基于异质子图对比学习的抑郁症检测方法
本发明涉及自然语言处理和图神经网络领域,特别涉及一种基于异质子图对比学习的抑郁症检测方法。
背景技术:
1、随着现代社会生活、工作压力逐渐增大,各个年龄段人群的心理问题频发。受抑郁症、压力等心理健康问题困扰的人愈来愈年轻化,尤其是青少年抑郁问题愈发严重。传统的心理健康诊断和治疗方法,需要和医生进行面对面的交流,这种接触式的方式限制了潜在病人识别的可能性。并且鉴于经济水平、资源缺乏、社会歧视、隐私保护等问题,患者即使意识到自己可能患上了心理健康疾病,也不会去医院或诊所进行鉴定。因此,以往的治疗方案往往难以在大样本情况下对人们的心理或精神状态进行检测和追踪。
2、社交网络的繁盛使得海量的社交媒体数据捕获了人们自己真实的想法、情感、交流等信息,这些数据在公共健康监控中变得非常重要。相对于传统的生理指标、心理测试等诊断方法,社交网络分析起步较晚,因此利用社交媒体数据进行心理健康诊断的方法不够成熟,还没有作为临床确诊标准。但是有效的模型可以更早地发现潜在的心理状态,辅助心理健康专家对抑郁症及其他心理健康疾病的确诊进行更彻底的评估,并为治疗提供支持。因此,社交媒体数据可以作为心理学领域的辅助资源和研究对象,从而促进公共健康的评估、快速干预和建设。
3、以往的研究最常用的抑郁症检测模型是经典的分类器,比如贝叶斯、决策树、神经网络、svm等,这些方法与wordnet、liwc等资源结合,通过研究文本序列,计算推文之间的语义相似度等方法,来评估twitter中用户的抑郁情绪。这些工作都是有监督学习,表明了经典机器学习方法的可行性,但是都没有考虑社交网络数据的动态性。针对社交网络和抑郁症用户发布内容的特点,部分研究工作考虑了时间信息的影响或者推文发布的时间段,并选择描述性统计值作为时间特征,结合情绪的非时间特征识别抑郁用户,提高了识别的准确度。这些研究表明,情绪状态不但受其他用户的影响,而且会随着时间变化。绝大多数工作只是研究了用户内容数据或者用户关系随时间推移所体现的抑郁状态差异,而忽略了抑郁情绪的波动性和复发性。另外用户在社交平台上的信息通常由多个维度组成,具有异质性,如何利用这些异质信息并发掘它们之间的关系,同样是一项重大的挑战。
4、综上,基于异质子图对比学习的抑郁症检测方法的研究不仅有助于提高对心理健康的确诊和治疗、公共健康的干预和建设等应用领域的智能处理能力,而且对社交网络分析、图神经网络等相关任务的研究提供重要的理论方法。针对社交网络数据新的特性,抓住抑郁症这一重点心理健康问题,将社交媒体数据构建为异质图结构,并考虑到了社交用户间潜在的关联,效地判断用户是否存在抑郁倾向,进行心理健康的诊断研究,研究基于异质子图对比学习的抑郁症检测具有重要的理论意义和应用价值。
技术实现思路
1、本发明的目的在于克服现有技术中的缺点与不足,提供一种基于异质子图对比学习的抑郁症检测方法,能够有效检测社交网络中用户的抑郁倾向。
2、为实现以上目的,本发明采取如下技术方案:
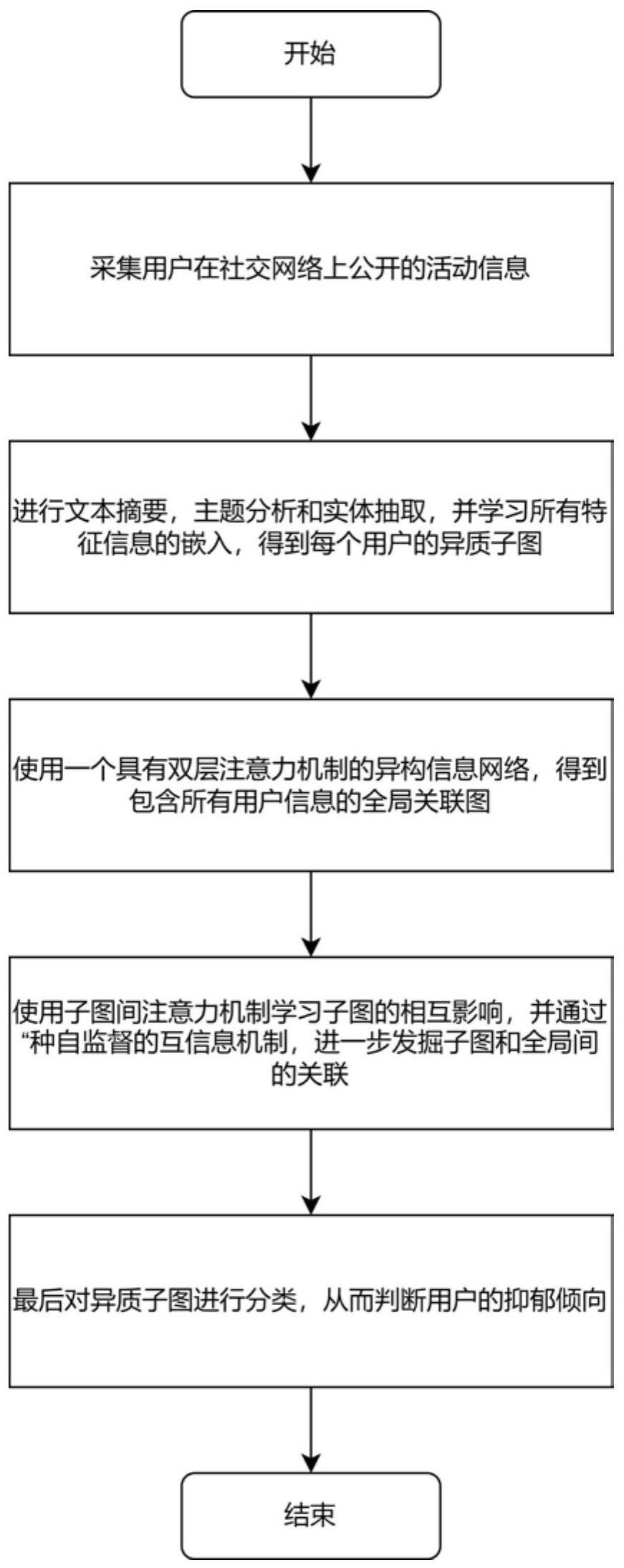
3、一种基于异质子图对比学习的抑郁症检测方法,其特征在于,包括以下步骤:
4、s1、通过api采集用户在社交网络上公开的活动信息,提取发表的推文及其附加信息;
5、s2、对s1中的文本进行摘要,并进行主题分析和实体抽取,学习所有特征信息的嵌入,得到每个用户的异质子图;
6、s3、构建一个具有双层注意力的异构信息网络,它可以学习任何类型的异质信息并注意到它们之间的关系,使用该网络得到包含所有用户信息的全局关联图;
7、s4、考虑到用户间潜在的关联,使用子图间注意力机制学习子图的相互影响,并通过一种自监督的互信息机制,进一步发掘子图和全局间的关联;
8、s5、最后对异质子图进行分类,从而判断用户的抑郁倾向。
9、作为优选的技术方案,步骤s1中,所述的推文及其附加信息,是指由于至少需要两周来确定抑郁症,因此采集了锚定推文前一个月内的所有推文数据,包括推文中的文本信息、发布时间、表情符号、人称词的数量和情绪倾向词汇的数量,以及用户的关注和粉丝列表,发推和转推数量等诸多具有丰富含义的信息。
10、作为优选的技术方案,步骤s2的具体过程为:
11、s21、用户发表的推文中存在大量冗余和对分析抑郁倾向无用的信息,需要进行必要的数据清洗,包括正则表达式过滤、停用词表过滤、异状词检查等;
12、s22、接下来使用bert学习推文的词嵌入,并通过k-means选择最重要的推文,随后使用一种结合bert解码器和gpt编码器的模型bart,来提取文本的摘要,在保留重要语义的同时,将用户大量的社交文本浓缩为简短的结论性描述;
13、s23、为了发掘文本中更深层次的信息,使用一种结合bert和聚类的主题提取模型bertopic,对社交文本进行主题分析,得到主题的嵌入;
14、s24、同样对社交文本进行实体抽取,使用实体链接工具tagme将实体映射到维基百科,得到对应的描述文本,并使用bert学习其嵌入;
15、s25、对s1中的附加信息进行标准化,得到其分布作为嵌入;
16、s26、最后以s22中的文本嵌入作为中心节点,其他信息的嵌入作为附加节点,构建用户的异质子图网络g,同时子图间也会通过相同的主题和实体连接,得到初步的关联图g。
17、作为优选的技术方案,步骤s3的具体过程为:
18、s31、令s2中的关联图为g=(v,e),其中v=d∪t∪e∪o表示节点的集合,记文本d={d1,...,dm},主题t={t1,...,tk},实体e={e1,...,en},其他附加信息o=[o1,...,om},e表示边的集合;
19、s32、对于图g,令x∈r|v|×q为所有节点的特征矩阵(其中每一行xv∈rq表示节点v的特征向量),邻接矩阵a′=a+i,度矩阵m(其中mii=∑ja′ij),归一化邻接矩阵可以得到网络每层的传播公式如下:
20、
21、其中τ={τ1,...,τk}表示不同的节点类型,表示中类型为τ的子矩阵(其中行表示所有节点,列表示相邻节点),wτ(l)表示l层的可训练转化矩阵,表示l层的节点表示,初始σ(·)表示激活函数;
22、s33、类型级注意力可以学习不同类型的相邻结点的权重,首先将τ类型的嵌入表示为其相邻节点特征hv′的总和随后计算类型的注意力得分,并使用softmax函数归一化,具体公式如下:
23、
24、
25、其中μτ表示类型为τ的注意力向量,||表示连接,σ(·)表示激活函数;
26、s34、节点级注意力可以学习不同相邻结点的重要性,并减少有噪声节点的权重,首先给定一个类型为τ的特定节点v,其相邻节点的类型为τ′,根据节点的嵌入hv和hv′与类型注意力得分ατ′,可以计算节点的注意力得分,并使用softmax函数归一化,具体公式如下:
27、bvv′=σ(vt·ατ′[hv||hv′]) (4)
28、
29、其中v是注意力向量;
30、s35、最后更新公式(1)得到每一层的传播规律,具体公式如下:
31、
32、其中bτ是注意力矩阵(第v行第v′列中的元素是βvv′);
33、s36、在经过l层传播后,可以得到更丰富的节点嵌入和节点关联,并构成全局关联图g,定义传播的损失如下:
34、
35、其中c是类数,dtrain是用于训练的子图集合,y是对应的标签,θ是模型参数,η是正则化因子,使用梯度下降法进行传播优化。
36、作为优选的技术方案,步骤s4的具体过程为:
37、s41、将更新后的子图作为超节点gi,通过多头注意力计算系数αi,则子图的嵌入可以表示为:
38、
39、其中αi是注意力系数,是权重矩阵,m是注意力的头数;
40、s42、接下来利用互信息(mi)来衡量子图和全局间的关联,首先使用jensen-shannon(js)mi estimator来最大化子图的全局嵌入互信息,具体公式如下:
41、
42、其中wmi是互信息的评分矩阵,g是s3中的全局关联图,σ(·)是sigmoid函数;
43、s43、这种互信息最大化机制是以一种对比学习的方式进行的,除了将子图的全局嵌入对作为正样本,还需要构建一些负样本,这里是随机将子图的全局特征矩阵打乱,得到一个扰动的全局嵌入作为负样本。
44、s44、自监督互信息的目标可以定义为标准的二元交叉熵损失,具体公式如下:
45、
46、其中npos表示正样本的数量,nneg表示负样本的数量。
47、作为优选的技术方案,步骤s5的具体过程为:
48、s51、模型整体的损失函数是节点更新损失函数与互信息最大化损失函数的结合,具体公式如下:
49、
50、其中β控制mi部分的权重,λ是θ上l2正则化的系数;
51、s52、训练,最后通过softmax得到概率预测,对异质子图分类,从而判断用户的抑郁倾向。
52、本发明相对于现有技术具有如下的优点和效果:
53、1、本发明的方法挖掘了在社交网络中多种可能表现用户抑郁状态的信息,这些信息除了用户在社交媒体上发布的文本之外,还包括多个与用户相关的重要附加信息,包括用户发送信息的时间分布统计、用户使用积极和消极表情比例的统计、用户使用积极和消极词汇比例的统计、用户使用第一人称单数和复数比例的统计、用户的关注和粉丝列表的统计、发推和转推数量的统计,这些丰富的信息可以更好地体现用户的心理状态,有助于提高模型的性能。
54、2、本发明的方法在数据处理阶段能更好地解决信息碎片化和无用信息干扰的问题,用户在社交平台上发布的内容数据量庞大且主题分散,部分信息对于判断抑郁状态没有作用或起负面效果,故对文本进行了摘要处理,从用户大量的社交文本中筛选出重要的句子,并且发掘了社交文本中更深层次的信息,即主题和实体,与不进行文本处理相比,模型在处理后的效果有了明显提高,并且处理时间更短,有效降低了信息干扰,并且丰富了语义。
55、3、本发明的方法构建了一个灵活的异质信息网络来处理社交信息,它可以集成任何类型的附加信息,并使用节点级注意力和类型级注意力机制,捕获不同相邻节点的重要性,以及不同节点类型对特定节点的重要性,以此更好地实现了信息聚合,同时减少噪声信息的影响。
56、4、本发明的方法考虑到了社交用户间潜在的关联,使用对比学习的思想,通过子图间注意力和互信息机制,得到了更有效的用户信息表示,同时提升了模型的抗鲁棒性,而在此之前,抑郁心理检测领域的文本分类研究都没有考虑到社交用户间的关联性。
57、5、本发明的方法首次将异质图结合子图对比学习应用在抑郁症的检测研究中,twitter、微博等社交网络数据属于典型的异质图结构,包括推文、用户附加信息等不同的节点类型,用户-用户、用户-推文,推文-推文等不同的边类型,因此在抑郁症检测研究中,异质图更适合建模社交网络数据,同时由于社交媒体具有大量的在线人数和活跃度,用户所发表的信息被广泛传播,因此考虑社交用户间的关联性,研究用户对于用户的影响,对抑郁检测十分重要。
- 还没有人留言评论。精彩留言会获得点赞!