一种可图像识别的骨传导盲人眼镜的制作方法
本发明涉及眼镜的技术领域,尤其是一种可图像识别的骨传导盲人眼镜。
背景技术:
眼镜,是用来帮助视力有缺陷的人群的一种工具。传统眼镜只能起到普通的眼镜作用。在高科技发展的当今社会,普通眼镜远远不能满足人们的需求;后来科研人员经过不断的研究发明了各种智能眼镜,其功能仅仅具备拍照、录像、上网、收发邮件、蓝牙接听电话等功能中的一种或多种;但对于盲人或视力障碍的人群来说,他们看不见眼前的东西,他们需要一副可以帮他们看到眼前事物的眼镜;由于市面上已有的智能眼镜主要针对视力正常人,不具备帮助盲人获取眼前信息的功能,因此我们提出可图像识别的盲人眼镜,可实现将眼前图像转化为语音,并通过骨传导的方式传达给盲人。
技术实现要素:
本发明要解决的技术问题是:为了解决上述背景技术中的现有技术存在的问题,提供一种可图像识别的骨传导盲人眼镜,结构简单,可以辅助盲人进行眼前景象图像识别,识别率达到90%以上,方便了盲人的使用。
本发明解决其技术问题所采用的技术方案是:一种可图像识别的骨传导盲人眼镜,包括眼镜壳、第一镜腿、第二镜腿、挂耳和鼻托,所述眼镜壳中部采用鼻托连接,所述眼镜壳的两端分别铰接第一镜腿和第二镜腿,所述第一镜腿和第二镜腿尾端均固定设置挂耳,还包括硬件电路板、骨传导耳机、电池和摄像头,所述摄像头嵌入式设置在鼻托中,所述第一镜腿内嵌入式设置硬件电路板,所述第二镜腿内嵌入式设置电池,所述挂耳与第一镜腿连接处的下端和挂耳与第二镜腿连接处的下端均连接骨传导耳机。
进一步地说明,所述电池与硬件电路板、骨传导耳机、摄像头之间均通过电性并联连接。
进一步地说明,所述摄像头为高清摄像头。
进一步地说明,所述硬件电路板为smart-glass-board。
一种图像识别的骨传导盲人眼镜的识别方法,包括如下步骤:s1、使用摄像头拍摄图片;s2、对图片进行预处理;s3、文字识别首先加载文字识别模型,然后利用人工智能框架tensorflow,进行文字识别,将其生成文字;s4、后处理对词组方式进行自动匹配;文字横竖方向进行分析处理;版面恢复;s5、语音输出使用tts技术将文字转化成音频文件利用骨传导耳机进行播报。
进一步地说明,所述步骤s2中的对图片进行预处理的方法为s11、使用wiener维纳声波对图片进行降噪;s22、图片轮廓的锐化;s33、使用mser进行图片文字区域检测;s44、利用透视变换原理对倾斜、扭曲的文字进行矫正;s55、基于改进的连通域分割法进行版面分析;s66、使用漫水填充法过滤密集点区域;s77、基于haar特征的伪区域去除;s88、利用惯性滴水法对图片字符进行分割;s99、图片二值化。
本发明的有益效果是:结构简单,可以辅助盲人进行眼前景象图像识别,识别率达到90%以上,方便了盲人的使用。
附图说明
下面结合附图和实施例对本发明进一步说明。
图1是本发明的结构示意图。
图2是本发明部件的连接示意图。
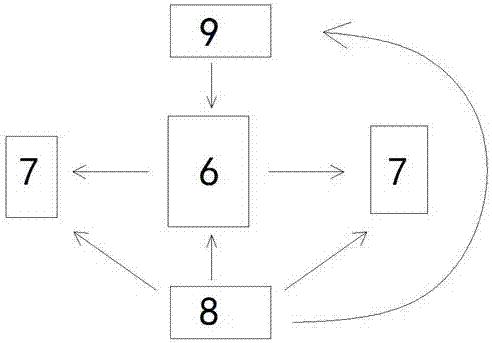
图中:1、眼镜壳,2、第一镜腿,3、第二镜腿,4、挂耳,5、鼻托,6、硬件电路板,7、骨传导耳机,8、电池,9、摄像头。
具体实施方式
现在结合附图对本发明作进一步详细的说明。这些附图均为简化的示意图,仅以示意方式说明本发明的基本结构,因此其仅显示与本发明有关的构成。
在
本技术:
中,硬件电路板为smart-glass-board,作用是通过摄像头拍摄图片,并将图片传输给中央处理器处理并进行图像识别,最后输出识别结果,并把识别结果通过骨传导耳机播报;摄像头9为高清摄像头,可以用来进行图像的拍摄;骨传导耳机7是用来进行语音的播报;电池8对硬件电路板6、骨传导耳机7、摄像头9提供电源。
在本申请中,人工智能框架tensorflow、mser、漫水填充法、惯性滴水法、tts技术均为本领域技术领域的常规实验方法。
如图1和图2所示的是一种可图像识别的骨传导盲人眼镜,包括眼镜壳1、第一镜腿2、第二镜腿3、挂耳4和鼻托5,眼镜壳1中部采用鼻托5连接,眼镜壳1的两端分别铰接第一镜腿2和第二镜腿3,第一镜腿2和第二镜腿3尾端均固定设置挂耳4,还包括硬件电路板6、骨传导耳机7、电池8和摄像头9,摄像头9嵌入式设置在鼻托5中,第一镜腿2内嵌入式设置硬件电路板6,第二镜腿3内嵌入式设置电池8,挂耳4与第一镜腿2连接处的下端和挂耳4与第二镜腿3连接处的下端均连接骨传导耳机7。
其中,电池8与硬件电路板6、骨传导耳机7、摄像头9之间均通过电性并联连接。摄像头9为高清摄像头。硬件电路板6为smart-glass-board。
一种可图像识别的骨传导盲人眼镜的识别方法,包括如下步骤:s1、使用摄像头9拍摄图片;s2、对图片进行预处理;s3、文字识别首先加载文字识别模型,然后利用人工智能框架tensorflow进行文字识别,将其生成文字;s4、后处理对词组方式进行自动匹配;文字横竖方向进行分析处理;版面恢复;s5、语音输出使用tts技术将文字转化成音频文件利用骨传导耳机7进行播报。
其中,步骤s2中的对图片进行预处理的方法为s11、使用wiener维纳声波对图片进行降噪;s22、图片轮廓的锐化;s33、使用mser进行图片文字区域检测;s44、利用透视变换原理对倾斜、扭曲的文字进行矫正;s55、基于改进的连通域分割法进行版面分析;s66、使用漫水填充法过滤密集点区域;s77、基于haar特征的伪区域去除;s88、利用惯性滴水法对图片字符进行分割;s99、图片二值化。
本发明产生的有益效果:盲人戴上眼镜可以对眼前景象进行图像识别,可以识别的事物包括:物品、文字、钱币、人脸;目前可识别的物品主要针对生活常见物品,如:杯子、椅子、凳子、公交车等,在训练样本数据足够丰富、光线良好情况下识别率准确率达到85%以上;文字识别主要有:公交站牌、街边门店门牌、餐牌、读书、看包,在光线良好的情况下,识别准确率达90%以上;钱币主要是识别人民币,在光线良好的情况下,识别准确率达95%以上;骨传导耳机的传导方式良好,声音可调节,每个骨传导配备3w功放,可满足盲人在户外实际使用场合。
以上述依据本发明的理想实施例为启示,通过上述的说明内容,相关工作人员完全可以在不偏离本项发明技术思想的范围内,进行多样的变更以及修改。本项发明的技术性范围并不局限于说明书上的内容,必须要根据权利要求范围来确定其技术性范围。
技术特征:
技术总结
本发明涉及眼镜的技术领域,尤其是一种可图像识别的骨传导盲人眼镜。其包括眼镜壳、第一镜腿、第二镜腿、挂耳和鼻托,所述眼镜壳中部采用鼻托连接,所述眼镜壳的两端分别铰接第一镜腿和第二镜腿,所述第一镜腿和第二镜腿尾端均固定设置挂耳,还包括硬件电路板、骨传导耳机、电池和摄像头,所述摄像头嵌入式设置在鼻托中,所述第一镜腿内嵌入式设置硬件电路板,所述第二镜腿内嵌入式设置电池,所述挂耳与第一镜腿连接处的下端和挂耳与第二镜腿连接处的下端均连接骨传导耳机。该可图像识别的骨传导盲人眼镜,结构简单,可以辅助盲人进行眼前景象图像识别,识别率达到90%以上,方便了盲人的使用。
技术研发人员:邝维威;林锴;张彬;梁镇武;曾祥沐
受保护的技术使用者:广州古拉思信息科技有限公司
技术研发日:2017.07.20
技术公布日:2017.12.01
- 还没有人留言评论。精彩留言会获得点赞!