一种脓毒症多器官功能障碍预测模型及其训练方法
本发明属于脓毒症多器官功能障碍预测模型领域,更具体地,涉及一种脓毒症多器官功能障碍预测模型及其训练方法。
背景技术:
1、脓毒症是感染导致宿主全身反应失调的器官功能障碍症候群。脓毒症主要引起的器官功能障碍包括:休克、呼吸功能障碍、肾功能障碍、肝功能障碍、凝血功能障碍等,严重的会导致死亡。及时的诊断和治疗对于脓毒症至关重要,早期发现和治疗不但可以减少患者住院时间和重症监护的需求,降低医疗成本,还能显著降低患者的死亡风险。
2、患者进入icu的最初5天内,病情的快速变化尤为关键。在这个时间窗口内基于临床数据进行早期预测诊断,对于医疗研究具有重要价值。利用深度学习技术,通过分析患者的临床数据,构建脓毒症多器官功能障碍预测模型,可以为医生在评估病情和制定治疗策略时提供有力的决策辅助。
3、然而,现有的脓毒症多器官功能障碍预测模型均存在一些不可忽略的缺陷:
4、第一、由于医疗信息的隐私性问题,脓毒症相关的数据集往往有限,且数据质量参差不齐(例如数据可能存在缺失值和异常值,或者存在数据稀缺),这会导致样本量不足以支持复杂模型的训练,进而导致训练得到的脓毒症多器官功能障碍预测模型在源域数据上表现良好,但在目标域上泛化能力较差;
5、第二、由于脓毒症的发展是一个复杂的动态变化过程,需要对时间序列数据进行有效处理,但现有的脓毒症多器官功能障碍预测模型无法充分捕捉这种动态性,因此会导致模型在脓毒症早期预测方面性能不佳;
6、第三、由于现有的脓毒症多器官功能障碍预测模型往往在特定的数据集上表现良好,但在不同的医疗环境或人群中可能难以实现同样的预测精度,因此会导致模型的泛化性能不佳,限制其在实际临床应用中的适用性。
技术实现思路
1、针对现有技术的以上缺陷或改进需求,本发明提供了一种脓毒症多器官功能障碍预测模型及其训练方法,其目的在于,解决现有脓毒症多器官功能障碍预测模型由于医疗信息的隐私性问题,脓毒症相关的数据集有限、且数据质量参差不齐,导致样本量不足以支持复杂模型的训练,进而导致训练得到的脓毒症多器官功能障碍预测模型在源域数据上表现良好、但在目标域上泛化能力较差的技术问题;以及无法充分捕捉脓毒症发展的复杂动态变化过程,导致模型在脓毒症早期预测方面性能不佳的技术问题;以及在不同的医疗环境或人群中难以实现一致的预测精度,导致模型的泛化性能不佳的技术问题。
2、为实现上述目的,按照本发明的一个方面,提供了一种脓毒症多器官功能障碍预测模型,其包括依次连接的双向长短时记忆网络bi-lstm、矩阵拼接模块、两个多层感知器mlp以及softmax函数层,
3、对于bi-lstm而言,其用于处理时序数据,其输入为当前时刻t时的输入xt,输出为当前时刻t时的前向隐藏状态和后向隐藏状态合并后的输出
4、bi-lstm包括前向lstm单元和后向lstm单元;
5、前向lstm单元根据当前时刻t时的输入xt和上一时刻t-1时隐藏层的隐藏状态来获取其t时刻的前向隐藏状态,这可以通过以下公式表示:
6、
7、其中,lstmfw是前向lstm的函数。
8、后向lstm单元根据当前时刻t时的输入xt和下一时刻t+1时隐藏层的隐藏状态来获取其t时刻的反向隐藏状态,这可以通过以下公式表示:
9、
10、其中,lstmbw是后向lstm的函数。
11、当前时刻t时刻的前向隐藏状态和反向隐藏状态合并成为当前时刻t时bi-lstm的输出其中[;]表示将两个隐藏状态连接起来;
12、第一mlp包括一个或多个隐藏层,第一mlp的输入为数据xmlp,输出为第一mlp中最后一个隐藏层输出hmlp,第一mlp的公式可以表示为:
13、hmlp=activation(wmlp·xmlp+bmlp)
14、其中activation为激活函数,wmlp为第一mlp的权重,bmlp为第一mlp的偏置;
15、对于矩阵拼接模块而言,其输入为当前时刻t时的前向lstm和后向lstm合并后的输出以及第一个mlp中最后一个隐藏层的输出hmlp,输出为当前时刻t时合并后的特征向量
16、对于第二mlp而言,其包括一个或多个隐藏层,第二mlp的输入为当前时刻t时合并后的特征向量输出为第二mlp中最后一个隐藏层输出hfinal。
17、第二mlp的公式可以表示为:
18、
19、其中activation为激活函数,wfinal表示第二mlp的权重,bfinal表示第二mlp的偏置,二者的取值在模型训练过程中不断变化。
20、对于softmax层而言,其输入为第二mlp中的最后一个隐藏层的输出logits,输出为概率分布
21、优选地,bi-lstm中的前向/后向lstm单元包括以下三个阶段:
22、第一部分特征选择记忆阶段,其输入为当前时刻t时的数据xt,输出为当前时刻t时的遗忘门向量ft;
23、具体而言,首先,遗忘门将lstm在上一时刻t-1时隐藏层的输出ht-1和当前时刻t时的输入xt连接,然后,使用激活函数sigmoid对连接后的结果进行处理,以获取一个在[0,1]之间的、当前时刻t时的遗忘门向量ft,该遗忘门向量决定了让上一时刻t-1时的所学信息ct-1舍弃或者保留;其中,0表示全部舍弃,1表示全部保留,
24、第一部分特征选择记忆阶段具体是采用如下公式:
25、ft=σ(wf·[ht-1,xt]+bf)
26、其中wf为权重,bf为偏置,二者的取值在模型训练过程中不断变化,ht-1是上一时刻t-1时隐藏层的输出。
27、第二部分特征更新阶段,其输入为当前时刻t时的输入门向量it,输出为当前时刻t时的所学信息ct;
28、具体而言,首先是输入门通过sigmoid函数获取得到输入的当前时刻t时的输入门向量it,然后,利用tanh函数对该当前时刻t时的输入门向量it进行处理,以获取当前时刻t时的新候选信息c′t,最后,根据当前时刻t时的新候选信息c′t、当前时刻t时的遗忘门向量ft、上一时刻t-1时的所学信息ct-1、以及当前时刻t时的输入门向量it获取当前时刻t时的所学信息ct;
29、第二部分特征更新阶段具体是采用如下公式:
30、it=σ(wg·[ht-1,xt]+bg)
31、c′t=tanh(wi·[ht-1,xt]+bi)
32、ct=ft*ct-1+c′t*it
33、其中wg和wi为权重,bg和bi为偏置,它们的取值在模型训练过程中不断变化。
34、第三部分特征输出阶段,其输入为上一时刻t-1时隐藏层的输出ht-1和当前时刻t时的数据xt,输出为当前时刻t时隐藏层的输出ht,即lstm的输出hlstm。
35、具体而言,首先,根据上一时刻t-1时隐藏层的输出ht-1与当前时刻t时的数据xt,并通过sigmoid函数获取当前时刻t时的输出门向量ot,然后,使用tanh函数将当前时刻t时的信息值ct缩放为[-1,1]之间的向量,最后,将缩放处理后的向量与当前时刻t时的输出门向量ot相乘,以最终得到当前时刻t时隐藏层的输出ht;
36、第三部分特征输出阶段具体是采用以下公式:
37、ot=σ(wo[ht-1,xt]+bo)
38、ht=ot*tanh(ct)
39、其中wo为权重,bo为偏置,二者的取值在模型训练过程中不断变化。
40、优选地,对于第一mlp而言,其输入层l=0,输出层l=l,其中l表示第一mlp中层的总数,l表示第一mlp中层的序号,且有l∈[1,l]。
41、当l=0时,第一mlp的输入即输入层的数据。
42、当l=l时,第一mlp中第l层的输出即第一mlp中最后一个隐藏层的输出。
43、对于第l层(其中l≠0和l,即中间的隐藏层或输出层)而言,其输入为第l-1个隐藏层的输出输出为第l个隐藏层的输出可以表示为:
44、
45、其中activation为激活函数,为第l个隐藏层的输出,为第l个隐藏层的输入,即第l-1个隐藏层的输出,为第l个隐藏层的权重,为第l个隐藏层的偏置,二者的取值在模型训练过程中不断变化。
46、优选地,对于第二mlp而言,其输入层j=0,输出层j=j,其中j表示第二mlp中层的总数,j表示第二mlp中层的序号,且有j∈[1,j]。
47、当j=0时,第二mlp的输入即合并后的特征向量。
48、当j=j-1时,第二mlp中第l层的输出即第二mlp中倒数第二个隐藏层输出。
49、对于第j层(其中j≠0和j,即中间的隐藏层)而言,其输入为第j-1个隐藏层的输出输出为第j个隐藏层的输出可以表示为:
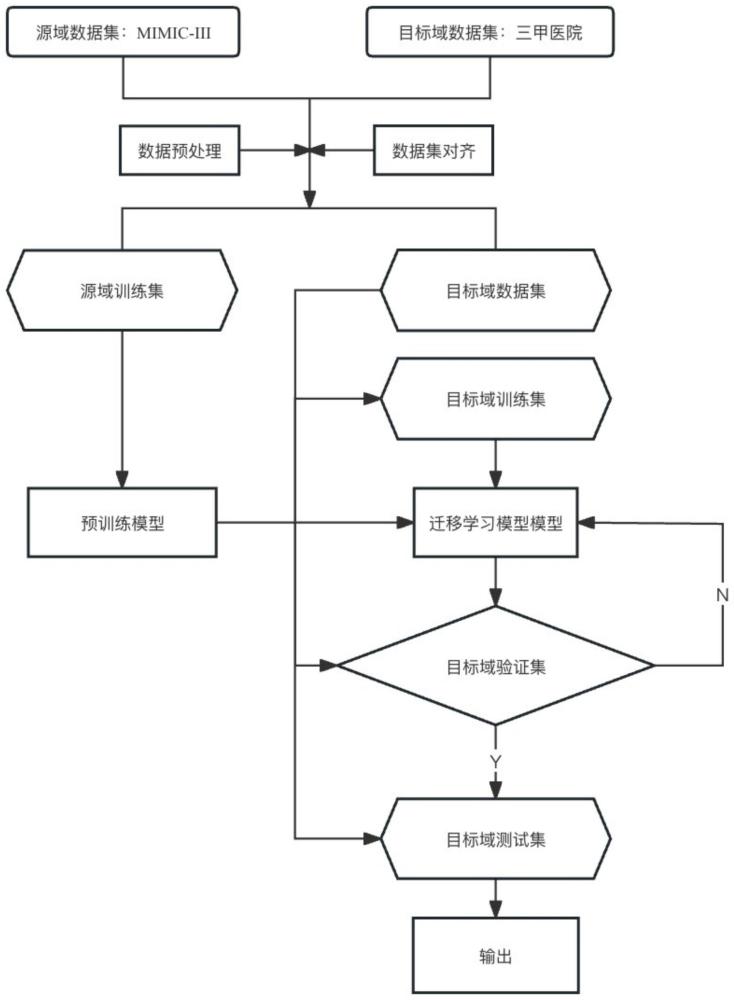
50、
51、其中activation为激活函数,为第j个隐藏层的输出,为第j个隐藏层的输入(即第j-1个隐藏层的输出),为第j个隐藏层的权重,为第j个隐藏层的偏置,二者的取值在模型训练过程中不断变化。
52、特征向量hfinal,即第二mlp中倒数第二个隐藏层输出被输入第二mlp中的最后一个隐藏层后,即得到第二mlp中的最后一个隐藏层的输出logits,也就是j=j时的输出具体公式如下:
53、logits=woutput·hfinal+boutput
54、其中woutput表示线性层的权重,boutput表示线性层的偏置,二者的取值在模型训练过程中不断变化。
55、优选地,第二mlp中的最后一个隐藏层的输出logits输入softmax层,以得到概率分布具体公式如下:
56、
57、其中表示在给定当前时刻t时合并后的特征向量的条件下每个类别的预测概率。
58、按照本发明的另一方面,提供了一种脓毒症多器官功能障碍预测模型的训练方法,包括以下步骤:
59、(1)获取mimic-iii数据库和医院数据库,根据第三版的脓毒症定义识别mimic-iii数据库和医院数据库中对应的脓毒症患者,并对获取的所有脓毒症患者进行筛选,筛选后的所有脓毒症患者对应的mimic-iii数据和医院数据分别构成mimic-iii脓毒症数据集和医院脓毒症数据集。
60、(2)对步骤(1)得到的mimic-iii脓毒症数据集和医院脓毒症数据集进行预处理,以分别获取预处理后的mimic-iii脓毒症数据集和医院脓毒症数据集分别作为源域数据集和目标域数据集;
61、(3)按照8:1:1的比例将步骤(2)得到的目标域数据集划分为目标域训练集、目标域验证集和目标域测试集。
62、(4)采用滑动窗口的方式将步骤(2)得到的源域数据集中所有当前时刻t时的时序数据构成的当前时刻t时的时序数据序列集合st={xt1,xt2,...,xtz}输入bi-lstm,以获取当前时刻t时bi-lstm的输出其中当前时刻t时的时序数据序列集合s中的第z个时序数据序列xtz=[xtz1,xtz2,...,xtzm],z∈[1,t],m∈[1,m],m表示每个时序数据序列中的时序数据总数,xtzm表示当前时刻t时的时序数据序列集合s中第z个时序数据序列中的第m个时序数据,z表示当前时刻t时的时序数据序列集合s中的时序数据序列总数。
63、(5)将步骤(2)得到的源域数据集中的非时序数据序列xc=[x1,x2,...,xn]输入第一mlp,以获取输出即第一mlp中最后一个隐藏层的输出,其中n∈[1,n],n表示源域数据集中非时序数据的总个数,xn表示非时序数据序列中的第n个时序数据。
64、(6)将步骤(4)得到的当前时刻t时bi-lstm的输出与步骤(5)得到的输出进行合并,以得到当前时刻t时合并后的输出
65、(7)将步骤(4)得到的当前时刻t时合并后的输出先后输入第二mlp和softmax层,以得到下一时刻t+1时的模型预测标签yt+1。
66、(8)根据步骤(7)获取的下一时刻t+1时的模型预测标签yt+1和下一时刻t+1时的真实标签计算交叉熵损失函数。
67、(9)根据步骤(8)得到的交叉熵损失函数,并利用反向传播方法对脓毒症多器官功能障碍预测模型进行迭代训练,直到该脓毒症多器官功能障碍预测模型收敛为止,从而获得初步训练好的脓毒症多器官功能障碍预测模型。
68、(10)使用步骤(3)获取的目标域测试集对步骤(9)初步训练好的脓毒症多器官功能障碍预测模型进行验证,直到获取的检测精度达到最优为止,从而获取预训练好的脓毒症多器官功能障碍预测模型。
69、(11)运用迁移学习策略将步骤(3)得到的目标域训练集输入到步骤(10)预训练好的脓毒症多器官功能障碍预测模型中,以得到最终训练好的脓毒症多器官功能障碍预测模型。
70、优选地,步骤(2)包括以下子步骤:
71、(2-1)获取步骤(1)得到的mimic-iii脓毒症数据集和医院脓毒症数据集中的所有时序数据和非时序数据,针对同一类型的所有时序数据而言,按照其生成时间的先后顺序对所有时序数据进行排序,并对排序后的所有时序数据按照“名称+时间”的方式进行统一标记,从而得到标记时序数据后的mimic-iii脓毒症数据集和医院脓毒症数据集;
72、(2-2)对子步骤(2-1)标记时序数据后的mimic-iii脓毒症数据集和医院脓毒症数据集分别进行数据清洗,即删除mimic-iii脓毒症数据集和医院脓毒症数据集中缺失值大于50%的数据,以得到数据清洗后的mimic-iii脓毒症数据集和医院脓毒症数据集;
73、(2-3)将子步骤(2-2)数据清洗后的mimic-iii脓毒症数据集和医院脓毒症数据集分别进行缺失值填补,以得到缺失值填补后的mimic-iii脓毒症数据集和医院脓毒症数据集;
74、(2-4)将子步骤(2-3)填补缺失值后的mimic-iii脓毒症数据集和医院脓毒症数据集中的所有数值型数据分别进行z-score标准化处理,以获取标准化处理后的mimic-iii脓毒症数据集和医院脓毒症数据集。
75、(2-5)对子步骤(2-4)得到的标准化处理后的mimic-iii脓毒症数据集和医院脓毒症数据集分别进行对齐处理,以获取更新后的mimic-iii脓毒症数据集和医院脓毒症数据集,二者分别作为最终的源域数据集和目标域数据集。
76、具体而言,本步骤是将mimic-iii脓毒症数据集中所有未出现在医院脓毒症数据集中的数据全部删除,并将医院脓毒症数据集中所有未出现在mimic-iii脓毒症数据集中的数据全部删除,将更新后的mimic-iii脓毒症数据集作为源域数据集,将更新后的医院脓毒症数据集作为目标域数据集。
77、优选地,步骤(4)具体为:
78、首先,将当前时刻t时的时序数据序列集合s中的所有时序数据依次输入到bi-lstm的两个方向上;
79、然后,针对当前时刻t时的时序数据序列集合s中第t个时序数据序列xtz而言,在前向lstm部分,lstm正向处理当前时刻t时的时序数据序列集合s中第t个时序数据序列xtz,并结合其上一时刻t-1时正向传播fw下的隐藏状态通过多个门控机制共同作用,以得到当前时刻t时正向传播fw下的隐藏状态以及在当前时刻t时正向传播fw下所学习到的信息
80、随后,针对当前时刻t时的时序数据序列集合s中第t个时序数据序列xtz而言,在后向lstm部分,lstm反向处理当前时刻t时的时序数据序列集合s中第t个时序数据序列xtz,并结合其下一时刻t+1时反向传播bw下的隐藏状态通过多个门控机制共同作用,以得到当前时刻t时反向传播bw下的隐藏状态以及在当前时刻t时反向传播bw下所学习到的信息
81、最后,将当前时刻t时产生的正向和反向隐藏状态合并成当前时刻t时最终bi-lstm的输出
82、优选地,步骤(7)具体为:
83、首先将当前时刻t时合并后的特征向量输入第二mlp,以获取第二mlp中倒数第二个隐藏层的输出即特征向量hfinal。
84、本过程的公式可以表示为:
85、
86、其中activation为激活函数,wfinal表示第二mlp的权重,bfinal表示第二mlp的偏置,二者的取值在模型训练过程中不断变化。
87、随后,将获取的特征向量hfinal,即第二mlp中倒数第二个隐藏层的输出输入线性层,即第二mlp中的最后一个隐藏层,以得到第二mlp中的最后一个隐藏层的输出logits,即j=j时的输出具体公式如下:
88、logits=woutput·hfinal+boutput
89、其中woutput表示线性层的权重,boutput表示线性层的偏置,二者的取值在模型训练过程中不断变化。
90、最后,将第二mlp中的最后一个隐藏层的输出logits输入到softmax层,以得到概率分布即下一时刻t+1时的模型预测标签yt+1,具体公式如下:
91、
92、其中表示在给定当前时刻t时合并后的特征向量的条件下每个类别的预测概率;
93、步骤(8)中的交叉熵损失的计算公式为:
94、
95、其中,k为标签类别的总数,表示真实标签中第i个类别的真实概率,即真实概率分布中的第i个元素,yt+1(i)表示模型预测标签yt+1中第i个类别的预测概率,即预测概率分布中的第i个元素。
96、优选地,步骤(11)具体包括以下子步骤:
97、(11-1)对步骤(10)预训练好的脓毒症多器官功能障碍预测模型进行参数冻结,以获取参数冻结后的脓毒症多器官功能障碍预测模型;
98、(11-2)使用步骤(3)得到的目标域训练集对子步骤(11-1)参数冻结后的脓毒症多器官功能障碍预测模型进行微调,以得到微调后的脓毒症多器官功能障碍预测模型;
99、(11-3)使用步骤(3)得到的目标域验证集对子步骤(11-2)得到的微调后的脓毒症多器官功能障碍预测模型进行验证,以得到验证有效的脓毒症多器官功能障碍预测模型;
100、(11-4)使用步骤(3)得到的目标域的测试集对子步骤(11-3)验证有效的脓毒症多器官功能障碍预测模型进行最终评估,以得到最终训练好的脓毒症多器官功能障碍预测模型。
101、总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:
102、1、由于本发明使用步骤(1)到步骤(3),其通过构建新的医院脓毒症临床数据集,克服现有脓毒症数据集数量有限和质量参差不齐,导致样本量不足以支持复杂模型的训练的问题,这不仅增加脓毒症相关数据的丰富性,填补原有数据集的不足,而且对数据进行质量控制和清洗,处理缺失值、异常值等问题,提高数据的质量和可信度,这使得训练得到的脓毒症多器官功能障碍预测模型更具可信度和稳定性;
103、2、由于本发明使用步骤(4)到步骤(11),训练出一种脓毒症多器官功能障碍预测模型,其通过利用bi-lstm,模型可以处理复杂的时间序列数据,不仅提高了对脓毒症多器官功能障碍的早期识别能力,还能有效捕捉脓毒症的动态发展过程;
104、3、由于本发明使用步骤(4)到步骤(11),其通过在源域数据集上进行预训练,然后在医院数据集上应用迁移学习的方法,提供一个基于深度学习和迁移学习的高效、准确的预测系统,不仅减少模型对特定数据集的过度依赖,增强模型在不同医疗环境和人群中的泛化能力和可扩展性。
- 还没有人留言评论。精彩留言会获得点赞!