一种高效测定共聚反应单体竞聚率的神经网络辅助方法
本发明属于聚合物合成,具体涉及一种高效测定共聚反应单体竞聚率的神经网络辅助方法。
背景技术:
1、共聚反应能够在同种聚合物上引入不同单体的性能特点,在聚合物材料研发过程中有重要作用。通过改变共聚物的组成和序列结构,得到的共聚物可以在保持化学成分相同的情况下具有各异的性能。竞聚率指单体自增长的速率常数与交叉增长的速率常数的比值,可以由此计算出不同单体组成下共聚物的瞬时组成,以用于调控共聚物的组成和序列结构。因此,开发高效准确的竞聚率测量方法尤为重要。
2、竞聚率的传统测定方法有两种形式,分别是基于共聚物组成微分方程和积分方程的方法。前一种方法最早由mayo-lewis提出(j.am.chem.soc.,1944,66,1594),后经过fineman-ross和改良(j.polym.sci.,1950,5,259;j.polym.sci.,polym.chem.ed.,1975,13,2277),其方法主要是在保持共聚单体转化率低于10%的基础上,测定不同投料比下单体的转化率情况,进行曲线拟合得到竞聚率数值。但该方法存在测量难度与准确性上的问题,包括:1)单体转化率在10%以内时分析误差较大;2)低转化率下得到的共聚物产率低,提纯时会造成较大损失,为分析共聚物组成带来影响;3)当共聚单体的竞聚率相差较大时(例如,其中一个远大于1而另一个远小于1),保持所有单体在低转化率范围较为困难。对此,meyer和lowry在1965年提出了基于共聚物组成积分方程的方法(j.polym.sci.,parta:gen.pap.,1965,3,2843),通过测定同一组共聚反应下,单体转化率随反应进程的变化,以此数据拟合得到竞聚率,摆脱了转化率10%以内的限制。但该方法后续被证明其测量准确性受到反应投料比的显著影响(macromolecules,2019,52,2277)。因此,上述传统测量方法在测量效率与准确性上还存在一定的局限性。由于在共聚物研发过程中常常涉及多种共聚单体和反应条件的筛选,所需测量的竞聚率数量庞大,在传统的测定方法下会导致巨大的工作量和成本。
3、因此,发展高效、准确的竞聚率测定方法,能够为调控共聚物的组成和序列结构提供精确指导,同时通过快速建立竞聚率库加速共聚物材料的研发进程。
技术实现思路
1、有鉴于此,本发明的目的是针对现有技术中存在的问题,提供一种可适用于各类聚合体系的高效测定共聚反应单体竞聚率的神经网络辅助方法,助力于共聚物的组成和序列调控,以及共聚物材料的研发。
2、为了实现上述目的,本发明采用如下技术方案:
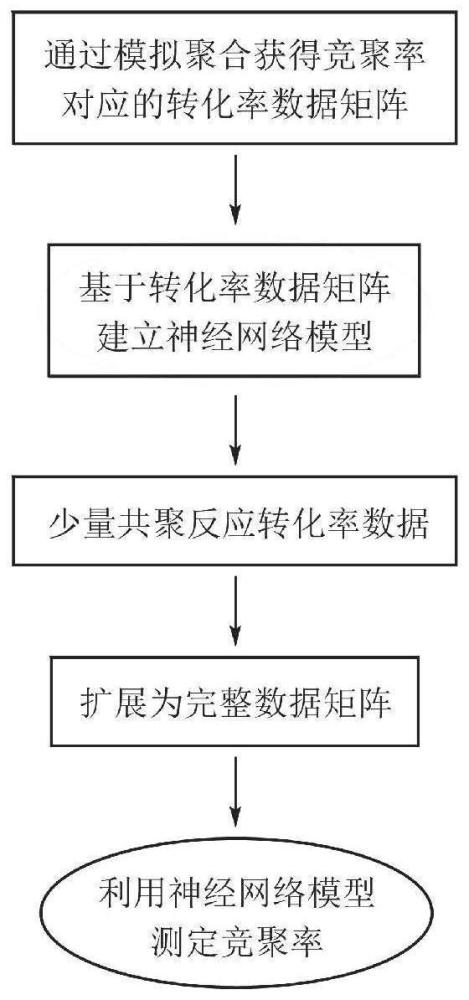
3、一种高效测定共聚反应单体竞聚率的神经网络辅助方法,包括以下步骤:
4、步骤1:通过monte carlo聚合动力学模拟收集不同竞聚率下单体转化率随投料比和总转化率的变化数据,整合成多维数据矩阵的形式,建立竞聚率与转化率数据矩阵一一对应的数据库;
5、步骤2:通过建立的数据库,构建神经网络模型,用于从共聚反应转化率数据预测竞聚率数值;
6、步骤3:对任意一组或多组共聚单体,进行多组任意投料比下的共聚反应,收集单体转化率数据;
7、步骤4:利用基于算法的数据矩阵补全方法,将少量的转化率数据扩展成完整数据矩阵,输入到构建的算法模型,输出竞聚率。
8、近些年来,机器学习和神经网络辅助的聚合物合成方法被不断报道。借助机器学习和神经网络技术在处理多变量分析问题和探索复杂关系上的优越性,这些方法能够高效分析已有数据,发现直觉之外的潜在规律,并已经实现了包括自动化活性自由基聚合(angew.chem.int.ed.,2019,58,3183)、聚酯自优化制备(macromolecules,2020,53,10847)和聚合逆分析平台(sci.china chem.,202164,1039)等工作。然而,现有的研究工作还局限于对聚合物分子量的优化,与竞聚率测定相关的研究还鲜有报道。本发明将神经网络算法引入到竞聚率的测定中,可将共聚反应数据与竞聚率形成对应关系,建立以共聚反应数据为输入端,竞聚率为输出端的关联模型,可以有效作用于竞聚率的高效、准确测定。
9、值得说明的是,本发明公开的神经网络辅助测定方案是将每组竞聚率数值所对应的共聚单体消耗情况整合成计算机语言可处理的高维数据矩阵,描述共聚单体转化率随单体投料比和总转化率的变化关系。通过建立聚合转化率数据矩阵与竞聚率之间的神经网络模型,实现由少量实验数据获得可靠的竞聚率测定结果。
10、进一步的,所述步骤1中的monte carlo聚合动力学模拟包括自由基共聚、阴离子共聚、阳离子共聚或开环共聚,共聚单体数量为2~4个,对应称为二元、三元、四元共聚。
11、更进一步的,考虑到不同聚合方法所需设定的参数不同,本发明所述monte carlo聚合动力学模拟的参数设定包括:
12、对于自由基共聚,设定固定不变的参数为引发剂分解速率常数kd、初级自由基与单体反应的速率常数ki、链增长速率常数kp、链终止速率常数kt、单体总浓度[m]、引发剂浓度[i];设定变化的参数为竞聚率r,单体投料比;或,
13、对于阴离子共聚,设定固定不变的参数为引发剂引发速率常数ki、链增长速率常数kp、单体总浓度[m]、引发剂浓度[i];设定变化的参数为竞聚率r,单体投料比,其中两种单体之间的竞聚率乘积固定为1,即r1r2=1;或,
14、对于阳离子共聚,设定固定不变的参数为引发剂引发速率常数ki、链增长速率常数kp、链转移速率常数ktr、单体总浓度[m]、引发剂浓度[i];设定变化的参数为竞聚率r,单体投料比,其中两种单体之间的竞聚率乘积固定为1,即r1r2=1;或,
15、对于开环共聚,设定固定不变的参数为引发剂引发速率常数ki、链增长速率常数kp、链终止速率常数kt、单体总浓度[m]、引发剂浓度[i];设定变化的参数为竞聚率r,单体投料比,其中两种单体之间的竞聚率乘积固定为1,即r1r2=1。
16、更进一步的,所述步骤1中的多维数据矩阵的形式包括:
17、对于二元共聚,第一维是投料比,第二维是单体总转化率,第三维是单体种类,矩阵中的数据为单体转化率;或,
18、对于三元共聚,第一维和第二维是其中两种单体的投料比,第三维是单体总转化率,第四维是单体种类,矩阵中的数据为单体转化率;或,
19、对于四元共聚,第一维至第三维是其中三种单体的投料比,第四维是单体总转化率,第五维是单体种类,矩阵中的数据为单体转化率。
20、更进一步的,所述步骤1中的竞聚率设定范围为r=0.01~100;其中,模拟二元共聚时,一组竞聚率包含2个r;模拟三元共聚时,一组竞聚率包含6个r;模拟四元共聚时,一组竞聚率包含12个r。
21、进一步的,步骤1中的投料比设定范围为fn=0~1,fn为任意共聚单体占单体混合物的摩尔分数;步骤1中的总转化率设定范围为0~1。
22、值得说明的是,步骤1中所述的monte carlo聚合动力学方法能够快速生成大量共聚反应数据,用于神经网络模型的训练。设定的多维数据矩阵的形式易于被计算机语言所处理,以便于神经网络模型进行特征提取。
23、进一步的,所述步骤2中神经网络模型包括:
24、卷积层:筛选的超参数包括输出通道数(channel)、卷积核大小(kernel)、步长大小(stride);
25、池化层:筛选的超参数包括池化函数(最大池化或平均池化)、过滤器大小;
26、激活层:筛选的激活函数包括sigmoid函数、tanh函数、softmax函数、relu函数等;
27、长短记忆递归(lstm)层:筛选的超参数包括层数(num_layers)、隐层维度(hidden_size)、是否双向(bifunctional)。
28、其中,所述神经网络模型的训练包括:
29、首先将数据集按80/20分割成训练集和验证集,训练集用于训练模型,通过反向传播算法更新网络参数,验证集用于评估神经网络的泛化能力,检验其过拟合程度。训练过程中,采用adam优化器优化网络模型参数,均方误差函数(mseloss)作为损失函数,批次大小(batch_size)和学习率(learning_rate)为算法中需要筛选的超参数,选取模型训练收敛后预测误差最小的作为最优模型。
30、值得说明的是,步骤2中所述神经网络的结构设置使模型具有更大的灵活性,其中lstm层的引入有助于捕捉单体转化率这一序列数据的特征。神经网络训练过程中的数据集分割和adam优化器能够筛选出合适的超参数,有助于提高模型的泛化能力和避免过拟合。
31、进一步的,所述步骤3中的共聚反应数据包括:投料比设定范围为fn=0~1,fn为各共聚单体占单体混合物的摩尔分数;总转化率设定范围为0~1;反应数据组数为3~20组。
32、进一步的,所述步骤4中的基于神经网络的数据矩阵补全方法包括:卷积神经网络、递归神经网络、生成对抗网络和变分自解码器。
33、更进一步的,所述数据矩阵补全方法的建立方法包括以下步骤:
34、步骤1:将通过monte carlo方法生成的数据矩阵进行随机遮盖,只留下数据矩阵中的少量位置的数据,留下的数据个数为3~100个,由此方法生成不完整的数据矩阵作为数据集,用于后续神经网络模型的训练;
35、步骤2:采用不同的数据矩阵补全算法,设定输入端为不完整的数据矩阵,输出端为完整的数据矩阵,其中每一个不完整的数据矩阵对应一个完整的原始数据矩阵,进行训练,将输出的数据矩阵与原始数据矩阵进行比对,计算二者之间的误差以评估模型的性能。最终根据误差表现筛选出最优的数据矩阵补全算法。
36、值得说明的是,步骤4中所述的数据矩阵补全方法能够用于现实情况下通过实验获得的少量数据转换成神经网络模型所需的完整数据矩阵,增强实验数据的可用性,以便于在神经网络模型中得到更精确的竞聚率预测值,减少获取数据时的实验成本。
37、相比于传统的竞聚率测定方法,本发明提出的神经网络辅助的竞聚率测定方法具有如下优点:
38、1.没有单体转化率的限制,能有效解决低转化率测定下的繁琐操作和测定误差,提高测定效率;
39、2.适用于任意投料比的聚合数据,摆脱传统方法竞聚率测定准确性受投料比影响的问题;
40、3.利用三元、四元共聚数据进行测定,可以一次性获得多组竞聚率数据,能用于高效建立单体竞聚率库。
- 还没有人留言评论。精彩留言会获得点赞!