一种K12阶段数据处理及学生学习情况的智能诊断方法与流程
本发明涉及一种诊断方法,具体是一种K12阶段数据处理及学生学习情况的智能诊断方法。
背景技术:
处于小学、初中、高中阶段的学生,很多都知道自己学的不好,但是并不清楚哪一部分学的不好,以及不好到什么程度,现有的技术方案,只是以帮助学生课后答疑,都是集中解决学生课后作业不会做,通过扫描拍照,解决学生课后作业的问题。学生做练习的目的,是巩固所学知识的同时检验知识掌握情况。但是,学生直接得到解题过程,并不能有效的帮助学生学好,反而容易养成学生不动脑筋、抄作业的坏习惯,指标不治本的同时,失去学生做练习的意义。
技术实现要素:
本发明的目的在于提供一种针对性强、简单可靠的学生学习情况的智能诊断方法,在以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
一种学生学习情况的智能诊断方法,具体步骤如下:
(1)将学生在K12阶段的题目均设置解答思路、详细解答过程,及标签;
(2)学生搜索题目后,再根据学生不会做的题目,对题目的标签经行分析;
(3)进行个性化分析,基于某一个学生所搜题目进行统计,得到该学生某一个章节中各个知识点的学习情况;
(4)进行群体分析,针对一个特定群体的学生所搜题目情况进行分析,得到这一群体各章节中各个知识点的学习情况。
作为本发明进一步的方案:所述K12阶段的题目的数目为8000-9000万道。
作为本发明进一步的方案:所述标签包括该题所属的年级、章节、该题所包含的知识点、所用到的解题方法以及该题的难度系数。
作为本发明进一步的方案:所述的知识点包括了解点、理解点、重点和难点。
作为本发明再进一步的方案:所述的特定群体为一个班级或一个年级,或一个区域。
与现有技术相比,本发明的有益效果是:
本发明为每个题目设置一个标签,以标签为基本素材,对学生进行大数据分析,可以很快的检测出学生某一个章节、某一个知识点的掌握情况,为学生推荐针对性的学习方案,不仅能帮助学生解决课后作业,使K12阶段学生的所有知识点以及常见题目完全透明化理顺的基础上,不仅能帮助学生解决课后作业,可以针对性的帮助其学习,还可以大幅提高教师的教学效率。
附图说明
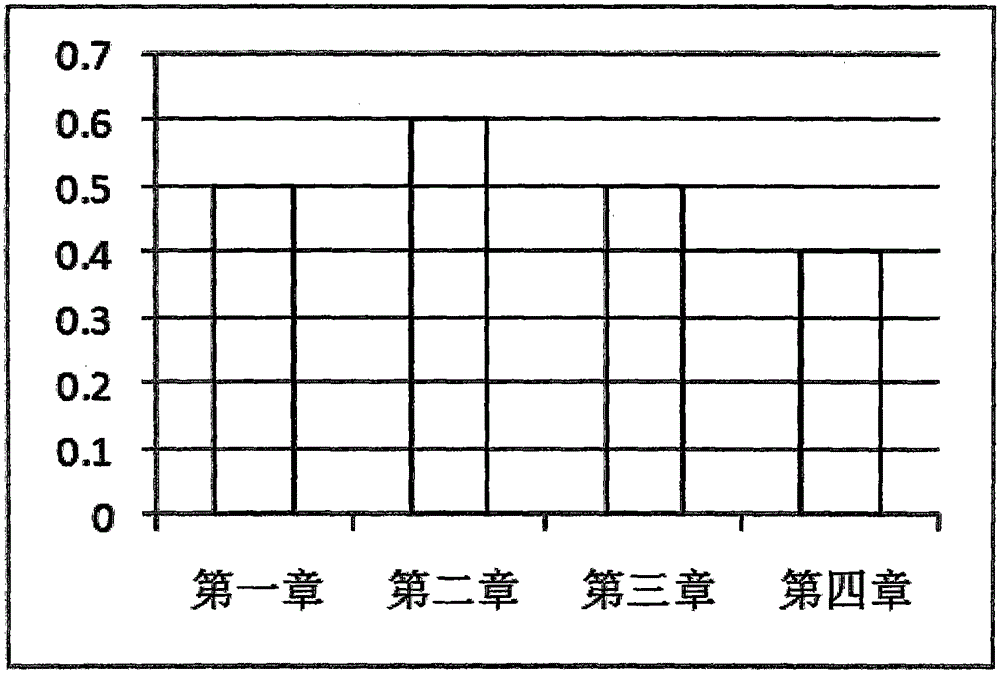
图1为本发明中进行个性化分析时的示意图之一。
图2为本发明中进行个性化分析时的示意图之二。
图3为本发明中进行群体分析时的示意图之一。
图4为本发明中进行群体分析时的示意图之二。
具体实施方式
下面结合具体实施方式对本专利的技术方案作进一步详细地说明。
实施例1
请参阅图1-4,本发明实施例中,一种K12阶段数据处理及学生学习情况的智能诊断方法,具体步骤如下:
(1)将学生在K12阶段的题目均设置解答思路、详细解答过程,及标签;所述K12阶段的题目的数目为8000万道左右,所述标签包括该题所属的年级、章节、该题所包含的知识点、所用到的解题方法以及该题的难度系数,所述的知识点包括了解点、理解点、重点和难点,这样以来,K12阶段的海量题目就会变的透明无比,还可以根据学生所搜题目统计学生知识掌握情况,也可以查询所有包含某一个知识点的所有题目;
(2)学生搜索题目后,再根据学生不会做的题目,对题目的标签进行分析;
(3)进行个性化分析,基于某一个学生所搜题目进行统计,得到该学生某一个章节 中各个知识点的学习情况;学生所搜题中,每一章中各个考点所占的比例,结合该章节重点、难点考点,如图1所示,可以分析出学生该章中哪个知识点没有学好,如图2所示,亦可以分析出该学生某一册书,各个章节的学习情况,该学生的第四章所搜的题目难度系数最小,题目最简单,说明该学生第四章掌握的比较差;
(4)进行群体分析,针对一个特定群体的学生所搜题目情况进行分析;所述的特定群体为一个班级或一个年级;如图3所示,高一(2)班数学必修第一章基于考点的统计,统计该班级中,这一章各知识点所占的比例,结合该章节重点、难点考点可以分析出这个班级的学生哪个知识点掌握的相对较差,把统计结果反馈给任课教师,如图4所示,亦可以分析出高一(2)班这一册书的整体学习情况,在这一本书中,高一(2)班的第三章所搜的题目难度系数最小,题目最简单,说明这个班级整体第三章整体学的稍差,把统计结果反馈给任课教师。
实施例2
请参阅图1-4,本发明实施例中,一种K12阶段数据处理及学生学习情况的智能诊断方法,具体步骤如下:
(1)将学生在K12阶段的题目均设置解答思路、详细解答过程,及标签;所述K12阶段的题目的数目为8200万道左右,所述标签包括该题所属的年级、章节、该题所包含的知识点、所用到的解题方法以及该题的难度系数,所述的知识点包括了解点、理解点、重点和难点,这样以来,K12阶段的海量题目就会变的透明无比,还可以根据学生所搜题目统计学生知识掌握情况,也可以查询所有包含某一个知识点的所有题目;
(2)学生搜索题目后,再根据学生不会做的题目,对题目的标签经行分析;
(3)进行个性化分析,基于某一个学生所搜题目进行统计,得到该学生某一个章节中各个知识点的学习情况;学生所搜题中,每一章中各个考点所占的比例,结合该章节重点、难点考点,如图1所示,可以分析出学生该章中哪个知识点没有学好,如图2所示,亦可以分析出该学生某一册书,各个章节的学习情况,该学生的第四章所搜的题目难度系数最小,题目最简单,说明该学生第四章掌握的比较差;
(4)进行群体分析,针对一个特定群体的学生所搜题目情况进行分析;所述的特定群体为一个班级或一个年级;如图3所示,高一(2)班数学必修第一章基于考点的统计,统计该班级中,这一章各知识点所占的比例,结合该章节重点、难点考点可以分析出这个班级的学生哪个知识点掌握的相对较差,把统计结果反馈给任课教师,如图4所示,亦可以分析出高一(2)班这一册书的整体学习情况,在这一本书中,高一(2)班的第三章所搜的题目难度系数最小,题目最简单,说明这个班级整体第三章整体学的稍差,把统计结果反馈给任课教师。
实施例3
请参阅图1-4,本发明实施例中,一种K12阶段数据处理及学生学习情况的智能诊断方法,具体步骤如下:
(1)将学生在K12阶段的题目均设置解答思路、详细解答过程,及标签;所述K12阶段的题目的数目为8500万道左右,所述标签包括该题所属的年级、章节、该题所包含的知识点、所用到的解题方法以及该题的难度系数,所述的知识点包括了解点、理解点、重点和难点,这样以来,K12阶段的海量题目就会变的透明无比,还可以根据学生所搜题目统计学生知识掌握情况,也可以查询所有包含某一个知识点的所有题目;
(2)学生搜索题目后,再根据学生不会做的题目,对题目的标签经行分析;
(3)进行个性化分析,基于某一个学生所搜题目进行统计,得到该学生某一个章节中各个知识点的学习情况;学生所搜题中,每一章中各个考点所占的比例,结合该章节重点、难点考点,如图1所示,可以分析出学生该章中哪个知识点没有学好,如图2所示,亦可以分析出该学生某一册书,各个章节的学习情况,该学生的第四章所搜的题目难度系数最小,题目最简单,说明该学生第四章掌握的比较差;
(4)进行群体分析,针对一个特定群体的学生所搜题目情况进行分析;所述的特定群体为一个班级或一个年级;如图3所示,高一(2)班数学必修第一章基于考点的统计,统计该班级中,这一章各知识点所占的比例,结合该章节重点、难点考点可以分析出这个班级的学生哪个知识点掌握的相对较差,把统计结果反馈给任课教师,如图4所示,亦可 以分析出高一(2)班这一册书的整体学习情况,在这一本书中,高一(2)班的第三章所搜的题目难度系数最小,题目最简单,说明这个班级整体第三章整体学的稍差,把统计结果反馈给任课教师。
实施例4
请参阅图1-4,本发明实施例中,一种K12阶段数据处理及学生学习情况的智能诊断方法,具体步骤如下:
(1)将学生在K12阶段的题目均设置解答思路、详细解答过程,及标签;所述K12阶段的题目的数目为8800万道左右,所述标签包括该题所属的年级、章节、该题所包含的知识点、所用到的解题方法以及该题的难度系数,所述的知识点包括了解点、理解点、重点和难点,这样以来,K12阶段的海量题目就会变的透明无比,还可以根据学生所搜题目统计学生知识掌握情况,也可以查询所有包含某一个知识点的所有题目;
(2)学生搜索题目后,再根据学生不会做的题目,对题目的标签经行分析;
(3)进行个性化分析,基于某一个学生所搜题目进行统计,得到该学生某一个章节中各个知识点的学习情况;学生所搜题中,每一章中各个考点所占的比例,结合该章节重点、难点考点,如图1所示,可以分析出学生该章中哪个知识点没有学好,如图2所示,亦可以分析出该学生某一册书,各个章节的学习情况,该学生的第四章所搜的题目难度系数最小,题目最简单,说明该学生第四章掌握的比较差;
(4)进行群体分析,针对一个特定群体的学生所搜题目情况进行分析;所述的特定群体为一个班级或一个年级;如图3所示,高一(2)班数学必修第一章基于考点的统计,统计该班级中,这一章各知识点所占的比例,结合该章节重点、难点考点可以分析出这个班级的学生哪个知识点掌握的相对较差,把统计结果反馈给任课教师,如图4所示,亦可以分析出高一(2)班这一册书的整体学习情况,在这一本书中,高一(2)班的第三章所搜的题目难度系数最小,题目最简单,说明这个班级整体第三章整体学的稍差,把统计结果反馈给任课教师。
实施例5
请参阅图1-4,本发明实施例中,一种K12阶段数据处理及学生学习情况的智能诊断方法,具体步骤如下:
(1)将学生在K12阶段的题目均设置解答思路、详细解答过程,及标签;所述K12阶段的题目的数目为9000万道左右,所述标签包括该题所属的年级、章节、该题所包含的知识点、所用到的解题方法以及该题的难度系数,所述的知识点包括了解点、理解点、重点和难点,这样以来,K12阶段的海量题目就会变的透明无比,还可以根据学生所搜题目统计学生知识掌握情况,也可以查询所有包含某一个知识点的所有题目;
(2)学生搜索题目后,再根据学生不会做的题目,对题目的标签经行分析;
(3)进行个性化分析,基于某一个学生所搜题目进行统计,得到该学生某一个章节中各个知识点的学习情况;学生所搜题中,每一章中各个考点所占的比例,结合该章节重点、难点考点,如图1所示,可以分析出学生该章中哪个知识点没有学好,如图2所示,亦可以分析出该学生某一册书,各个章节的学习情况,该学生的第四章所搜的题目难度系数最小,题目最简单,说明该学生第四章掌握的比较差;
(4)进行群体分析,针对一个特定群体的学生所搜题目情况进行分析;所述的特定群体为一个班级或一个年级;如图3所示,高一(2)班数学必修第一章基于考点的统计,统计该班级中,这一章各知识点所占的比例,结合该章节重点、难点考点可以分析出这个班级的学生哪个知识点掌握的相对较差,把统计结果反馈给任课教师,如图4所示,亦可以分析出高一(2)班这一册书的整体学习情况,在这一本书中,高一(2)班的第三章所搜的题目难度系数最小,题目最简单,说明这个班级整体第三章整体学的稍差,把统计结果反馈给任课教师。
本发明为每个题目设置一个标签,以标签为基本素材,对学生经行大数据分析,可以很快的检测出学生某一个章节、某一个知识点的掌握情况,为学生推荐针对性的学习方案,不仅能帮助学生解决课后作业,使K12阶段学生的所有知识点以及常见题目完全透明化理顺的基础上,不仅能帮助学生解决课后作业,可以针对性的帮助其学习,还可以大幅提高教师的教学效率。
上面对本专利的较佳实施方式作了详细说明,但是本专利并不限于上述实施方式,在本领域的普通技术人员所具备的知识范围内,还可以在不脱离本专利宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!