一种基于代谢物定性定量数据的非靶向代谢组分析方法与流程
本发明涉及生物信息,更具体地说,它涉及一种基于代谢物定性定量数据的非靶向代谢组分析方法。
背景技术:
1、代谢组学指利用质谱等技术,对生物样本中所有低分子量的代谢产物进行定性和定量,并寻找代谢物与生理病理变化的相关关系的一门科学,是转录组学和蛋白质组学的延伸,能够更直接、更准确地反映生物体的生理状态。目前代谢组学广泛应用于各研究领域,在疾病诊断、药靶筛选、营养与健康管理、个性化药物治疗、植物生长发育与抗逆等各个研究方向受到越来越多的关注,其中,非靶向代谢组能够对样本中的各类代谢物进行无偏向、大规模、系统性的检测,最大程度反映生物体内的代谢水平扰动情况,相关的数据分析需求也日益增加,因此开发一套相应的自动化分析方法非常重要,而现有的分析工具存在如下几点不足:
2、(1)目前已有代谢组自动化分析工具meataboanalyst在对代谢组数据进行整套分析时,需要人工完成对结果的整理以及每步工作的衔接,操作步骤相对较多,比较浪费人工和时间。
3、(2)代谢物通路富集的映射物种选择有限,往往只针对模式生物或特定物种,对于特殊样本的映射物种选择范围窄;
4、(3)无法同时进行多批数据的分析。
技术实现思路
1、针对现有技术存在的不足,本发明的目的在于提供一种基于代谢物定性定量数据的非靶向代谢组分析方法,旨在解决上述技术问题。
2、为实现上述目的,本发明提供了如下技术方案:一种基于代谢物定性定量数据的非靶向代谢组分析方法,包括以下步骤:
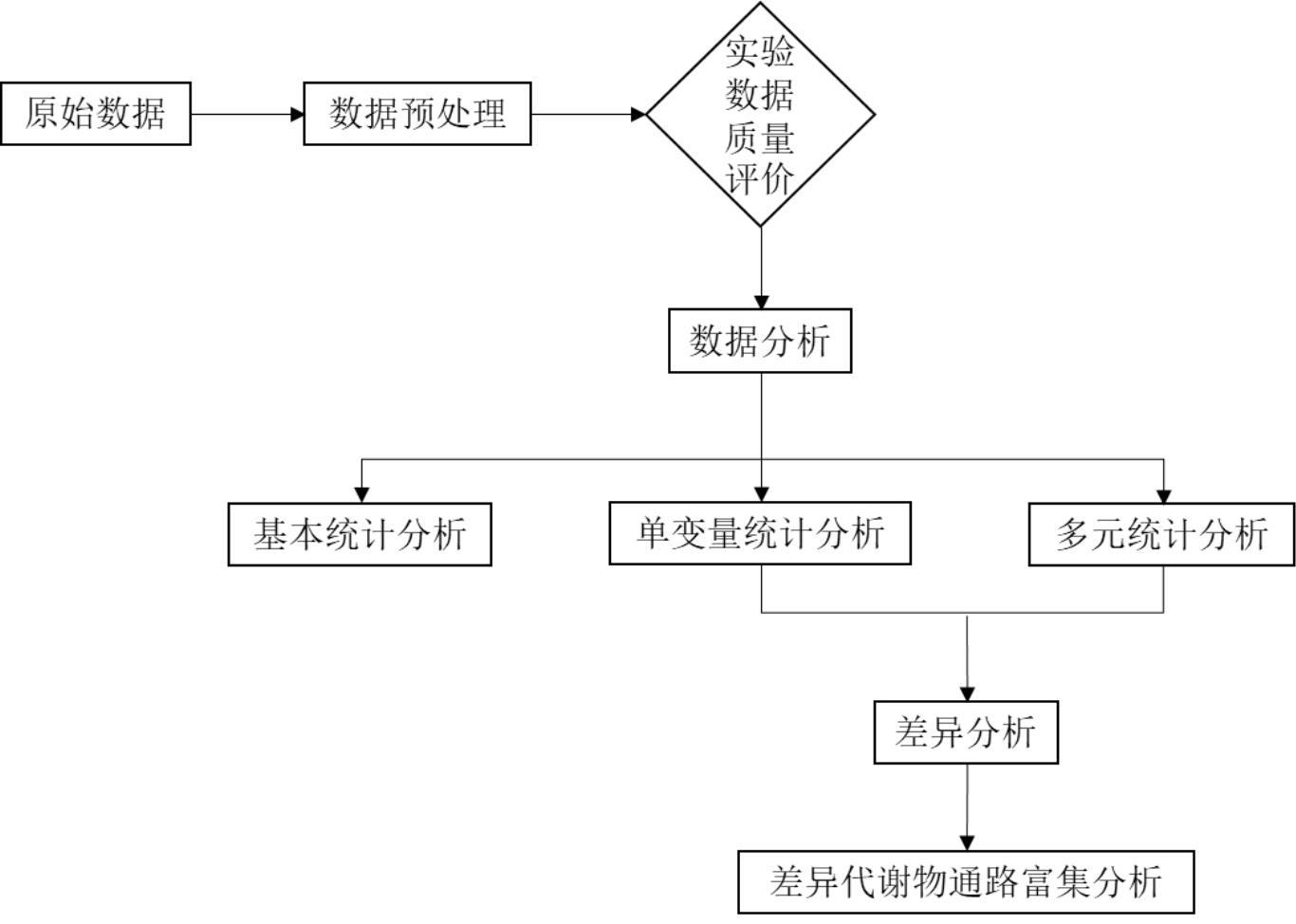
3、步骤一,准备并读取config文件,config文件中包括:正负离子模式下代谢物定性定量数据、样本名对应关系文件、分组名对应关系文件、比较组文件、差异代谢物筛选参数设定、任务名称、分析结果保存路径;
4、步骤二,数据预处理:包括对预先准备的原始数据中目标代谢物在半数及半数以上样本中的表达量进行检查,再对表达量为缺失值和异常值时的情形进行处理并调整数据格式;
5、步骤三,数据质量评估:从总体样本主成分分析、qc样本相关性、qc样本离子峰丰度的相对标准偏差这三个方面评估预处理后的数据质量;
6、步骤四,代谢物基本统计分析:通过代谢物基本统计分析对代谢物的分类和表达量进行统计分析与可视化;
7、步骤五,单变量统计分析:计算对照组和处理组之间代谢物的差异倍数,并使用t检验计算差异显著性pvalue值;
8、步骤六,多元统计分析:借助r语言的ropls软件包,用多元统计的方法如正交偏最小二乘判别分析对代谢组数据进行降维和归类分析,从中挖掘提炼信息,该信息包括vip值;
9、步骤七,差异分析:默认使用结合单变量统计分析得到的差异倍数、pvalue值以及多元统计分析计算出的vip值作为标准,筛选出差异代谢物;
10、步骤八,差异代谢物通路富集分析:对筛选得到的差异代谢物,结合原始数据中的代谢物注释数据,使用脚本根据超几何检验得到差异代谢物显著富集的通路;
11、步骤九,结果整理:对用于生成非靶向代谢组数据分析结果报告的统计分析结果进行整理。
12、作为本发明进一步的方案:所述步骤二中对原始数据的检查方式如下:首先,若数据中某代谢物在半数及半数以上样本中的表达量都是缺失值时,删除此代谢物;若数据中某代谢物在半数及半数以上样本中的表达量不都是缺失值时,将缺失值替换为数值9;然后,将小于或等于0的异常值,替换为0-1之间符合均匀分布的随机数;其次,再对经过处理后的缺失值和异常值的数据进行转置,最后,保存处理后的数据,用于后续分析。
13、作为本发明进一步的方案:所述步骤四中通过制作代谢物分类饼图、密度图、样本相关性图、层次聚类树图、小提琴图和总代谢物热图来对代谢物的分类和表达量进行统计分析和可视化。
14、作为本发明进一步的方案:所述步骤五中的计算方法为对代谢物在对照组样本和处理组样本中的表达量分别求均值,然后用处理组的均值除以对照组的均值,即可得到差异倍数,再使用r语言中t.test函数计算得到差异显著性pvalue值,根据计算得出的差异显著性pvalue值绘制火山图。
15、作为本发明进一步的方案:所述步骤六中多元统计的方法包括主成分分析(pca)和偏最小二乘判别分析(pls-da)。
16、作为本发明进一步的方案:所述步骤七中默认筛选的标准为:当vip>1且差异倍数>1且pvalue<0.05时的代谢物为上调的代谢物;当vip>1且差异倍数<1且pvalue<0.05时的代谢物为下调的代谢物;其余的则为非差异代谢物。
17、与现有技术相比,本发明具备以下有益效果:
18、分析内容全面多层次,涵盖了市场所需绝大部分分析内容,分析时,对正离子模式、负离子模式下的代谢物数据分别进行分析,此外每种模式下分析的代谢物又分为两类,所有代谢物和有kegg compound注释信息的代谢物;
19、自动化程度高,操作简便,自动整理所有分析结果,完成各个部分分析之后,自动对结果进行统计,可视化,以及归类整理,使结果排布尽然有序,直接用于报告生成;
20、差异代谢物通路富集分析不受物种限制,结果呈现多样,提供表格、图片、网页等多种形式的结果,可同时进行多批数据分析。
技术特征:
1.一种基于代谢物定性定量数据的非靶向代谢组分析方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于代谢物定性定量数据的非靶向代谢组分析方法,其特征在于,所述步骤二中对原始数据的检查方式如下:首先,若数据中某代谢物在半数及半数以上样本中的表达量都是缺失值时,删除此代谢物;若数据中某代谢物在半数及半数以上样本中的表达量不都是缺失值时,将缺失值替换为数值9;然后,将小于或等于0的异常值,替换为0-1之间符合均匀分布的随机数;其次,再对经过处理后的缺失值和异常值的数据进行转置,最后,保存处理后的数据,用于后续分析。
3.根据权利要求2所述的一种基于代谢物定性定量数据的非靶向代谢组分析方法,其特征在于,所述步骤四中通过制作代谢物分类饼图、密度图、样本相关性图、层次聚类树图、小提琴图和总代谢物热图来对代谢物的分类和表达量进行统计分析和可视化。
4.根据权利要求3所述的一种基于代谢物定性定量数据的非靶向代谢组分析方法,其特征在于,所述步骤五中的计算方法为对代谢物在对照组样本和处理组样本中的表达量分别求均值,然后用处理组的均值除以对照组的均值,即可得到差异倍数,再使用r语言中t.test函数计算得到差异显著性pvalue值,根据计算得出的差异显著性pvalue值绘制火山图。
5.根据权利要求4所述的一种基于代谢物定性定量数据的非靶向代谢组分析方法,其特征在于,所述步骤六中多元统计的方法包括主成分分析、偏最小二乘判别分析和正交偏最小二乘判别分析。
6.根据权利要求5所述的一种基于代谢物定性定量数据的非靶向代谢组分析方法,其特征在于,所述步骤七中默认筛选的标准为:当vip>1且差异倍数>1且pvalue<0.05时的代谢物为上调的代谢物;当vip>1且差异倍数<1且pvalue<0.05时的代谢物为下调的代谢物;其余的则为非差异代谢物。
技术总结
本发明公开了一种基于代谢物定性定量数据的非靶向代谢组分析方法,其特征在于,包括如下步骤:数据预处理、实验数据质量评估、代谢物基本统计分析、单变量统计分析、多元统计分析、差异分析、差异代谢物通路富集分析、分析结果整理。本发明的有益效果在于:分析内容丰富,涵盖市场所需绝大部分分析内容;操作简便,根据配置文件,自动整合各步骤的数据分析、可视化以及结果整理,继而快速生成报告,分析效率高,可同时进行多批数据的分析。
技术研发人员:孟玉,孙子奎
受保护的技术使用者:南京派森诺基因科技有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!