二阶导数,表示如下:
32、
33、由于前k-1个子模型已经确定,因此在式(6)中除了与fk(xn)相关的项均为常数,不影响最终的优化求解;故将常数项去掉,则目标函数转化为:
34、
35、由式(8)推出,在fk-1(xn)确定的情况下,对每个样本n都计算出一个gn和hn;
36、将正则化项式(5)代入式(6),得到如下公式:
37、
38、将所有同一个节点上的样本重组,得到如下公式:
39、
40、其中nj={xn|q(xn)=j}表示节点j上的样本集,q(xn)为将样本映射到节点上的索引函数,ωj=fk(xn)(n∈nj)为节点j上的回归值;
41、令将目标函数改写成关于节点分数ωj的一个一元二次函数,为了使目标函数最小,令其导数为0,解得每个节点的最优预测分数为:
42、
43、将式(11)带入目标函数,得到最小损失为:
44、
45、xgboost模型使用如下公式来评测节点分裂的优劣:
46、
47、其中,gl,hl,gr,hr表示分裂后不同子树的相应分数;结构评分gain
48、表示就是分裂前的损失与分裂后的损失的差值,差值越大,表明分裂后损失越小,目标函数值越低,即效果越好;
49、步骤s4:训练结束,获得最终预测模型;
50、步骤s5:使用测试数据集对预测模型进行测试评估。
51、与现有技术相比,本发明具有以下有益效果:该方法首先针对真实世界数据分析各个指标对食管癌患者免疫治疗预后生存的影响,获取多个与预后生存显著相关并且有预测价值的指标;接着基于若干个预后生存高度相关的指标使用级联预测模型构建食管癌患者免疫治疗预后生存预测模型;最后使用测试数据对食管癌患者的免疫治疗预后三年生存状态预测模型进行评估。该模型可以有效地预测食管癌患者免疫治疗预后的三年生存状况
- 还没有人留言评论。精彩留言会获得点赞!