一种基于深度学习的RNA修饰位点预测模型的构建方法
本发明涉及rna修饰位点预测领域,更具体的,涉及基于深度学习卷积神经网络及循环神经网络组合的预测模型。
背景技术:
1、研究表明,rna的转录后修饰广泛存在于各类生物体中,并起着非常重要的调控作用。rna修饰导致的基因表达失调与还与人类癌症的发病机制有关,并由此研发出了许多治疗癌症的新思路。为此,准确鉴定这些修饰位点的位置信息将有利于这些修饰位点的后续研究。近些年,测序技术的出现为修饰位点的鉴定做出了许多贡献,同时使得各类数据都得到了指数式的增长。
2、然而,传统的测序方法有着流程复杂、耗时以及成本较高的一些缺点。因此,对于这些修饰位点的鉴别以及认识,只靠这些方法是远远不够的。虽然各类rna修饰数据库中的修饰位点数据都方便获取,但是如何从这些大量的测序数据中构建相应的位点识别模型,以及提取出有价值的知识依旧是生物信息学中一个待解决的问题。目前,对于这些生物信息学数据的处理方法中,主要包含一些机器学习中出现频率较高的分类算法,以及一些基于深度学习的常见分类模型。
3、对于m6a甲基化修饰位点来说,schwartz等人率先利用了机器学习的方法,参考了rna序列的核苷酸组成、其相对位置以及二级结构等信息,结合逻辑回归分类器来预测短序列中是否存在m6a的甲基化修饰位点;2018年,zhang等人利用miclip-seq数据建立一个深度学习模型deepm6aseq,该方法结合了卷积层以及lstm,能够基于单碱基测序数据预测序列中的m6a修饰位点,并且表征其位点周围的生物学特征。
4、现有方法虽然虽然取得了一定成果,但其预测性能还有待提升,同时,关于位点形成的机制以及规律还需要深入的挖掘。
技术实现思路
1、本发明利用深度学习的方法建立了一个端到端的修饰位点识别模型。该模型基于卷积神经网络和循环神经网络,进行组合,并增加rna序列的二级结构信息,形成双特征输入模型。同时在循环神经网络层之后加上了注意力机制,以此来提高模型性能。最后,再通过对卷积层进行可视化的方式来了解模型的工作原理以及模型所关注的重要特征。
2、为达到上述目的,本发明采用如下技术方案:
3、一种基于深度学习的rna修饰位点预测模型的构建方法,包括如下步骤:
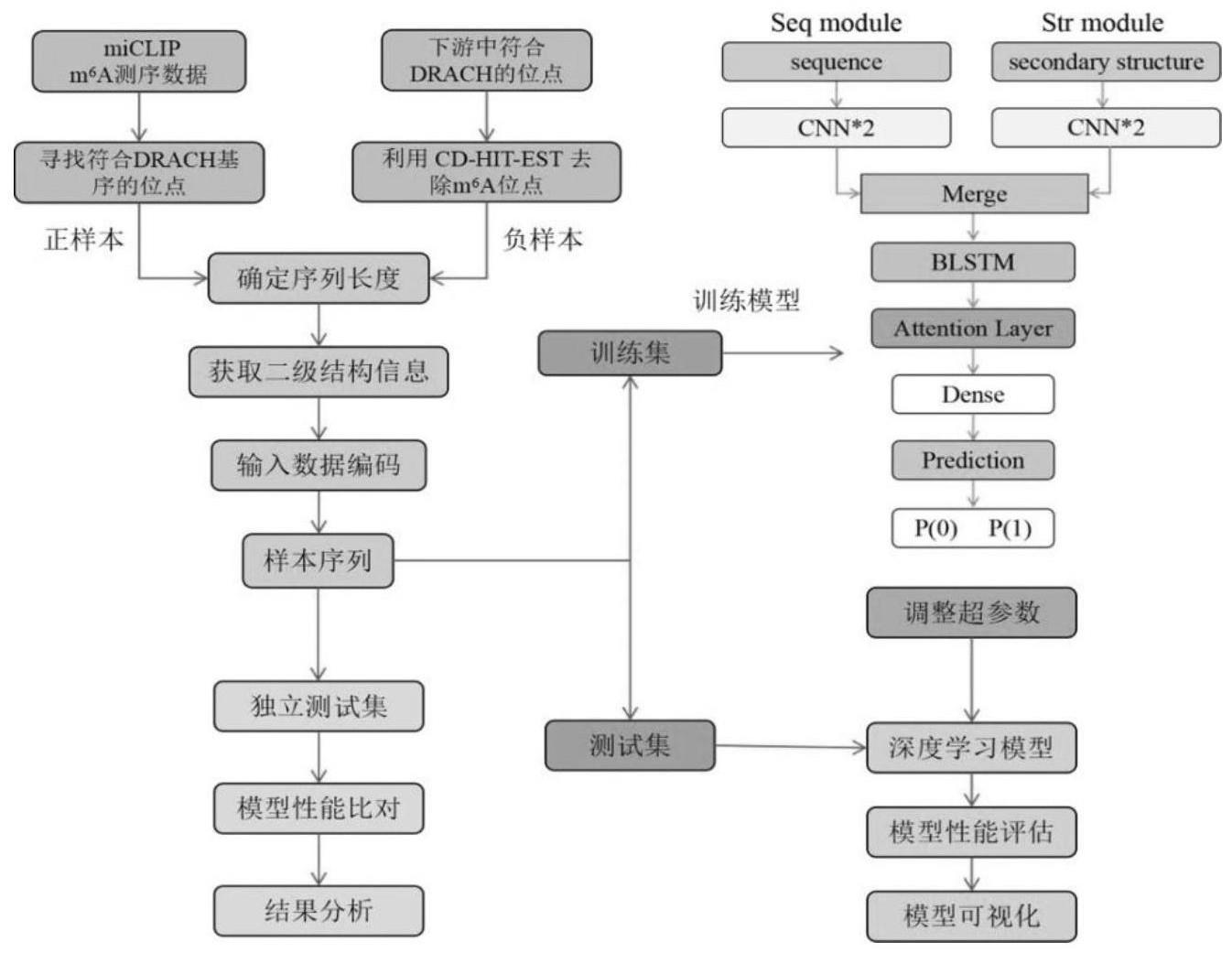
4、步骤1:本发明使用geo数据库中登陆号为gse63753和gse71154的人类rna序列的m6a修饰位点数据,进行模型构建和测试。数据主要包括了5种不同的细胞系和组织类型,分别为:大脑组织、肝组织、a594细胞系、hek293细胞系和cd8t细胞系。获取含有m6a位点信息数据之后,将其定位到人类参考基因组hg19上,根据序列中是否存在含有m6a位点的特征“drach”保守区段进行筛选,并确定序列中心位置,截取此中心位置向两端延伸一定长度的dna序列,作为构建模型的正样本。在相应m6a参考位置下游搜索并截取同样以“drach”保守序列为中心但不是m6a修饰位点的dna序列,作为构建模型的负样本。在样本序列总长选择上,围绕51bp、101bp和151bp设置长度梯度,选择令模型验证效果最佳的长度。获取原始正负样本序列之后,还需要对其进行预处理;
5、为了避免冗余数据对模型训练以及评估所产生的影响,利用计算机程序“cd-hit-est”工具包对所有的样本数据进行去冗余操作,即去除与聚类类中代表序列相似度高于设定阈值的样本,本发明中设定为80%;
6、考虑序列的二级结构也具有一定的生物学意义,模型还引入了二级结构信息。rnafold程序能根据自由能最低等原理进行rna结构预测,获取dot-bracket表示法标记的原始样本序列的最佳二级结构。rna序列中的未产生碱基互补配对的自由碱基用“.”表示,而形成互补碱基对的两个碱基分别用圆括号“(”和“)”表示。
7、步骤2:将rna序列转换为模型能够理解的向量。输入的序列信息以及对应的二级结构信息需要进行相应的数据编码,采用one-hot编码方法。碱基a用向量[1,0,0,0]表示,u用[0,1,0,0]表示,c和g分别表示为[0,0,1,0]和[0,0,0,1]。
8、二级结构信息中点、左右括号表示碱基所属的二级结构,每个碱基其编码为3维的向量,其中“(”被编码为了[1,0,0],“)”被编码为了[0,1,0],“.”则为[0,0,1];
9、步骤3:数据处理结束后,构建模型网络架构。将cnn与rnn结合,采用一维卷积层与lstm层作为模型的基本结构。模型包含三个模块,分别为处理rna序列信息的seq模块,处理序列二级结构信息的str模块,以及将这两者合并处理输出的joint模块。seq和str模块均包含两组由一维卷积层、批标准化层以及dropout层组成的网络块。在joint模块中以上两个模块的信息被整合在一起,再依次通过bilstm层以及attention层,bilstm层用来学习顺序信息,attention层用来改善bilstm的效果,提升模型整体顺序信息学习的效果。最后,全连接层对以上的信息进行最终的整合并作出相应的预测。
10、在模型中,本发明引入了注意力机制,其好处是可以为rna序列中一些重要的碱基分配较高的权重,从而使得模型不仅关注m6a位点上下文信息,还能捕获到序列中的重要位置信息;
11、本发明还采取双输入模式来整合rna序列信息和相应二级结构信息,进一步提高了模型的分类效果;
12、步骤4:确定深度学习的网络架构后,对网络进行训练,完善模型细节并确定各项超参数数值。
13、进一步地,步骤1中去冗余之后,正样本的数量为35922,负样本为29797。为了防止不平衡数据对模型的影响,通过下采样,保证了正负样本数据量的一致。
14、进一步地,步骤1中根据以往经验和设置梯度实验验证确定了序列裁剪的最佳长度为101bp;进一步地,步骤3中模型中的循环神经网络层采用了双向lstm,经过实验验证,其网络层中的隐藏节点为128时模型效果最好。
15、进一步地,步骤中注意力机制的详细计算过程:首先,将输入信号ht送入一个单层感知机中来获得ht的隐含层响应:ut=tanh(wwht+bw)。随后用softmax操作获得一个归一化的权重矩阵最后再输出序列与权重的加权和output=∑tαtht;其好处是可以为rna序列中一些重要的碱基分配较高的权重,从而使得模型不仅关注m6a位点上下文信息,还能捕获到序列中的重要位置信息。
16、进一步地,步骤3中经过反复实验优化了两层卷积层的卷积核数量,第一层中卷积核数量128,第二层则选择了64。对于卷积核长度,这两层分别采用了11和5。
17、进一步地,步骤3中序列信息以及二级结构信息均采用one-hot编码且较为相似。因此,在seq和str这两个模块中也均采用了相同参数设置。
18、与现有的模型相比,本发明具有以下有益的技术效果:
19、将cnn与rnn结合,采用一维卷积层与lstm层作为模型的基本层,额外学习序列的局部特征,同时引入了序列二级结构信息来提升模型分类准确度,增强网络学习过程中的信息流;为了提升模型性能以及防止过拟合,卷积层后面还分别加入了批标准化层以及dropout层;为了更好的体现序列中碱基的顺序信息,采用双向长短期记忆网络(bilstm),bilstm是在lstm的基础上做了进一步发展,拥有前后向两个方向的隐藏层;在现有模型的基础上,还增加attention机制来改善lstm性能。
20、与现有最优的算法模型相比,本发明准确度得到明显提升。为了更好的理解模型的工作原理,该工作还利用第一层cnn卷积核提取了修饰位点周围的重要motif,并与已知的一些motif进行了比对。结果表明,卷积层中的提取的motif与rbm5以及dazap1等motif有着很高的一致性。
- 还没有人留言评论。精彩留言会获得点赞!