一种虚拟角色的控制方法和相关装置与流程
本申请涉及计算机,特别是涉及一种虚拟角色的控制方法和相关装置。
背景技术:
1、随着人工智能(artificial intelligence,ai)技术的发展,可以通过ai控制虚拟角色执行各种拟人化的动作。例如,ai技术可以应用在复杂战术竞技游戏上,如通过ai技术预测虚拟角色即将执行的事件,从而实现虚拟角色的自动控制。
2、虽然通过ai技术控制的虚拟角色可以战胜用户控制的虚拟角色,但其在游戏中的策略和行为往往单一且难以理解。例如,通过ai技术控制的虚拟角色a当遇到生命值低于预设生命值阈值的虚拟角色b,必然会优先触发针对虚拟角色b的攻击技能,即ai技术控制的虚拟角色满足预设条件就会执行固定事件,固定且单一,又不看当前游戏环境,拟人程度较低。
3、也就是说,通过ai技术控制虚拟角色很难模拟用户控制的虚拟角色,限制了ai技术控制虚拟角色的吸引力和可玩性,导致用户体验感较低。
技术实现思路
1、为了解决上述技术问题,本申请提供了一种虚拟角色的控制方法和相关装置,用于提高控制虚拟角色的多样性和一致性,提高用户体验感。
2、本申请实施例公开了如下技术方案:
3、一方面,本申请实施例提供一种虚拟角色的控制方法,所述方法包括:
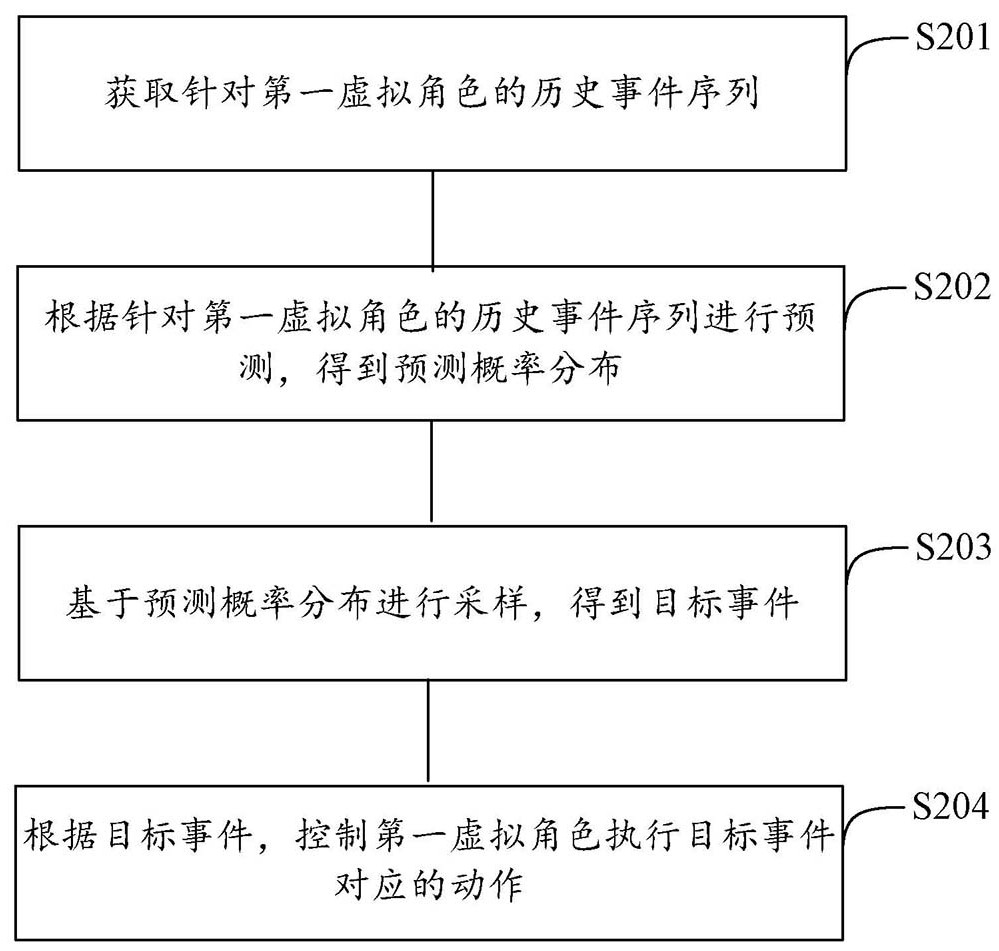
4、获取针对第一虚拟角色的历史事件序列,所述历史事件序列包括在n个阶段分别执行的事件,且n个所述事件按照时间先后顺序排列,所述事件用于指示所述第一虚拟角色执行对应动作,n为大于1的整数;
5、根据针对所述第一虚拟角色的历史事件序列进行预测,得到预测概率分布,所述预测概率分布包括预测所述第一虚拟角色在第n+1个阶段触发各个事件的概率;
6、基于所述预测概率分布进行采样,得到目标事件,所述目标事件为所述第一虚拟角色在第n+1个阶段触发的多个事件中的一个事件;
7、根据所述目标事件,控制所述第一虚拟角色执行所述目标事件对应的动作。
8、另一方面,本申请实施例提供一种虚拟角色的控制装置,所述装置包括:获取单元、预测单元、采样单元和控制单元;
9、所述获取单元,用于获取针对第一虚拟角色的历史事件序列,所述历史事件序列包括在n个阶段分别执行的事件,且n个所述事件按照时间先后顺序排列,所述事件用于指示所述第一虚拟角色执行对应动作,n为大于1的整数;
10、所述预测单元,用于根据针对所述第一虚拟角色的历史事件序列进行预测,得到预测概率分布,所述预测概率分布包括预测所述第一虚拟角色在第n+1个阶段触发各个事件的概率;
11、所述采样单元,用于基于所述预测概率分布进行采样,得到目标事件,所述目标事件为所述第一虚拟角色在第n+1个阶段触发的多个事件中的一个事件;
12、所述控制单元,用于根据所述目标事件,控制所述第一虚拟角色执行所述目标事件对应的动作。
13、另一方面,本申请实施例提供一种计算机设备,所述计算机设备包括处理器以及存储器:
14、所述存储器用于存储计算机程序,并将所述计算机程序传输给所述处理器;
15、所述处理器用于根据所述计算机程序中的指令执行上述方面所述的方法。
16、另一方面,本申请实施例提供了一种计算机可读存储介质,所述计算机可读存储介质用于存储计算机程序,所述计算机程序用于执行上述方面所述的方法。
17、另一方面,本申请实施例提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述方面所述的方法。
18、由上述技术方案可以看出,获取针对第一虚拟角色的历史事件序列,历史事件序列包括在n个历史阶段分别执行的事件,即指示第一虚拟角色执行对应动作,且n个事件按照时间先后顺序排列。根据针对第一虚拟角色的历史事件序列进行预测,得到预测概率分布,即预测得到的第n+1个阶段触发各个事件的概率。对预测概率分布进行采样,得到目标事件,根据目标事件,控制第一虚拟角色执行目标事件对应的动作。
19、由此,相比于仅预测得到一个控制方式,本申请通过预测得到多个事件以及触发各个事件的概率,即第一虚拟角色可能会执行的事件均会被预测得到。而且针对预测概率分布进行采样得到的目标事件是随机的,使得针对同一游戏环境多次采样可能会得到不同的事件,从而增加第一虚拟角色执行动作的多样性,提高了虚拟角色控制的拟人程度。而且,结合历史事件序列进行预测,使得预测过程可以具有时序感知,使得第n+1个阶段的事件与前n个阶段的事件之间的一致性较高,提高了虚拟角色控制的拟人程度。故此,通过提高控制虚拟角色的多样性和一致性,提高用户体验感。
技术特征:
1.一种虚拟角色的控制方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述根据针对所述第一虚拟角色的历史事件序列进行预测,得到预测概率分布,包括:
3.根据权利要求2所述的方法,其特征在于,所述根据虚拟资源值最大化,以及所述训练概率分布和所述第一标签之间差异最小化的训练方向,调整所述初始预测模型的模型参数,得到所述预测模型,包括:
4.根据权利要求2所述的方法,其特征在于,所述根据虚拟资源值最大化,以及所述训练概率分布和所述第一标签之间差异最小化的训练方向,调整所述初始预测模型的模型参数,得到所述预测模型,包括:
5.根据权利要求2-4任意一项所述的方法,其特征在于,所述训练事件序列包括的m个事件的多样性大于预设多样性阈值。
6.根据权利要求2-4任意一项所述的方法,其特征在于,所述预测模型为生成式模型。
7.根据权利要求1所述的方法,其特征在于,若虚拟场景包括属于多个阵营的虚拟角色,所述第一虚拟角色为多个所述虚拟角色中的一个所述虚拟角色,则所述方法还包括:
8.根据权利要求1所述的方法,其特征在于,若所述事件用于指示所述第一虚拟角色向对应位置移动,则所述方法还包括:
9.根据权利要求1所述的方法,其特征在于,若所述事件用于指示所述第一虚拟角色移动至对应位置执行对应任务,则所述方法还包括:
10.根据权利要求9所述的方法,其特征在于,所述根据所述目标事件,控制所述第一虚拟角色执行所述目标事件对应的动作,包括:
11.根据权利要求1所述的方法,其特征在于,若所述事件用于指示所述第一虚拟角色移动至对应位置通过释放对应虚拟技能执行对应任务,则所述方法还包括:
12.一种虚拟角色的控制装置,其特征在于,所述装置包括:获取单元、预测单元、采样单元和控制单元;
13.一种计算机设备,其特征在于,所述计算机设备包括处理器以及存储器:
14.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质用于存储计算机程序,所述计算机程序用于执行权利要求1-11中任意一项所述的方法。
15.一种包括计算机程序的计算机程序产品,其特征在于,当其在计算机设备上运行时,使得所述计算机设备执行权利要求1-11中任意一项所述的方法。
技术总结
本申请实施例公开了一种虚拟角色的控制方法和相关装置,可应用机器学习、预训练模型技术等技术领域,获取针对第一虚拟角色的历史事件序列,历史事件序列包括在n个历史阶段分别执行的事件,即指示第一虚拟角色执行对应动作,且n个事件按照时间先后顺序排列。根据针对第一虚拟角色的历史事件序列进行预测,得到预测概率分布,即预测得到的第n+1个阶段触发各个事件的概率。对预测概率分布进行采样,得到目标事件,根据目标事件,控制第一虚拟角色执行目标事件对应的动作。由此,通过预测和采样结合,以及结合历史事件序列进行预测,使得预测过程具有时序感知,能够提高控制虚拟角色的多样性和一致性,提高用户体验感。
技术研发人员:俞涛,王亮,付强
受保护的技术使用者:腾讯科技(深圳)有限公司
技术研发日:
技术公布日:2024/4/22
- 还没有人留言评论。精彩留言会获得点赞!