一种基于机器学习的糖尿病肾病风险预测方法及系统
本发明涉及机器学习领域,尤其是涉及一种基于机器学习的糖尿病肾病风险预测方法及系统。
背景技术:
1、糖尿病肾病,也被称为糖尿病性肾病,是一种由糖尿病引起的肾脏疾病。它是糖尿病的一个常见并发症,通常出现在糖尿病患者中。糖尿病肾病的分期一般分为5期,在一期时,可能存在一些不容易察觉肾脏损害,但肾小球滤过率正常,肾脏体积会稍微增大,没有其他症状或者症状不明显;在二期时,肾小球过滤功能轻微下降,开始泄漏微量白蛋白,大多数患者在此之前都没有具体的症状;在第三期,随着病情的进展,尿液中蛋白质的丢失会增加;在第四期,蛋白尿明显,甚至伴随着一些血液,患者会表现出呼吸困难等明显症状;在第五期,也即尿毒症阶段,伴随着导致肾功能不全或终末期肾病,患者可能需要透析或肾移植来维持生命。
2、如果在一期阶段进行干预,逆转的可能性最大,二期会部分逆转,而到了三期及后续,病情会不断加重,逆转的可能性越来越低。对于糖尿病肾病的干预越早越好,甚至前期的及时发现糖尿病肾病比后期治疗效果要好很多。但是越是早期,糖尿病肾病的判断越难,以往对糖尿病肾病的判断依据主要是利用肾小球滤过率(glomerular filtration rate,gfr)公式,但是这是一个经验公式,只是考虑了性别、体重、血清肌酐等这几个因素,有很大的局限性。机器学习能够从很多特征中学习规律,很多高校以及研究机构尝试采用机器学习的方式对糖尿病肾病的得病风险进行预测,但是受限于样本少,尤其是阳性样本少的问题,效果并不明显。
技术实现思路
1、为了解决上述问题,本发明提供了一种基于机器学习的糖尿病肾病风险预测方法,所述方法包括以下步骤:
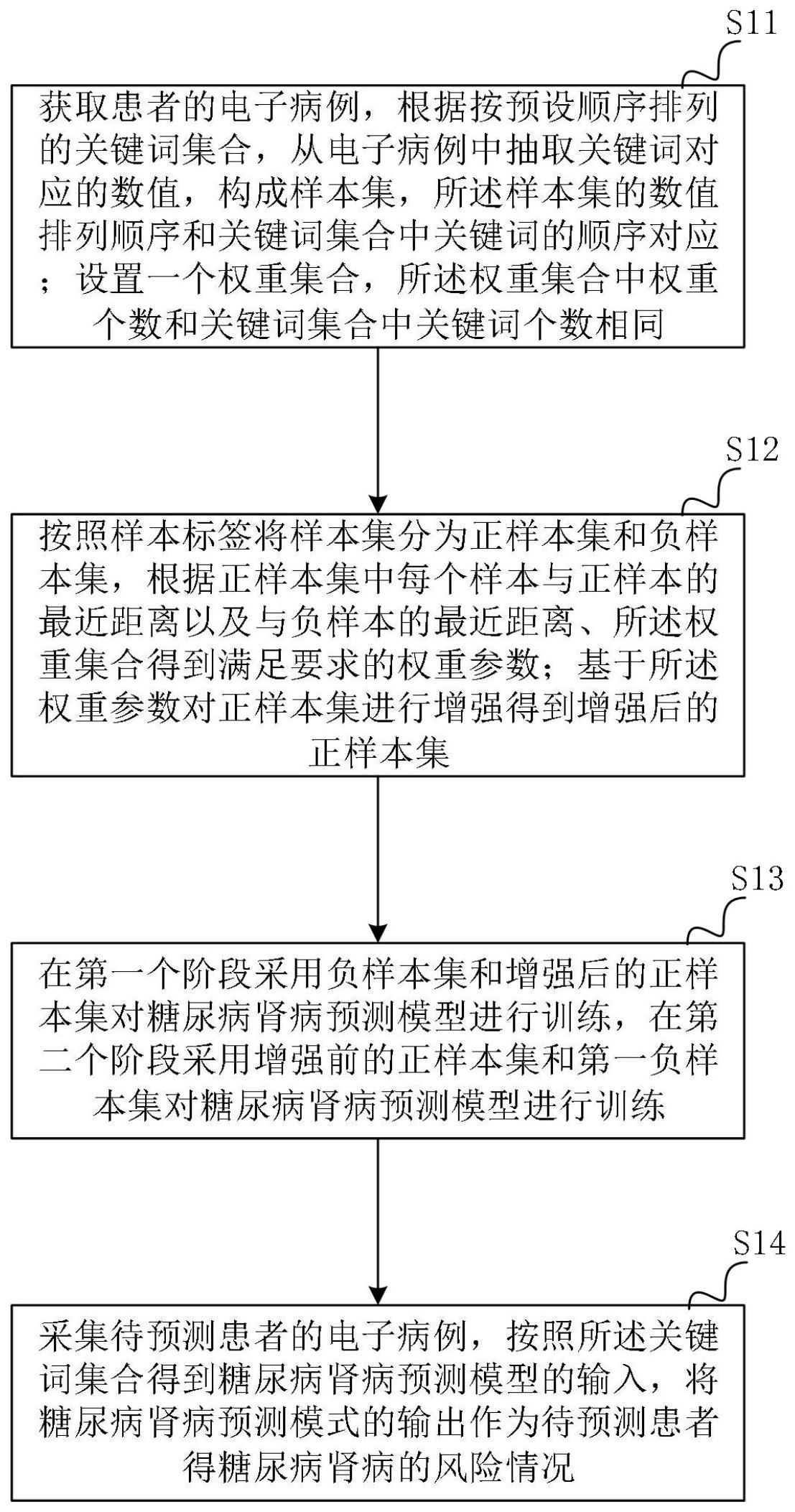
2、获取患者的电子病例,根据按预设顺序排列的关键词集合,从电子病例中抽取关键词对应的数值,构成样本集,所述样本的数值排列顺序和关键词集合中关键词的顺序对应;设置一个权重集合,所述权重集合中权重个数和关键词集合中关键词个数相同;
3、按照样本标签将样本集分为正样本集和负样本集,根据正样本集中每个样本与正样本的最近距离以及与负样本的最近距离、所述权重集合得到满足要求的权重参数;基于所述权重参数对正样本集进行增强得到增强后的正样本集;
4、在第一个阶段采用负样本集和增强后的正样本集对糖尿病肾病预测模型进行训练,在第二个阶段采用增强前的正样本集和第一负样本集对糖尿病肾病预测模型进行训练;
5、采集待预测患者的电子病例,按照所述关键词集合得到糖尿病肾病预测模型的输入,将糖尿病肾病预测模式的输出作为待预测患者得糖尿病肾病的风险情况。
6、优选地,所述根据正样本集中每个样本与正样本的最近距离以及与负样本的最近距离、所述权重集合得到满足要求的权重参数,具体为:
7、获取正样本集中每个正样本与最近的正样本的距离d1、以及与最近的负样本的距离d2,若d1>d2,则按照权重集合重新计算距离d1和/或d2,使得d1<d2,得到多个含有权重的不等式;
8、将所述多个含有权重的不等式作为约束条件,将每个权重的值最接近1作为目标函数,采用数值优化算法得到至少一组权重参数。
9、优选地,所述基于所述权重参数对正样本集进行增强得到增强后的正样本集,具体为:
10、对于正样本中的每个正样本,将正样本的数值和权重集合按对应位置相乘得到增强后的正样本,将增强前的正样本和增强后的正样本放入第二正样本集合;
11、对于所述第二正样本集合中的每个正样本,从所述第二正样本集合中获取所述正样本距离最近的正样本,构成样本对;
12、计算每个样本对的距离,根据所述距离和预设间距获取多个增强样本并放入所述第二正样本集合,对所述第二正样本集合进行过滤操作,将过滤后的所述第二正样本集合作为增强后的正样本集。
13、优选地,所述根据所述距离和预设间距获取多个增强样本并放入所述第二正样本集合,具体为:
14、从样本对的一个样本开始,沿样本对的另外一个样本的方向每隔预设间距增加一个样本点,将增加的样本点作为增强样本放入到第二正样本集合中。
15、优选地,所述对所述第二正样本集合进行过滤操作,具体为:
16、获取所述样本集中每个样本距离其他样本的最近间距d3,确定所述样本集中每个样本对应的间距d3中的最大值d4;
17、计算所述第二正样本集合中每个样本距离第三样本集中其他样本最近的距离d5,若d5>d4,则将样本从所述第二正样本集合中删除;其中所述第三样本集包括所述第二正样本集合和所述负样本集。
18、优选地,所述第一负样本集中样本的数量和增强前的正样本集中样本的数量相同;且所述第一负样本集中样本是按照与增强前的正样本集中正样本的距离从所述负样本集中选取。
19、优选地,所述第一负样本集中样本是按照与增强前的正样本集中正样本的距离从所述负样本集中选取,具体为:
20、计算所述负样本集中每个样本与最近的n个负样本的平均距离d6、以及与最近的n个正样本的平均距离d7,按照|d6-d7|从小到大的顺序对所述负样本集中的样本排序,从排序后的样本中选取与增强前的正样本集中样本个数相同的负样本。
21、此外,本发明还提供了一种基于机器学习的糖尿病肾病风险预测系统,所述系统包括以下模块:
22、样本集获取模块,用于获取患者的电子病例,根据按预设顺序排列的关键词集合,从电子病例中抽取关键词对应的数值,构成样本集,所述样本的数值排列顺序和关键词集合中关键词的顺序对应;设置一个权重集合,所述权重集合中权重个数和关键词集合中关键词个数相同;
23、样本集增强模块,用于按照样本标签将样本集分为正样本集和负样本集,根据正样本集中每个样本与正样本的最近距离以及与负样本的最近距离、所述权重集合得到满足要求的权重参数;基于所述权重参数对正样本集进行增强得到增强后的正样本集;
24、训练模块,用于在第一个阶段采用负样本集和增强后的正样本集对糖尿病肾病预测模型进行训练,在第二个阶段采用增强前的正样本集和第一负样本集对糖尿病肾病预测模型进行训练;
25、预测模块,用于采集待预测患者的电子病例,按照所述关键词集合得到糖尿病肾病预测模型的输入,将糖尿病肾病预测模式的输出作为待预测患者得糖尿病肾病的风险情况。
26、优选地,所述根据正样本集中每个样本与正样本的最近距离以及与负样本的最近距离、所述权重集合得到满足要求的权重参数,具体为:
27、获取正样本集中每个正样本与最近的正样本的距离d1、以及与最近的负样本的距离d2,若d1>d2,则按照权重集合重新计算距离d1和/或d2,使得d1<d2,得到多个含有权重的不等式;
28、将所述多个含有权重的不等式作为约束条件,将每个权重的值最接近1作为目标函数,采用数值优化算法得到至少一组权重参数。
29、优选地,所述基于所述权重参数对正样本集进行增强得到增强后的正样本集,具体为:
30、对于正样本中的每个正样本,将正样本的数值和权重集合按对应位置相乘得到增强后的正样本,将增强前的正样本和增强后的正样本放入第二正样本集合;
31、对于所述第二正样本集合中的每个正样本,从所述第二正样本集合中获取所述正样本距离最近的正样本,构成样本对;
32、计算每个样本对的距离,根据所述距离和预设间距获取多个增强样本并放入所述第二正样本集合,对所述第二正样本集合进行过滤操作,将过滤后的所述第二正样本集合作为增强后的正样本集。
33、优选地,所述根据所述距离和预设间距获取多个增强样本并放入所述第二正样本集合,具体为:
34、从样本对的一个样本开始,沿样本对的另外一个样本的方向每隔预设间距增加一个样本点,将增加的样本点作为增强样本放入到第二正样本集合中。
35、优选地,所述对所述第二正样本集合进行过滤操作,具体为:
36、获取所述样本集中每个样本距离其他样本的最近间距d3,确定所述样本集中每个样本对应的间距d3中的最大值d4;
37、计算所述第二正样本集合中每个样本距离第三样本集中其他样本最近的距离d5,若d5>d4,则将样本从所述第二正样本集合中删除;其中所述第三样本集包括所述第二正样本集合和所述负样本集。
38、优选地,所述第一负样本集中样本的数量和增强前的正样本集中样本的数量相同;且所述第一负样本集中样本是按照与增强前的正样本集中正样本的距离从所述负样本集中选取。
39、优选地,所述第一负样本集中样本是按照与增强前的正样本集中正样本的距离从所述负样本集中选取,具体为:
40、计算所述负样本集中每个样本与最近的n个负样本的平均距离d6、以及与最近的n个正样本的平均距离d7,按照|d6-d7|从小到大的顺序对所述负样本集中的样本排序,从排序后的样本中选取与增强前的正样本集中样本个数相同的负样本。
41、最后,本发明提供了一种计算机可读存储介质,所述存储介质上存储有计算机程序,所述计算机程序在被处理器执行时,实现如上所述的方法。
42、针对采用机器学习预测糖尿病肾病患病风险时,样本个数少,尤其正样本个数少,出现样本不平衡,影响预测效果的问题,本发明按照样本标签将样本集分为正样本集和负样本集,根据正样本集中每个样本与正样本的最近距离以及与负样本的最近距离、所述权重集合得到满足要求的权重参数;基于所述权重参数对正样本集进行增强得到增强后的正样本集;在第一个阶段采用负样本集和增强后的正样本集对糖尿病肾病预测模型进行训练,在第二个阶段采用增强前的正样本集和第一负样本集对糖尿病肾病预测模型进行训练。通过上述过程,增强了正样本数量,使得正样本和负样本的数量达到平衡;而且在训练时,先用增强后的正样本进行训练,而后采用原来的正样本进行训练,提高模型的拟合程度以及最后预测的准确度。
- 还没有人留言评论。精彩留言会获得点赞!