基于复数胶囊网络融合的跨模态抑郁倾向识别模型的构建方法
本发明涉及数据分析,尤其涉及机器深度学习模型,更具体地说涉及一种基于复数胶囊网络融合的跨模态抑郁倾向识别模型的构建方法。
背景技术:
1、抑郁症是全球易发且具有凸显危害性的精神障碍疾病,其轻则带来心理压力,重则导致患者产生轻生的想法。因此,抑郁症的防治要未雨绸缪,并且在社交媒体迅猛发展的时代,如何充分利用丰富的语音、图像以及文本资源,进行便捷且准确的抑郁倾向识别,是研究的主要目的。
2、在情感分析领域,已有的大部分研究都仅仅使用了文本信息来帮助监测抑郁症。如分析文本间的句法、单词用法、建立情感词典;当机器学习算法逐渐投入科研中时,又滋生了基于卷积神经网络、单/双向长短期记忆网络提取患者文特征,并加入注意力机制优化信息提取,最后进行情感分类的方法。
3、尽快基于文本的情感识别有所建树,但当模型在实际场景中应用时,患者说话时的图像、语音等等其他模态的信息也同样蕴含丰富情感。近年来,人们开始倾向于利用多模态数据进行抑郁症检测,包括基于层次化rnn变种网络整合图片、语音或文本特征;基于强化学习抽取相关的语音和文本信息帮助抑郁症检测。
4、总体来看,多模态技术应用于抑郁症检测仍属于研究阶段,现有技术存在的不足可主要总结如下:
5、1、抑郁患者语言具有冗余信息存在和特征序列长的特点。大部分基于注意力机制的融合特征提取方法会带来较大的计算量和不稳定的网络训练过程。因此,需要在小算力和细微层次上建模融合特征学习的方法。
6、2、多模态融合模型的泛化性能普遍较差,并且容易在小样本数据集上过拟合。如何提高模型的鲁棒性和泛化能力,是模型落地的不二法门。
7、3、不同模态的信息间存在语义鸿沟,如何有效融合不同模态的特征语义,会影响模型预测效果上限。
8、虽然多模态郁抑症模型研究问题重重,但在学术界中,将复数用于深度学习任务的场景也在逐年增长。其亮点在于,复数可以为模型架构带来出色的泛化性能。此外,自2016年胶囊网络的概念提出以后,其在情感分析任务中的研究逐渐深入。如何将复数用于胶囊网络架构的优化,并且利用胶囊网络对多模态数据进行融合建模,是目前亟需解决的难题。
技术实现思路
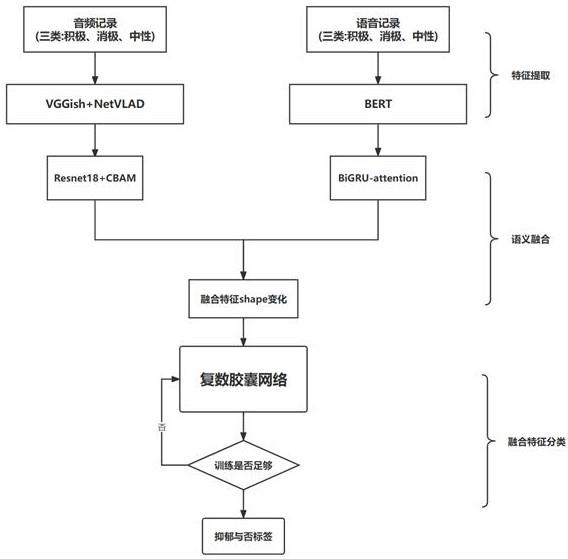
1、为了克服上述现有技术中存在的缺陷和不足,本发明提供了一种基于复数胶囊网络融合的跨模态抑郁倾向识别模型的构建方法,本发明的发明目的在于利用复数胶囊网络对多模态数据进行融合建模,构建出一种能够快速且准确捕获被试者所提供的语音和文本信息,并能能够自适应地挖掘深度语音,并给出预测结果的模型。本发明以语音和文本模态信息作为输入,建立公共语义空间,进行语义融合,利用语义融合后的融合特征训练复数胶囊网络,且本技术的复数胶囊网络采用三层结构,第一层为复数卷积层,第二层为复数胶囊层,第三层为复数路由层,最后聚类生产的高层胶囊,通过解码高层胶囊,得到模型预测结果。本发明能够及时、准确地检测抑郁倾向,防患于未然;且能有效提取并学习融合特征信息,为多模态语义对齐研究提供新方法。
2、为了解决上述现有技术中存在的问题,本发明是通过下述技术方案实现的。
3、本发明提供了一种基于复数胶囊网络融合的跨模态抑郁倾向识别模型的构建方法,该方法包括以下步骤:
4、s1、对参与回答随机抑郁症相关问题的志愿者,记录其回答问题对应的语音音频数据和文本数据,分别构建语音音频训练样本集和文本数据样本集;
5、s2、从语音音频训练样本集中的每个语音音频样本中分别提取出语义特征向量;从文本数据样本集中的每个文本数据样本中分别提取出文本特征向量;
6、s3、将s2步骤中提取出的语义特征向量和文本特征向量,通过映射层建立公共语义空间,并投影到公共语义空间;在公共语义空间进行特征形态转换,将语音和文本在公共语义空间上的特征拼接后转换为双通道复数矩阵,作为融合特征;
7、s4、将s3步骤得到的融合特征作为输入,输入到复数胶囊网络模型中进行训练;所述复数胶囊网络包括三层结构,第一层为复数卷积层,其卷积核为w=a+b*i的形式;在第一层中,对于融合特征进行复数卷积运算,然后利用复数-relu激活函数,分别在实部和虚部上作噪声系数处理,得到去噪特征d;
8、第二层为复数胶囊层,利用256维输出通道的复数卷积网络提取去噪特征d,并进行shape转换,得到复数胶囊单元并压缩;
9、第三层为复数路由层,将第二层压缩后的复数胶囊单位凭借路由机制,更新实复数阈值,最后聚类生成高层胶囊。
10、s5、对复数胶囊网络输出的高层胶囊进行解码,得到预测结果。
11、进一步优选的,s3步骤中,对于语义特征向量,使用resnet18-cbam模型作为映射器;对于文本特征向量,使用gru-attention模型作为映射器;通过映射层建立公共语义空间:
12、其中,fresnet(·)为对被试者语音音频的语义特征提取模型;fbigru(·)为对被试者文本数据的文本特征提取模型;gβa为语义特征映射层,gβt为文本特征映射层,为netvlad提取的语义特征集合,为bert提取的文本特征集合;为语音在公共语义空间上的特征,为文本在公共语义空间上的特征;
13、将和拼接后变化为双通道复数矩阵,作为融合特征:
14、其中,z128a,z128t中的下标128分别表示语义特征和文本特征的高层语义向量维数;fuse(2,16,8)为双通道复数矩阵,其中,下标2表示双通道,16为特征图的长,8表示特征图的宽。
15、s4步骤中,融合特征r=p+q*i,与复数卷积核运算可以表达如下:
16、其中,r表示实部,w表示复数卷积核,i表示虚部,a表示复数卷积核实部,b表示复数卷积核虚部,p表示融合特征实部、q表示融合特征虚部、i表示虚部的符号。
17、利用复数-relu激活函数,分别在实部和虚部上作噪声稀疏处理:
18、crelu(x)=relu(r(x))+i*relu(i(x)),其中,r(x)表示复数卷积核的实部部分,i(x)表示复数卷积核的虚部部分。
19、进一步优选的,在复数路由层中,所述路由机制具体是指,以高层预测胶囊uhat和迭代次数t作为输入,从1到t进行迭代,产生初始权重b1,并在双通道维度上进行softmax,得到权重ci;将权重与高层预测胶囊相乘并求和,将胶囊单元f进行squash操作,并得到输出高层胶囊g={g1,g2},反向传播,更新b2=g*uhat,返回第一步,继续迭代,只至迭代t次后,输出高层胶囊g。
20、进一步优选的,对于一个包含复数学习特征的胶囊为v={v1,v2,…,vk},其胶囊的每一个维度值为vk={a1+b1*j,a2+b2*j,…,ak+bk*j},其胶囊的模长表示为此时模长为m+n*j的形式,保留模长实部,通过放缩法估计实部m的范围为ζ为控制系数,控制胶囊存在概率的上届,此时每个分量的虚数部分融入实部,得到融合特征信息;
21、利用squash对m进行压缩,得到正常特征和抑郁特征的高层胶囊组存在概率{g1,g2}=squash(m1,m2);取{g1,g2}中模长较大者的类别作为被试者抑郁与否的识别结果:labelpredict=arg max(||g1‖,‖g2‖)。
22、s4步骤中,对于复数胶囊网络模型的参数训练与更新,其目标函数由marginloss、focalloss和重构函数加权组成:
23、lk=ek max(0,m+-||gk||)2+λ(1-ek)max(0,‖gk‖-m-)2;
24、fl(pt)=-(1-p)γlog(p);
25、loss=wσl+(1-w)fl(p)+λmse;
26、其中p为预测结果对应的概率,w为权重系数,mse为重构函数,lk表示margin函数,fl表示focal函数;ai表示胶囊分量实部,bi表示胶囊分量虚部,j表示虚部符号,m+表示正样本概率上界,m-表示负样本概率下界。
27、进一步优选的,s2步骤中,采用vggish-netvlad模型从语音音频训练样本集中的每个语音音频样本中分别提取出语义特征向量,具体地,采用vggish从语音音频数据中提取得到语音语义,提取出梅尔普图,再利用netvlad模型对提取出的梅尔普图进行语音语义的融合提取语义特征向量。
28、更进一步优选的,s2步骤中,采用vggish-netvlad模型从语音音频训练样本集中的每个语音音频样本中分别提取出语义特征向量,具体过程如下:
29、对全部的语音特征图进行k-means聚类,获得k个聚类中心,记为ck;
30、将n*d的局部特征图转为一个全局特征图v,表示如下:
31、式中,j表示第j个局部特征,k表示第k个权重参数,i表示第i个语音样本,n表示特征数,为自然数;xi(j)表示第i个语音样本的特征信息,其中w就是netvlad需要学习的参数。
32、进一步优选的,采用bert模型从文本数据样本集中的每个文本数据样本中分别提取出文本特征向量。
33、更进一步优选的,s2步骤中,bert模型是由双向的transformer结构进行堆叠构成;bert模型的编码方式包括oken embeddings(分词编码),segment embeddings(句子编码)以及position embeddings(位置编码)。通过两两之间相加共同输入bert中运行,输出最后通过layernorm层得到句向量。
34、与现有技术相比,本发明所带来的有益的技术效果表现在:
35、本发明中,采用的复数胶囊网络与现有胶囊网络截然不同,其特点是复数胶囊网络特殊的三层结构,分别为复数卷积层、复数胶囊层和复数路由层,第一层使用复数卷积层在各通道上进行特征提取;第二层通过初始胶囊层产生底层胶囊群体,自适应地学习融合特征;第三层基于复数动态路由机制,驱使底层胶囊聚类融合为高层胶囊。最后解码高层胶囊,得到被试者是否有抑郁倾向的结果,同时观测测试集上效果优化网络参数。本发明能够及时、准确地检测抑郁倾向,防患于未然;且能有效提取并学习融合特征信息,为多模态语义对齐研究提供新方法。
- 还没有人留言评论。精彩留言会获得点赞!