一种基于时间序列的大气腐蚀速率预测模型的制作方法
本发明涉及大气腐蚀研究及预测领域,具体为一种使用长短时记忆神经网络时间序列技术预测大气腐蚀速率的模型。
背景技术:
1、材料及其制品在自然大气环境中会受到各种气象和环境因素的影响,导致其变质、甚至破坏,这种现象被称为大气腐蚀。大气腐蚀不仅影响材料的美观性,而且可能降低材料的机械强度,影响其使用寿命。
2、大气中,金属材料所面临的腐蚀影响因子很多,其中主要涉及气象因子和大气中的污染物。由于金属在大气中常常受到多重因素的综合作用,腐蚀行为表现出复杂性。气象因子中尤为重要的是大气的相对湿度、温度、表面润湿时间、降雨量以及日照时间等。
3、此外,大气中的降尘、风向等也会对金属的腐蚀行为产生一定的影响。特别是在不同的区域,空气中的成分会有所不同。例如,在工业较为发达的地方,空气中可能会含有较多的硫化物、氮化物等大气污染物质。因此,准确预测金属材料的大气腐蚀速率,必须综合考虑多种因素的影响,并对材料的大气腐蚀状况及其主要的环境影响因素进行持续的、实地的数据积累,基于这些数据进行科学的分析,建立腐蚀速率预测模型。
4、随着数据科学和机器学习技术的发展,时间序列预测已经在多个领域显示出了强大的预测能力。其中,lstm(长短时记忆)模型因其在处理长序列数据上的优势,逐渐成为时间序列预测的热门技术。但是,在大气腐蚀速率预测方面,基于lstm的研究还处于初级阶段,相关的研究和应用还不够成熟。
5、目前市场上大部分的大气腐蚀速率预测工具或模型主要基于统计学方法,这些方法在某些简单场景下可能表现良好,但在复杂的真实环境中,它们往往无法准确地捕捉腐蚀速率的动态变化规律。因此,开发一个能够充分利用时间序列数据特性,具有高准确性和泛化能力的大气腐蚀速率预测模型显得尤为重要。为满足金属材料大气腐蚀与防护技术的要求,并结合现代数据分析技术的迅速发展,迫切需要一个基于时间序列的大气腐蚀速率预测模型,以提高预测的准确性,为各个行业提供更为可靠的技术支持。
技术实现思路
1、为了克服现有大气腐蚀速率预测模型的缺陷,本发明首先对腐蚀数据、环境以及气象时间序列数据进行采集,腐蚀数据包括瞬态腐蚀速率,环境污染物数据包括温度、相对湿度、二氧化硫、二氧化氮、一氧化碳、臭氧、空气质量指数(aqi)、pm2.5及pm10,气象数据包括风速、风向、天气状况指数、降雨、气压、凝露温度、热指数、紫外线指数、风寒温度、白天与否及阵风速率。由于各特征变量的值相差较大,并且与腐蚀速率的数量级相差超过105。因此在构建时间序列预测模型之前,先对所有特征变量进行标准化,对腐蚀速率作数处理。
2、随后对时间序列数据进行adf(augmented dickey fuller)平稳性检验,帮助更容易捕捉到数据中的模式,选择合适的模型和评估指标,提高模型的性能。再对平稳性检验后的数据,进行关键特征筛选,以瞬时腐蚀速率作为输出,其他参数作为输入,建立随机森林模型,得到影响金属材料腐蚀的大气环境因子重要性,剔除重要性低于5%的影响因子。进而基于长短时记忆神经网络建立时间序列预测模型,并通过超参数迭代使模型达到最佳性能,实现了基于时间序列的大气腐蚀速率预测模型。
3、本发明具体采用如下技术方案:
4、一种基于时间序列的大气腐蚀速率预测模型,其特征在于包括以下步骤:
5、步骤一:金属材料实时大气腐蚀速率、气象及污染物数据获取
6、通过腐蚀大数据电偶传感器技术获取材料的腐蚀速率,电偶传感器的工作原理为双电极体系,钢材料为工作电极,铜电极既作为参考电极又作为对电极。钢电极与铜电极之间存在绝缘垫片,三者紧密耦合,当传感器的表面形成薄液体电解质膜,腐蚀就会发生,从而产生瞬态腐蚀电流,通过数据标准化即可实现材料腐蚀速率的实时获取。气象及污染物数据通过多种环境因子传感器获取。
7、步骤二:数据预处理
8、将采集的大气腐蚀数据按小时作平均,再将平均后的数据与环境、污染物及气象数据通过时间关联起来,从而得到模型训练数据集,每条样本的结构由多维特征变量组成。由于各特征变量的值相差较大,并且特征变量与腐蚀速率的数量级相差超过105。因此在构建时间序列预测模型之前,先对所有特征变量进行标准化,对腐蚀速率作对数处理。
9、步骤三:平稳性检验
10、使用adf检验对时间序列数据进行平稳性检测,adf检验的原假设是时间序列数据非平稳,备择假设是时间序列数据平稳。在adf检验中,会得到一个检验统计量。而临界值是在1%、5%和10%的显著性水平下的阈值,如果检验统计量小于选择的显著性水平下的临界值,那么可以拒绝原假设,认为时间序列数据是平稳的。
11、步骤四:关键特征筛选
12、为了确定每个特征变量对大气腐蚀速率影响的重要性,并剔除重要性较低的特征变量。以除腐蚀速率外其他参数作为输入,腐蚀速率作为输出,建立随机森林模型,使用的随机森林模型通过scikit-learn库实现,将重要性低于5%的特征变量从数据集剔除,不参与后续建模。
13、步骤五:lstm时间序列预测模型构建
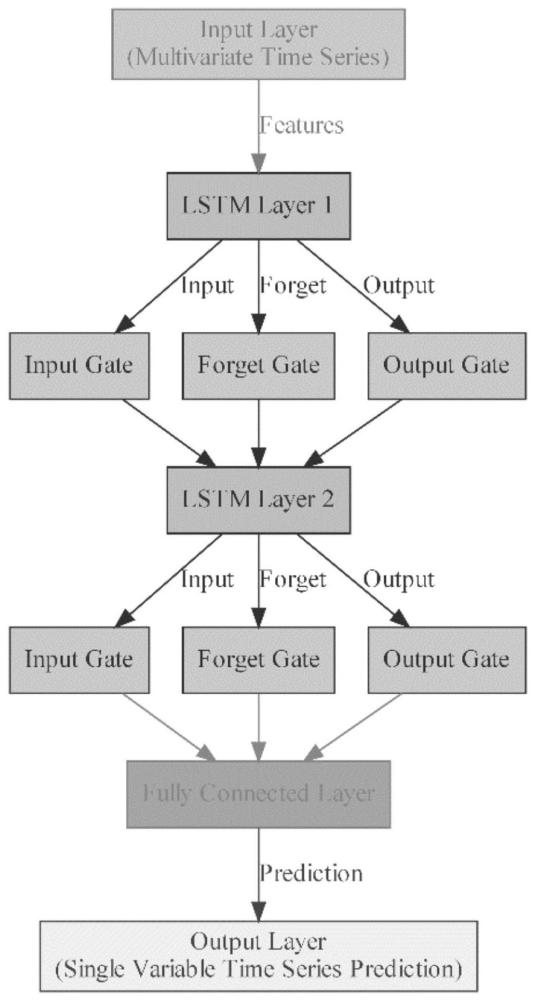
14、使用的lstm模型通过tensorflow库实现。图1展示出lstm方法的预测过程。lstm通过引入“门”结构解决了传统循环神经网,以及两个记忆:长记忆和短记忆,通过这些门来控制信息在时间序列中的传递和遗忘。
15、输入门决定将哪些新信息添加到细胞状态。它包含两个部分:一个sigmoid函数来决定更新的程度,一个tanh函数来计算新的候选细胞状态。
16、遗忘门决定了哪些信息需要从细胞状态中遗忘,通过sigmoid函数来实现。
17、输出门控制如何基于当前细胞状态生成当前时间步的隐藏状态(短记忆)。它使用一个sigmoid函数来确定哪些信息将输出,并使用一个tanh函数来缩放细胞状态。细胞状态是lstm中的长记忆。它通过遗忘门和输入门的输出进行更新。
18、通过在神经网络结构中引入门控机制,lstm能够自适应地确定在每个时间步中哪些信息需要保留、遗忘或更新。在训练过程中,lstm使用损失函数来优化预测结果,通常使用预测值与真实值之间的误差来衡量损失函数。经过一定数量的迭代,lstm模型逐渐适应输入数据的时序特征,并进行预测。
19、步骤六:lstm模型最佳参数确定
20、通过网格搜索的方式进行batch size(批尺寸)和epochs(轮次)为深度学习中两个十分重要的参数,batch size是指在一次迭代中所抓取的样本数量。较小的批尺寸可能导致梯度的更新更频繁,从而使模型训练得更快,但是较小的批量可能会导致模型在训练集上的收敛不稳定。较大的批量可以提高模型在训练集上的稳定性,但可能需要更多的内存,并且训练速度可能较慢。
21、epochs是指模型在整个训练数据集上进行的完整迭代次数,在每个epoch中,模型将对所有数据进行一次完整的前向传播和反向传播,增加epoch的数量可能使模型在训练集上的性能提高,但过多的epoch可能导致过拟合。
22、与现有的技术比,本发明的有益效果是:
23、现有的大气腐蚀速率预测方法一般是基于传统机器学习方法,忽略时间这一维度对腐蚀进程的影响。大气腐蚀是随时间变化的动态过程,随着时间的推进,不同阶段的腐蚀速率、腐蚀机理和影响因素各不相同。时间序列预测通过分析历史数据中的模式和趋势,预测未来某个时间点或一段时间内的数据,帮助发现数据中的规律,例如周期性、趋势性和季节性等。本发明创造性的通过lstm时间序列预测模型,实现了大气腐蚀速率的精准预测,其结果相对传统机器学习方法更为科学准确,可以很好的用于预测大气腐蚀及开发相应的腐蚀防护方法中。
- 还没有人留言评论。精彩留言会获得点赞!