基于视觉设备的语言学习方法及系统与流程
本发明涉及多媒体技术领域,特别涉及一种基于视觉设备的语言学习方法及系统。
背景技术:
随着多媒体技术的不断发展进步,教学的方式不再局限于实际中的学校和课堂,在虚拟的世界中,人们通过互联网利用视频或者文字的方式交流、传授思想的方式越来越常见。针对语言学习,语言本身的特点要求学习者不断地进行发音练习且对发音的准确性和时效性要求较高,传统的教学方式已然不能满足用户的需求;因此,越来越多的学习者选择利用互联网进行学习。而在实际的语言学习中,教学视频也因其便捷性,成为语言学习中必不可少的用于传递信息的媒介,且教学视频也因其直观性和高效性,受到了越来越多语言学习者的青睐。但目前尚未出现通过便捷的视觉设备播放教学视频,来进行语言学习的技术。
技术实现要素:
本发明提供一种基于视觉设备的语言学习方法及系统,用以通过智能的视觉设备来进行语言类交互操作。
本发明提供一种基于视觉设备的语言学习方法,其特征在于,所述语言学习方法包括:
基于教材内容和对应的视频素材,制作所述教材内容对应的教材视频;
将所述教材视频集成在具备语音交互功能的视觉设备上,供用户通过观看所述视觉设备播放的所述教材视频进行语言学习;
接收用户发出的语音内容,对所述语音内容进行语音识别;根据识别结果,进入语音识别纠错模式,或者进入智能交互式对话模式。
优选地,所述根据识别结果,进入语音识别纠错模式包括:
识别出用户发音错误时,提示用户发音错误并提示用户重新录入正确的发音;或者,播放错误发音所对应的正确发音,供用户学习;或者,提供多种回应方式供用户选择;
识别出用户发音正确时,回应用户发出的所述语音内容,并进入下一学习内容。
优选地,所述根据识别结果,进入智能交互式对话模式包括:
识别出用户的语音内容为基于预设场景的内容,则检索语音对话数据库,回应用户发出的所述语音内容;
识别出用户发音错误时,提供多种回应方式供用户选择,直至用户发音正确并进入下一对话。
优选地,所述基于教材内容和对应的视频素材,制作所述教材内容对应的教材视频,包括:
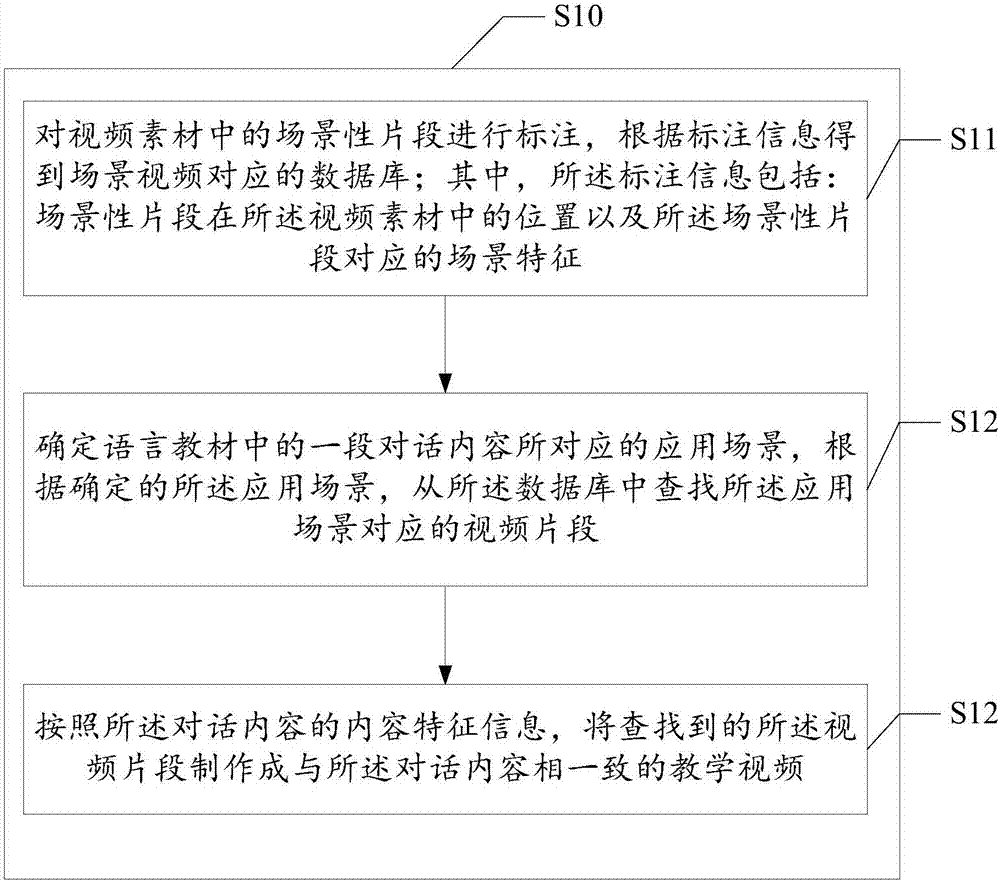
对视频素材中的场景性片段进行标注,根据标注信息得到场景视频对应的数据库;其中,所述标注信息包括:场景性片段在所述视频素材中的位置以及所述场景性片段对应的场景特征;
确定语言教材中的一段对话内容所对应的应用场景,根据确定的所述应用场景,从所述数据库中查找所述应用场景对应的视频片段;
按照所述对话内容的内容特征信息,将查找到的所述视频片段制作成与所述对话内容相一致的教学视频。
优选地,所述基于教材内容和对应的视频素材,制作所述教材内容对应的教材视频,包括:
对视频素材中对应一个场景的视频帧进行标注,根据标注信息得到视频帧对应的数据库;
确定语言教材中的一段对话内容所对应的应用场景,根据确定的所述应用场景,从所述场景视频数据库中查找所述应用场景对应的视频帧;
按照所述对话内容的发音特征信息,将查找到的所述视频帧改编为与所述对话内容相一致的教学视频。
本发明还提供了一种基于视觉设备的语言学习系统,所述语言学习系统包括:
视频制作模块,用于基于教材内容和对应的视频素材,制作所述教材内容对应的教材视频;
视频集成模块,用于将所述教材视频集成在具备语音交互功能的视觉设备上,供用户通过观看所述视觉设备播放的所述教材视频进行语言学习;
视频交互模块,用于接收用户发出的语音内容,对所述语音内容进行语音识别;根据识别结果,进入语音识别纠错模式,或者进入智能交互式对话模式。
优选地,所述视频交互模块还用于:
识别出用户发音错误时,提示用户发音错误并提示用户重新录入正确的发音;或者,播放错误发音所对应的正确发音,供用户学习;或者,提供多种回应方式供用户选择;
识别出用户发音正确时,回应用户发出的所述语音内容,并进入下一学习内容。
优选地,所述视频交互模块还用于:
识别出用户的语音内容为基于预设场景的内容,则检索语音对话数据库,回应用户发出的所述语音内容;
识别出用户发音错误时,提供多种回应方式供用户选择,直至用户发音正确并进入下一对话。
优选地,所述视频制作模块包括:
场景标注单元,用于对视频素材中的场景性片段进行标注,根据标注信息得到场景视频对应的数据库;其中,所述标注信息包括:场景性片段在所述视频素材中的位置以及所述场景性片段对应的场景特征;
片段查找单元,用于确定语言教材中的一段对话内容所对应的应用场景,根据确定的所述应用场景,从所述数据库中查找所述应用场景对应的视频片段;
片段制作单元,用于按照所述对话内容的内容特征信息,将查找到的所述视频片段制作成与所述对话内容相一致的教学视频。
优选地,所述视频制作模块包括:
帧标注单元,用于对视频素材中对应一个场景的视频帧进行标注,根据标注信息得到视频帧对应的数据库;
帧查找单元,用于确定语言教材中的一段对话内容所对应的应用场景,根据确定的所述应用场景,从所述场景视频数据库中查找所述应用场景对应的视频帧;
帧制作单元,用于按照所述对话内容的发音特征信息,将查找到的所述视频帧制作成与所述对话内容相一致的教学视频。
本发明基于视觉设备的语言学习方法及系统可以达到如下有益效果:
通过基于教材内容和对应的视频素材,制作所述教材内容对应的教材视频;将所述教材视频集成在具备语音交互功能的视觉设备上,供用户通过观看所述视觉设备播放的所述教材视频进行语言学习;接收用户发出的语音内容,对所述语音内容进行语音识别;根据识别结果,进入语音识别纠错模式,或者进入智能交互式对话模式;达到了通过智能的视觉设备来进行语言类交互操作的目的,用户可以采用视觉设备来进行自由、自主的语言学习,解决了传统语言学习中哑巴学习的短板,提高了语言学习的灵活性和便捷性,在一定程度上,也提高了用户体验。另外,本发明基于视觉设备的语言学习系统中采用视频片段或者视频帧来制作教材视频的方法,达到了教材视频制作多样性和灵活性的目的,丰富了教材视频的内容,提高了教材视频学习的趣味性,扩大了教材视频的应用范围。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书、权利要求书、以及附图中所指出的内容来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明基于视觉设备的语言学习方法的一种实施方式的流程示意图;
图2为图1所述实施例中步骤s10的一种实施方式的流程示意图;
图3为图1所述实施例中步骤s10的另一种实施方式的流程示意图;
图4为本发明基于视觉设备的语言学习系统的一种实施方式的结构框图;
图5为图4所述实施例中视频制作模块60的一种实施例方式的结构框图;
图6为图4所述实施例中视频制作模块60的另一种实施例方式的结构框图。
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
本发明提供了一种基于视觉设备的语言学习方法及系统,用以通过智能的视觉设备来进行语言类交互操作。如图1所示,本发明基于视觉设备的语言学习方法可以实施为如下描述的步骤s10-s30:
步骤s10、基于教材内容和对应的视频素材,制作所述教材内容对应的教材视频;
本发明实施例中,系统根据教材内容和对应的视频素材进行教材视频的制作时,可以根据现有的教材进行教材视频制作,也可以根据该教材视频的具体使用对象和应用场景针对性地编撰教材。在本发明一优选的实施例中,为了增强vr(virtualreality,虚拟现实)教学效果,教材内容主要以对话和口语练习为主,尤其是针对性改变目前语言教学中的短板:哑巴语言,能读不能说。
根据上述教材内容和对应的视频素材,可以设计不同的应用场景,设计的应用场景可以是真实的场景,例如餐馆点餐;也可以采用动画的形式进行趣味性展示。在教材视频制作时,可以根据教材内容,邀请真实的人物进行拍摄,例如邀请老师或者演员出演教材内容角色,进行实景拍摄或者虚拟背景拍摄;也可以根据教材内容,利用动画的形式作为场景进行拍摄,并采用真实的人物进行配音;动画虚拟拍摄的这种制作方式,由于动画形式的场景比较丰富,卡通、现实、幻想均能满足拍摄需求,因此,这种动画虚拟拍摄的方式可以根据不同年龄段的用户的兴趣爱好为依据,来选取对应的动画素材及卡通素材。
步骤s20、将所述教材视频集成在具备语音交互功能的视觉设备上,供用户通过观看所述视觉设备播放的所述教材视频进行语言学习;
制作完成对应的教材视频后,将该教材视频集成在对应的视觉设备上,该视觉设备包括但不限于:vr眼镜、多媒体眼镜等。本发明实施例中,上述制作的教材视频可以是独立系统,作为软件形式与视觉设备集成;该教材视频也可以作为模块化系统与视觉设备集成为视觉语言教学系统,例如,该教材视频作为模块化系统与vr眼镜集成为vr语言教学系统,并采用中央处理器拖带多套vr硬件,进行一对多教学模式,当然上述模式也可以是一对一教学,即一个用户使用一个vr设备进行单独学习。在实际的应用中,上述教材视频集成在视觉设备上的同时,由于需要与用户进行互动式教学,因此,该视觉设备同样需要集成语音系统,例如,集成麦克风等语音录入系统。用户通过观看自身所选择的上述视觉设备上播放的教材视频即可进行对应的语言学习。
步骤s30、接收用户发出的语音内容,对所述语音内容进行语音识别;根据识别结果,进入语音识别纠错模式,或者进入智能交互式对话模式。
本发明实施例中,系统支持两种学习模式,一种是语音识别纠错模式,比如,用户利用集成教材视频的视觉设备进行语音学习;另一种是智能交互式对话模式,比如,用户与集成教材视频的视觉设备进行智能性互动对话;当系统接收用户发出的语音内容,对用户输入的语音内容进行语音识别;根据识别结果,系统选择进行语音识别纠错模式,还是进行智能交互式对话模式。
在本发明一优选的实施例中,系统根据识别结果,进入智能交互式对话模式包括:
若系统识别出用户发音错误时,提示用户发音错误并提示用户重新录入正确的发音;或者,播放错误发音所对应的正确发音,供用户学习;或者,提供多种回应方式供用户选择,比如,系统回应“您说的什么意思”、“您说什么”、“您是不是想说~~”等等;识别出用户发音正确时,回应用户发出的所述语音内容,并进入下一学习内容。系统回应用户时,自动选择预先录入的多种对话语音,并随机抽取其中的对话语句,直至用户发音正确并系统接受。
例如,系统选择进入语音识别纠错模式,依托教材视频但不偏离教材视频,当用户出现发音错误时,系统能够迅速识别并提出相应的问题,主动让用户纠正发音错误,或者引导用户发出正确读音,然后进行下一段对话场景。
在本发明一优选的实施例中,系统根据识别结果,进入智能交互式对话模式包括:
若系统识别出用户的语音内容为基于预设场景的内容,则检索语音对话数据库,回应用户发出的所述语音内容;识别出用户发音错误时,提供多种回应方式供用户选择,直至用户发音正确并进入下一对话。
例如,系统选择进入智能交互式对话模式,相对主要依托某一具体的应用场景,比如问路、点餐等;例如,用户就场景内容提出问题或者对话内容,系统接收用户录入的音频信息,解析出用户录入的对话内容并给出相应答案,供用户参考。本发明实施例中,系统预先录入标准发音的对话库,系统回应用户录入的音频信息时,可以利用上述音频信息对应的关键字在对话库中检索最接近的对话内容并给予回应,直至用户结束本次对话。
在一具体的应用场景中,用户相对依托某一场景例如餐馆,参照对话库中的语句,用户随机开始与系统的对话。系统对话库分为多个单元模块,每个单元模块对应一个具体的应用场景,例如餐厅、车站、机场等;上述各个单元模块相对独立又互相关联。比如,在具体的使用过程中,张三去了泰国旅游,不懂泰文,在泰国饭店中点餐时,张三可以佩戴vr设备,在vr系统中选择泰国、饭店这一应用场景,边切身体验泰国饭店、边根据vr设备的提示完成用泰文点餐的过程。从而完成在实际发生的场景下,完成语言的应用和学习,使得用户的学习能力更快速,并且及时解决用户的语言障碍问题。又比如,在餐馆用餐时,使用与餐馆点餐相关的语句,系统默认场景为餐馆,但当用户在餐馆问路并提出问路的语句时,系统可以选择继续使用餐馆场景,也可以随机进入街景背景;在条件允许的情况下(比如,系统有权限获取当前位置信息并访问关联的地图软件),系统可以关联地图软件,并直接显示用户所问地点的地图和街景,甚至可以直接规划由用户当前位置达到目的位置的路径导航。
在智能交互式对话模式中,若系统识别出用户发音错误时,提供多种回应方式供用户选择,直至用户发音正确并进入下一对话。比如,系统回应“您说的什么意思”、“您说什么”、“您是不是想说~~”等等;识别出用户发音正确时,回应用户发出的所述语音内容,并进入下一句对话。系统回应用户时,自动选择预先录入的多种对话模式,并随机抽取其中的对话语句,直至用户发音正确并系统接受。
本发明基于视觉设备的语言学习方法可以达到如下有益效果:通过基于教材内容和对应的视频素材,制作所述教材内容对应的教材视频;将所述教材视频集成在具备语音交互功能的视觉设备上,供用户通过观看所述视觉设备播放的所述教材视频进行语言学习;接收用户发出的语音内容,对所述语音内容进行语音识别;根据识别结果,进入语音识别纠错模式,或者进入智能交互式对话模式;达到了通过智能的视觉设备来进行语言类交互操作的目的,用户可以采用视觉设备来进行自由、自主的语言学习,解决了传统语言学习中哑巴学习的短板,提高了语言学习的灵活性和便捷性,在一定程度上,也提高了用户体验。
在本发明一优选的实施例中,如图2所示,本发明基于视觉设备的语言学习方法图1所述实施例中,“步骤s10、基于教材内容和对应的视频素材,制作所述教材内容对应的教材视频”可以实施为如下描述的步骤s11-s13:
步骤s11、对视频素材中的场景性片段进行标注,根据标注信息得到场景视频对应的数据库;其中,所述标注信息包括:场景性片段在所述视频素材中的位置以及所述场景性片段对应的场景特征;
步骤s12、确定语言教材中的一段对话内容所对应的应用场景,根据确定的所述应用场景,从所述数据库中查找所述应用场景对应的视频片段;
步骤s13、按照所述对话内容的内容特征信息,将查找到的所述视频片段制作成与所述对话内容相一致的教学视频。
在本发明一优选的实施例中,系统按照所述对话内容的内容特征信息,将查找到的所述视频片段制作成与所述对话内容相一致的教学视频,可以实施为:
根据所述对话内容的内容特征信息,获取所述对话内容中一个特定对象所对应的对话条数、以及每条对话所分别对应的对话时长;
从查找到的所述视频片段中找出与所述对话内容相同的所述特定对象,并获取所述视频片段中所述特定对象对应的说话时长;
根据所述对话内容中特定对象的说话条数及说话时长,对所述视频片段中特定对象的说话内容进行截取和/或拼接,得到与所述对话内容中每条对话对应的视频子片段,且每个视频子片段的时长与其相对应的每条对话的对话时长相等。
在一具体的应用场景中,系统预先为每部电影、电视剧、mv等视频中的场景性片段(比如,在饭店中点餐的场景、在商场中买东西的场景、在酒店前台订房间的场景)进行标注,例如某个电影从第1000帧到10000帧都是饭店中点餐的场景,该段视频段中只显示出一个饭店服务员为顾客点餐提供服务的一段画面(这个片段中只有服务员,没有顾客,这个片段中服务员只说了一句话);则可为该片段进行标注,标注信息包括该片段在电影中的位置(从第几帧到第几帧)、该片段对应的场景(饭店点餐)。对多部视频进行上述标注操作,形成场景视频片段的数据库。编撰教材视频时,先确定出教材中一段对话x的应用场景,然后在上述数据库中查找该段对话x的应用场景所对应的视频片段y。将视频片段y按照该段对话x的特点进行制作。还是以饭店点餐为例,制作方式例如为:分析对话x中由服务员说的话的句数,例如有m句,每句记为i(i=1,2,,,m);分析每句话的时长,分别记为ti;分析视频片段中服务员说话的时长t;截取或者拼接该段视频中服务员说话的部分帧,使得最后能根据该段视频,得到对话x中每句话对应的视频子段,每段视频子段的时长与对话x中相应的那句话的时长是相等的。也可以理解为,例如对话x中有一句“请问您点什么餐?”,时长为2秒,则相应的视频子段中服务员的嘴处于说话状态的时长也为2秒。
在本发明一优选的实施例中,如图3所示,本发明基于视觉设备的语言学习方法图1所述实施例中,“步骤s10、基于教材内容和对应的视频素材,制作所述教材内容对应的教材视频”可以实施为如下描述的步骤s14-s16:
步骤s14、对视频素材中对应一个场景的视频帧进行标注,根据标注信息得到视频帧对应的数据库;
步骤s15、确定语言教材中的一段对话内容所对应的应用场景,根据确定的所述应用场景,从所述场景视频数据库中查找所述应用场景对应的视频帧;
步骤s16、按照所述对话内容的发音特征信息,将查找到的所述视频帧改编为与所述对话内容相一致的教学视频。
在本发明一优选的实施例中,系统按照所述对话内容的发音特征信息,将查找到的所述视频帧改编为与所述对话内容相一致的教学视频,可以实施为:
根据所述对话内容的发音特征信息,获取所述对话内容中一个特定对象所对应的每个词语的发音特征;
从查找到的所述视频帧中找出与所述对话内容相同的所述特定对象,并识别所述视频帧中所述特定对象的嘴型特征;
根据所述对话内容中特定对象对应的每个词语的发音特征,对所述视频帧中特定对象的嘴型特征进行模拟制作,得到与所述对话内容中每个特定对象对应的视频子片段,且每个视频子片段中特定对象的嘴型特征与其相对应的所述对话内容中每个词语的发音特征映射的嘴型特征相一致。
在一具体的应用场景中,系统预先从每部电影、电视剧、mv等视频中调取一个帧,该个帧对应一个场景,例如对于饭店点餐场景来说,这一帧里显示了饭店的场面、和一个服务员。同样为这样的每个帧进行标注,例如某个电影从第1000帧到10000帧都是饭店中点餐的场景,该段视频段中只显示出一个饭店服务员为顾客点餐提供服务的一段画面(这个片段中只有服务员,没有顾客,这个片段中服务员只说了一句话);则可为该片段进行标注,标注信息包括该片段在电影中的位置(从第几帧到第几帧)、该片段对应的场景(饭店点餐)。对多部视频进行上述标注操作,形成场景视频片段的数据库。编撰教材视频时,先确定出教材中一段对话x的应用场景,然后在上述数据库中查找该段对话x的应用场景所对应的视频帧z。将视频帧z按照该段对话x的特点进行制作。还是以饭店点餐为例,制作方式例如为:识别视频帧z中的服务员的嘴部形象;按照对话x中每个词语的发音,对嘴部形象的张合状态进行改变,最终拼接成与对话x中服务员所说的话的嘴部张合状态一致的视频片段,作为对话x的教学视频。
本发明基于视觉设备的语言学习方法中采用视频片段或者视频帧来制作教材视频的方法,达到了教材视频制作多样性和灵活性的目的,丰富了教材视频的内容,提高了教材视频学习的趣味性,扩大了教材视频的应用范围。
基于图1、图2和图3所述实施例描述的一种基于视觉设备的语言学习方法,本发明还提供了一种基于视觉设备的语言学习系统,对应于图1、图2和图3所述实施例的描述,如图4所示,本发明一种基于视觉设备的语言学习系统包括:
视频制作模块60,用于基于教材内容和对应的视频素材,制作所述教材内容对应的教材视频;
视频集成模块70,用于将所述教材视频集成在具备语音交互功能的视觉设备上,供用户通过观看所述视觉设备播放的所述教材视频进行语言学习;
视频交互模块80,用于接收用户发出的语音内容,对所述语音内容进行语音识别;根据识别结果,进入语音识别纠错模式,或者进入智能交互式对话模式。
在本发明一优选的实施例中,所述视频交互模块80还用于:
识别出用户发音错误时,提示用户发音错误并提示用户重新录入正确的发音;或者,播放错误发音所对应的正确发音,供用户学习;或者,提供多种回应方式供用户选择;
识别出用户发音正确时,回应用户发出的所述语音内容,并进入下一学习内容。
在本发明一优选的实施例中,所述视频交互模块80还用于:
识别出用户的语音内容为基于预设场景的内容,则检索语音对话数据库,回应用户发出的所述语音内容;
识别出用户发音错误时,提供多种回应方式供用户选择,直至用户发音正确并进入下一对话。
在本发明一优选的实施例中,如图5所示,本发明基于视觉设备的语言学习系统中,图4所述实施例中的所述视频制作模块60包括:
场景标注单元610,用于对视频素材中的场景性片段进行标注,根据标注信息得到场景视频对应的数据库;其中,所述标注信息包括:场景性片段在所述视频素材中的位置以及所述场景性片段对应的场景特征;
片段查找单元620,用于确定语言教材中的一段对话内容所对应的应用场景,根据确定的所述应用场景,从所述数据库中查找所述应用场景对应的视频片段;
片段制作单元630,用于按照所述对话内容的内容特征信息,将查找到的所述视频片段制作成与所述对话内容相一致的教学视频。
在本发明一优选的实施例中,如图6所示,本发明基于视觉设备的语言学习系统中,图4所述实施例中的所述视频制作模块60包括:
帧标注单元640,用于对视频素材中对应一个场景的视频帧进行标注,根据标注信息得到视频帧对应的数据库;
帧查找单元650,用于确定语言教材中的一段对话内容所对应的应用场景,根据确定的所述应用场景,从所述场景视频数据库中查找所述应用场景对应的视频帧;
帧制作单元660,用于按照所述对话内容的发音特征信息,将查找到的所述视频帧制作成与所述对话内容相一致的教学视频。
本发明基于视觉设备的语言学习系统通过基于教材内容和对应的视频素材,制作所述教材内容对应的教材视频;将所述教材视频集成在具备语音交互功能的视觉设备上,供用户通过观看所述视觉设备播放的所述教材视频进行语言学习;接收用户发出的语音内容,对所述语音内容进行语音识别;根据识别结果,进入语音识别纠错模式,或者进入智能交互式对话模式;达到了通过智能的视觉设备来进行语言类交互操作的目的,用户可以采用视觉设备来进行自由、自主的语言学习,解决了传统语言学习中哑巴学习的短板,提高了语言学习的灵活性和便捷性,在一定程度上,也提高了用户体验。另外,本发明基于视觉设备的语言学习系统中采用视频片段或者视频帧来制作教材视频的方法,达到了教材视频制作多样性和灵活性的目的,丰富了教材视频的内容,提高了教材视频学习的趣味性,扩大了教材视频的应用范围。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!