训练医疗数据生成模型的方法、医疗数据生成方法及设备
本发明涉及医疗数据生成,特别是涉及一种训练医疗数据生成模型的方法、医疗数据生成方法及设备。
背景技术:
1、疾病的诊断和治疗策略需要医疗数据。医生根据患者的临床信息、实验室检测数据和影像学数据做出诊断和决策。这些数据可以帮助他们确定疾病类型、选择治疗方案等。对于罕见病例或特定疾病的数据,传统医疗数据采集通常昂贵且困难。因此,医疗数据应用经常遇到样本分布不均和数据量有限的问题。生成对抗网络作为一种强大的生成模型,能够生成逼真的虚拟数据,解决了传统方法无法解决的问题。生成对抗网络是一种深度学习模型,由生成器和判别器组成。判别器预测输入数据来自真实训练数据的概率,生成器则试图生成模仿真实分布的数据,以至判别器无法区分。使用gan生成的模拟数据可以增加医学数据的样本量,拓宽数据分布,以满足医学领域对于真实和多样化数据的需求。
2、在训练时,鉴别器对训练集的数据会出现过拟合,导致输出的生成数据相比于非训练集数据会更接近训练集数据。因此,gan中训练数据具有一定脆弱性,攻击者可以通过成员推理攻击的方式判断出目标是否出现在gan的训练集中,甚至是目标在训练集中的成员身份。使用gan生成用于医学数据时,训练集样本成员身份的泄露会揭露个体的患病史等敏感信息。在此基础上攻击者可以根据泄露的成员身份信息发起其他攻击,如数据分析、属性推断等等,进一步侵害患者的隐私。差分隐私作为一种隐私保护手段,为当前信息越来越发达的社会所带来的用户隐私泄露问题提供了解决方法。差分隐私技术通过噪声扰动,在保持可接受的隐私保证情况下,针对图像数据训练出较好可用性的模型。扰动方式包含计算扰动、输出扰动和目标扰动。输出扰动方法的主要思想是在通过传统方法训练的深度学习模型参数上加入噪声。目标扰动主要是在目标函数上加以噪声干扰,间接影响参数收敛。计算扰动通常是每一轮训练过程中,在目标函数所得梯度上添加噪声。
3、部分生成模型已经开始采用基于差分隐私的隐私保护方法来抵抗成员推理攻击。然而这些扰动方式可能会使模型无法很好的收敛,从而影响模型性能,过度的噪声会导致数据的可用性较低,生成的数据不真实或模糊。故而本领域亟需一种保证数据可用性的技术方案。
技术实现思路
1、本发明的目的是提供一种训练医疗数据生成模型的方法、医疗数据生成方法及设备,在有效保护模型隐私的同时,最大限度地提高了生成数据的可用性。
2、为实现上述目的,本发明提供了如下方案:
3、第一方面,本发明提供了一种训练医疗数据生成模型的方法,所述方法包括:
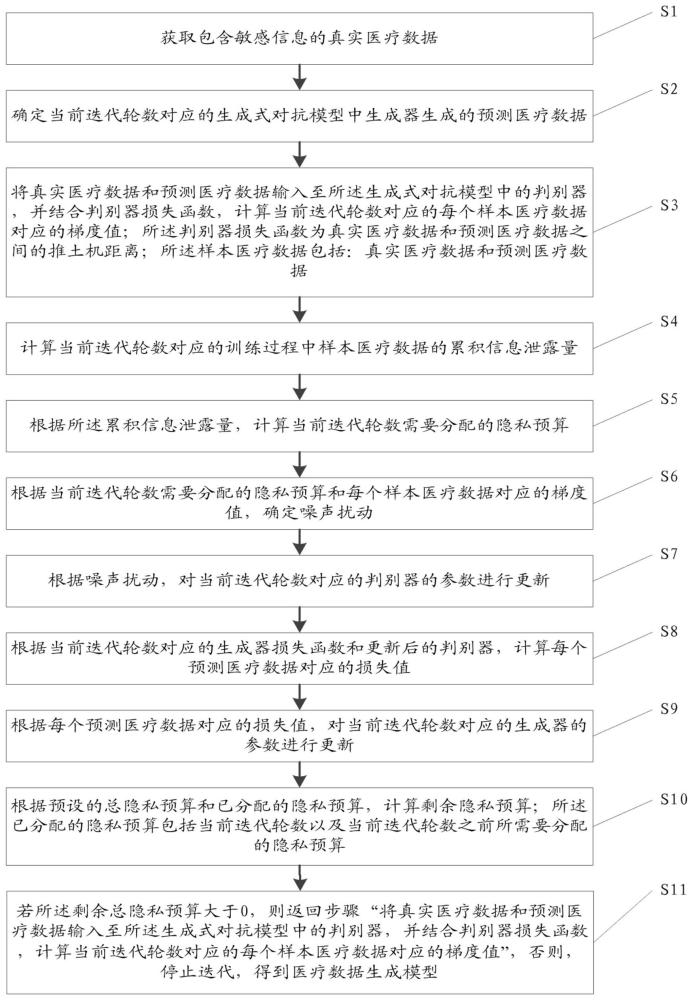
4、获取包含敏感信息的真实医疗数据;
5、确定当前迭代轮数对应的生成式对抗模型中生成器生成的预测医疗数据;
6、将真实医疗数据和预测医疗数据输入至所述生成式对抗模型中的判别器,并结合判别器损失函数,计算当前迭代轮数对应的每个样本医疗数据对应的梯度值;所述判别器损失函数为真实医疗数据和预测医疗数据之间的推土机距离;所述样本医疗数据包括:真实医疗数据和预测医疗数据;
7、计算当前迭代轮数对应的训练过程中样本医疗数据的累积信息泄露量;
8、根据所述累积信息泄露量,计算当前迭代轮数需要分配的隐私预算;
9、根据当前迭代轮数需要分配的隐私预算和每个样本医疗数据对应的梯度值,确定噪声扰动;
10、根据噪声扰动,对当前迭代轮数对应的判别器的参数进行更新;
11、根据当前迭代轮数对应的生成器损失函数和更新后的判别器,计算每个预测医疗数据对应的损失值;
12、根据每个预测医疗数据对应的损失值,对当前迭代轮数对应的生成器的参数进行更新;
13、根据预设的总隐私预算和已分配的隐私预算,计算剩余隐私预算;所述已分配的隐私预算包括当前迭代轮数以及当前迭代轮数之前所需要分配的隐私预算;
14、若所述剩余总隐私预算大于0,则返回步骤“将真实医疗数据和预测医疗数据输入至所述生成式对抗模型中的判别器,并结合判别器损失函数,计算当前迭代轮数对应的每个样本医疗数据对应的梯度值”,否则,停止迭代,得到医疗数据生成模型。
15、可选的,确定当前迭代轮数对应的生成式对抗模型中生成器生成的预测医疗数据,具体包括:
16、对潜在向量进行随机采样,得到潜在向量样本;
17、将所述潜在向量样本输入至生成式对抗模型中的生成器,得到与所述真实医疗数据样本数量相同,维度相同的预测医疗数据。
18、可选的,根据当前迭代轮数需要分配的隐私预算和每个样本医疗数据对应的梯度值,确定噪声扰动,具体包括:
19、计算每个样本医疗数据对应的梯度值的平均值;
20、在所述平均值中,添加均值为0,方差为的高斯噪声,得到噪声扰动;其中,p是采样的比例,td是一次生成器迭代中判别器的迭代次数,∈j为第j次迭代需要分配的隐私预算,δ是差分隐私的松弛项。
21、可选的,将真实医疗数据和预测医疗数据输入至所述生成式对抗模型中的判别器,并结合判别器损失函数,计算当前迭代轮数对应的每个样本医疗数据对应的梯度值,具体包括:
22、将真实医疗数据和预测医疗数据输入至所述生成式对抗模型中的判别器,并结合判别器损失函数,计算当前迭代轮数对应的判别器的损失值;所述判别器的损失函数为:其中,pr表示真实医疗数据的分布,pz表示作为生成器输入的噪声的分布,d表示判别器,g表示生成器,x和g(z)分别表示真实医疗数据和预测医疗数据,e表示期望值;
23、根据所述损失值计算当前迭代轮数对应的每个样本医疗数据对应的梯度值;梯度值的计算公式为:其中w表示判别器的参数,xi表示m个医疗数据中的第i个样本,zi表示对潜在向量z进行随机采样得到的第i个样本,g(zi)表示m个预测医疗数据样本中的第i个样本。
24、可选的,隐私预算的计算公式为:其中,lj是从第一次迭代到第j次迭代中每次迭代中泄露的信息量的总和,p是规模参数,lt是累积信息泄露的阈值。
25、可选的,根据每个预测医疗数据对应的损失值,对当前迭代轮数对应的生成器的参数进行更新,具体包括:
26、根据当前迭代轮数对应的每个预测医疗数据对应的损失值计算每个预测医疗数据对应的梯度值;梯度值的计算公式为:其中,θ表示生成器的参数,za表示对潜在向量z进行随机采样得到的第a个样本,g(za)表示m个预测医疗数据样本中的第a个样本,表示求梯度;
27、根据每个预测医疗数据对应的梯度值,更新当前迭代轮数对应的生成器的参数。
28、可选的,一次迭代过程中的信息泄露量的计算公式为:
29、ix'=mse(d,x')×id-mse(y,x')×iy;
30、其中,ix'表示第j-1次迭代泄露的信息量,d是真实医疗数据集,x'是当前判别器迭代中生成器生成的预测医疗数据集合,id是真实医疗数据集包含的信息量,y是从第一次迭代到当前迭代的前一次迭代生成的所有预测医疗数据,iy是当前迭代之前生成的所有预测医疗数据的总信息量,mse是均方误差。
31、第二方面,本发明提供了一种医疗数据生成方法,所述方法包括:
32、获取待处理医疗数据;
33、将所述待处理医疗数据输入医疗数据生成模型,输出基于差分隐私的医疗数据;所述医疗数据生成模型是利用如权利要求1至7中任一项所述的训练医疗数据生成模型的方法训练得到的。
34、第三方面,本发明提供了一种计算机设备,包括:存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序以实现上述训练医疗数据生成模型的方法的步骤。
35、第四方面,本发明提供了一种计算机设备,包括:存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序以实现上述医疗数据生成方法的步骤。
36、根据本发明提供的具体实施例,本发明公开了以下技术效果:
37、本发明提供了一种训练医疗数据生成模型的方法、医疗数据生成方法及设备,方法包括:获取包含敏感信息的真实医疗数据;确定当前迭代轮数对应的生成式对抗模型中生成器生成的预测医疗数据;将真实医疗数据和预测医疗数据输入至所述生成式对抗模型中的判别器,并结合判别器损失函数,计算当前迭代轮数对应的每个样本医疗数据对应的梯度值;所述判别器损失函数为真实医疗数据和样本医疗数据之间的推土机距离;所述样本医疗数据包括:真实医疗数据和预测医疗数据;计算当前迭代轮数对应的训练过程中样本医疗数据的累积信息泄露量;根据所述累积信息泄露量,计算当前迭代轮数需要分配的隐私预算;根据当前迭代轮数需要分配的隐私预算和每个样本医疗数据对应的梯度值,确定噪声扰动;根据噪声扰动,对当前迭代轮数对应的判别器的参数进行更新;根据当前迭代轮数对应的生成器损失函数和更新后的判别器,计算每个预测医疗数据对应的损失值;根据每个预测医疗数据对应的损失值,对当前迭代轮数对应的生成器的参数进行更新;根据预设的总隐私预算和已分配的隐私预算,计算剩余隐私预算;所述已分配的隐私预算包括当前迭代轮数以及当前迭代轮数之前所需要需要分配的隐私预算;若所述剩余总隐私预算大于0,则返回步骤“将真实医疗数据和预测医疗数据输入至所述生成式对抗模型中的判别器,并结合判别器损失函数,计算当前迭代轮数对应的每个样本医疗数据对应的梯度值”,否则,停止迭代,得到医疗数据生成模型,本发明提出了一种根据信息泄露灵活分配隐私预算的差分隐私方法,在保护了训练数据隐私的同时,合理分配隐私预算,提高生成医疗数据的可用性。
- 还没有人留言评论。精彩留言会获得点赞!