面向不平衡数据的lncRNA亚细胞定位预测方法和系统
本发明属于亚细胞定位预测领域,尤其涉及面向不平衡数据的lncrna亚细胞定位预测方法和系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、确定亚细胞定位对于理解lncrna(long noncoding rna,长链非编码rna)的相互作用模式、转录后或共转录调控修饰以及lncrnas在细胞稳态中的不同作用至关重要。lncrnas通过染色质相互作用调节细胞核中的转录过程,并为核室的空间组织提供支架。最近的研究发现,细胞质中的lncrna比以前认为的要多,它们在细胞质环境中发挥着协调和构建作用,因此,位于细胞质或细胞核的lncrnas在细胞过程中发挥着重要作用,确定lncrnas的亚细胞定位对了解其功能至关重要。越来越多的研究关注于使用计算方法来确定lncrna的亚细胞定位。
3、然而,现有技术采用的是使用glove方法作为核苷酸序列编码方式进行编码,然后将编码进一步输入由cnn、lstm和mlp组成的分类器中进行分类后预测,这种方法存在的缺陷是未针对不平衡数据做优化,且其仅采用了单一的特征编码,导致在数据不平衡的细胞系上表现不佳,鲁棒性差。
技术实现思路
1、为了解决上述背景技术中存在的至少一项技术问题,本发明提供面向不平衡数据的lncrna亚细胞定位预测方法和系统,其为了充分利用lncrna的序列信息,提取了两类特征,包括物理化学模式特征和核酸的分布式表示特征,整合了两个基础分类器,包括卷积神经网络(cnn)和门控递归单元(gru),解决了解决模型在不平衡数据集上表现不佳的问题。
2、为了实现上述目的,本发明采用如下技术方案:
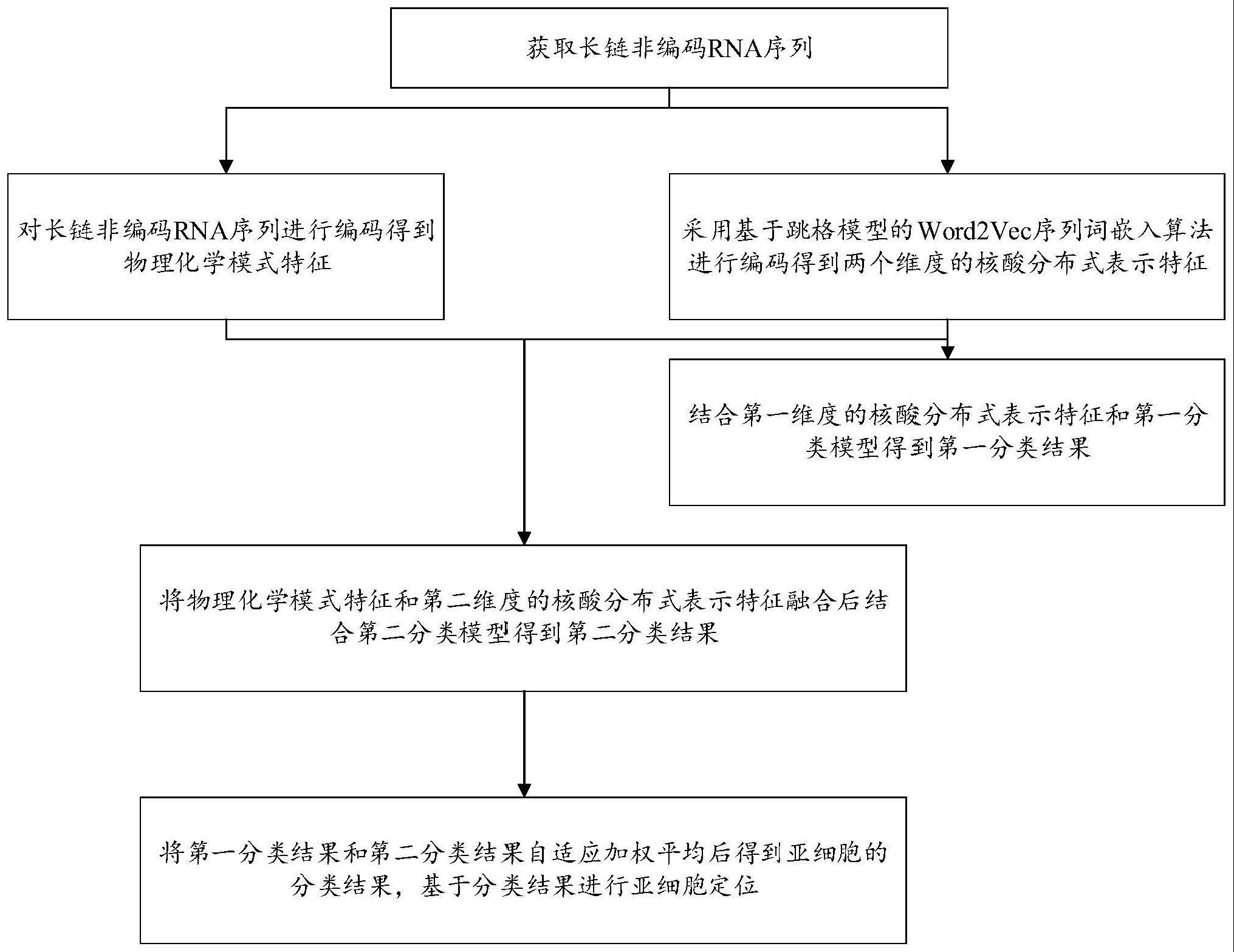
3、本发明的第一个方面提供面向不平衡数据的lncrna亚细胞定位预测方法,包括如下步骤:
4、获取长链非编码rna序列;
5、采用归一化moreau-broto自动交叉相关法对长链非编码rna序列进行编码得到物理化学模式特征;
6、对长链非编码rna序列进行处理得到语料库,基于语料库,采用基于跳格模型的word2vec序列词嵌入算法进行编码得到两个维度的核酸分布式表示特征;
7、结合第一维度的核酸分布式表示特征和第一分类模型得到第一分类结果;
8、将物理化学模式特征和第二维度的核酸分布式表示特征融合后结合第二分类模型得到第二分类结果;
9、将第一分类结果和第二分类结果自适应加权平均后得到亚细胞的分类结果,基于分类结果进行亚细胞定位。
10、本发明的第二个方面提供面向不平衡数据的lncrna亚细胞定位预测系统,包括:
11、数据获取模块,用于获取长链非编码rna序列;
12、特征提取模块,采用归一化moreau-broto自动交叉相关法对长链非编码rna序列进行编码得到物理化学模式特征;
13、对长链非编码rna序列进行处理得到语料库,基于语料库,采用基于跳格模型的word2vec序列词嵌入算法进行编码得到两个维度的核酸分布式表示特征;
14、分类模块,用于结合第一维度的核酸分布式表示特征和第一分类模型得到第一分类结果;
15、将物理化学模式特征和第二维度的核酸分布式表示特征融合后结合第二分类模型得到第二分类结果;
16、定位模块,用于将第一分类结果和第二分类结果自适应加权平均后得到亚细胞的分类结果,基于分类结果进行亚细胞定位。
17、本发明的第三个方面提供一种计算机可读存储介质。
18、一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现如上述第一个方面所述的面向不平衡数据的lncrna亚细胞定位预测方法中的步骤。
19、本发明的第四个方面提供一种计算机设备。
20、一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述第一个方面所述的面向不平衡数据的lncrna亚细胞定位预测方法中的步骤。
21、与现有技术相比,本发明的有益效果是:
22、为了充分利用lncrna的序列信息,提取了物理化学模式特征和核酸的分布式表示特征,同时整合了两个基础分类器,包括卷积神经网络(cnn)和门控递归单元(gru),通过两个模型的自适应加权平均后得到亚细胞的分类结果,基于分类结果进行亚细胞定位,且在训练过程中利用了标签分布边际感知(ldam)损失函数,可以提高在不平衡数据集对于亚细胞定位预测的精度,与传统的机器学习模型相比,提高了在数据不平衡的细胞系上更加细致的分类和更强的鲁棒性
23、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:
1.面向不平衡数据的lncrna亚细胞定位预测方法,其特征在于,包括如下步骤:
2.如权利要求1所述的面向不平衡数据的lncrna亚细胞定位预测方法,其特征在于,所述对长链非编码rna序列进行编码得到物理化学模式特征中采用归一化moreau-broto自动交叉相关法。
3.如权利要求1所述的面向不平衡数据的lncrna亚细胞定位预测方法,其特征在于,所述对长链非编码rna序列进行处理得到语料库的方式为使用窗口大小为3、跨度为1的分词器,将所有长链非编码rna序列分解为包含多个三核苷酸的句子,将所有句子整合后得到语料库。
4.如权利要求2所述的面向不平衡数据的lncrna亚细胞定位预测方法,其特征在于,所述采用归一化moreau-broto自动交叉相关法对长链非编码rna序列进行编码得到物理化学模式特征为:
5.如权利要求1所述的面向不平衡数据的lncrna亚细胞定位预测方法,其特征在于,所述采用基于跳格模型的word2vec序列词嵌入算法进行编码得到两个维度的核酸分布式表示特征包括:
6.如权利要求1所述的面向不平衡数据的lncrna亚细胞定位预测方法,其特征在于,所述第一分类模型采用门控循环单元神经网络,所述第二分类模型采用卷积神经网络。
7.如权利要求1所述的面向不平衡数据的lncrna亚细胞定位预测方法,其特征在于,在第一分类模型和第二分类模型训练时,利用标签分布边际感知损失函数。
8.面向不平衡数据的lncrna亚细胞定位预测系统,其特征在于,包括:
9.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如权利要求1-7中任一项所述的面向不平衡数据的lncrna亚细胞定位预测方法中的步骤。
10.一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1-7中任一项所述的面向不平衡数据的lncrna亚细胞定位预测方法中的步骤。
技术总结
本发明属于亚细胞定位预测领域,提供了面向不平衡数据的lncRNA亚细胞定位预测方法和系统,为了充分利用lncRNA的序列信息,提取了物理化学模式特征和核酸的分布式表示特征,同时整合了两个基础分类器,包括卷积神经网络和门控递归单元,通过两个模型的自适应加权平均后得到亚细胞的分类结果,基于分类结果进行亚细胞定位,可以提高在不平衡数据集对于亚细胞定位预测的精度。为了解决模型在不平衡数据集上表现不佳的问题,在训练过程中利用了标签分布边际感知损失函数。与传统的机器学习模型和现有的预测器相比,本发明方法表现出更强大的类别不平衡容忍度和鲁棒性。
技术研发人员:吴昊,刘海斌,董记华
受保护的技术使用者:山东大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!