一种基于脑电图和微表情的多模态情绪识别和意识检测方法
本发明属于人工智能、脑机接口、情绪识别,具体涉及一种基于脑电图和微表情的多模态情绪识别和意识检测方法。
背景技术:
1、情绪识别是通过分析人的生理行为和活动来理解其情绪的状态,涉及心理学和医学等领域。该技术不仅可以帮助理解个体的情绪体验,还成为评估意识状态的重要工具。意识检测是准确监测和评估意识障碍患者的意识状态的技术,关系到患者治疗手段的选择和预后的判断,准确的评估意识状态对这类患者尤为重要。近年来,人们对通过面部表情、手势和语言等方式来表达情绪进行了广泛的研究,生理信号如肌电图、心电图和脑电图等也是情绪难以隐藏的客观表现。通过脸部肌肉的变化可以反映情绪的变化,大脑正常活动的电信号变化也能反映出脑神经细胞产生的各种生理电信号在大脑皮层的变化情况,进而分析出情绪的变化情况。
2、目前,在情绪识别领域中,研究人员主要使用单一模态数据,如脑电图(eeg)、心电图、肌电图或面部表情、手势和语言等进行情绪识别。然而,在对意识障碍患者进行情绪检测存在单一模态方法的局限性,这些方法无法捕捉到情绪状态的复杂相互作用,导致评估结果的不准确和不全面,使得评估结果准确率不高。因此,需要更准确、综合的评估工具。在意识障碍领域,存在着意识障碍患者的意识状态诊断的挑战,特别是在昏迷、微意识状态(mcs)和无反应觉醒综合征(uws)三种类型的意识障碍中,诊断的挑战性问题日益凸显。针对意识障碍患者的意识检测方法主要包括运动反应为基础的临床评估方法和功能性磁共振成像(fmri)技术。这些方法也存在一些短板,传统的临床评估方法,例如以运动反应为基础的昏迷恢复量表修订版(crs-r)。这种临床评估方法存在高误诊率和缺乏敏感性的问题,在诊断意识状态时有着37%~43%的误诊率,这可能导致一些患者未能获得准确的意识状态评估和适当的治疗,因此需要更准确和全面的评估工具。功能性磁共振成像(fmri)可以显示意识障碍患者在特定活动任务中的脑活动模式,但它设备昂贵且操作复杂,需要专业的操作和分析,在临床环境中的应用受到限制,对操作和分析人员的技术要求较高。为降低误诊率并提高评估的准确性,需要引入更简便和有效的方法来补充意识状态评估,使得在临床环境中实施足够简便,并能够提供更准确的意识状态信息。
3、为降低误诊风险并提高评估的准确性,需要引入更简化和敏感性的方法来补充意识评估。对于无反应觉醒综合征(uws)患者而言,他们对周围环境和自身没有意识,而微意识状态(mcs)患者的意识较弱。因此,可以假设在被动范式中出现情绪变化的患者有更好的康复机会。近年来,由于计算机视觉和脑机接口(bcis)的迅猛发展,基于面部图像和脑电图的情绪识别准确度有所提高。相比于基于运动反应的评估方法和fmri,基于脑电图和微表情的多模态情绪识别可以更简化地诊断意识障碍患者的残余意识状态,并作为辅助诊断的工具
技术实现思路
1、本发明的目的在于提供一种基于脑电图和微表情的多模态情绪识别和意识检测方法,以解决上述背景技术中提出的意识障碍领域中存在的传统诊断方法误诊率高、缺乏敏感性的问题。
2、为实现上述目的,本发明提供如下技术方案:一种基于脑电图和微表情的多模态情绪识别和意识检测方法,具体包括如下步骤:
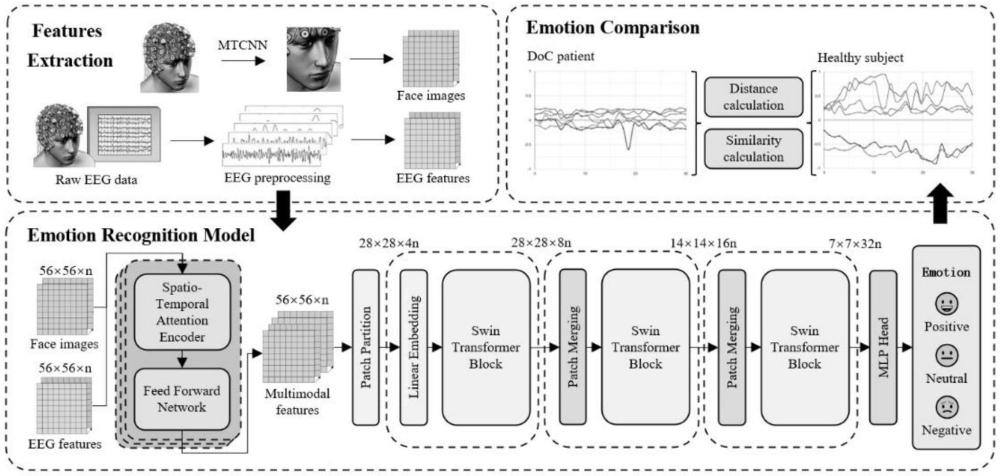
3、步骤一:特征提取,关注多通道脑电信号的关联并提取微表情特征,通过特征层对脑电图和微表情进行特征融合,形成多模态特征;
4、对于脑电图特征,处理步骤如下:
5、a、对原始脑电信号进行预处理,包括剔除伪影、滤波和成分去除;
6、b、预处理后,根据输出大小将每个通道的脑电图数据分割成不重叠的1秒间隔,以提取脑电图特征;
7、步骤二:构建情绪识别模型,选择swintransformer作为模型的骨干网络,在定制swintransformer时,模型优化补丁大小和网络深度,使之与特征张量的维度相一致;确保了stst模型符合情感识别任务的要求,并能充分发挥swintransformer架构的潜力;
8、步骤三:情绪对比指标,将准确性作为基准,将其模型性能与其他已有方法进行比较,在情绪分类方面的功效提供了一个量化的衡量标准;
9、步骤四:实验数据集,在公开数据集上,在多模态数据集mahnob-hci上检测其情绪识别准确率;
10、步骤五:实验数据预处理,使用了公开数据集和自采数据集,并对这两种数据集采用了一致的数据预处理流程,以确保结果的可比性和稳健性;
11、步骤六:实验参数设置,提取de作为脑电模态的输入,提取连续的人脸图像序列作为微表情模态的输入;它们的输入大小分别为56×56×5;脑电图模态表示5个脑电图频带,微表情模态表示在0.2秒内均匀连续变化的5幅人脸图像;在公共数据集上验证了本方法的可行性,然后在健康受试者的数据上进行预训练,并在mcs患者的数据上进行微调;最后,在uws患者的数据上计算评估指标。
12、作为本发明中一种优选的技术方案,在步骤一中,经过带通滤波器后的脑电信号服从高斯分布n(μ,σ2),,脑电图的de特征计算如下:
13、
14、其中f(x)是x的概率密度函数,σ2是这段脑电图的方差;de特征属于频域特征,通常用于情绪识别的脑电信号被分为五个不同的频段:δ(0.1-4hz)、θ(4-8hz)、α(8-12hz)、β(12-30hz)和γ(30-45hz);在本方法中,分别计算了每个频段的de特征;每个样本的最终特征向量包含56个通道(或28个通道×2)×56个de特征×5个频段,以确保与微表情特征的大小相匹配。
15、作为本发明中一种优选的技术方案,在所述步骤一中,对于脑电图和微表情的多模态特征融合,使用一种针对于脑电图和微表情数据的时空注意力机制多模态特征融合架构,旨在从多模态数据流中分离出情感上的显著特征;
16、在时间注意力模块中,输入的微表情特征xme最初通过一个1×1卷积层(表示为wv)进行处理,生成一个转换特征;随后,这些特征经过重塑,维度为cme×2hw,h和w分别表示特征图的高度和宽度;另一个1×1卷积层wq用于生成查询特征,然后通过softmax层计算注意力分布;该注意力分布图与转置特征元素相乘,得到时间注意力特征图zta;时间注意力机制旨在捕捉微表情图像序列中的时间信息;它利用注意力权重,捕捉相同空间位置随时间的变化来描述微表情的特征;表示这一过程的公式如下:
17、
18、其中,wq、wv和wz是1×1卷积层,σ1和σ2是两个张量重塑算子,是矩阵点积运算,⊙是通道乘法;fsm是softmax运算符;包括wz卷积运算,然后是层正则化和sigmoid运算符;
19、与此同时,空间注意力机制以类似的方式处理输入的脑电图特征xeeg;该机制通过全局池化和重塑操作计算空间注意力分布;随后,该分布通过softmax和sigmoid层生成空间注意力特征zsa;空间注意力机制善于捕捉脑电信号同一频段内不同通道的空间注意力信息;表示这一过程的公式如下:
20、
21、其中,wq和wv是1×1卷积层,σ1和σ2是两个张量重塑算子,是矩阵点积运算,⊙是通道乘法,g是全局池化算子;fsm是softmax运算符;σs由一个张量重塑运算符和一个sigmoid运算符组成。
22、作为本发明中一种优选的技术方案,在脑电图和微表情特征的融合模型中,注意力机制得到了整合,以适应单一模态输入x;
23、在模型中,首先将脑电图和微表情特征结合起来;为了加强特征表征,将多层单模态输入叠加到时空注意机制上;在领域协调机制中,时间注意力特征zta和空间注意力特征zsa通过prelu激活函数进行非线性转换;prelu通过引入可学习参数来调整输入负部分的斜率,从而增强了模型从数据中学习复杂模式的能力;然后,将各自的结果与相加的融合特征进行通道乘法运算,求和的结果通过sigmoid函数进行处理,输出最终的融合特征zdc;域协调机制的计算公式如下:
24、zdc_1=x⊙fsg((fprl(zta)+fprl(zsa))⊙(zta+zsa))
25、zdc_2=fsg((fprl(zta)+fprl(zsa))⊙(zta+zsa))
26、其中,zdc_1和zdc_2分别是输入多模态数据或脑电图和微表情两个维度时得到的输出;fsg表示sigmoid算子,fprl表示prelu算子;
27、时空注意力模块中所使用的前馈网络设计基于swintransformer,它适用于处理脑电信号时间数据和微表情空间数据,可以捕捉微表情数据中的局部空间特征,并适应脑电信号的时间特征,从而实现多模态数据融合;此外,滑动窗口机制改变了自我注意的计算方法。
28、作为本发明中一种优选的技术方案,所述步骤二中,骨干网络的输入是尺寸为56×56×n的多模态特征张量,然后对这些张量分割后进行线性嵌入,将特征转换成适合stst输入的尺寸;每个模块都由多层自注意力机制和多层感知器(mlp)组成,每个模块都会进行层归一化,之后都会应用残差连接相连;块内的自我注意力在层与层之间移动的局部窗口上运行,使模型能够有效捕捉局部和全局上下文信息。
29、作为本发明中一种优选的技术方案,所述步骤三中,对于自采数据集,首先使用10名健康受试者的数据来评估模型的准确性,这一步骤为预期的情绪反应建立了基线;随后,将模型应用于采集的21名患者的情绪分类;模型的情绪分类概率被映射到-1到1的连续情绪分数区间,其中-1表示消极,0表示中性,1表示积极;为了计算总体情绪状态得分,采用了加权法,这包括将每个类别的预测概率乘以其相关标签值,从而得到连续分数;表示这一过程的公式如下:
30、score=cneg×cneg+cneu×pneu+cpos×ppos
31、其中,cneg、cneu和cpos分别代表与消极、中性和积极情绪状态相关的贡献值,赋值分别为-1、0和1;pneg、pneu和ppos分别代表深度学习模型预测的消极、中性和积极情绪的概率;该公式旨在将情绪分类的概率输出转化为-1到1的连续得分,提供更准确的情绪倾向综合评估;为了评估模型的输出结果,分别使用欧氏距离和余弦相似度作为距离计算和相似度评估的指标;这些指标衡量的是意识障碍患者的情绪模式与健康人的情绪模式之间的相似程度;
32、使用准确率来评估情绪识别的分类性能;准确度是对模型在不同情绪类别中正确分类阳性和阴性实例能力的一般衡量标准,指标的定义如下:
33、
34、其中,tp表示真阳性,tn表示真阴性,fp表示假阳性,fn表示假阴性;准确度得分允许量化模型在整个数据集上的整体分类准确度,提供了一个全局性能指标;在对意识障碍患者进行情绪识别时,不能直接使用意识障碍患者的情绪标签;无法确保患者已被诱导出相应的情绪,因此无法进行传统的准确度评估,使用欧氏距离和余弦相似度作为衡量标准;
35、首先,使用欧氏距离来测量情绪表达之间的空间距离;对于每个样本,将其情绪得分表示为一个向量,并计算欧氏距离来衡量样本之间的差异;欧氏距离越小,情感强度越接近;
36、其次,使用余弦相似度来衡量情感向量之间的角度关系;具体来说,余弦相似度值越接近1,表示两者之间的情感变化趋势越相似;反之,该值越接近-1,则两者之间的情感变化趋势越相反;对于健康受试者在诱发视频播放时的情绪得分向量a=(a1,a2,...,an)和意识障碍患者的情绪得分向量b=(b1,b2,...,bn),它们之间的欧氏距离d和余弦相似度s按以下公式计算:
37、
38、欧氏距离是两个向量对应分量的平方差之和的平方根,欧氏距离的取值范围为[0,2];余弦相似度的取值范围为[-1,1],取值越接近1表示两个向量越相似,取值越接近-1表示两个向量越相反。
39、作为本发明中一种优选的技术方案,所述步骤四中,自采数据集中的数据包括脑电信号和面部表情图像;为了收集高质量的头皮脑电信号,使用nuamps放大器和脑电图帽记录了32个电极的头皮脑电信号,32个电极的阻抗均保持在30kω以下;脑电信号以1000hz的采样率采集,然后进行带通滤波(0.1-50hz);面部表情图像以1080p 30fps从摄像机录制的视频中导出;受试者处于受控环境中,外部刺激极少;实验设计包括观看视频诱发情绪的被动范式,包括图像和音频片段。
40、作为本发明中一种优选的技术方案,在所述步骤五中,在对面部图像进行预处理时,采取了几个步骤来确保数据的质量和适配性;从数据集中加载人脸图像并生成灰度图像,以降低计算复杂度;应用直方图均衡化来增强图像的对比度,从而提高图像质量,然后使用mtcnn模型检测图像中的人脸,并对检测到的人脸进行对齐,以确保它们具有相似的位置和大小;采用图像标准化处理,使像素值的均值为0,方差为1;
41、对于脑电信号的预处理:
42、首先,使用0.1至60hz带通滤波器和50hz陷波滤波器对信号进行滤波,以去除噪音;也检查导联的方差是否过大,是否包含过多的零,并检查每个导联的数据采集是否正常,如果有采集不正常的导联,则使用不良导联周围的通道的平均值进行插值;使用独立成分分析(ica)来识别和去除眼电和肌电信号中的噪声;还对脑电信号进行了标准化处理,以确保各通道的振幅一致。
43、作为本发明中一种优选的技术方案,在所述步骤六的实验中,以4:1的比例划分训练集和测试集,使用五则交叉验证策略来训练情绪识别模型;该模型使用pytorch框架实现,并使用学习率为3e-4的adamw优化器进行训练,学习率衰减使用余弦退火法;模型训练使用的批次大小为32,并对模型进行了100次训练。
44、与现有技术相比,本发明的有益效果是:
45、通过脑电图和微表情的多模态融合特征进行情绪识别,并用距离来衡量意识障碍患者和正常人情绪表达之间的差距,来区分意识状态的好坏程度,起到意识状态辅助检测的目的。对于多模态的情绪识别,本发明提出了一种多模态特征融合方法,通过创新的时空注意机制将eeg和微表情数据进行融合,并将情绪识别技术引入到意识状态评估。该方法通过深度学习技术,利用eeg的微分熵特征和微表情的时域特征进行融合,显著提高了情绪状态的检测和分类能力。结合eeg和微表情的多模态方法,更全面和深入地了解意识障碍患者的情绪状态。eeg作为对脑活动的直接反映,微表情则通过微小的面部变化信息,综合提供对意识障碍患者情绪状态的更全面和精确的描述。该方法不仅在准确性方面达到了主流模型的水平,还展示了在医学诊断中的广泛应用潜力,为个性化患者护理提供了基础,并为临床实践研究开辟了新的途径。在实际应用中的结果表明,对于检测出情绪波动与正常人更相似的患者,他们有着更高的脑活动水平,预示着有着更好的治疗结果,这与一个月后的临床结果一致。该方法通过有效地合并多个模态的数据,为意识障碍辅助检测中的情绪识别设立了新的范式,有助于更准确的临床评估,及时调整患者的治疗方案,提高了患者的生活质量和治疗结果。
46、(1)在本发明中,提出了一种创新的多模态融合框架,将eeg和微表情数据相结合,通过深度学习技术实现情绪状态的检测和分类。在框架中多模态融合的关键是提出了一种用于多模态融合的时空注意力模块,该模块能够独立处理来自脑电图和微表情的空间和时间数据,并通过一种基于极化注意力和领域融合的时空注意力机制,在特征层面上融合eeg和微表情数据,提高情绪识别的准确性。
47、(2)该方法将脑电图和微表情的低维人工特征与高维深度学习特征相结合,提高了情绪识别的准确率。低维人工特征通过时空注意力模块提取更多相关信息,并通过神经网络生成高维特征。这种混合方法能够将特定的低维特征和复杂的高维特征相结合,提高情绪识别的准确率。
48、(3)本发明提出了一种新的评估意识状态的结合eeg和微表情多模态方法,提供了更全面和精确的意识障碍患者情绪状态描述,为医疗保健专业人员提供了个性化医疗和护理决策的依据。通过多模态特征融合和深度学习方法,建立了用于评估意识障碍患者情绪表达的评估指标,为意识状态评估提供了新的量化手段,也将多模态情绪识别引入意识检测领域的临床实践提供了新的方法和理念。
- 还没有人留言评论。精彩留言会获得点赞!