基于老年人群的糖尿病关键转变期的识别及预测方法与流程
本发明涉及糖尿病,尤其是指一种基于老年人群的糖尿病关键转变期的识别及预测方法。
背景技术:
1、糖尿病是一种慢性代谢性疾病,由于该疾病的高患病率和相关并发症的致残率,已经成为世界范围内一个严重的健康问题。
2、已有研究表明,从健康到疾病的发展进程中存在临界剧变,在剧变发生前存在一个可能标识疾病发生的临界状态。一些慢性疾病,比如癌症、糖尿病,在临界状态到来前可能存在数年或数十年的慢性炎症过程,这个临界状态即为疾病发生前的关键转变期。临界状态到来之后,疾病进展到不可逆阶段,即使使用高级医疗手段也很难使机体恢复到正常状态。因此,识别糖尿病的关键转变期并进行预测,在关键转变期到来之前采取预防措施,对及时控制糖尿病的发展有着十分重要的意义。
技术实现思路
1、为此,本发明所要解决的技术问题在于克服现有技术中,糖尿病关键转变期无法识别及预测的问题。
2、为解决上述技术问题,本发明提供了一种基于老年人群的糖尿病关键转变期的识别方法,具体步骤包括:
3、确定研究对象;选取在相同年限内连续多次进行体检且体检结果符合质控人员质控标准的老年人群作为研究对象,其体检结果末年诊断为糖尿病,其余年份均未发病;
4、将研究对象的体检指标依据是否为糖尿病风险因素,分为集群内变量和集群外变量;
5、依据分岔理论和中心流理论,利用集群内变量和集群外变量中同年的体检数据,计算各年份的dnb复合指数i,基于dnb复合指数识别糖尿病关键转变期;
6、比较各年份的dnb复合指数i;若其中某一年的复合指数快速上升,则研究对象在该年份处于糖尿病的临界状态,该年份即为末年确诊糖尿病人群的糖尿病关键转变期。
7、在本发明的一个实施例中,所述集群内变量包括年龄,腰围,bmi,葡萄糖,胆固醇,甘油三酯,高密度脂蛋白,低密度脂蛋白;集群外变量包括红细胞压积,红细胞分布宽度cv,血红蛋白测定,平均血红蛋白含量,肌酐,总胆红素,谷草转氨酶,谷丙转氨酶。
8、在本发明的一个实施例中,所述dnb复合指数i的计算公式为:
9、
10、其中,sdd为集群内变量间的平均标准差,pccd为集群内变量间的平均皮尔逊相关系数,pcco为集群内变量和集群外变量间的平均皮尔逊相关系数。
11、在本发明的一个实施例中,所述糖尿病的诊断标准为体检时空腹血糖≥7.0mmol/l。
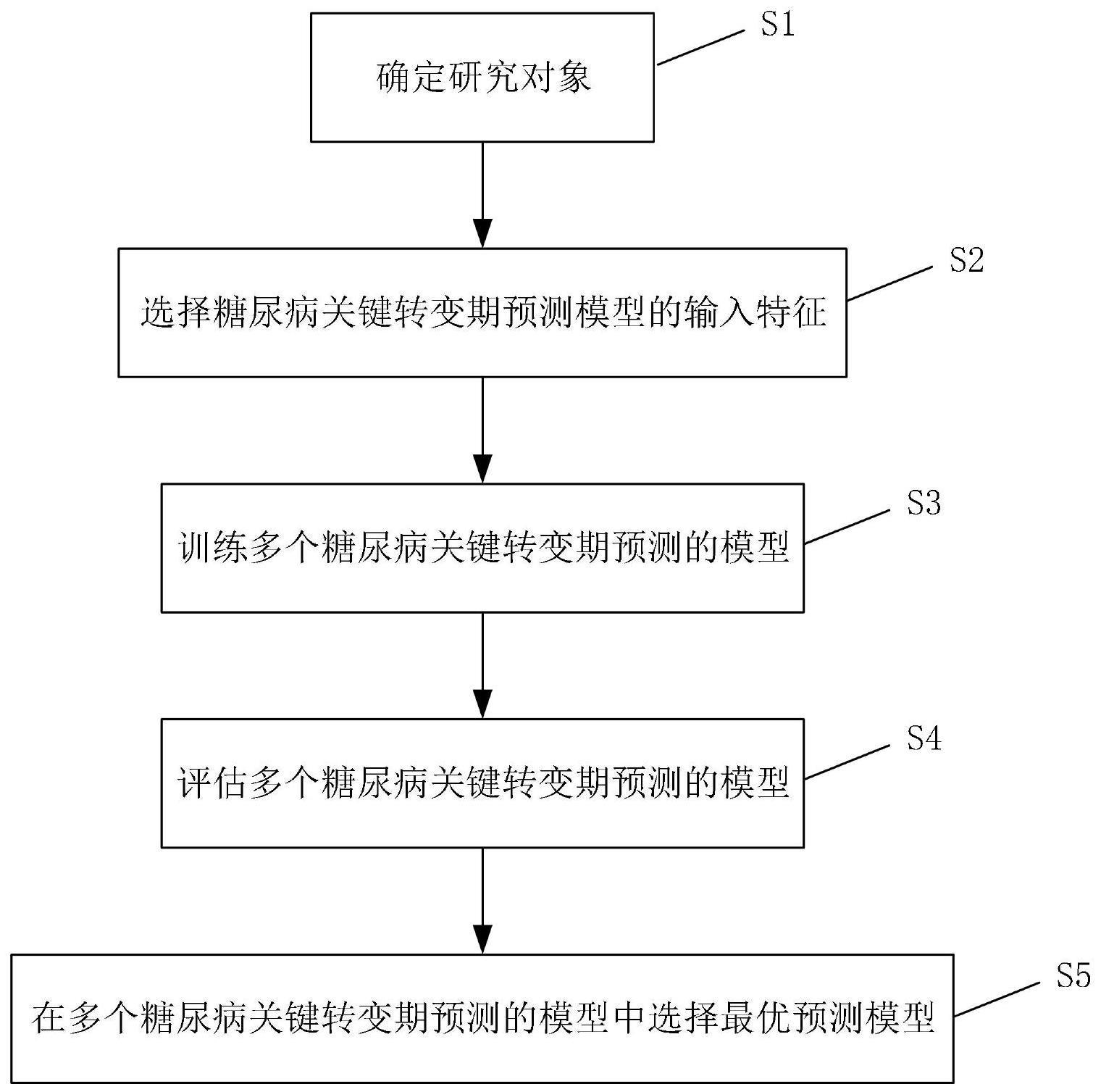
12、本发明还提供了一种基于老年人群的糖尿病关键转变期的预测方法,具体步骤包括:
13、s1、确定研究对象;选取体检结果符合质控人员质控标准的老年人群作为研究对象;
14、s2、选择糖尿病关键转变期预测模型的输入特征,步骤包括:
15、构建数据集;收集所述研究对象的原始体检指标,构建数据集,并利用权利要求1至4任一项所述基于老年人群的糖尿病关键转变期的识别方法,确定数据集中样本的标签,即该样本是否处于糖尿病关键转变期;
16、数据预处理;填补数据集内样本体检指标中连续变量的缺失值,并将连续变量变为二分类变量,然后将整个数据集按照预设比例随机划分为训练集和测试集;
17、特征选择;根据样本体检指标与糖尿病关键转变期的相关性,在原始体检指标中筛选糖尿病关键转变期预测模型的目标输入特征;
18、s3、模型训练;使用多种机器学习算法,构建多个糖尿病关键转变期的预测模型,在训练集上对所述多个预测模型进行训练;
19、s4、模型评估;在测试集上对所述多个糖尿病关键转变期的预测模型进行性能评价,并进一步将所述多个预测模型用于总人群大样本数据集进行测试;
20、s5、依据模型评估中测试集和总人群大样本数据集的测试结果,在所述多个糖尿病关键转变期的预测模型中,选择最优的预测模型作为目标糖尿病关键转变期的预测模型。
21、在本发明的一个实施例中,s2中,所述原始体检指标分为个人信息和生活方式变量、血常规指标、生化指标三类;其中个人信息和生活方式变量包括包括年龄、性别、bmi、吸烟、饮酒、收缩压;所述血常规指标包括红细胞计数、红细胞压积、白细胞计数、血小板计数、血小板平均体积;所述生化指标包括空腹血糖、胆固醇、总胆红素、尿酸。
22、在本发明的一个实施例中,s2中,所述数据预处理,数据集内样本体检指标中连续变量的缺失值采用随机森林法填补,并将连续变量按照roc曲线的cut-off值变成二分类变量,使得分类变量的分类标准是以本研究结局和人群为依据的最佳截断值。
23、在本发明的一个实施例中,s2中,使用单因素逻辑回归作为所述特征选择的方法;将单因素逻辑回归结果显示有统计学意义的变量,按照回归系数绝对值大小,从大到小依次加入预测模型;若对auc有提升,则将该变量保留在模型中,作为建立预测模型的变量。
24、在本发明的一个实施例中,s3中,所述多种机器学习算法包括xgboost算法模型、randomforest算法模型、lightgbm算法模型、mlp神经网络算法模型、svm算法模型和逻辑回归模型。
25、在本发明的一个实施例中,s4中,所述模型性能评价指标包括roc曲线和曲线下面积auc值、敏感度、特异度、阳性预测值ppv、阴性预测值npv和准确率acc。
26、本发明的上述技术方案相比现有技术具有以下优点:
27、本发明所述的一种基于老年人群的糖尿病关键转变期的识别方法,使用动态网络生物标志物模型识别糖尿病从健康到疾病动态进展中的关键转变期,通过动态的、系统化的分析方法,对糖尿病发展过程进行描述和探究。与传统的单一生物标志物研究方法相比,动态网络生物标志物模型能够综合多种生物标志物数据,并且是在临界状态强烈波动的一组成员。所述基于老年人群的糖尿病关键转变期的识别方法能够从时间序列数据中识别疾病的临界状态,从而为糖尿病发生前的精准干预提供重要的理论依据。
28、本发明所述的一种基于老年人群的糖尿病关键转变期的预测方法,通过构建多个机器学习模型,并进一步比较其性能,挑选出最适合的糖尿病关键转变期预测模型,能够帮助我们更准确地筛选处于关键转变期的人群,锁定高危人群,从而提高诊断和治疗的准确性和效果。所述预测方法为精准预防提供理论依据,对预防措施的实施具有指导意义。
29、除此之外,本发明构建糖尿病关键转变期的识别和预测模型的数据为多次连续体检的数据。所述多次连续体检的数据不仅携带了大量的生物医学信息,同时还包含了反应人群健康动态变化的时间信息,具有重要的研究意义和价值。使用多次连续体检数据可以获取更多的生物标志物信息和相关临床指标,从而提高模型的精度和准确性,为确定关键转变期提供更加准确的依据,增加了研究结果的实践意义。
技术特征:
1.一种基于老年人群的糖尿病关键转变期的识别方法,其特征在于,具体步骤包括:
2.根据权利要求1所述的一种基于老年人群的糖尿病关键转变期的识别方法,其特征在于,所述集群内变量包括年龄,腰围,bmi,葡萄糖,胆固醇,甘油三酯,高密度脂蛋白,低密度脂蛋白;集群外变量包括红细胞压积,红细胞分布宽度cv,血红蛋白测定,平均血红蛋白含量,肌酐,总胆红素,谷草转氨酶,谷丙转氨酶。
3.根据权利要求1所述的一种基于老年人群的糖尿病关键转变期的识别方法,其特征在于,所述dnb复合指数i的计算公式为:
4.根据权利要求1所述的一种基于老年人群的糖尿病关键转变期的识别方法,其特征在于,所述糖尿病的诊断标准为体检时空腹血糖≥7.0mmol/l。
5.一种基于老年人群的糖尿病关键转变期的预测方法,其特征在于,具体步骤包括:
6.根据权利要求5所述的一种基于老年人群的糖尿病关键转变期的预测方法,其特征在于,s2中,所述原始体检指标分为个人信息和生活方式变量、血常规指标、生化指标三类;其中个人信息和生活方式变量包括包括年龄、性别、bmi、吸烟、饮酒、收缩压;所述血常规指标包括红细胞计数、红细胞压积、白细胞计数、血小板计数、血小板平均体积;所述生化指标包括空腹血糖、胆固醇、总胆红素、尿酸。
7.根据权利要求5所述的一种基于老年人群的糖尿病关键转变期的预测方法,其特征在于,s2中,所述数据预处理,数据集内样本体检指标中连续变量的缺失值采用随机森林法填补,并将连续变量按照roc曲线的cut-off值变成二分类变量,使得分类变量的分类标准是以本研究结局和人群为依据的最佳截断值。
8.根据权利要求5所述的一种基于老年人群的糖尿病关键转变期的预测方法,其特征在于,s2中,使用单因素逻辑回归作为所述特征选择的方法;将单因素逻辑回归结果显示有统计学意义的变量,按照回归系数绝对值大小,从大到小依次加入预测模型;若对auc有提升,则将该变量保留在模型中,作为建立预测模型的变量。
9.根据权利要求5所述的一种基于老年人群的糖尿病关键转变期的预测方法,其特征在于,s3中,所述多种机器学习算法包括xgboost算法模型、randomforest算法模型、lightgbm算法模型、mlp神经网络算法模型、svm算法模型和逻辑回归模型。
10.根据权利要求5所述的一种基于老年人群的糖尿病关键转变期的预测方法,其特征在于,s4中,所述模型性能评价指标包括roc曲线和曲线下面积auc值、敏感度、特异度、阳性预测值ppv、阴性预测值npv和准确率acc。
技术总结
本发明涉及糖尿病技术领域,尤其是指一种基于老年人群的糖尿病关键转变期的识别及预测方法,使用多次连续的体检数据,运用动态网络生物标志物复合指数,来识别糖尿病关键转变期,并在此基础上构建多个糖尿病关键转变期的预测模型,具体步骤包括确定研究对象、选择构建糖尿病关键转变期预测模型的特征、训练多个糖尿病关键转变期预测的模型、评估多个糖尿病关键转变期预测的模型、在多个糖尿病关键转变期预测的模型中选择最优预测模型。所述方法能够帮助我们更准确地筛选处于关键转变期的人群,锁定高危人群,从而提高诊断和治疗的准确性和效果,为精准预防提供理论依据,对预防措施的实施具有指导意义。
技术研发人员:周慧,俞璐刚,陈小芳,董晨,张可心,刘佳,钱晓燕,吴蕾,周靓玥,景阳,黄彦珲,郭屹彬,朱璇,张敬琪,马玉琴
受保护的技术使用者:苏州市工业园区疾病防治中心有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!