基于多特征融合的混合神经网络慢病诊疗问题分类方法
本发明涉及文本分类,特别涉及一种基于多特征融合的混合神经网络慢病诊疗问题分类方法。
背景技术:
1、近年来,慢性病的增加成为了威胁人类健康的一大挑战。随着社会生活方式、饮食结构以及工作模式的改变,慢性病的患病率不断攀升。这些疾病不像传染病那样具有明显的急性特征,而是在较长的时间内逐渐发展。因此,对慢性病进行早期诊断和有效预测显得尤为重要。及时发现慢性疾病,尤其是在其早期阶段,有助于及时采取预防和治疗措施,以防止疾病进一步恶化,提高患者的生活质量。
2、然而,慢性病问题在大众中的认知和了解存在着一定的局限和偏差。很多人对这类疾病的认知不足,往往容易将慢性病与一般疾病混淆,忽视了它们的潜在危险性。现有的慢性病相关网站或平台未能满足患者的实际需求,无法根据患者提出的问题提供及时、准确的答案,这导致了患者在诊断过程中耗费了大量的时间和精力,甚至造成了误诊或延误诊治。
3、为解决这些问题,发展一种高效、高质量的医疗问答系统变得至关重要。这种系统不仅需要快速响应用户的问题,还需要准确地分类问题并提供精确的答案。因此,问题分类任务变得尤为关键。这项任务涉及将用户提出的问题自动归类到一个或多个相关类别中,从而为后续的诊断和治疗提供关键信息。通过计算机对自然语言进行理解和分类,系统可以自动将用户问题分门别类,为慢性病患者提供及时有效的帮助,减轻医患双方的负担。
4、在慢病诊疗问题分类任务方面,最初采用基于规则的方法,依赖于手动提取的特征或规则,方法难以迁移到其他领域,无法处理复杂的场景。随着慢病诊疗问题的多样化和复杂化,仅依靠规则进行分类过于简单,因此采用基于机器学习的方法。相比基于规则的方法,基于机器学习的方法可以取得很好的效果,但目前主要是采用线性模型或者浅层的非线性模型,准确性受到了固有的局限性制约,在处理复杂的语义信息和大数据集时效果有限,难以捕捉文本的深层次特征。此外,基于规则和基于机器学习的慢病诊疗问题分类方法通常受限于特征工程的局限性,需要大量人工干预和调整。
5、目前深度学习模型主要集中在基于深度学习的慢病诊疗问题分类方法。例如,卷积神经网络(cnn)和循环神经网络(rnn)等模型在诊疗问题分类任务中取得了一定的成功。但基于深度学习的方法多是采用简单的浅层深度学习模型,对文本表示能力弱、无法准确捕捉文本语义特征,导致了现有技术在实现慢病诊疗问题分类任务时的性能较低。
技术实现思路
1、本发明的目的在于针对现有技术在处理慢病领域诊疗问题分类上存在的主要不足,使用多特征融合联合混合神经网络模型建立的慢病诊疗问题分类模型考虑多特征融合对问题分类的影响,尤其是针对慢病诊断问题文本的复杂性和特殊性,通过利用文本字特征和词特征的融合,在模型训练中充分使用文本的多特征信息,提高了文本特征的表示能力。
2、本发明是通过如下措施实现的:一种基于多特征融合的混合神经网络慢病诊疗问题分类方法,其特征在于,包括:
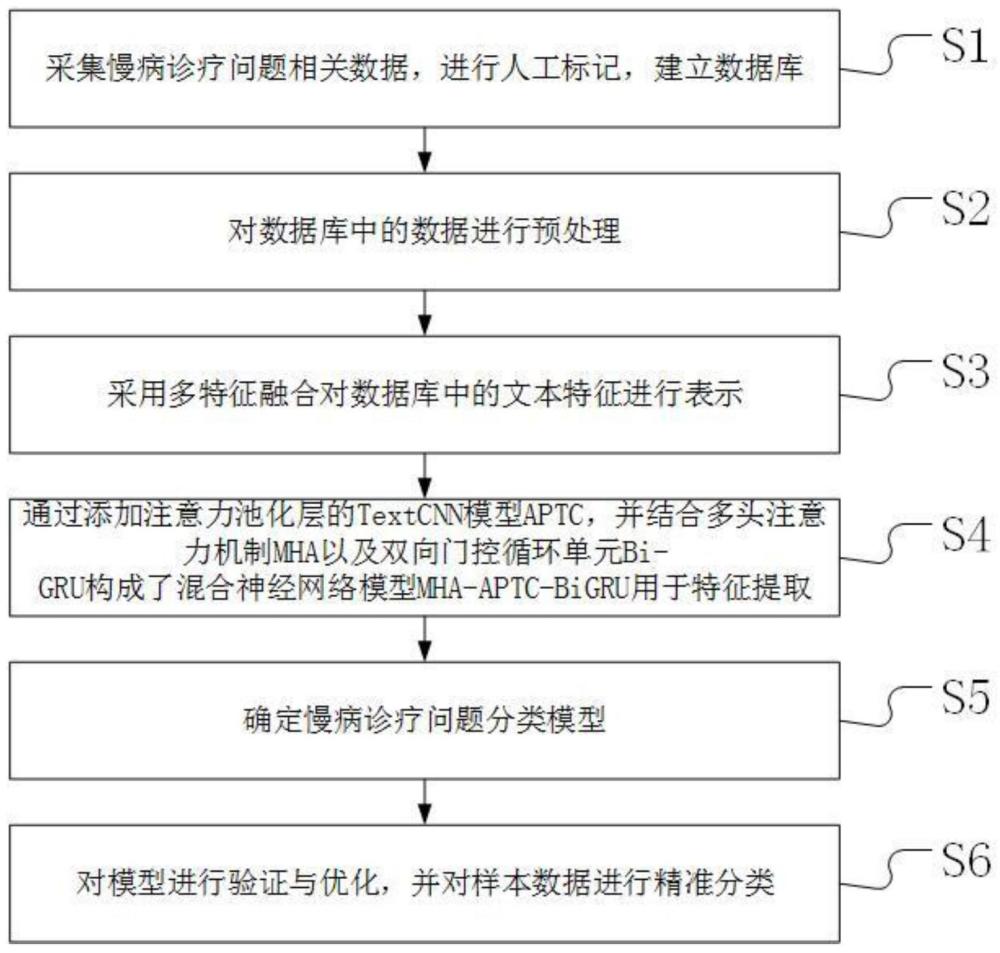
3、采集慢病诊疗问题相关数据,进行人工标记,建立数据库;其中慢病诊疗问题相关数据是指公众(非医疗领域工作者)通过互联网发布在慢病医疗网站上关于某个主题,以获得医生回复的请求数据;
4、对数据库中的数据进行预处理,包括去除停用词和无关标点符号、删除异常样本;
5、采用多特征融合对数据库中的文本特征进行表示,可以提高文本特征表示能力。
6、通过添加注意力池化层的textcnn模型aptc,并结合多头注意力机制mha以及双向门控循环单元bi-gru构成了混合神经网络模型mha-aptc-bigru用于特征提取;
7、确定慢病诊疗问题分类模型;
8、对模型进行验证与优化,并对样本数据进行精准分类。
9、进一步地,采用多特征融合对数据库中的文本特征进行表示,包括:
10、对输入文本进行按字为单位的分词操作,得到字序列x=x1,x2,x3,......,xn},用xi表示第i个字,总字数为n;
11、再将xi表示成向量ui,映射到roberta模型的嵌入空间;映射过程如下所示:
12、ci=roberta embedding(ui),其中,ci代表第i个字的向量表示,robertaembedding是roberta的编码模块,采用12层transformer编码模块构成;
13、将每个字转换为其在roberta嵌入空间中的向量表示,如下:croberta=[c1,c2,c3,......,cn]t∈rn×d,其中,n表示文本中字的数量,d表示字向量的维度,croberta表示n行、d列的字向量矩阵,以zc表示字向量矩阵;
14、对输入文本进行按词为单位的分词操作,得到词序列x={x1,x2,x3,......,xm},用xi表示第i个词,m表示总词数;
15、在训练过程中,最小化给定中心词时预测上下文词汇的错误,通过反向传播算法更新词向量,损失函数公式为:
16、
17、其中,t代表数据库中的词汇总数,xt是中心词,xi+j是上下文词汇;
18、将单词映射到word2vec模型的词嵌入空间,映射过程如下所示;wi=word2vecembedding(xi),其中,wi代表第i个词的向量表示,word2vec embedding是skip-gram编码模块;通过这个操作,将每个词转换为在word2vec嵌入空间中的向量表示,如下:wword2vec=w1,w2,......,wm]t∈rm×d,其中,m表示文本中词的数量,d表示词向量的维度,wword2vec表示m行、d列的词向量矩阵,以zw表示词向量矩阵。
19、进一步地,通过添加注意力池化层的textcnn模型aptc,并结合多头注意力机制mha以及双向门控循环单元bi-gru构成了混合神经网络模型mha-aptc-bigru用于特征提取,包括,
20、将zc、zw输入mha-aptc-bigru模型时,先分别输入到多头注意力机制mha中进行关键词加权输出得到和mc和mw;具体为:
21、将通过文本特征表示生成的向量矩阵命名为zr=(z1,z2,.......,zn),其中包括zr包括zc和zw;
22、通过自注意力机制,计算出单词之间的注意力权重矩阵,zi代表第i个单词的向量,z∈rn×d中n代表n个单词数,d为向量维数,注意力机制表示的计算
23、过程如下:
24、
25、其中q,k,v分别代表着向量矩阵zr映射的查询矩阵和键矩阵以及值矩阵,dk为嵌入层的输出维数,attention表示经过softmax归一化得到的注意力权重矩阵与值矩阵相乘,加权求和后得到的注意力输出;
26、使用h个注意力头,对输入矩阵x进行多头注意力计算:
27、
28、mr=[head1,head2,......,headh]w0;
29、其中,wiq、wik、wiv针对第i个注意力头学习的映射矩阵,headi代表第i个注意力头的输出,w0是所有注意力头的输出拼接后的注意力矩阵参数,mr是经过mha加权后的向量输出,其中mr包括mc和mw。通过多头注意力机制,根据类别的语义关联性对多类别相关的不同关键词进行权重赋值,提高模型对文本语义信息的理解程度。
30、再输入到卷积核个数为t的aptc模块增强重要特征在预测问题类别中影响力,关注卷积提取的不同细粒度特征之间以及文本上下文之间的关系后输出qw和qc,拼接后通过dropout层防止过拟合输出为
31、具体为:在卷积层,将mha输出的向量矩阵mr使用不同尺寸大小的卷积核进行卷积操作,从而得到不同粒度的特征向量。对于大小为k的卷积核w∈rd×k以及窗口mi:i+k-1进行卷积操作生成特征向量:
32、ci=f(g(w·mi:i+k-1)+b)
33、其中,mi:i+k-1表示由m的i行到i+k-1行组成的大小为k×d的窗口,由mi,mi+1,......,mi+k-1拼接而成,g函数是将一个矩阵的所有元素求和,b为偏置参数,f为非线性函数,本文使用relu激活函数。卷积之后得到的特征向量c∈r(n-k+1,1)为:c=[c1,c2,......,cn-k+1]t;
34、注意力池化层将经过不同大小卷积核卷积后的特征向量,互相计算注意力权重,从而区分其中的重要信息。将两个特征向量分别命名为cs和cb,代表不同大小卷积核卷积后的小尺寸特征向量和大尺寸特征向量,进行如下公式计算可以得到注意力权重向量矩阵a:ai,j=getscore(cs[i,:],cb[j,:]),其中aij代表cs的第i行向量和cb的第j行向量的距离度量代表cs的第i行向量和cb的第j行向量的距离度量。
35、cs每个单元对应的attention权重αs,j是由权重向量矩阵a按列向量求和的值作为权重值:αs,j=∑a[j,:];
36、cb每个单元对应的attention权重αs,j是由权重向量矩阵a按行向量求和的值作为权重值:αb,j=∑a[:,j];
37、将卷积后输出的特征矩阵与对应的注意力的权重值相乘,提取出重要的特征信息:px[l,:]=∑k=0:n-kax,kcx[k,l],l=0......t,其中,x分为s和b,分别代表两个不同卷积核尺寸大小,n为输入文本序列的单词数,k为卷积核的尺寸大小,t为卷积核数目,αx,k是对应的attention权重值,cx是卷积后得到的特征向量,px是池化后得到的文本特征;
38、将ps和pb进行拼接操作,得到不同细粒度卷积后交互特性信息向量:
39、
40、qr=[q1,q2,......,qn];
41、其中,qi为注意力池化后的特征向量,qr为aptc提取的特征向量,n为卷积核尺寸大小的数目,根据aptc接收的内容不同,r分为c和w,分别代表字特征向量和词特征向量;
42、最后,采用bi-gru模型从正反两个方向提取文本的上下文特征,以及语义特征和语法特征。采用由aptc提取的特征拼接而成的特征信息经过dropout层防止过拟合后的向量x,作为bi-gru模块的输入:
43、再将x输入bi-gru模块分别从正向和反向同时提取上下文语义信息和拼接为具体为:
44、bi-gru模块分别从正向和反向同时提取长文本的上下文语义信息,每个方向的gru涉及四个部分的计算;
45、使用复位门来选择上一时刻要舍弃的信息,rt=σ(wrxt+urht-1+br),其中wr和ur是权重信息,ht-1是上一时刻的输入,br是偏置。
46、然后通过更新门选择更新当前时刻的信息,zt=σ(wzxt+uzht-1+bz),其中wz和uz为权重信息,ht-1为上一时刻的输入,bz为偏置:
47、然后计算候选记忆内容,其中w和u为权重信息,b为偏置:
48、然后,计算当前时刻输出:
49、最后bi-gru模块是将正反两个方向输出的特征向量和进行拼接,输出向量h:
50、进一步地,采用sigmoid函数作为模型的输出函数,公式为:
51、
52、设置将判断文本是否属于给定类别的阈值,当pij≥阈值,表示该类别作为当前样本的输出类别之一,否则,不作为当前样本的输出类别。
53、进一步地,采集慢病诊疗问题相关数据包括从专业慢病网站的慢病诊疗问题;
54、或包括从专业慢病网站的慢病诊疗问题以及引入其他医疗网站健康问句,由于专业慢病网站中缺少外科学和中药学版块,因此从其他网站内随机采集相关板块问题数据进行数据增强。
55、进一步地,采集慢病诊疗问题相关数据,进行人工标记,建立数据库,包括:
56、人工筛查,剔除数据中与“慢病诊疗问题”的定义不符的问题;
57、手动丢弃其中不复杂的数据、重复的数据和不相关的数据;
58、当一个问题被排除后,从医疗网站同一版块中随机抽取另一个问题,以保持样本的均衡性;
59、根据健康问题分类标注规则对数据进行人工标注,分为六种类别,包括诊断、治疗、解剖学/生理学、流行病学、健康生活方式、择医,对每条数据标注为单一或多个类别标签。
60、进一步地,对模型进行验证与优化,并对样本数据进行精准分类,包括选择一部分具有代表性的慢病诊疗样本作为验证样本集来对模型反复进一步检验;
61、使用精确率、召回率和f1值对模型进行衡量,来验证本模型在慢病领域内诊疗问题分类的有效性。
62、进一步地,还包括根据训练数据集的预测值,通过二元交叉熵函数作为损失函数对慢病诊疗问题分类模型进行训练,公式为:
63、
64、其中,n为文本数,q为类别数,pij∈[0、1],yij∈{0,1}分别为第i个样本的第j个类别的预测值和真实值。
65、当模型的性能达到满意的水平时,将训练好的模型保存以备后续使用。包括保存模型的权重、结构和优化器的状态,以便在未来使用时加载已训练好的模型,而无需重新进行训练。
66、本发明实施例提供的技术方案带来的有益效果是:现有慢病诊疗问题分类方法通常只考虑使用字或词等单一的特征向量表示,忽视多特征信息融合对诊疗问题分类任务的研究,导致在面对繁杂多样的诊疗问句时语义表示能力较差,分类精度低。且慢病诊疗问题通常具有多个主题类别,现有的慢病诊疗问题分类方法通常忽视每个类别相关的不同关键词特征信息权重,从而导致分类错误以及类别预测缺失的问题。本发明提出的多特征融合和混合神经网络慢病诊疗问题分类方法,通过利用文本字特征和词特征的融合,在模型训练中充分使用文本的多特征信息,提高了文本特征的表示能力。通过混合神经网络模型提高文本的特征提取能力,进而提高分类精度。最终实现对样本的分类,解决了由于医学术语的繁杂性,以及患者主诉的口语化。为解决慢病诊疗问题分类中的挑战提供了一个有前景的方向,并可能促进智能医疗问答系统的发展。
- 还没有人留言评论。精彩留言会获得点赞!