基于深度学习的VR智能语音交互英语方法与流程
本发明属于智能学习技术领域,特别是涉及一种基于深度学习的vr智能语音交互英语方法。
背景技术:
国内的英语口语教学主要有以下几种方式:线下培训班、网上在线外教平台、英语教学视频、英语教学软件等等。而这几种方式,学生们在英语学习的过程中都面临着很多的问题,比如难以摆脱母语环境影响、学习兴趣低下、哑巴英语等。
线下培训班和网络在线外教平台中,真人外教教学质量良莠不齐,且价格单次较高,时间成本昂贵且无法随时随地的学习。普通英语多媒体教学类,也就是英语教学视频、英语教学软件等,对学员的对话语音识别正确率低,一般使用关键字识别,无语义识别;学习过程单调线性,每次对话内容固定机械;一般多媒体英语教学软件多为卡通2d场景,无法引起学员真实情境的感受;一般多媒体英语教学多为2d人物无面部表情,无法感受对话人情绪;一般多媒体英语教学多为2d人物,无法展现人物动作和肢体状态;传统多媒体英语教学多为2d画面,即使使用3d技术的高端教学软件也无沉浸感。
总结来说,国内真人口语教学价格高昂,质量无保证;智能平台教学,尚未完全智能化,教案死板无变化,教学质量低下;且目前国内尚未有同时使用ai、vr技术的智能英语口语训练。
技术实现要素:
本发明的目的在于提供基于深度学习的vr智能语音交互英语方法,通过逼真模拟3d真实环境,学习者可以随时随地进行学习,并且无限次数可重复,成本低;本平台逼真模拟各类情境、可适应职场英语、生活日常英语、旅游英语、专业英语等不同情境。
为解决上述技术问题,本发明是通过以下技术方案实现的:
本发明为基于深度学习的vr智能语音交互英语方法,包括如下步骤:
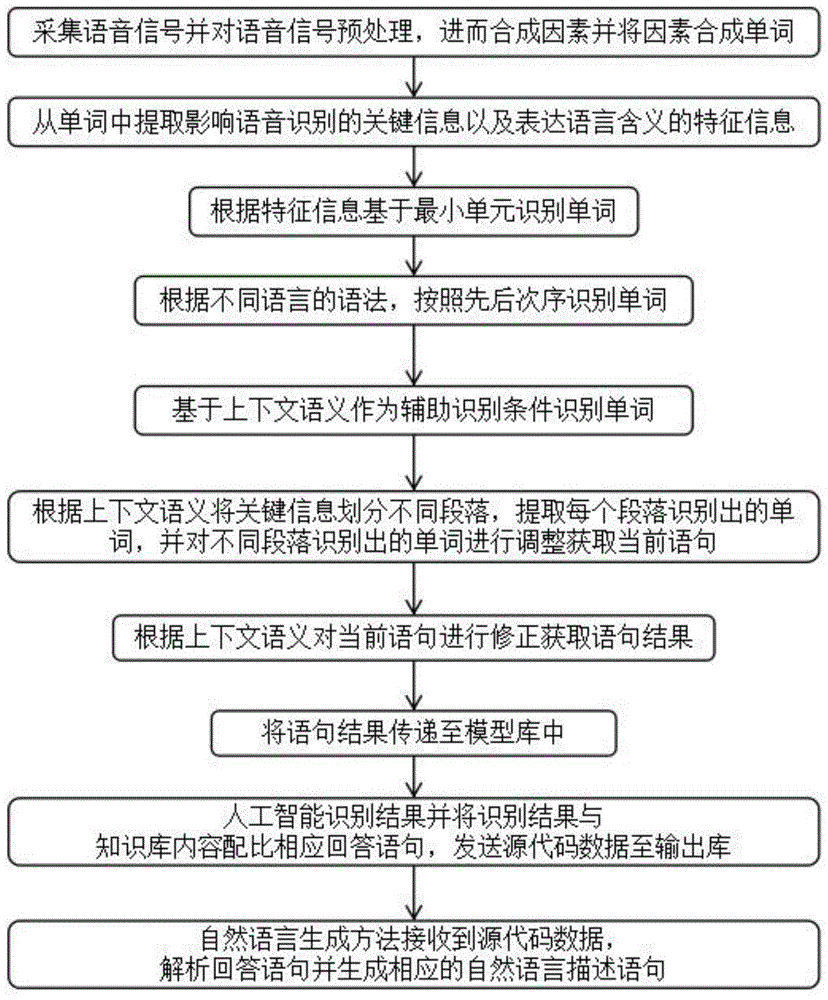
a00:采集语音信号并对语音信号预处理,进而合成因素并将因素合成单词;
a01:从所述单词中提取影响语音识别的关键信息以及表达语言含义的特征信息;
a02:根据所述特征信息基于最小单元识别单词;
a03:根据不同语言的语法,按照先后次序识别单词;
a04:基于上下文语义作为辅助识别条件识别单词;
a05:根据上下文语义将所述关键信息划分不同段落,提取每个段落识别出的单词,并对不同段落识别出的单词进行调整获取当前语句;
a06:根据上下文语义对当前语句进行修正获取语句结果;
a07:将所述语句结果传递至模型库中;
a08:人工智能识别结果并将识别结果与知识库内容配比相应回答语句,发送源代码数据至输出库;
a09:自然语言生成方法接收到源代码数据,解析回答语句并生成相应的自然语言描述语句。
优选地,a01中对语音信号预处理包括如下:
对所述语音信号进行采样、克服混叠滤波、去除部分由个体发音的差异和环境引起的噪声影响。
优选地,a01中合成因素并将因素合成单词包括如下:
对所述声音信号进行分析,用移动窗函数将声音信号分帧;再将得到的波形进行变换处理,将每一帧的波形变为一个多维向量;把帧识别成状态,使用隐马尔可夫模型建立状态网络,从所述状态网络中寻找与声音信号最匹配的路径,将状态合成音素进而将音素合成单词。
本发明具有以下有益效果:
1、本发明可根据不同人的语音无需提前训练计算机即可以非常高的准确率识别出对应语音的语句文字;可实现通过语音输入直接对语音进行文本转换;可实现中文和英文的智能语音识别,提高语音识别效率;
2、本发明通过语音或文字的输入智能分析语义,能结合上下文对语音/文字的含义做出正确分析和理解;系统支持中文和英文的语义识别,适用多语种、多语境识别,提高语音识别和语义理解的适用性;
3、本发明基于深度学习技术实现的智能对话;深度学习技术通过监督学习特定情境下的英语对白案例,分析获得不同对白输入条件下的不同输出结果,达到机器自主学习的目的,从而实现能接近真实人类的智能对话结果。
当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明的基于深度学习的vr智能语音交互英语方法的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
请参阅图1所示,本发明为基于深度学习的vr智能语音交互英语方法,包括:如下步骤:
a00:采集语音信号并对语音信号预处理,进而合成因素并将因素合成单词;
a01:从单词中提取影响语音识别的关键信息以及表达语言含义的特征信息;
a02:根据特征信息基于最小单元识别单词;
a03:根据不同语言的语法,按照先后次序识别单词;
a04:基于上下文语义作为辅助识别条件识别单词;
a05:根据上下文语义将关键信息划分不同段落,提取每个段落识别出的单词,并对不同段落识别出的单词进行调整获取当前语句;
a06:根据上下文语义对当前语句进行修正获取语句结果;
a07:将语句结果传递至模型库中;
a08:人工智能识别结果并将识别结果与知识库内容配比相应回答语句,发送源代码数据至输出库;
a09:自然语言生成方法接收到源代码数据,解析回答语句并生成相应的自然语言描述语句。
其中,a01中对语音信号预处理包括如下:
对语音信号进行采样、克服混叠滤波、去除部分由个体发音的差异和环境引起的噪声影响。
其中,a01中合成因素并将因素合成单词包括如下:
对声音信号进行分析,用移动窗函数将声音信号分帧;再将得到的波形进行变换处理,将每一帧的波形变为一个多维向量;把帧识别成状态,此处,将每一帧的波形变为一个多维向量,声音就成了一个12行(假设声学特征是12维)、n列的一个矩阵,称之为观察序列,这里n为总帧数;使用隐马尔可夫模型建立状态网络,从状态网络中寻找与声音信号最匹配的路径,将状态合成音素进而将音素合成单词;
单词的发音由音素构成;对英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的音素集,具体参见thecmupronouncingdictionary;汉语一般直接用全部声母和韵母作为音素集;
本发明应用vr技术打造极具真实感的沉浸式英语对话vr环境;使用智能语音技术对参训人员的英语对话进行智能识别;利用ai技术让对话的npc角色智能进行对话响应;采用逼真模拟3d真实环境,学习者可以随时随地进行学习,并且无限次数可重复,成本低;本平台逼真模拟各类情境、可适应职场英语、生活日常英语、旅游英语、专业英语等不同情境;
对整句进行语义识别,动态判别语义,根据识别的语义产生新的动态对话;深度学习支持,每次对话内容动态变化,学习者会认为是在和一个真实的人类进行英语对话;使用虚拟现实技术,逼真模拟各类真实英语对话情境和场景,视觉体验强烈,能产生深刻记忆;使用3d面部表情技术和语言智能表情技术,根据每一句英文句子的语义展现对应情绪和面部表情以及发音口型;使用3d动态动作技术可真实表达当前句子语义对应的人物动作和肢体状态;使用虚拟现实技术,学员完全沉浸在真实环境和场景中。
值得注意的是,上述系统实施例中,所包括的各个单元只是按照功能逻辑进行划分的,但并不局限于上述的划分,只要能够实现相应的功能即可;另外,各功能单元的具体名称也只是为了便于相互区分,并不用于限制本发明的保护范围。
另外,本领域普通技术人员可以理解实现上述各实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,相应的程序可以存储于一计算机可读取存储介质中。
以上公开的本发明优选实施例只是用于帮助阐述本发明。优选实施例并没有详尽叙述所有的细节,也不限制该发明仅为所述的具体实施方式。显然,根据本说明书的内容,可作很多的修改和变化。本说明书选取并具体描述这些实施例,是为了更好地解释本发明的原理和实际应用,从而使所属技术领域技术人员能很好地理解和利用本发明。本发明仅受权利要求书及其全部范围和等效物的限制。
- 还没有人留言评论。精彩留言会获得点赞!