一种基于大语言模型的人工智能用药辅助方法及装置
本发明涉及机器学习领域、计算机视觉领域以及自然语言处理领域,尤其涉及一种基于大语言模型的人工智能用药辅助方法及装置。
背景技术:
1、大语言模型在医疗领域已经有了很广泛的应用。大语言模型以其强大的语言理解能力,能快速地对大量信息进行处理和分析,在医疗领域可以较好地完成医疗助理类工作,如用药咨询、健康咨询等。然而,大语言模型在医疗领域的应用距离具体落地还存在一定距离,医疗领域是一个专业性很强,对大语言模型回答的准确率要求很高的一个领域,而大语言模型会存在隐私泄露、回答准确率不高等问题。因此,深入研究并实现一个安全、可靠、便捷的人工智能辅助用药系统对大语言模型在医疗领域的应用发展具有重要的作用。
2、目前,已有人对大语言模型在医疗领域的应用作了众多研究。杜克-新加坡国立大学医学院(duke-nus medical school)daniel shu wei ting等研究人员近日在naturemedicine发表《大语言模型医学应用的机遇与挑战》,从大语言模型开发历史、现状出发,以chatgpt为代表阐释了在医学等领域表现优异的大语言模型的训练以及fine-tuning过程;并剖析其医学应用存在的信息不准确、不及时、隐私泄露等问题。颜健智等在论文《生成式大语言模型在医疗领域的潜在典型应用与面临的挑战》中指出生成式大语言模型在医疗领域的应用逐渐增多,为医疗服务、医学研究和教育等方面提供智能辅助,同时也面临诸多挑战,如其本身存在的幻觉问题,以及数据隐私保护、伦理、结果可控性和算法可解释性等问题。以上论文都明确指出了大语言模型在医疗领域的应用存在着回答准确率不高,隐私泄露等问题。
3、综上所述,虽然大语言模型在医疗邻域中能为医疗的发展。但是在回答准确率、据隐私保护、伦理、结果可控性和算法可解释性等还存在较大的问题,这些问题严重阻碍了大语言模型在医疗领域的落地应用,因此建立一款能落地的基于大语言模型的人工智能辅助用药系统是促进该领域发展的一个当务之急。
技术实现思路
1、为至少一定程度上解决现有技术中存在的技术问题之一,本发明的目的在于提供一种基于大语言模型的人工智能用药辅助方法及装置。
2、本发明所采用的技术方案是:
3、一种基于大语言模型的人工智能用药辅助方法,包括以下步骤:
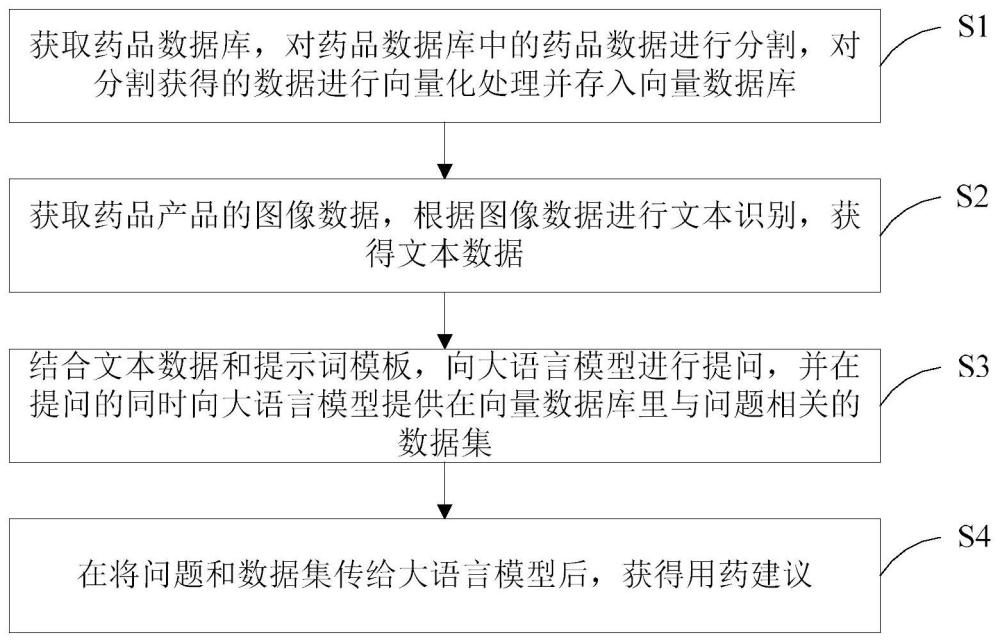
4、获取药品数据库,对药品数据库中的药品数据进行分割,对分割获得的数据进行向量化处理并存入向量数据库;
5、获取药品产品的图像数据,根据图像数据进行文本识别,获得文本数据;
6、结合文本数据和提示词模板,向大语言模型进行提问,并在提问的同时向大语言模型提供在向量数据库里与问题相关的数据集;
7、在将问题和数据集传给大语言模型后,获得用药建议。
8、进一步地,所述对药品数据库中的药品数据进行分割,对分割获得的数据进行向量化处理并存入向量数据库,包括:
9、利用开源的langchain框架中的text_splitter组件将药品数据进行分割;
10、利用langchain框架中的text-embedding-ada-002模型将分割出来的药品数据编码成向量,并将向量存入向量数据库。
11、进一步地,所述根据图像数据进行文本识别,获得文本数据,包括:
12、对图像数据进行预处理;
13、对预处理后的图像数据进行特征提取,根据提取的特征定位图像中的文字区域;其中使用非极大值抑制来去除重叠的区域;
14、将获得的文字区域输入预设的文字识别模型中进行识别,获得文本数据。
15、进一步地,所述对预处理后的图像数据进行特征提取,根据提取的特征定位图像中的文字区域,包括:
16、利用paddleocr框架通过文本检测定位图像中文本出现的位置,获得检测框;
17、将检测框调整为矩形框,判断矩形框中的文本方向是否为正向,若出现文字方向为非正向,对矩形框进行调整;
18、根据获得矩形框,以对矩形框中的文字进行识别。
19、进一步地,所述将获得的文字区域输入预设的文字识别模型中进行识别,获得文本数据,包括:
20、对文字区域内的文字进行ocr识别,得到文本数据;
21、遍历文本数据并判断是否识别出以第一预设标识开头的文本,若识别出,则将该文本去除;
22、遍历文本数据并判断是否识别出以第二预设标识结尾的文本,若识别出,则将该文本添加到负责存储的列表中,并返回该列表;
23、使用正则表达式将其分割为多个成分,并返回这些成分;
24、将识别出的药品名字置入变量name中,将识别出的药品成份置入变量ram中。
25、进一步地,所述结合文本数据和提示词模板,向大语言模型进行提问,并在提问的同时向大语言模型提供在向量数据库里与问题相关的数据集,包括:
26、利用langchain框架将得到的文本数据与提示词模板相结合,生成问题数据;
27、利用mmr(max-marginal-relevance)算法从药品的向量数据库中找到与问题最匹配的两条数据。
28、进一步地,所述利用langchain框架将得到的文本数据与提示词模板相结合,生成问题数据,包括:
29、利用langchain框架里面的prompttemplate类中的template参数创建一条问题模板;
30、通过prompttemplate类中的input_variables参数接收文本数据,并生成问题数据。
31、进一步地,所述利用mmr算法从药品的向量数据库中找到与问题最匹配的两条数据,包括:
32、采用langchain所提供的text-embedding-ada-002模型把问题编码成问题向量,并进行向量化处理;
33、利用langchain所提供的mmr算法从药品的向量数据库中找到与问题向量最匹配的两条数据。
34、进一步地,所述在将问题和数据集传给大语言模型后,获得用药建议,包括:
35、将得到的问题数据和两条相关数据一起传给大预言模型,生成用药建议,将解析结果通过可视化方式进行呈现。
36、本发明所采用的另一技术方案是:
37、一种基于大语言模型的人工智能用药辅助系统,包括:
38、生成药品向量数据库模块,用于获取药品数据库,对药品数据库中的药品数据进行分割,对分割获得的数据进行向量化处理并存入向量数据库;
39、图片数据采集与文字识别模块,用于获取药品产品的图像数据,根据图像数据进行文本识别,获得文本数据;
40、生成相关提问问题与数据集模块,用于结合文本数据和提示词模板,向大语言模型进行提问,并在提问的同时向大语言模型提供在向量数据库里与问题相关的数据集;
41、生成用药建议模块,用于在将问题和数据集传给大语言模型后,获得用药建议。
42、本发明所采用的另一技术方案是:
43、一种基于大语言模型的人工智能用药辅助装置,包括:
44、至少一个处理器;
45、至少一个存储器,用于存储至少一个程序;
46、当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现如上所述方法。
47、本发明所采用的另一技术方案是:
48、一种计算机可读存储介质,其中存储有处理器可执行的程序,所述处理器可执行的程序在由处理器执行时用于执行如上所述方法。
49、本发明的有益效果是:本发明利用langchain框架将私有数据库与大语言模型(如:openai)相结合,在私有数据库中找到与问题相匹配的数据,并与问题一起发送到大语言模型中,不仅可以使得用户得到更准确的个性化建议,还可以让用户得到更多的药品详情。
- 还没有人留言评论。精彩留言会获得点赞!