基于大数据的胶原蛋白肽抗衰老评估系统的制作方法
本发明涉及医疗保健信息处理,具体涉及基于大数据的胶原蛋白肽抗衰老评估系统。
背景技术:
1、胶原蛋白肽是一种蛋白质分子,是胶原蛋白的一种水解产物。通常作为保健品或化妆品中的成分使用,具有美容、抗衰老、促进伤口愈合等功能。胶原蛋白肽具有一定的抗衰老功能。随着年龄的增长,人体内胶原蛋白的含量会逐渐减少,导致皮肤失去弹性和水分,并出现皱纹和干燥等现象。胶原蛋白肽的补充可以促进皮肤的胶原蛋白合成,改善皮肤弹性,增加皮肤水分含量,从而减缓皮肤老化的速度。
2、而在使用大数据对胶原蛋白肽抗衰老效果进行评估时,其中的异常数据会直接影响评估精度,故需要对其中的异常数据进行检测。lof局部离群因子(local outlierfactor)是常用的一种异常数据检测方法。而lof算法中k值的设定直接影响了异常检测的精度。k值过大,异常数据可能会被误判为正常数据。k值过小,数据点只考虑了非常有限的邻域信息,容易受到局部噪声和随机波动的影响,将正常数据误判为异常数据。
技术实现思路
1、为了解决算法本身容易受到影响的技术问题,本发明提供了基于大数据的胶原蛋白肽抗衰老评估系统,所采用的技术方案具体如下:
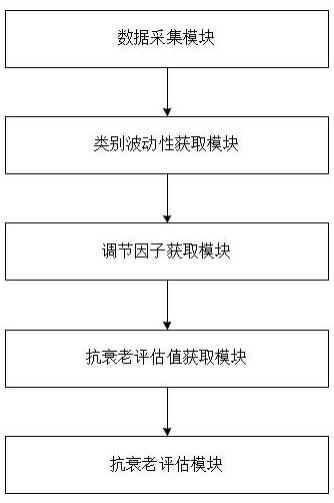
2、本发明提出了基于大数据的胶原蛋白肽抗衰老评估系统,该系统包括以下模块:
3、数据采集模块,用于获取用户的特征数据、皮肤相关数据、使用胶原蛋白肽的时间以及胶原蛋白肽的使用量,所述特征数据包括但不限于用户的年龄、性别、工作时间;
4、类别波动性获取模块,用于构建多维空间,获取每个用户的数据点和特征序列;将每一类特征数据对应的所有用户的特征值构成一条波动序列,根据波动序列中的特征值获取特征数据的类别波动性;
5、调节因子获取模块,用于根据数据点之间的类别波动性和特征序列特征值的差异获取数据点之间的特征差异值;任意一个数据点记为目标数据点,以目标数据点获取圆形区域,根据圆形区域内数据点到目标数据点的距离获取数据点的距离差异特征值;根据圆形区域内数据点的距离差异特征值、特征差异值以及数据点到目标数据点的欧氏距离获取目标数据点对应的圆形区域的分布规律性;根据目标数据点对应的圆形区域的分布规律性以及圆形区域内的最大特征差异值获取目标数据点的调节因子;
6、抗衰老评估值获取模块,用于根据调节因子对已知k值进行调节获取最优k值,根据最优k值获取最优局部离群因子,将用户使用胶原蛋白肽的时间和最优局部离群因子的比值作为用户置信度;根据用户置信度、胶原蛋白肽的使用量以及用户的皮肤相关数据获取胶原蛋白肽的抗衰老评估值;
7、抗衰老评估模块,用于根据抗衰老评估值判断胶原蛋白肽的抗衰老效果。
8、优选的,所述构建多维空间,获取每个用户的数据点和特征序列的方法为:
9、将用户的每个特征数据作为一个维度构建多维空间,每个用户在多维空间中表示一个数据点,用户的所有特征数据的值记为特征值,所有特征值构成一条特征序列。
10、优选的,所述根据波动序列中的特征值获取特征数据的类别波动性的方法为:
11、所述波动序列中的特征值是从小到大排序的,获取波动序列中的最大特征值和最小特征值,计算每个特征值在波动序列中出现的频率,根据波动序列中相邻特征值的差异和频率差异以及最大特征值和最小特征值获取特征数据的类别波动性。
12、优选的,所述根据波动序列中相邻特征值的差异和频率差异以及最大特征值和最小特征值获取特征数据的类别波动性的方法为:
13、将波动序列中相邻特征值的差值记为第一特征差异,将相邻特征值对应的频率差值记为第一频率差异,将任意一个特征值记为第一特征值,将第一特征值与其相邻靠后的特征值的第一特征差异和第一频率差异的乘积记为第一乘积,将最大特征值和最小特征值的差值的绝对值记为第一绝对值,将第一绝对值与所有特征值的第一乘积的累计和的乘积作为特征数据的类别波动性。
14、优选的,所述根据数据点之间的类别波动性和特征序列特征值的差异获取数据点之间的特征差异值的方法为:
15、;
16、式中,表示第b个数据点对应的特征序列中第e个特征值,表示第c个数据点对应的特征序列中第e个特征值,表示第e个特征数据的类别波动性,n表示数据点对应的特征值个数,表示第b个数据点和第c个数据点的特征差异值。
17、优选的,所述以目标数据点获取圆形区域,根据圆形区域内数据点到目标数据点的距离获取数据点的距离差异特征值的方法为:
18、以目标数据点为圆心,选取距离目标数据点最近的预设数量个数据点,以选取的数据点中距离目标数据点最远的欧氏距离为半径构建圆形区域;
19、将圆形区域内所有数据点到圆心的距离从小到大排序获取距离序列,将距离序列中任意一个数据点记为选择数据点,将选择数据点到圆心的欧氏距离与距离序列中选择数据点后一位数据点到圆心的欧氏距离的差值的绝对值记为选择数据点的距离差异特征值。
20、优选的,所述根据圆形区域内数据点的距离差异特征值、特征差异值以及数据点到目标数据点的欧氏距离获取目标数据点对应的圆形区域的分布规律性的方法为:
21、;
22、式中,表示目标数据点的圆形区域内的第r个数据点的距离差异特征值, 表示目标数据点的圆形区域内的第个数据点的距离差异特征值,表示目标数据点的圆形区域内的第r个数据点与目标数据点的欧氏距离,表示目标数据点的圆形区域内的第r个数据点与目标数据点的特征差异值,表示目标数据点的圆形区域内的最大欧氏距离,表示目标数据点的圆形区域内的最小欧氏距离,n表示目标数据点圆形区域内除了目标数据点的数据点的数量,表示以自然常数为底的指数函数,表示目标数据点对应的圆形区域的分布规律性。
23、优选的,所述根据目标数据点对应的圆形区域的分布规律性以及圆形区域内的最大特征差异值获取目标数据点的调节因子的方法为:
24、预设初始k值,根据初始k值获取初始lof值;
25、在同时满足条件和条件,调节因子为;
26、在同时满足条件和条件时,调节因子为;
27、其中,表示目标数据点的圆形区域内的最大特征差异值,表示目标数据点对应的圆形区域的分布规律性,表示初始lof值,表示线性归一化。
28、优选的,所述根据调节因子对已知k值进行调节获取最优k值的方法为:
29、当调节因子为时,已知k值与调节因子加一的乘积作为调节后的k值,当调节因子为时,已知k值与调节因子减一的乘积作为调节后的k值,将调节后的k值重新计算得到新的k值,直到不满足调节条件或调节次数超过预设数量时,此时的k值就是最优k值。
30、优选的,所述根据用户置信度、胶原蛋白肽的使用量以及用户的皮肤相关数据获取胶原蛋白肽的抗衰老评估值的方法为:
31、皮肤相关数据包括皮肤的种类以及使用胶原蛋白前后每个皮肤相关数据对应的相关值;
32、;
33、式中,表示第i个用户对应的用户置信度,表示第i个用户的胶原蛋白使用量,表示使用胶原蛋白肽前第i个用户对应的第j个归一化相关值,表示使用胶原蛋白肽后第i个用户对应的第j个归一化相关值,o表示采集的皮肤相关数据的种类,u表示用户的数量,表示以自然常数为底的指数函数,表示胶原蛋白肽的抗衰老评估值。
34、本发明具有如下有益效果:本发明中获取胶原蛋白肽抗衰老评估的相关数据,通过对采集到的数据进行分析构建数据种类的类别波动性,进而基于类别波动性与数据点邻域内数据点的差异与分布规律性构建lof算法中k值的调节因子,进而基于调节因子对k值进行自适应调节,获取最优k值进行完成数据的异常检测,基于数据所对应的lof值构建用户置信度,基于用户置信度完成胶原蛋白肽的抗衰老评估。通过对k值的自适应调节,提高了胶原蛋白肽抗衰老评估的精度。
- 还没有人留言评论。精彩留言会获得点赞!