基于深度学习模型预测抗体翻译后修饰位点的方法和系统与流程
本发明涉及人工智能领域,具体涉及一种基于深度学习模型预测抗体翻译后修饰位点的方法和系统。
背景技术:
1、公开于该背景技术部分的信息仅仅旨在增加对本发明的总体背景的理解,而不应当被视为承认或以任何形式暗示该信息构成已为本领域一般技术人员所公知的现有技术。
2、抗体是一种免疫球蛋白分子,可以识别和结合外来抗原并调节免疫反应。抗体的基本结构包括两个重链和两个轻链,它们通过二硫键相互连接形成一个y形分子。
3、抗体在翻译后会发生多种修饰,这些修饰可以影响抗体的结构、功能和稳定性。其中最常见的修饰包括糖基化、去乙酰化、磷酸化、甲基化等。
4、糖基化是抗体翻译后最常见的修饰之一,大约90%的抗体都会发生糖基化。糖基化可以增强抗体的稳定性、活性和黏附性,并且还可以调节抗体与其他分子之间的相互作用。此外,糖基化还可以影响抗体的免疫原性和清除效率。
5、去乙酰化也是一种常见的修饰,在抗体的某些位点上发生去乙酰化可以增加其亲和力和特异性。磷酸化则可能影响抗体与其他分子的相互作用,例如抗体与受体或信号转导分子之间的相互作用。
6、甲基化是一种较少被研究的修饰,但已经发现可以影响抗体的稳定性和免疫原性。此外,还有其他一些不太常见的修饰方式,如二硫键桥的形成、脯氨酸的异构化等。
7、总之,抗体翻译后的修饰对其结构、功能和稳定性都有很大的影响,如何对抗体翻译后的修饰位点进行预测,也是生物制药领域所要解决的问题。
8、在已有技术中,可以通过开发特异于表位翻译后修饰状态的抗体的方法和组合物,生成泛翻译后修饰结合抗体文库以及非翻译后修饰结合抗体文库,然后做大量筛选,以此来寻找感兴趣的翻译后修饰位点。但是,采用数据库筛选的方式进行修饰位点预测的过程比较复杂,且耗时,泛化能力较差。
9、因此,提供一种基于深度学习的修饰位点预测方法,以期利用预先训练的深度学习模型对多种修饰位点进行快速、准确的预测,从而解决现有技术中修饰位点预测过程复杂耗时,泛化能力较差的技术问题,就成为本领域技术人员亟待解决的问题。
技术实现思路
1、发明目的
2、为解决上述技术问题,本发明的目的在于提供一种基于深度学习模型预测抗体翻译后修饰位点的方法和系统。本发明训练好的预测模型仅输入抗体序列即可,可快速实现大量抗体序列的多种翻译后修饰位点的预测。
3、解决方案
4、为实现本发明目的,第一方面,本发明提供了一种基于深度学习模型预测抗体翻译后修饰位点的方法,所述方法包括:
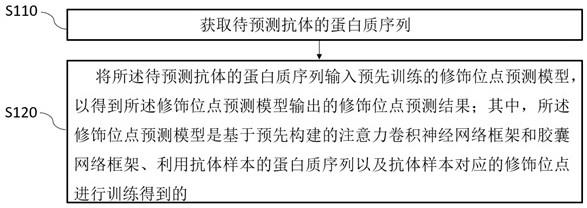
5、获取待预测抗体的蛋白质序列;
6、将所述待预测抗体的蛋白质序列输入预先训练的修饰位点预测模型,以得到所述修饰位点预测模型输出的修饰位点预测结果;
7、其中,所述修饰位点预测模型是基于预先构建的注意力卷积神经网络框架和胶囊网络框架、利用抗体样本的蛋白质序列以及抗体样本对应的修饰位点进行训练得到的。
8、在一些实施例中,基于预先构建的注意力卷积神经网络框架和胶囊网络框架、利用抗体样本的蛋白质序列以及抗体样本对应的修饰位点进行训练,得到所述修饰位点预测模型,具体包括:
9、获取抗体样本的蛋白质序列以及抗体样本对应的修饰位点;
10、将抗体样本对应的修饰位点进行分类,以得到多个位点类别;
11、以所述抗体样本的蛋白质序列和抗体样本对应的位点类别构建数据集;
12、将所述数据集中的训练集分别输入预先构建的注意力卷积神经网络框架和胶囊网络框架中进行训练,以得到所述修饰位点预测模型;
13、在训练过程中,将所述注意力卷积神经网络框架得到的预测分数与所述胶囊网络框架的预测分数取平均值,以所述平均值作为预测结果值。
14、注意力卷积神经网络框架中的注意力机制用于计算全长序列氨基酸之间的相互作用关系的注意力分布,根据注意力分布来计算输入信息的加权平均,提取权重较高的氨基酸对,捕捉抗体序列信息中的远距离依赖特征。
15、在一些实施例中,获取抗体样本的蛋白质序列以及抗体样本对应的修饰位点,具体包括:
16、获取带有翻译后修饰注释信息的抗体样本的蛋白质序列;
17、在所述抗体样本的蛋白质序列中,提取含有以翻译后修饰位点为中心的n个氨基酸残基的片段序列作为一维向量进行二进制单热编码,得到翻译后修饰位点的n×m二维矩阵数据;
18、其中,n为≥7的奇数;m为氨基酸种类的特征维度。
19、在一些实施例中,所述修饰位点预测模型包括多个子模型;将所述待预测抗体的蛋白质序列输入预先训练的修饰位点预测模型,以得到所述修饰位点预测模型输出的修饰位点预测结果,具体包括:
20、将所述待预测抗体的蛋白质序列输入至少一个子模型,以分别得到子模型输出的预测分数;
21、将所述子模型输出的预测分数的平均值与预设的阈值进行比较,在所述预测分数的平均值高于阈值的情况下,则判定该待预测抗体包含翻译后修饰位点,并得到修饰位点预测结果。
22、在一些实施例中,预先构建的所述注意力卷积神经网络框架包括三层卷积层、注意力层、全连接层和输出层,其中,
23、注意力卷积神经网络的第一卷积层用于提取序列编码后的特征,并逐一滤波求和;其中,第一卷积层的卷积通道数为100,卷积核大小:1×1,步长:1,采样率:0.8;
24、注意力卷积神经网络的第二卷积层用于将第一卷积层的输出结果进行填充继续提取特征,再汇总求和,其中,所述第二卷积层卷积核通道数为50,卷积核大小:6×6,步长:1,采样率:0.5;
25、注意力卷积神经网络的第三卷积层,用于将第二卷积层的输出结果进行填充继续提取特征,再汇总求和,其中,所述第三卷积层的卷积核通道数为100,卷积核大小:10×10,步长:1,采样率:0.8;
26、注意力层用于计算全长序列氨基酸之间的相互作用关系的注意力分布,根据注意力分布来计算输入信息的加权平均,提取权重较高的氨基酸对,捕捉抗体序列信息中的远距离依赖特征,其中,注意力层含有100个隐藏神经元,权重上l1正则化参数:0.2;
27、全连接层用于整合抗体序列在卷积层中具有类别区分性的局部信息,所述全连接层含有20个隐藏神经元;
28、输出层用于输出每个残基是翻译后修饰位点的概率,所述输出层含有2个隐藏神经元。
29、在一些实施例中,预先构建的胶囊网络框架包括两层卷积层、第一胶囊层、动态路由层和第二胶囊层,其中,
30、胶囊网络的第一卷积层用于提取序列编码后的特征,逐一滤波求和;其中,卷积通道数为100,卷积核大小:1×1,步长:1,采样率:0.8;
31、胶囊网络的第二卷积层用于将第一卷积层的输出结果进行填充继续提取特征,再汇总求和,其中,卷积核通道数为100,卷积核大小:6×6,步长:1,采样率:0.8;
32、第一胶囊层用于将卷积层探测的基本特征组合,进行卷积运算,其中,卷积核通道数为30,卷积核大小:15×15,步长:1,采样率:0.8;
33、动态路由层用于更新不同层级胶囊的权重,迭代过程中将预测向量进行加权求和,权重更新后进行点积处理,检测胶囊输入与输出的相似性;
34、第二胶囊层用于获得所有向量的主要特征,作出最终分类,其中,正向层具有10个隐藏神经元,反向层具有10个隐藏神经元。
35、第二方面,本发明提供一种基于深度学习的修饰位点预测系统,所述系统包括:
36、数据获取单元,用于获取待预测抗体的蛋白质序列;
37、结果生成单元,用于将所述待预测抗体的蛋白质序列输入预先训练的修饰位点预测模型,以得到所述修饰位点预测模型输出的修饰位点预测结果;
38、其中,所述修饰位点预测模型是基于预先构建的注意力卷积神经网络框架和胶囊网络框架、利用抗体样本的蛋白质序列以及抗体样本对应的修饰位点进行训练得到的。
39、第三方面,提供一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现如第一方面所述方法的步骤。
40、第四方面,提供一种非暂态计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如第一方面所述方法的步骤。
41、有益效果
42、本发明所提供的基于深度学习的修饰位点预测方法,通过获取待预测抗体的蛋白质序列,将所述待预测抗体的蛋白质序列输入预先训练的修饰位点预测模型,即可得到所述修饰位点预测模型输出的修饰位点预测结果;其中,所述修饰位点预测模型是基于预先构建的注意力卷积神经网络框架和胶囊网络框架、利用抗体样本的蛋白质序列以及抗体样本对应的修饰位点进行训练得到的。这样,本发明通过搭建深度学习模型,训练抗体翻译后修饰位点数据集,从而训练出几种常见的抗体翻译后修饰位点的模型,本发明训练好的预测模型仅输入抗体序列即可,可快速实现大量抗体序列的多种翻译后修饰位点的预测;从而利用预先训练的深度学习模型对多种修饰位点进行快速、准确的预测,解决了现有技术中修饰位点预测过程复杂耗时,泛化能力较差的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!