多体模拟的制作方法
背景技术:
1、本发明涉及多体模拟,更具体地涉及用于分子动力学模拟的设备的电路实现。
技术实现思路
1、在以下美国专利中描述了用于多体模拟的设备的电路实现和操作过程的许多示例,这些专利通过引用并入本文:标题为“orthogonal method”的美国专利7,707,016、标题为“grid based computation for multiple body simulation”的美国专利7,526,415和标题为“approaches and architectures for computation of particle interactions”的美国专利8,126,956。
2、本文描述了可以与先前描述的方法结合使用的许多方面,例如,用本文呈现的方面替换子系统的实现或修改子系统。
3、在许多实现中,用于多体模拟的设备模拟包括多个粒子的物理体积。在分子动力学模拟的背景下,粒子包括原子,该原子的群可以形成分子。
4、设备包括多个互连处理节点,这些互连处理节点可以布置成三维阵列。在设备的许多使用中,在处理节点和物理体积的正被模拟的物理区域之间存在一对一的关联。实施例包括物理区域是立方体的实施例、物理区域是长方体的实施例、以及物理区域以与处理节点相同的相邻关系布置的实施例。在至少一些实现中,处理节点具有到其直接的邻居的通信路径。这些路径形成环形。
5、如在先前的专利中描述的,具体粒子的数据存储在与该粒子的物理位置相关联的处理节点中。粒子相互作用的计算通常涉及交换关于粒子的信息,使得处理节点可以计算逐对的相互作用,并且对于至少一些粒子,交换力信息,使得处理节点可以更新这些粒子的位置(和速度)。
6、可以单独使用或彼此组合使用的下面提及的许多新特征为在基于电路的系统中准确地模拟物理系统的实际问题提供了技术改进。
7、一个改进是减少了给定模拟所消耗的能量的总量。这种能量的减少使得能够实现更快和/或更小的系统。
8、另一改进是减少了模拟物理系统所需的时间,这不仅仅是由于使用更快的电路或通用处理器,而且是由于可以更好地使用可用电路的计算和节点间通信的特定布置,例如,通过引入处理元件的特定组合、布置通信和计算方面以减少延迟从而减少各模拟周期所需的时间,以及更有效地使用处理器之间的通信链路。
9、本文描述的所有实现和方法都是非抽象的,并且提供技术效果。如本文所用,申请人作为其自己的词典编纂者,在此将“非抽象”定义为“抽象”的反义词,因为该术语已由联邦巡回法院和最高法院在本技术提交日定义。因此,将权利要求解释为抽象的任何人将是以直接违背说明书的方式解释权利要求。
10、在一个方面,发明的特征在于一种用于使一对原子中的两个原子相互作用的混合方法。根据该方法,一个或多于一个计算节点的集合用于使一对原子相互作用。通过平衡必须在集合内的通信节点之间通信关于原子的数据的成本和与计算相互作用相关联的计算复杂性来选择集合。
11、如本文所使用的,动词“相互作用”应指执行估计由两个原子之间的相互作用而产生的这两个原子的状态变化(如位置、动量、电荷等)所需的计算。在本发明中,术语“原子”和“粒子”应互换使用。
12、如本文所使用的,术语“原子”不一定意指具有电子随从的原子核。在分子动力学的背景下,“原子”以其原始意义使用,被视为模拟期间的不可分割单位。因此,“原子”可以是原子核、原子核和一个或多于一个电子、键合在一起的多个原子核(例如分子)、或作为大得多的分子的一部分的官能团。
13、在分子动力学模拟器中,两个原子的相互作用需要关于这两个原子的信息。该信息必须在将执行相互作用的任何计算节点处可用。特定的计算节点具有关于一些但不是所有原子的信息。如果节点已经具有与一对原子的全部两个原子相关联的信息,则没有与发送这种信息相关联的通信成本。另一方面,如果节点不具有关于其中一个原子的信息,则结果导致了通信成本。在某些情况下,节点不具有关于任何一个原子的信息。这导致更大的通信成本。
14、本文描述的实现在具有较高通信成本以及较低计算复杂性的第一方法和具有较低通信成本以及较高计算复杂性的第二方法之间进行选择。在目前的情况下,第一方法是曼哈顿(manhattan)法,第二方法是全壳(full shell)法。对于各相互作用,模拟器权衡第一方法增加的通信成本和第二方法较高的计算成本,并且选择为各相互作用提供更好性能的计算节点集合。
15、当与现有的中立区域(neutral territory)法(例如在美国专利us7,707,016中描述的方法)相比时,曼哈顿法通常由于在节点之间具有更小的导入量和在节点之间具有更好的计算平衡而改进了性能。曼哈顿法计算与节点中的包含在物理空间中离节点间边界最远的粒子的节点有关的相互作用。然后,将共享结果返回给另一节点。
16、全壳法在计算上比上述任何一方法都要复杂得多。然而,也需要少得多的通信。由于相互作用是在两个原子的主节点处计算的且因此相互作用不返回到配对的节点,因此产生了通信方面的这种节省。
17、在另一方面,设备包括在处理节点处用于评估粒子之间逐对的相互作用的电路。
18、计算一对粒子之间的相互作用可能取决于粒子的分离而有不同的要求。例如,彼此距离较远的粒子可能需要较少的计算,这是因为相互作用不如在这些粒子彼此距离较近的情况下复杂。相互作用的特性的幅值可能较小。所计算的相互作用的特性可能较小。
19、为了适应这一点,具有用于计算逐对的相互作用的多种类型的处理元件是有用的,其中根据粒子的分离来选择处理元件的类型。
20、作为示例,在分子动力学的模拟中,非键合粒子在彼此靠近时比更远离时具有更复杂的行为。近和远是由围绕点粒子的球体的截止半径定义的。由于分布在液体中的粒子的接近均匀的密度和截止范围,因此远区域中的粒子通常是近区域中的粒子的三倍。设备通过将彼此靠近的粒子对引导向能够执行更复杂处理的大相互作用模块来利用这一点。相反,彼此远离的粒子对被引导向小相互作用模块,该小相互作用模块执行较低精度的计算,并忽略仅当粒子彼此足够靠近时才重要的某些现象。
21、使用“大”和“小”是恰当的,因为大相互作用模块物理上尺寸更大。大相互作用模块比小相互作用模块消耗更多的芯片面积,并且每次相互作用还消耗更多的能量。处理节点可以具有比“大”处理元件数量更多的“小”处理元件,以适应模拟体积中粒子的空间分布。
22、各集成电路的总面积的一部分容纳形成计算流水线的相互作用电路。该相互作用电路执行前述相互作用。
23、与通用计算机不同,计算流水线是最小可配置的硬件模块,仅具有有限的功能。然而,无论计算流水线做什么,都做得很好。相互作用电路执行相互作用所消耗的能量远低于通用计算机针对相同的相互作用所消耗的能量。可以被看作逐对粒子相互作用模块的这种相互作用电路是集成电路的真正主力。
24、基板的其它部分上形成有逻辑电路。这种逻辑电路通常包括相互连接以将电力电压转换成输出电压的晶体管。这种转换的结果是相对于相互作用电路发送或接收由电压表示的信息,提供信息的临时存储,或者以其他方式调节信息。
25、在另一方面,通常,给定粒子的两个集合的数据,处理节点根据粒子之间的距离确定(1)是否评估粒子之间的相互作用,和/或(2)应该使用哪个处理元件来计算粒子之间的相互作用。
26、一些示例在确定是否评估相互作用时使用关于粒子之间距离的严格阈值。这有助于避免,例如,无意地“重复计算”相互作用(例如,粒子上的力)。
27、在其他示例中,粒子之间的距离确定了节点的不同类型的处理元件中的哪个类型被用于相互作用。这是特别有利的,因为不同的处理元件执行不同准确性水平的计算。这使得可以选择哪个准确性水平最适合于特定的相互作用。
28、在这方面,基于距离的决定(即,上面的(1)和(2))是分两个级进行的,增加了精度和/或增加了计算成本。
29、例如,在第一级,如果保证粒子对超过了阈值分离,则排除这些粒子对。作为另一示例,在第二级,未由第一级排除的粒子对根据它们的分离而被进行处理,例如,以进一步排除超过了阈值分离的粒子对和/或根据分离选择处理元件。例如,第二级对粒子对进行三向确定:一个粒子是否在第二粒子的近区域内(例如,在这种情况下,使用“大”处理元件评估该对),一个粒子是否在第二粒子的远区域内(例如,在这种情况下,使用“小”处理元件评估该对),或者一个粒子是否在第二粒子的远区域的截止半径之外(例如,在这种情况下,不进一步评估该对的相互作用)。
30、原子之间的相互作用包括考虑重要性随原子之间的距离而变化的现象。认识到这一点,定义距原子的阈值距离是有用的。如果一对原子中的第一和第二原子之间的原子间距离超过该阈值,将使用第一相互作用模块;否则,将使用第二相互作用模块。这两个相互作用模块在复杂性方面不同,其中第一相互作用模块忽略了至少一个在第二相互作用模块中考虑的现象。例如,当距离小时,量子力学影响足够重要以考虑在内。当距离大时,这种影响可以被忽略。
31、第一相互作用模块在物理上比第二相互作用模块大,因此占用更多的裸片(die)面积。此外,第一相互作用模块比第二相互作用模块每次相互作用消耗更多的能量。
32、通常,存在以第一原子为中心的球体。位于球体之外的原子根本不相互作用。位于球体内但超过阈值半径的原子使用第二相互作用模块进行相互作用。所有其他原子在第一相互作用模块中相互作用。
33、为了将相互作用引导到正确的相互作用模块,具有匹配电路是有用的,该匹配电路确定原子间距离,并且基于原子间距离是低于还是高于阈值半径,相应地丢弃所提出的相互作用或者将相互作用引导到第一相互作用模块或第二相互作用模块。
34、对于均匀的原子密度,预期更多的原子将位于球体的阈值半径之外的部分。因此,具有两个或多于两个第二相互作用模块是有用的。这进一步促进了第二类型的相互作用的并行性。
35、在一些实施例中,原子首先被保存在存储器中,然后被流式传输到相互作用电路中,特别地,流式传输到将原子引导到适当相互作用模块的匹配电路。匹配电路实现两级滤波器,其中低精度级为粗略的包含性滤波器。在各时钟周期中,低精度级计算各个被流式传输的原子和可能与被流式传输的原子相互作用的多个被存储原子之间的原子间距离。
36、各原子具有“类型”是有用的。了解原子的“类型”对于选择当该原子是相互作用的参与者时要使用的合适的相互作用方法是有用的。例如,当两个原子的类型已知时,可以查阅查找表来获得关于这两个原子之间的逐对相互作用的性质的信息。
37、为了避免与大表相关联的笨拙,相互作用模块具有两级表是有用的,其中第一级具有相互作用索引,并且第二级具有与各相互作用索引相关联的相关相互作用类型。相互作用索引表示的数据量比关于原子的类型的信息要少。因此,必须物理地存在于裸片上的表的第一级消耗小面积的裸片。因此,维持该信息也消耗较少的能量。
38、如上所述,形成计算流水线的相互作用电路仅具有有限的功能性。对于一些相互作用,需要执行相互作用电路不能执行的操作。对于这种情况,与参与原子之一相关联的相互作用类型指示需要特殊操作。为了执行该操作,相互作用电路实现了到相邻的通用核心(本文称为“几何核心”)的活板门(trap-door)。几何核心通常比相互作用电路能效低。然而,其可以执行更复杂的处理。因此,该实现保持了与相互作用电路相关联的能效,同时具有偶尔将计算的一部分分包给效率较低的几何核心的能力。
39、如上所述,处理节点之间的通信涉及交换关于粒子状态的信息。这种信息包括粒子的位置、速度和/或力中的一个或多于一个。在模拟的连续迭代中,特定的一对处理节点可以发送关于同一粒子的信息。
40、另一方面,通常,通过参考先前通信的信息来实现通信需求的减少。例如,接收节点可以高速缓存信息(例如,大量粒子),并且发送节点可以在随后的迭代中发送对高速缓存的数据的引用(例如,标签),而不是重新发送完整的数据。
41、另一方面,通常,发送节点和接收节点共享来自先前迭代的信息,该信息用于预测当前信息中要发送的信息。然后,发送节点相对于所共享的预测而对要在当前迭代中发送的信息进行编码,从而减少要发送的数据量。例如,在发送节点和接收节点共享粒子的先前位置和速度的程度上,例如通过以该先前速度移动粒子并假设速度保持恒定,各节点可以预测当前位置和速度。因此,发送节点只需发送当前位置和所预测的位置之间的差和/或当前速度和所预测的速度之间的差。类似地,可以以类似的方式预测力,并且可以发送所预测的力和所计算的力之间的差。
42、另一方面,连接系统中处理节点的通信基础设施(例如,节点间通信电路)包括用于节点之间的通信的同步的电路。在前述基础设施的实施例中,包括如下的实施例:节点发出“围栏(fence)”消息,该消息指示消息集合中的所有消息都已被发送和/或指示在围栏消息之后从该节点发送的消息必须在围栏消息之后被传送到目的地。
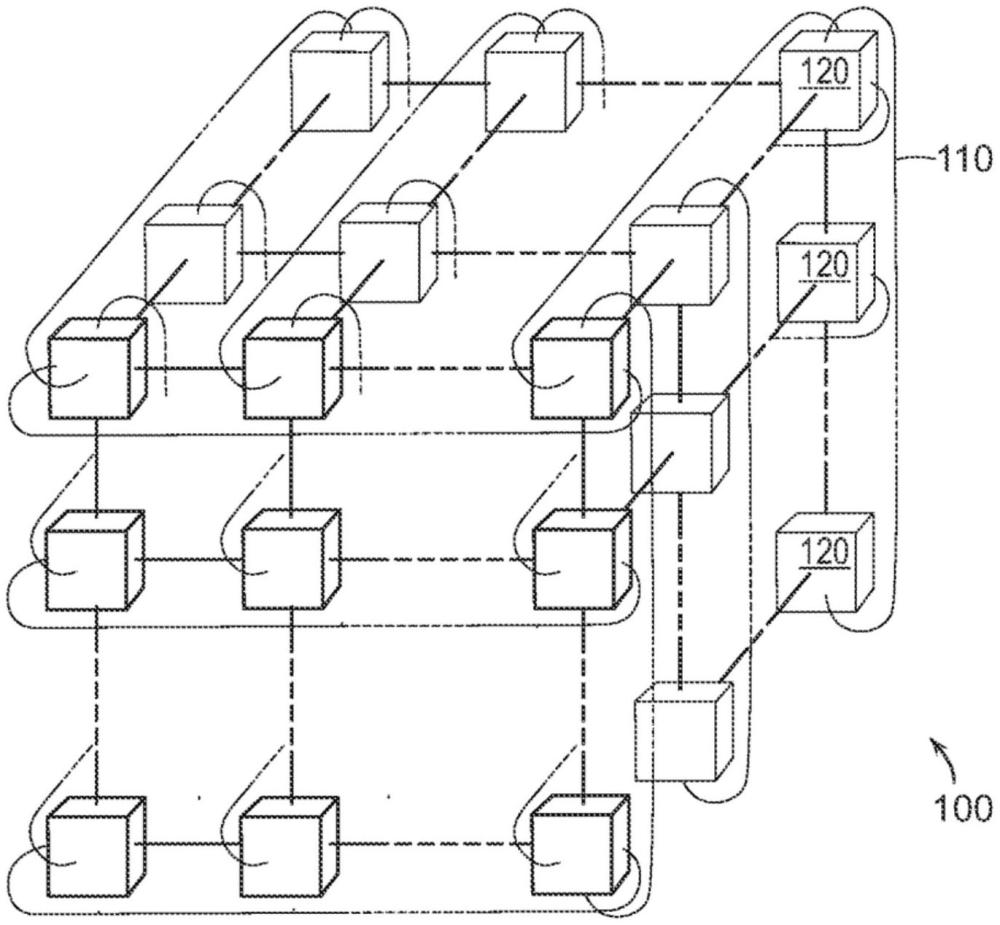
43、在前述基础设施的实施例中,还包括如下的实施例:通信基础设施确定何时向目的地节点发送消息,该消息指示来自源节点集合的所有消息已经被传送。在这些实施例中,通信基础设施处理来自源节点集合的围栏消息,并且当已经接收到来自源节点的所有围栏消息时,将围栏消息传送到目的地节点。这种基于基础设施的围栏消息处理可以避免必须在处理节点对之间发送“n2”次消息的需要。
44、另一方面,用于通过网络连接的大型多处理器计算机的处理器同步机制利用围栏。围栏是向目的地处理器保证不再有更多的数据从所有可能的源到达的屏障。在一些实施例中,围栏是全局屏障,即使计算机中的所有处理器同步。在其他实施例中,围栏是使计算机区域同步的选择性屏障。
45、在这些实施例中,包括如下的实施例:各个源向各个目的地发送指示发送了最后数据的包,并且各个目的地等待直到已经接收了来自各个源的包。在具有n个处理器的计算机中,全局屏障需要o(n2)个包以从所有源处理器穿越网络到目的地处理器。备选的围栏机制只要求端点处理器发送和接收o(n)个包。其他的实施例包括使用多播和计数器以减少围栏网络流量和端点处的处理的网络,从而减少功耗并减少硅芯片上使用的物理面积,由此减少制造成本。
46、另一方面,本发明包括用于计算原子对之间的相互作用的相互作用模块,其中本文称为“区块”的计算单元在集成电路或“芯片”内形成行和列的二维阵列。给定区块相对于同一列中的相邻区块或者同一行中的相邻区块发送和接收关于粒子的信息。为了便于说明,关于粒子的信息应简称为“粒子”。
47、区块存储粒子集合(在下文中称为“存储集粒子”)。在模拟过程期间,该区块接收粒子流(在下文中称为“流集粒子”)。在模拟过程中,区块使各流集粒子与各存储集粒子相互作用。在模拟中的各时间步长处,已经利用区块进行了相互作用的流集粒子沿着该区块的行移动到后续区块,以与该后续区块处的存储集粒子相互作用。另一方面,区块从该区块的行中的前一区块接收新的流集粒子。
48、为了执行这种逐行流式传输,存在专用的流式传输网络。这种专用的流式传输网络的特征在于位置总线和力总线。位置总线从芯片边缘处的存储器中获得关于粒子位置的信息,并且将该信息通过相互作用电路从一个区块流式传输到下一区块。对于各粒子,力总线累积作用在该粒子上的力,因为这些力是由该粒子通过的相互作用模块计算的。
49、如上所述,区块也能够与其列中的其他区块通信。这种通信不涉及流集粒子。这种通信涉及存储集粒子。特别地,区块处的存储集粒子被多播到该区块的列中的区块。因此,存储集粒子在同一列中的所有区块上复制。这使得存储集粒子与不同的流集粒子同时相互作用成为可能。
50、出现的困难是,由于与一个行中的流集粒子的相互作用而作用在存储集粒子上的力不一定可用于另一行中的相应存储集粒子。为了应对该困难,通过简单地遵循最初用于多播存储集粒子的多播模式的倒转,在卸载时在网络中减少针对行中的流集粒子计算的力。
51、此外,在同一列中的所有区块都准备好开始卸载之前,不允许任何区块开始卸载存储集粒子。为了实现这一点,以跨列内所有区块的四线同步总线的形式提供列同步器是有用的。这种同步总线避免了网络死锁,并且提供了低延迟同步。
52、在另一方面,本发明包括作为协处理器的键计算器,以帮助通用处理器执行涉及原子之间特定类型的键、特别是共价键的某些专门计算。通用处理器通过向键计算器提供关于原子和键的性质的信息并从键计算器的输出存储器中检索这种处理的结果来启动这种计算。
53、键计算器的实施例支持键对力的一个或多于一个响应。这种响应包括键长的变化,诸如键的延伸或收缩,键角度的变化(当三个原子键合时可能出现),以及键的二面角或扭转角的变化(诸如当四个键合原子存在时可能出现)。
54、对力的这些响应在分子模拟中尤其常见。因此,将与确定这些响应相关联的处理卸载到紧凑且专用的电路是特别有用的。这样做减少了计算原子的这种状态变化所需的能量。
55、在一些实施例中,粒子之间的相互作用采取指数差的形式,例如,exp(-ax)-exp(-bx)的形式,或者作为表示电子云分布卷积的积分的评估。虽然可以分别计算两个指数,然后取差,但这种差可能在数字上不准确(例如,非常大数字的差)。优选的方法是形成该差的一个级数表示。例如,该级数可以是泰勒级数或基于高斯-雅可比求积的级数。此外,维持整体模拟的精度所需的项的数量通常取决于ax和bx的值。因此,在(例如在粒子-粒子-相互作用电路(ppim)中)计算逐对的项时,不同的特定粒子对、或者基于ax和bx的值的差的不同标准(例如,绝对差、比率等)可以确定要保留多少个级数项。通过减少项的数量(例如,针对许多对粒子的单个项),例如,当两个值接近时,所有逐对相互作用的总体计算可以显著减少,同时维持总体准确性,从而在准确性和性能(计算速度和/或硬件要求)之间提供可控的折衷。
56、在一些实现中,例如,在不同的处理器中冗余地计算相同的值(例如,粒子上的力),以避免通信成本。例如,这种冗余计算可以发生在“全壳”法中。还存在系统地截断或舍入结果可能对整体模拟有害的情形,例如,由于在一系列迭代中引入偏差。例如,重复向下舍入可能使积分随着时间的推移而显著过小。
57、避免随着连续时间步长由舍入导致的累积偏差的一个方法是在舍入或截断针对粒子集合计算的值之前添加小的零均值随机数。这方法可以被称为抖动。然而,当在不同的处理器中进行冗余计算时,例如因为随机数生成的顺序不同,没有理由在不同的处理器中生成的伪随机数将是相同的。对于不同的随机数,舍入或截断的值可能不同,以至于模拟可能不会在处理器之间保持完全同步。
58、优选的方法是使用数据相关随机数生成,其中在计算针对粒子集合的值的所有节点处使用完全相同的数据。生成随机值的一个方式是使用计算中涉及的粒子之间的坐标差作为随机种子,以供生成要在舍入或截断之前添加的随机值。在一些实施例中,三个几何坐标方向各自中的绝对差的低阶位被保留并组合作为散列函数的输入,散列函数的输出被用作随机值或被用作生成一个或多于一个随机数的伪随机数发生器的随机种子。当存在涉及粒子集合的多个计算时,相同的散列用于生成不同的随机数,以添加到计算的结果中。例如,一个随机数(如果分成几部分),或者随机数生成器被用于从同一种子生成一系列随机数。由于坐标距离的值在所有处理器处完全相同,因此散列值将是相同的,并且因此随机数将是相同的。粒子之间的距离可能优于绝对位置,这是因为距离对于平移和环形包裹是不变的,而绝对位置可能不是。计算坐标方向的差不会产生舍入误差,因此可能比欧几里德(标量)距离更优选。
59、实施例、示例和/或实现利用上述方法的各种组合,并且在不需要将各个方法与其他方法组合使用的情况下可以实现各个方法的优点,包括减少以发送的信息位数测量的通信需求,减少以绝对时间或相对于进行某些计算所需的时间测量的通信的延迟,减少在模拟时间内和对于多个模拟时间步长进行给定模拟的绝对(即“挂钟”(wall-clock))时间,减少进行模拟所需的计算操作的数量,将计算分配到特定的计算模块以减少所需的计算时间和/或功率和/或电路面积,以及/或者使用较少的通信资源的分布式模块之间的同步,以及/或者使用网络通信原语提供更同步的操作。从下面的描述中可以明显看出其他优点。
- 还没有人留言评论。精彩留言会获得点赞!