基于数据驱动与机理模型自适应融合的水泥强度预测方法
本发明涉及深度学习算法,具体而言,尤其涉及一种基于数据驱动与机理模型自适应融合的水泥强度预测方法。
背景技术:
1、水泥是建筑工程的基础原材料之一,在国民经济建设中占有重要的地位,如何有效控制水泥质量,提高水泥生产效率,是整个水泥生产行业关注的焦点。
2、水泥强度是用来衡量水泥质量的一个关键指标,目前业界人员均将28天作为水泥强度基本稳定的龄期,并且将水泥28天强度作为通用水泥的代表强度。水泥熟料28天强度的预测是一个多变量、非线性、滞后时间长的复杂问题。熟料中各种矿物质成分在水泥水化、硬化过程中进行了一系列复杂的化学反应,所以熟料中各种矿物质成分及相对含量对熟料强度的有着非常复杂的影响,传统的简单的线性函数关系并不能够精确地描述水泥生产的复杂过程。水泥熟料28天强度需要等到第28天人工化验得到,周期长,滞后时间长,无法预先调配混合材掺入量。因此需要找到影响熟料强度的主要因素,摸索并进一步完善适应生产工程实际的预测熟料28天强度的方法,建立合理准确的预测模型,从而可以尽早发现水泥熟料的质量问题,及时调整生料配比、水泥配合比中混合材的掺加量,合理确定水泥粉磨细度和粉磨时间,使水泥生产过程处于科学控制状态,在确保出厂水泥的标号的同时,获得更高的收益。
3、传统的机理建模的方法是通过线性函数关系式预测水泥强度,这种把高度非线性关系简化为线性关系的方式,会导致预测精度不够。目前,采用较多的是数据驱动的方法,如神经网络算法:back propagation(bp)、deep neural networks(dnn)等来建立非线性关系。然而单纯数据驱动的方法是一个黑箱建模的过程,模型的好坏过度依赖于数据,所以模型的可靠性不能得到保证,而且训练好的模型对不同数据来源适用性不高。
4、针对上述问题,本发明提出了一种基于数据驱动与机理模型自适应融合的水泥强度预测方法。
技术实现思路
1、根据上述提出的不足,而提供一种基于数据驱动与机理模型自适应融合的水泥强度预测方法。本发明主要通过将机理模型与数据驱动模型融合,机理模型保证模型的可靠性,数据驱动模型使用卷积神经网络(convolutional neural networks,cnn)提取高度复杂的非线性关系,从而提高模型预测精度。同时,提出自适应融合更新机制,当测试误差大于设定阈值时,会以批量学习方式将测试完的数据返回机理模型和数据驱动模型来更新模型参数,以达到更新模型提高精度的目的。
2、本发明采用的技术手段如下:
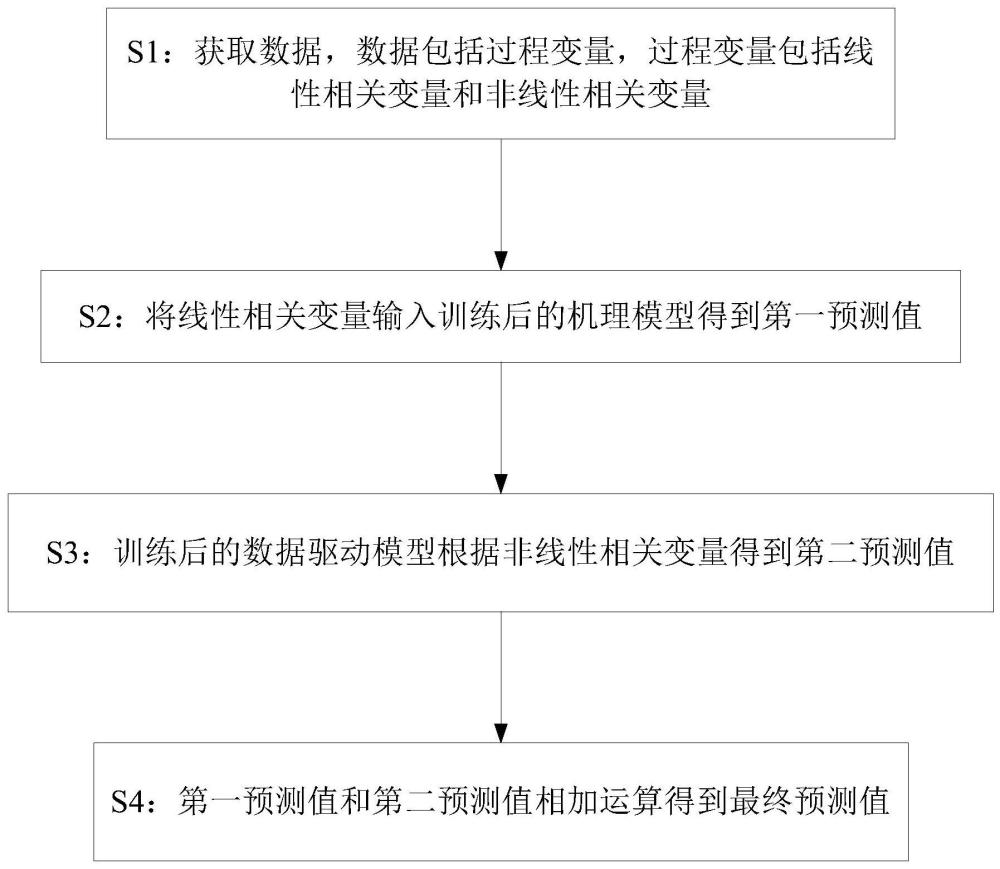
3、本发明提供的一种基于数据驱动与机理模型自适应融合的水泥强度预测方法,包括:
4、获取数据,所述数据包括过程变量,所述过程变量包括线性相关变量和非线性相关变量;
5、将所述线性相关变量输入训练后的机理模型得到第一预测值;
6、训练后的数据驱动模型根据所述非线性相关变量得到第二预测值;
7、所述第一预测值和所述第二预测值相加运算得到最终预测值。
8、进一步地,对所述数据驱动模型进行训练,包括:
9、获取训练集,所述训练集包括多个训练样本,所述训练样本包括所述过程变量和质量变量;
10、将所述线性相关变量输入训练后的所述机理模型得到所述第一预测值;
11、将所述质量变量和所述第一预测值的差值作为所述数据驱动模型的标签,向所述数据驱动模型输入所述非线性相关变量进行训练,得到训练后的所述数据驱动模型。
12、进一步地,将所述质量变量和所述第一预测值的差值作为所述数据驱动模型的标签,向所述数据驱动模型输入所述非线性相关变量进行训练之前,还包括:
13、对所述质量变量和所述第一预测值的差值、所述非线性相关变量进行归一化处理,按照以下方式计算:
14、
15、其中,xi为第i非线性相关变量,x为xi对应的向量,yi为所述数据驱动模型训练过程中,所述质量变量和所述第一预测值的差值,y为yi对应的向量,min()为取最小值函数,max()为取最大值函数,为xi归一化后的值,为yi归一化后的值。
16、进一步地,还包括:
17、根据水泥第1天至第n天的水泥强度均值和预设准确度得到误差限;
18、当所述最终预测值与真实值的偏差小于等于所述误差限,将所述真实值、所述数据形成数据组进行保存;
19、当所述最终预测值与所述真实值的偏差大于所述误差限,将保存的所述数据组更新至所述训练集,采用更新后的所述训练集对所述机理模型和所述数据驱动模型进行训练。
20、进一步地,训练后的所述数据驱动模型根据所述非线性相关变量得到所述第二预测值,包括:
21、对所述线性相关变量进行归一化处理后输入训练后的所述数据驱动模型得到输出值;
22、对所述输出值进行反归一化处理,得到所述第二预测值。
23、进一步地,对所述输出值进行反归一化处理,按照以下方式计算:
24、
25、其中,为所述输出值,为所述第二预测值,min()为取最小值函数,max()为取最大值函数,y为yi对应的向量,yi为所述数据驱动模型训练过程中,质量变量和所述第一预测值的差值。
26、进一步地,所述数据驱动模型包括顺次连接的第一block模块、第二block模块、第三block模块、第一全连接层和第二全连接层;
27、所述第一block模块、所述第二block模块和所述第三block模块结构相同,包括顺次连接的卷积层、批量归一化层和非线性激活函数层;
28、所述第一全连接层包括相连接的linear层和所述非线性激活函数层;
29、所述第二全连接层包括相连接的所述linear层和sigmoid激活函数层。
30、进一步地,所述第二全连接层按照以下方式计算:
31、
32、其中,xblock为所述第三block模块的输出值,linear()为所述linear层处理,sigmoid()为所述sigmoid激活函数层处理,为所述输出值。
33、进一步地,根据所述水泥第1天至第n天的水泥强度均值和所述预设准确度得到所述误差限,按照以下方式计算:
34、
35、其中,为所述水泥第1天至第n天的水泥强度均值,yj为第j天的水泥强度值,s为所述预设准确度,r为所述误差限。
36、进一步地,采用所述训练集对所述数据驱动模型进行训练时,损失函数按照以下方式计算:
37、
38、其中,y′为真实值归一化处理后的值,为输出值,λ为正则化系数,w为所述数据驱动模型的参数。
39、较现有技术相比,本发明具有以下优点:
40、1、本发明提供的基于数据驱动与机理模型自适应融合的水泥强度预测方法,提出了机理模型与数据驱动模型融合的方法,机理模型解决定性的问题,数据驱动模型解决定量的问题,两者互补。机理模型,提高模型的可靠性;数据驱动模型,通过cnn学习复杂过程的非线性特征建立数据驱动模型,提高预测精度。
41、2、本发明提供的基于数据驱动与机理模型自适应融合的水泥强度预测方法,提出了自适应融合更新机制,定义了预测值与实际值的误差限,当测试误差大于设定阈值时,会将测试完的数据返回机理模型和数据驱动模型来更新模型参数,以达到自适应更新模型提高精度的目的。
42、3、本发明提供的基于数据驱动与机理模型自适应融合的水泥强度预测方法,考虑了不同水泥厂家独特生产条件和加工差异,能够不断更新模型,以批量学习模式自适应地修正预测偏差。
- 还没有人留言评论。精彩留言会获得点赞!