一种脂肪肝风险预测方法、装置、系统及存储介质与流程
本发明涉及脂肪肝风险检测,更具体地说,涉及一种脂肪肝风险预测方法、装置、系统及存储介质。
背景技术:
1、脂肪肝是一种肝脏疾病,其主要特征是肝细胞中脂肪(主要是甘油三酯)的异常积累。这种情况通常发生在肝脏处理脂肪时发生紊乱的情况下。
2、脂肪肝大致分为两类:(1)非酒精性脂肪肝病(nafld):不是由酒精消费引起的脂肪肝。它与肥胖、2型糖尿病和其他代谢综合征症状相关。(2)酒精性脂肪肝病(afld):由长期过量饮酒引起。
3、脂肪肝在早期通常没有症状。但随着病情的发展,可能出现以下症状:如疲劳、右上腹部不适或疼痛、体重下降或黄疸(在严重情况下),因此,在发病前进行及时的风险预测和检查,是避免脂肪肝病情进一步发展的关键。
4、当前,脂肪肝的风险预测方法主要包括以下几种:(1)临床评估:包括病史询问、体检、评估生活方式(如饮食、运动)和家族病史等,临床评估主要依赖于患者提供的信息,可能受到主观性和回忆偏差的影响;(2)血液生化指标:包括肝功能测试、胰岛素抵抗测试和血脂水平检测等,血液指标可能会受到多种因素的影响,且在脂肪肝早期可能表现正常。它们不能单独用于确诊脂肪肝。(3)影像学评估:如超声波、ct或mri扫描。其中,超声波对于轻度脂肪肝不够敏感,准确性受到操作者技术和患者体型的影响;而ct扫描则存在辐射风险,成本较高,对轻度脂肪肝的识别也有限。mri成本高昂,不适合作为常规筛查工具;(4)遗传和生物标志物研究:研究特定的遗传变异和血液生物标志物。研究领域较新,许多潜在的生物标志物和遗传因素还没有被充分验证或普及应用,且早期脂肪肝部分生物标志物无法体现;(5)生活方式评估:分析饮食习惯、运动水平等。这种方式受到个体报告的准确性和诚实性的影响,可能不够客观。
5、总之,尽管有多种方法可用于预测脂肪肝的风险,但每种方法都有其局限性,例如影像学评估存在的检测成本较高,生物标志物测量的准确性和复杂性可能存在问题,预测准确性不高、无法提供个性化的风险评估等。
技术实现思路
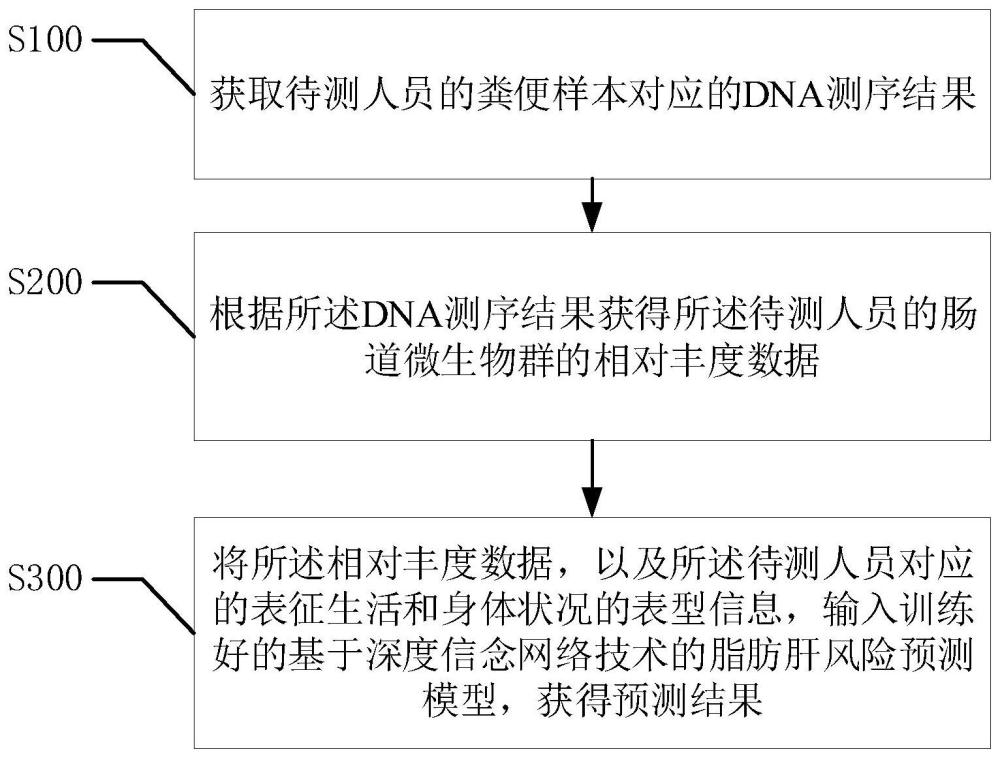
1、有鉴于此,针对于上述技术问题,本发明提供一种脂肪肝风险预测方法,包括:
2、获取待测人员的粪便样本对应的dna测序结果;
3、根据所述dna测序结果获得所述待测人员的肠道微生物群的相对丰度数据;
4、将所述相对丰度数据,以及所述待测人员对应的表征生活和身体状况的表型信息,输入训练好的基于深度信念网络技术的脂肪肝风险预测模型,获得预测结果。
5、优选地,所述获取受试者的粪便样本对应的dna测序结果之前,还包括:
6、获取实验群组中每个粪便样本对应的微生物dna测序数据;所述实验群组中包括健康受试者和脂肪肝受试者;
7、根据所述微生物dna测序数据,确定每个所述粪便样本对应的丰度信息;
8、获取所述实验群组中每个粪便样本对应的受试者的表型信息,并根据所述丰度信息和所述表型信息确定其中高重要性的特征作为特征集;
9、根据所述特征集,构建深度信念网络模型,并利用基于所述实验群组构建的测试集和训练集对所述深度信念网络模型进行训练,得到训练好的所述脂肪肝风险预测模型。
10、优选地,所述根据所述丰度信息和所述表型信息确定其中高重要性的特征作为特征集,包括:
11、将所述表型信息和所述丰度信息合并,得到合并训练数据;
12、根据所述合并训练数据构建决策树模型;
13、根据所述决策树模型计算得到每个特征对应的重要性分数;
14、对所述特征基于所述重要性分数进行排序,根据排序提取其中预设数量的高重要性分数的特征,构成所述特征集。
15、优选地,所述根据所述决策树模型计算得到每个特征对应的重要性分数,包括:
16、对所述决策树模型根据特征划分节点,计算所述决策树模型中的每个节点对应的初始不纯度,以及划分后的每个子节点的子节点不纯度;
17、对于所述特征的节点划分,根据所述初始不纯度和所述子节点不纯度,计算每个节点对应的不纯度减少;
18、对于每个特征对应的所有划分,计算其不纯度减少的加权平均值,将所述加权平均值作为每个所述特征对应的表征综合不纯度减少的所述重要性分数。
19、优选地,所述对于所述特征的节点划分,根据所述初始不纯度和所述子节点不纯度,计算每个节点对应的不纯度减少中,采用熵指标计算所述初始不纯度和所述子节点不纯度,计算公式为:
20、
21、其中,ientropy(t)代表节点t的熵值;i代表类别的索引,取值范围为1-c;c代表类别的数量,pi是节点上属于类别i的样本的比例。
22、优选地,所述每个节点对应的不纯度减少,通过计算所述初始不纯度与所述子节点不纯度的加权差异得到,所述子节点包括左子结点和右子节点,对应的设有左子节点不纯度和右子节点不纯度;
23、所述不纯度减少的计算公式为:
24、
25、其中,impurity decrease(t)代表节点t的不纯度减少;iinitia1(t)代表节点t的初始不纯度;n代表节点t上的总样本数;nleft和nright分别代表所述左子节点上的样本数和所述右子节点上的样本数;ileft(t)和iright(t)分别代表所述左子节点不纯度和所述右子节点不纯度。
26、优选地,所述根据所述特征集,构建深度信念网络模型,并利用基于所述实验群组构建的测试集和训练集对所述深度信念网络模型进行训练,得到训练好的所述脂肪肝风险预测模型,包括:
27、通过多个受限玻尔兹曼机的顺序堆叠,构建所述深度信念网络模型;
28、利用对比发散法对所述深度信念网络模型进行逐层预训练;
29、通过反向传播算法对经过逐层预训练的所述深度信念网络模型进行调整,得到训练好的所述脂肪肝风险预测模型。
30、优选地,所述利用对比发散法对所述深度信念网络模型进行逐层预训练,包括:
31、将特征集中的特征作为可见单元,初始化为训练数据的特征向量;
32、根据所述可见单元并行更新隐藏单元,再根据所述隐藏单元进行重建,并行更新所述可见单元;
33、利用重建后的所述可见单元并行更新所述隐藏单元,采用的计算方法均为:
34、p(hj=1|v)=σ(bj+∑iviwij);
35、其中,p(hj=1|v)代表在给定可见单元v时,所述隐藏单元hi被激活的概率;σ代表sigmoid函数;bj是隐藏单元hi的偏置项;vi代表可见单元中的第i个元素;wij代表连接所述可见单元vi和所述隐藏单元hi之间的权重;
36、所述根据所述隐藏单元进行重建,并行更新所述可见单元中,采用的计算方法为:
37、p(vi=1|h)=σ(ai+∑jhjwij);
38、其中,p(vi=1|h)代表在给定隐藏单元h时,可见单元vi被激活的概率;σ代表sigmoid函数;ai代表可见单元vi的偏置项;hj代表隐藏单元中的第j个元素;wij代表连接所述可见单元vi和所述隐藏单元hi之间的权重;
39、根据对比发散法,通过计算数据分布和重建分布的差异来更新权重。
40、优选地,所述根据对比发散法,通过计算数据分布和重建分布的差异来更新权重,采用的计算方法为:
41、δwij∝[(vihj)data-(vihj)reconstruction];
42、其中,δwij代表权重wij的差异值;(vihj)data代表数据分布值;(vihj)reconstruction代表重建分布值。
43、此外,为解决上述问题,本发明还提供一种脂肪肝风险预测装置,包括:
44、获取模块,用于获取待测人员的粪便样本对应的dna测序结果;
45、计算模块,用于根据所述dna测序结果获得所述待测人员的肠道微生物群的相对丰度数据;
46、预测模块,用于将所述相对丰度数据,以及所述待测人员对应的表征生活和身体状况的表型信息,输入训练好的基于深度信念网络技术的脂肪肝风险预测模型,获得预测结果。
47、本发明提供一种脂肪肝风险预测方法,包括:获取待测人员的粪便样本对应的dna测序结果;根据所述dna测序结果获得所述待测人员的肠道微生物群的相对丰度数据;将所述相对丰度数据,以及所述待测人员对应的表征生活和身体状况的表型信息,输入训练好的基于深度信念网络技术的脂肪肝风险预测模型,获得预测结果。本发明中,以人类肠道微生物群落作为研究对象,基于肠道微生物组和生物信息学思路,提供一种利用深度信念网络(deep belief network,dbn)预测脂肪肝风险的方法,明晰了脂肪肝患者和健康人之间的微生物差异,通过提前识别脂肪肝风险,个体可以采取适当的生活方式调整和治疗方法,从而降低患病风险,具有成本低、无创取样、稳定性高、附加值高等特点。
- 还没有人留言评论。精彩留言会获得点赞!