基于子树权重拓扑指标预测抗HIV病毒活性的方法
本发明涉及抗hiv活性预测的,特别是一种基于子树权重拓扑指标预测抗hiv病毒活性的方法。
背景技术:
1、图的一个拓扑指标是一个映射f,该映射将图集合映射到实数集合。该指标相当于定义在图上的一个数值描述符,通常情况下是一个图不变量,即同构意义下的两个图,他们对应该拓扑指标的值是相等的。拓扑指标能反映图的很多结构特性,近年来,国内外众多学者使用拓扑指标进行抗hiv活性的预测研究,2001年,gupta等人提出了离心邻接指标,利用该指标进行抗hiv预测,准确率达90%以上。2009年,dureja等人融合了wiener指标、分子连通度指标、增强离心连通拓扑化学指标等三个指标,预测了二甲基氨基吡啶-2-酮的抗hiv活性,预测准确度达到81%-85%之间。2017年,tian等人基于堆叠自编码器进行抗hiv活性预测,实验发现该方法与人工神经网络(ann)、支持向量机(svm)相比,具有非常好的性能。
2、作为基于结构和计数的拓扑指标,图的子树数指标(图的所有非空的子树的个数)和bc子树数指标(任意两片叶子间的距离均为偶数的子树个数)可用来分析混合网络局部可靠性(网络的节点或边遭受攻击时,仍然能够保持连通的性能),rna和蛋白质结构预测及基因发现,预测化合物的物理化学特性。此外,已有研究表明子树数指标和wiener指标、randi′c指标和harary指标关系密切,而后三个指标与化合物的沸点、色谱保留时间、生成热焓、表面积以及水溶解度密切相关。
3、目前的抗hiv活性预测大多采用距离型的拓扑指标,比如wiener指标、离心率联通指标,还未见利用结构型的拓扑指标来进行抗hiv活性预测的研究。
技术实现思路
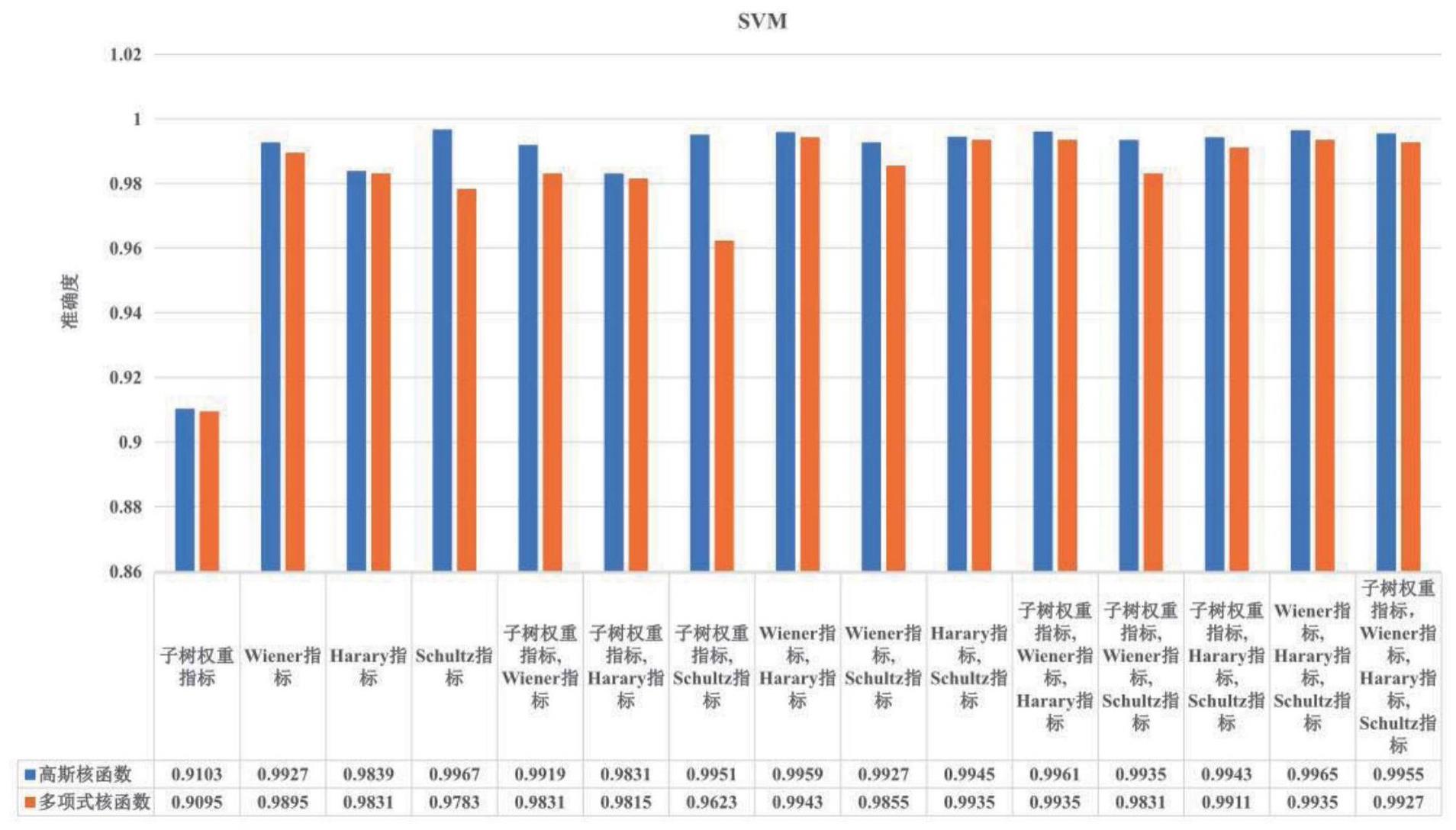
1、本发明提出一种基于子树权重拓扑指标预测抗hiv病毒活性的方法,单个指标子树权重指标的预测准确度为90.95%~94.71%,子树权重指标参与的多个指标预测准确度为93.99%~99.67%,该指标具有良好的特征区分能力,可以为新药研发提供新的度量。
2、本发明的技术方案是这样实现的:基于子树权重拓扑指标预测抗hiv病毒活性的方法,包括以下步骤:
3、(1)将化合物的原子采用对应的化学符号标记为顶点权重,原子与原子之间相连的键价数标记为边权重,然后将顶点权重和边权重映射到n阶广义邻接矩阵,n>1;
4、(2)构造基于n阶广义邻接矩阵的子树权重信息无丢失行列变换规则,对化合物的图g进行树、单圈图结构、双圈图结构的识别,并计算图g的子树权重指标;
5、(3)通过机器学习经典监督学习算法构建模型,对化合物的抗hiv病毒活性进行预测。
6、进一步地,步骤(3)中,将wiener指标、harary指标和schultz指标中的至少一种与子树权重指标相结合,通过机器学习经典监督学习算法构建模型,对化合物的抗hiv病毒活性进行预测。
7、进一步地,步骤(2)中,当图g的结构为树时,树t:=g,树的子树权重指标的计算方法如下:
8、步骤3.1:初始化树厂的子树权重指标为sw:=0;
9、步骤3.2:对于n阶广义邻接矩阵a(t)的任意的主对角线元素ai,i,若第i行和第i列元素除去ai,i后只有一个元素ai,j或ak,i大于0,可知ai,i为叶子顶点,aj,j或ak,k为父亲顶点,采用公式(4)更新aj,j的值aj,j=aj,j(1+ai,iai,j)或ak,k=ak,k(1+ai,iak,i),j≠i≠k,0≤j<n,0≤i<n,0≤k<n,公式(4)如下:
10、v(t′)=v(t)\{u},e(t′)=e(t)\{e},且
11、
12、其中,对任意vs∈v(t′),g′(e)=g(e)(e∈e(t′)),v(t)为树t的顶点集,e(t)为树t的边集,t=(v(t),e(t);f,g)为n(n>1)个顶点的加权树,e=(u,v)为对应的悬挂边,加权树t′=(v(t′),e(t′);f′,g′),u,v为树t的顶点,v(t)\{u}为去除顶点u的顶点集,e(t)\{e}为去除边e的边集,f为顶点生成函数,g为边生成函数;
13、步骤3.3:采用公式(5)更新子树权重指标sw:=sw+ai,i,并删除矩阵a(g)的第i行与第i列,公式(5)如下:
14、f(g;f,g)=f(g′;f′,g′)+f(u) (5)
15、其中,f(g;f,g)为图g的子树权重指标;
16、步骤3.4:重复步骤3.2和步骤3.3直至矩阵a(t)不再变化,若是矩阵a(t)为1阶矩阵,则图g是树,更新子树权重指标sw:=sw+a0,0,就可以得到树的子树权重指标;
17、若矩阵a(t)的阶大于2,则图g不是树,如果余下对角线元素的度都为2,图g为单圈图结构。
18、进一步地,步骤(2)中,单圈图的子树权重指标的计算方法如下:
19、步骤4.1:假定单圈图边集(v1,v2),(v2,v3),...,(vn-1,vn),(vn,v1)分别对应矩阵a(g)中的元素a0,1,a1,2,…,an-2,n-1,a0,n-1,以单圈图顶点在矩阵中的邻接关系构造顺序数组ca=[0,1,…,n-1],这里的数值为对角线元素的位置下标;
20、步骤4.2:根据步骤4.1的数组,可知不含边(vn,v1)的树结构的子树权重指标
21、步骤4.3:同样的,根据步骤4.1的数组,可知不含边(v1,v2)但含边(vn,v1)的树结构的子树权重指标,即
22、步骤4.4:重复步骤4.3,分别计算不含边(v2,v3),但含边(vn,v1),(v1,v2)的树结构的子树权重指标,...,计算不含边(vn-1,vn),但含边(vn,v1),(v1,v2),...,(vn-2,vn-1)的树结构的子树权重指标,再结合步骤4.2以及公式(6),得到基于广义邻接矩阵的单圈图的子树权重指标,公式(6)如下:
23、
24、其中,f(un;f,g)为单圈图的子树权重指标,f(un\(v1,v2);f,g)为单圈图不含边(v1,v2)的子树权重指标,f(un\(vj,vj+1);f,g;(vi,vi+1))为单圈图不含边(vj,vj+1)但含边(vi,vi+1)的子树权重指标。
25、进一步地,步骤(2)中,当图g不是树结构的时候,可以根据广义邻接矩阵中对角线元素的度来识别三种双圈图结构,方法如下:
26、对于广义邻接矩阵a(g),存在一个主对角线元素ai,i,其第i行和第i列元素除去ai,i后共有四个元素大于0,其余主对角线元素aj,j,j≠i,其第j行和第j列元素除去aj,j后共有两个元素大于0,则此矩阵对应双圈图结构bg1;
27、对于广义邻接矩阵a(g),存在两个主对角线元素ai,i,其第i行和第i列元素除去ai,i后共有三个元素大于0,其余主对角线元素aj,j,j≠i,其第j行和第j列元素除去aj,j后共有两个元素大于0,则此矩阵对应双圈图结构bg2或者双圈图结构bg3,更新ai,i邻接的三个大于0的元素中的两个元素置为0,令a:=a,调用树的子树权重指标的计算方法,记返回的结果为r阶矩阵a,若r=1,则为双圈图结构bg3,若r>1,则为双圈图结构bg2。
28、进一步地,无公共边的双圈图bg1的子树权重指标的计算方法如下:
29、步骤6.1:找到度为4的顶点vs在矩阵中的位置下标s,从s出发根据单圈图结构识别算法建立单圈图顶点邻接关系数组;
30、步骤6.2:利用步骤6.1的数组,结合步骤4.2单圈图的不含给定一条边的子树权重计算算法,以及步骤4.3单圈图的含给定路径的子树权重计算算法,可得到单圈图或的不含顶点vs的子树权重以及含顶点vs的子树权重;
31、步骤6.3:若是步骤6.2得到是单圈图的不含顶点vs的子树权重以及含顶点vs的子树权重,则根据步骤6.1数组的值,得到关于另外一个单圈图的广义邻接矩阵,重复步骤6.1和6.2得到单圈图的不含顶点vs的子树权重指标以及含顶点vs的子树权重指标;
32、若是步骤6.2得到是单圈图的不含顶点vs的子树权重以及含顶点vs的子树权重,则根据步骤6.1数组的值,得到关于另外一个单圈图的广义邻接矩阵,重复步骤6.1和6.2得到单圈图的不含顶点vs的子树权重指标以及含顶点vs的子树权重指标;
33、步骤6.4:结合步骤6.2和6.3,根据公式(7),得到无公共边的双圈图bg1的子树权重指标,公式(7)如下:
34、
35、其中,f(bg1;f,g)为双圈图bg1的子树权重指标,f(bg1\vs;f,g)为双圈图bg1不含顶点vs的子树权重指标,为树顶点收缩到圈上后的其中一个单圈图,fc(vs)为树收缩到顶点vs的顶点生成函数,为双圈图中的一个单圈图的含顶点vs的子树权重指标。
36、进一步地,无公共边的双圈图bg2的子树权重指标的计算方法如下:
37、步骤7.1:建立单圈图顶点邻接关系数组,找到度为3的两个顶点vs,wt在矩阵中的位置下标x,β,从x出发建立单圈图顶点邻接数组,若再次找到x,则数组建立成功,若找到β则数组建立失败,或者从β出发建立单圈图顶点邻接数组,若再次找到β,则数组建立成功,若找到x则数组建立失败;若数组建立失败,根据此数组的值断开两个度为3的顶点vs,wt相连的边,再次从x或β出发建立单圈图顶点邻接数组;
38、步骤7.2:根据步骤7.1的数组,可得到此单圈图不含顶点vs或wt的子树权重以及含顶点vs或wt的子树权重,得到另外一个单圈图不含顶点vs或wt的子树权重;或者可得到此单圈图不含顶点vs或wt的子树权重,含顶点vs或wt的子树权重,以及另外一个单圈图不含顶点vs或wt的子树权重;
39、步骤7.3:若含顶点vs,计算含顶点vs的子树权重,首先建立bg2,2的顶点邻接数组,根据此数组,可以计算含顶点wt的子树权重,更新顶点wt的子树权重,断开与wt相连的两条圈上的边,使顶点wt能够收缩到顶点vs,得到含顶点vs的子树权重指标;同理,若含顶点vs,计算含顶点vs的子树权重;
40、若含顶点wt,计算含顶点wt的子树权重,首先建立bg2,2的顶点邻接数组,根据此数组,可以计算含顶点vs的子树权重,更新顶点vs的子树权重,断开与vs相连的两条圈上的边,使顶点vs能够收缩到顶点wt,得到含顶点wt的子树权重指标;同理,若含顶点wt,计算含顶点wt的子树权重;
41、步骤7.4:结合步骤7.2、7.3,结合公式(8),得到无公共边的双圈图bg2的子树权重指标,公式(8)如下:
42、
43、其中,f(bg2;f,g)为双圈图bg2的子树权重指标,f(bg2/vs;f,g)为双圈图bg2不含顶点vs的子树权重指标,为树顶点收缩到圈上后的其中一个单圈图,fc(vs)为树收缩到顶点vs的顶点生成函数,为双圈图中的一个单圈图含顶点vs的子树权重指标。
44、进一步地,有公共边的双圈图bg3的子树权重指标的计算方法如下:
45、步骤8.1:建立单圈图顶点邻接关系数组,找到度为3的两个顶点v0,vm在矩阵中的位置下标x,β,从x出发建立单圈图顶点邻接数组,找到β,则数组建立成功,或者从β出发建立单圈图顶点邻接数组,找到x,则数组建立成功;
46、步骤2:根据步骤8.1数组分别计算不含边(v0,v1)的子树权重指标,含边(v0,v1),不含边(v1,v2)的子树权重指标,........,直至计算含边(v0,v1),(v1,v2),.......,(vm-1,vm)的子树权重指标,结合公式(9),最终得有公共边的双圈图bg3的子树权重指标,1≤m<n,公式(9)如下:
47、
48、其中,f(bg3;f,g)为双圈图bg3的子树权重指标,f(bg3\(v0,v1);f,g)为双圈图bg3不含边(v0,v1)的子树权重指标,为双圈图bg3含边(vi,vi+1)的子树权重指标,为双圈图bg3不含边(vj,vj+1),但含边(vi,vi+1)的子树权重指标。
49、本发明的有益效果:
50、本发明的子树权重指标为子树所有顶点和边的权重乘积,通过构造基于广义邻接矩阵的子树权重信息无丢失行列变换规则,实现对该指标的高效计算.同时结合wiener指标、harary指标、schultz指标,利用机器学习经典监督学习算法(支持向量机(svm),k-近邻算法(knn),决策树算法)构建模型对化合物分子的抗hiv病毒活性进行预测,对子树权重指标具有良好的特征区分能力和准确度(90.95%~99.67%),因此该指标可以作为一种有效的新药研发新度量。
- 还没有人留言评论。精彩留言会获得点赞!