基于大语言模型的胃癌健康宣教和患病风险预测系统和方法
本发明属于医疗数据处理技术以及大语言模型的人工智能,具体地说,是一种基于大语言模型的胃癌健康宣教和患病风险预测系统和方法。
背景技术:
1、胃癌是一种严重的消化道恶性肿瘤,其发病率和死亡率在全球范围内都较高,在所有癌症疾病中排第三。胃癌的发病机制复杂,与环境、饮食、生活习惯、遗传等多种因素有关。早期诊断和治疗对于提高胃癌患者治愈率和生存率具有重要意义:早期胃癌患者5年生存率可达到90%以上,而晚期患者的5年生存率仅有10%到20%。此外,胃癌在早期阶段往往症状不明显,如轻微消化不良、食欲不振或上腹部不适,容易被患者和医生忽视,导致疾病在无明显症状的情况下进展到晚期。。
2、在此背景下,传统的胃癌健康宣讲和诊断方法(内镜、手术、病理组织提取)有以下问题:
3、1、传统诊断方法具有侵入性,且成本高、时间长,通常不能及时对患者进行确诊;
4、2、面对面的胃癌相关咨询耗费大量医生的时间和资源;
5、3、传统的胃癌健康宣教多以纸质材料和视频为主,没有办法进行交互,患者体验感较差,健康宣教的效果不佳。
6、大语言模型的发展历程是自然语言处理(nlp)技术进步的重要组成部分。随着计算能力的显著提升和大量数据的可用性,神经网络模型尤其是深度学习技术在自然语言处理领域取得了突飞猛进的发展。特别是在过去十年中,出现了如bert、gpt等一系列具有里程碑意义的大型语言模型,这些模型通过大规模数据集的预训练,学会了理解和生成自然语言,极大地推动了机器理解和生成人类语言的能力。
7、在医疗领域,大语言模型展现出了巨大的潜力和价值。例如,通过分析病历记录和医疗文献,这些模型可以帮助医生更快地诊断疾病。在实际应用中,模型能够理解患者的症状描述,综合医生的治疗建议,并提供个性化的辅助诊断信息。这不仅可以减轻医生的工作负担,提高工作效率,还可以帮助医生和患者做出更加精准的决策。一些研究也表明,大语言模型可以辅助在复杂病症(如癌症)的诊断过程中,提供更为全面和深入的见解。
技术实现思路
1、鉴于上述,本发明的目的是提出了一种基于大语言模型的胃癌健康宣教和患病风险预测系统和方法,旨在实现在线可交互地,快速准确地以及个性化的胃癌健康宣教和患病风险预测。
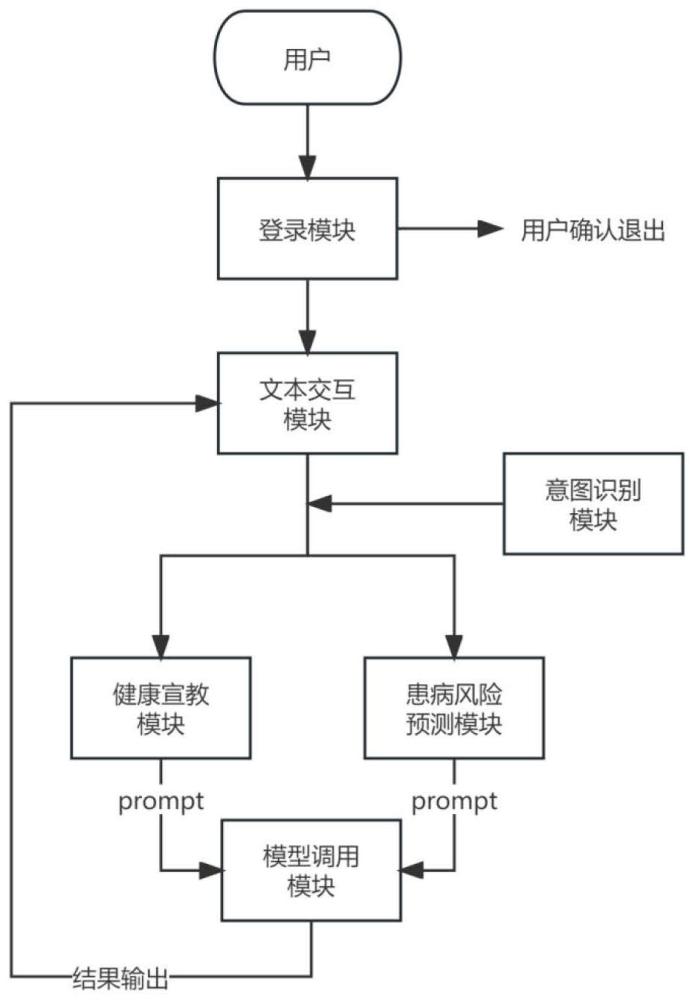
2、为实现上述发明目的,一种基于大语言模型的胃癌健康宣教和患病风险预测系统,包括:
3、登录模块,用于胃癌健康宣教和患病风险预测系统的登录和登出;
4、文本交互模块,用于与用户进行文本交互,包括输入的咨询文本和输出的健康宣教文本和胃癌患病风险预测结果文本;
5、意图识别模块,其内置自然语言模型,用于识别输入的咨询文本的意图,并根据意图调用胃癌健康宣教模块或者胃癌患病风险预测模块;
6、胃癌健康宣教模块,用于启用胃癌健康宣教知识库以及胃癌健康宣教的提示模版,根据咨询文本包括的胃癌相关问题进行胃癌健康宣教知识库的第一匹配和利用第一匹配结果并基于提示模版生成宣教提示,将宣教提示传递给模型调用模块;
7、胃癌患病风险预测模块,用于依据意图判断处于患病风险情景时,收集用户问卷信息,启用胃癌患病诊断相关知识库和胃癌患病风险预测的提示模版,根据用户问卷信息进行胃癌患病诊断相关知识库的第二匹配和利用第二匹配结果并基于提示模版生成预测提示,将预测提示传递给模型调用模块;
8、模型调用模块,其内置大语言模型,用于启用胃癌健康宣教或患病风险预测的大语言模型,基于宣教提示生成胃癌健康宣教文本,或基于预测提示生成胃癌患病风险预测结果文本,并传递到文本交互模块。
9、优选地,用于意图识别的自然语言模型采用bert模型,并经过训练得到。
10、优选地,所述意图识别模块中,基于自然语言模型识别输入的咨询文本的意图,包括:
11、基于自然语言模型判断输入的咨询文本涉及问询胃癌相关资讯时,则认为意图是与胃癌健康宣教相关的,则会调用胃癌健康宣教模块;
12、基于自然语言模型判断输入的咨询文本以进行胃癌患病风险预测为意图,则会调用胃癌患病风险预测模块。
13、优选地,所述意图识别模块,还包括:
14、基于自然语言模型判断输入的咨询文本的意图不是胃癌健康宣教相关的,也不是胃癌患病风险预测相关的,则会触发文本交互模块,通过文本交互处模块引导用户输入符合意图的咨询文本或输出建议咨询专业医生。
15、优选地,所述胃癌健康宣教知识库和胃癌患病诊断相关知识库是存在于本地端的向量数据库,用于存储被向量化的知识文本信息。
16、优选地,所述胃癌健康宣教模块中,基于根据咨询文本包括的胃癌相关问题进行胃癌健康宣教知识库的第一匹配时,通过计算胃癌相关问题与胃癌健康宣教知识库中知识文本的相似度,筛选高相似度的知识文本作为第一匹配结果;
17、所述胃癌患病风险预测模块中,根据用户问卷信息进行胃癌患病诊断相关知识库的第二匹配时,通过计算用户问卷信息胃癌患病诊断相关知识库中知识文本的相似度,筛选高相似度的知识文本作为第二匹配结果。
18、优选地,所述用户问卷信息通过大语言模型经过问答对话方式收集,包括地区、年龄、性别、民族、疾病史、家族史、胃肠症状、饮食时间、盐摄入情况、糖分摄入情况、油脂摄入情况、是否进食辛辣食物、是否进食烫的食物、水果摄入情况、蔬菜摄入情况、豆制品摄入情况、牛奶摄入情况、饮酒情况共18项数据。
19、优选地,所述大语言模型在被应用之前经过参数优化,具体过程为:
20、采用基于大语言模型的开源项目langchain进行环境的部署,该开源项目langchain能够动态接入各种场景和模态的大语言模型,采用开源的中文医疗对话大语言模型ming作为底座,使用预处理后的文本数据和问答对话数据对ming进行大语言模型训练;
21、训练时采用finetuning和lora相结合的方法。
22、实施例还提供了一种上述胃癌健康宣教和患病风险预测系统的构建方法,包括以下步骤:
23、数据采集:获取企业历史至今各系统的胃癌相关到文本数据,包括医患对话数据,诊断和治疗信息数据,患者个人信息数据,以及医学领域涉及胃癌的医学刊物,指南和文献数据;
24、数据预处理:对文本数据进行清洗、规范化处理;请胃癌领域专家和医生以人工的手段对文本数据进行标注和校对;请胃癌领域专家和医生根据olga/olgim评判原则对病例人群进行分级,共分为三级,分别是:低患病风险组、中患病风险组、高患病风险组,作为标注数据;请胃癌领域专家和医生设计胃癌患病相关风险因素的调查问卷一用于收集用户问卷信息;使用chatgpt对现有的文本数据进行模拟问答对话的构造,用于创建训练大语言模型用的问答对话,并得到问答对话数据;
25、模型训练:采用基于大语言模型的开源项目langchain进行环境的部署,该开源项目langchain能够动态接入各种场景和模态的大语言模型,采用开源的中文医疗对话大语言模型ming作为底座,使用预处理后的文本数据和问答对话数据对ming进行大语言模型训练,训练时采用finetuning和lora相结合的方法;采用已公开的bert模型,将预处理后的文本数据作为训练数据,进行意图识别的bert模型的训练。
26、业务场景搭建:根据不同的胃癌健康宣教任务和胃癌患病风险预测任务场景,构建胃癌健康宣教知识库和胃癌患病诊断相关知识库,设计胃癌健康宣教的提示模版和胃癌患病风险预测的提示模版,编写不同任务场景的接口代码,并通过结合训练后的大语言模型能够实现符合场景的交互;
27、业务场景调整优化:请胃癌领域的专家和医生对交互结果进行观察和判断,如果存在交互存在问题,则通过模型训练步骤和场景内的知识库以及提示模版对大语言模型进行参数的微调。
28、优选地,场景调整优化采用了few-shot和prompt-tuning方法。
29、与传统方法相比,本发明的有益效果至少包括:
30、1、高效性与资源节约:使用该系统后患者不需要和医生面对面进行咨询,可以减少对医生时间的依赖,提供自动化、智能化的健康宣教和用药推荐,从而显著提高医疗服务的效率并节约宝贵的医疗资源。
31、2、交互性与用户体验:与传统的纸质材料和视频相比,该系统可以进行实时交互,提供立即的回复和建议,极大地提高了患者的体验感。这种互动性可能会增加患者遵循健康建议的可能性,从而提高健康宣教的效果。
32、3、准确性与高灵敏度:该系统在检出高危胃癌患病风险人群方面具有高灵敏度,能够保证病人不被漏诊,且结果准确。
33、4、灵活与快速:系统内的大语言模型可以对患者的信息进行收集和初步分析,在未来可以加入新的模块来利用这些基本信息做其他诊断。且本系统能够快速进行患病风险的预测,为病人的早期治疗提供更大的可能性。
34、5、普及性与质量保证:在医疗资源薄弱的地区,该系统可以作为一个质量稳定、安全和准确的健康宣教和胃癌患病风险筛查。这确保了即使在资源有限的地区,患者也可以获得高标准的风险筛查。
- 还没有人留言评论。精彩留言会获得点赞!