基于参数共享和知识蒸馏的分子属性预测模型的压缩系统和方法与流程
本发明涉及人工智能和化学信息学领域,尤其涉及基于参数共享和知识蒸馏的分子属性预测模型的压缩系统和方法。
背景技术:
1、transformer模型在化学信息学领域已成为一种高效的分子属性预测方法。不同于传统的机器学习模型,transformer模型通过自监督学习作为预训练步骤。这种自监督学习的数据基础是大规模的未标记化学序列或图数据集。经过自监督学习后,transformer模型可以通过微调来执行下游任务。更具体地说,模型可以在预训练过程中学习基本的分子结构知识(如化学式、键和电荷)。然后,在微调过程中将上述知识传递给下游任务,从而克服特定任务中的数据稀缺问题。因此,通过上述预训练和微调的策略,transformer模型能够实现分析属性预测任务的准确度提升。
2、尽管transformer模型在分子属性预测方面性能出色,但由于模型包含数千万以上的参数,transformer模型在训练和推理过程中的计算成本很高。例如,最近提出的预测模型需要至少四个高性能图形处理单元(gpu)进行数天的预训练。此外,在微调过程中的推理时间比其他模型要长很多。除了耗时,硬件运行产生的热量也不利于环境友好型社会的构建。因此,庞大的参数和较高的硬件成本,可能会阻碍transformer模型在分子性质预测领域的实际应用。
3、上述对背景技术的陈述仅是为了方便对本发明技术方案(使用的技术手段、解决的技术问题以及产生的技术效果等方面)的深入理解,而不应当被视为承认或以任何形式暗示该消息构成已为本领域技术人员所公知的现有技术。
技术实现思路
1、针对现有技术中存在的缺陷,本发明提出了一种新颖的分子属性预测transformer的模型压缩方法,其基于参数共享和知识蒸馏技术,可以分别在预训练和微调过程中减少模型参数,同时保持分子属性预测的准确度。
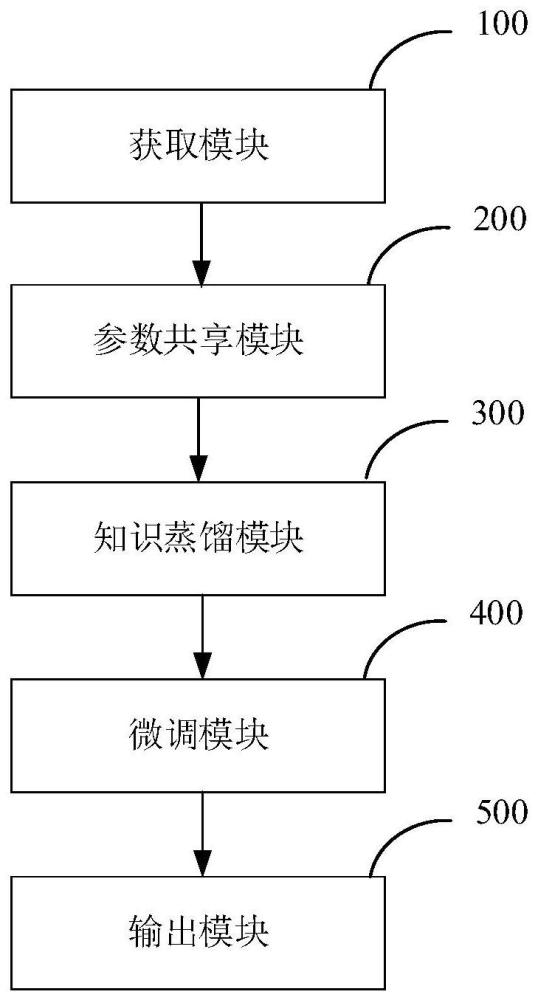
2、根据本发明的一个实施方案,提供了一种基于参数共享和知识蒸馏的分子属性预测模型的压缩系统,其包括以下模块:获取模块,其配置为获取分别用于预训练的分子结构数据的训练集、验证集以及用于微调的分子结构数据的训练集、验证集和测试集;参数共享模块,其配置为基于原始的分子属性预测模型来构建参数共享的分子属性预测模型,并且将用于预训练的分子结构数据的训练集输入到原始的分子属性预测模型和构建的参数共享的分子属性预测模型,以对参数共享的分子属性预测模型进行预训练,从而获得经过预训练的参数共享的分子属性预测模型;知识蒸馏模块,其配置为利用预训练的参数共享的分子属性预测模型来构建知识蒸馏的分子属性预测模型,并且将用于预训练的分子结构数据的训练集输入到知识蒸馏的分子属性预测模型,以对知识蒸馏的分子属性预测模型进行预训练,从而获得预训练的知识蒸馏的分子属性预测模型;微调模块,其配置为利用用于微调的分子结构数据的训练集对预训练的知识蒸馏的分子属性预测模型进行微调,从而获得最终的分子属性预测模型;输出模块,其配置为将用于微调的分子结构数据的测试集输入至最终的分子属性预测模型,从而输出分子性质预测效果的数据。
3、优选地,所述原始的分子属性预测模型设置为molbert模型;所述molbert模型包括12个编码器单元、768维度的隐藏层,每个编码器单元包括12个注意力头;所述12个编码器单元顺序地堆叠布置。
4、优选地,通过将molbert模型的不同编码器单元之间的权重设置为相同来获得参数共享的分子属性预测模型;molbert模型和参数共享的分子属性预测模型的编码器单元顺序地堆叠布置。
5、优选地,对参数共享的分子属性预测模型进行预训练包括遮蔽语言模拟和分子理化性质预测,并且基于使以下的损失函数最小化来获得最优模型:
6、lps=lmlm+lphyschempred
7、其中,lps是参数共享的损失函数,lmlm是遮蔽语言模拟的损失函数,lphyschempred是分子理化性质预测的损失函数,
8、
9、其中,yij是yi中第j个元素的值,是中第j个元素的值,
10、
11、其中,yi是第i个元素的预测值,代表真实值。
12、优选地,构建知识蒸馏的分子属性预测模型包括:构建知识蒸馏教师与学生模型,将教师模型设置为预训练的参数共享的分子属性预测模型,将学生模型的层数设置为少于教师模型的层数,通过随机初始化来获得学生模型的不同层之间的权重,从而得到压缩后的学生模型作为知识蒸馏的分子属性预测模型。
13、优选地,对知识蒸馏的分子属性预测模型进行预训练包括基于使以下的知识蒸馏的损失函数最小化来获得最优模型:
14、lkd=lmlm+lhidn+llogits
15、其中,lkd是知识蒸馏的损失函数,lmlm是遮蔽语言模拟的损失函数,lhidn是教师模型和学生模型之间的隐藏状态的损失函数,llogits是教师模型和学生模型之间的逻辑斯特得分的损失函数,
16、
17、其中,yij是yi中第j个元素的值,是中第j个元素的值;
18、
19、
20、其中,t是蒸馏温度,w是与t相关的线性函数,是老师模型的隐藏状态值,是学生模型的隐藏状态值,是老师模型的逻辑斯特得分值,是学生模型的逻辑斯特得分值。
21、优选地,对预训练的知识蒸馏模型进行微调包括:设置微调任务中的分类任务和回归任务的度量方式,其中,将分类任务的度量方式设置为接受者操作特征曲线下与坐标轴围成的面积,将回归任务的度量方式设置为决定系数;设置微调任务中的分类任务和回归任务的损失函数,其中,将分类任务的损失函数设置为交叉熵损失函数,将回归任务的损失函数设置为均方根误差损失函数。
22、优选地,所述获取模块进一步配置为:利用简化分子线性输入规范将获取的分别用于预训练和微调的分子结构数据转换为字符串形式。
23、根据本发明的实施方案,提供了一种基于参数共享和知识蒸馏的分子属性预测模型的压缩方法,其包括:获取分别用于预训练的分子结构数据的训练集、验证集以及用于微调的分子结构数据的训练集、验证集和测试集;基于原始的分子属性预测模型来构建参数共享的分子属性预测模型,并且将用于预训练的分子结构数据的训练集输入到原始的分子属性预测模型和构建的参数共享的分子属性预测模型,以对参数共享的分子属性预测模型进行预训练,从而获得经过预训练的参数共享的分子属性预测模型;利用预训练的参数共享的分子属性预测模型来构建知识蒸馏的分子属性预测模型,并且将用于预训练的分子结构数据的训练集输入到知识蒸馏的分子属性预测模型,以对知识蒸馏的分子属性预测模型进行预训练,从而获得预训练的知识蒸馏的分子属性预测模型;利用用于微调的分子结构数据的训练集对预训练的知识蒸馏模型进行微调,从而获得最终的分子属性预测模型;将用于微调的分子结构数据的测试集输入至最终的分子属性预测模型,从而输出分子性质预测效果的数据。
24、优选地,所述原始的分子属性预测模型设置为molbert模型;所述molbert模型包括12个编码器单元、768维度的隐藏层,每个编码器单元包括12个注意力头;所述12个编码器单元顺序地堆叠布置。
25、优选地,通过将molbert模型的不同编码器单元之间的权重设置为相同来获得参数共享的分子属性预测模型;molbert模型和参数共享的分子属性预测模型的编码器单元顺序地堆叠布置。
26、优选地,对参数共享的分子属性预测模型进行预训练包括遮蔽语言模拟和分子理化性质预测,并且基于使以下的损失函数最小化来获得最优模型:
27、lps=lmlm+lphyschempred
28、其中,lps是参数共享的损失函数,lmlm是遮蔽语言模拟的损失函数,lphyschempred是分子理化性质预测的损失函数,
29、
30、其中,yij是yi中第j个元素的值,是中第j个元素的值,
31、
32、其中,yi是第i个元素的预测值,代表真实值。
33、优选地,构建知识蒸馏的分子属性预测模型包括:构建知识蒸馏教师与学生模型,将教师模型设置为预训练的参数共享的分子属性预测模型,将学生模型的层数设置为少于教师模型的层数,通过随机初始化来获得学生模型的不同层之间的权重,从而得到压缩后的学生模型作为知识蒸馏的分子属性预测模型。
34、优选地,对知识蒸馏的分子属性预测模型进行预训练包括基于使以下的知识蒸馏的损失函数最小化来获得最优模型:
35、lkd=lmlm+lhidn+llogits
36、其中,lkd是知识蒸馏的损失函数,lmlm是遮蔽语言模拟的损失函数,lhidn是教师模型和学生模型之间的隐藏状态的损失函数,llogits是教师模型和学生模型之间的逻辑斯特得分的损失函数,
37、
38、其中,yij是yi中第j个元素的值,是中第j个元素的值;
39、
40、
41、其中,t是蒸馏温度,w是与t相关的线性函数,是老师模型的隐藏状态值,是学生模型的隐藏状态值,是老师模型的逻辑斯特得分值,是学生模型的逻辑斯特得分值。
42、优选地,对预训练的知识蒸馏模型进行微调包括:设置微调任务中的分类任务和回归任务的度量方式,其中,将分类任务的度量方式设置为接受者操作特征曲线下与坐标轴围成的面积,将回归任务的度量方式设置为决定系数;设置微调任务中的分类任务和回归任务的损失函数,其中,将分类任务的损失函数设置为交叉熵损失函数,将回归任务的损失函数设置为均方根误差损失函数。
43、优选地,基于参数共享和知识蒸馏的分子属性预测模型的压缩方法进一步包括:利用简化分子线性输入规范将获取的分别用于预训练和微调的分子结构数据转换为字符串形式。
44、根据本发明的实施方案,提供了一种计算机可读存储介质,其上存储有计算机指令,其特征在于,该计算机指令被处理器执行时实现以下步骤:获取分别用于预训练的分子结构数据的训练集、验证集以及用于微调的分子结构数据的训练集、验证集和测试集;基于原始的分子属性预测模型来构建参数共享的分子属性预测模型,并且将用于预训练的分子结构数据的训练集输入到原始的分子属性预测模型和构建的参数共享的分子属性预测模型,以对参数共享的分子属性预测模型进行预训练,从而获得经过预训练的参数共享的分子属性预测模型;利用预训练的参数共享的分子属性预测模型来构建知识蒸馏的分子属性预测模型,并且将用于预训练的分子结构数据的训练集输入到知识蒸馏的分子属性预测模型,以对知识蒸馏的分子属性预测模型进行预训练,从而获得预训练的知识蒸馏的分子属性预测模型;利用用于微调的分子结构数据的训练集对预训练的知识蒸馏模型进行微调,从而获得最终的分子属性预测模型;将用于微调的分子结构数据的测试集输入至最终的分子属性预测模型,从而输出分子性质预测效果的数据。
45、本发明采取以上技术方案,其具有以下有益效果:
46、1.通过将原始模型的不同层之间的权重设置为相同而获得参数共享的模型,可以减少模型参数的数量,从而降低模型的存储空间和计算复杂度。
47、2.通过将大型transformer模型的知识迁移到小型transformer模型中,可以实现对小型模型的有效训练和优化。同时,由于小型模型学习了大型模型的知识,因此其性能也能够得到保证。
48、3.通过使用少量的标记的分子属性数据来微调模型,使其更好地适应特定的任务,以进一步提高模型的性能和泛化能力。同时,由于只需要使用少量的标记的分子属性数据进行微调,因此可以节省大量的时间和计算资源。
49、总之,本发明采用参数共享和知识蒸馏的方法来训练和优化分子属性预测模型,具有高效、快速、准确等优点,适用于各种类型的分子属性预测任务,具有广泛的应用前景。
- 还没有人留言评论。精彩留言会获得点赞!