一种基于SVM的医学检测指标重要性评价方法与流程
本发明涉及一种数据处理方法,尤其是涉及一种基于svm的医学检测指标重要性评价方法。
背景技术:
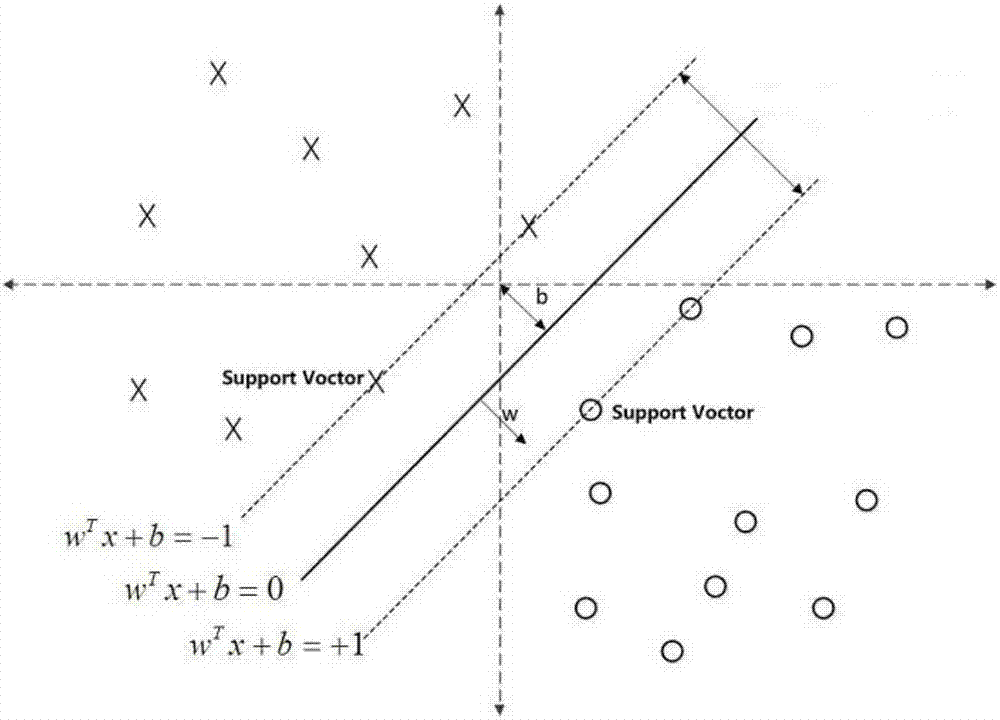
:在临床医学中,多年的门诊积累了大量患者的检测数据,然而这些检测数据种类多,数据量大,如何筛选出相关性较大的检测指标用于诊断,一直是医务人员非常关心的问题。如果利用这些检测数据发现检测数据内部及数据之间隐藏的规律,则可以提高诊断效率。医学数据的挖掘和处理重在从已知医学数据本身出发,能够提炼数据中的知识,总结医学专家的经验,是近年来医学信息领域颇受关注的研究方向。技术实现要素:本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于svm的医学检测指标重要性评价方法。本发明的目的可以通过以下技术方案来实现:一种基于svm的医学检测指标重要性评价方法,包括以下步骤:s1,获取多个样本的各项医学检测指标数据,所述的样本被分为至少两个类别;s2,将样本分为两部分,一部分作为标准训练集,另一部分作为测试集;s3,保留所有指标,对标准训练集建立支持向量机模型,支持向量机模型的输入为各项医学检测指标数据,输出为样本的类别,并用测试集检验该支持向量机模型的分类准确率;s4,使标准训练集仅缺失其中一个指标,建立支持对应的支持向量机模型,并用测试集检验该支持向量机模型的分类准确率,计算该分类准确率与步骤s3得到的分类准确率相比的下降值;s5,更换缺失的指标,重复步骤s4,直到遍历每个指标,利用分类准确率下降值评价对应的指标重要性,分类准确率下降值越大,则对应的指标重要性越大。所述的支持向量机为二分类支持向量机。所述的医学检测指标包括嗜酸性粒细胞占白细胞总数的百分比eos%(percentageofeosinophils)、第1秒用力呼气量fev1(forcedexpiratoryvolumein1second)在用力肺活量fvc(forcedvitalcapacity)中所占比例fev1/fvc(fev1/fvcratio)、最大用力呼气峰流量pef(peakexpiratoryflow)、呼出气体25%-75%肺容积平均流mmef75/25(maximalmid-expiratoryflow≥25%and≤75)和呼出气一氧化氮feno(fractionalexhalednitricoxide)。所述的样本被分为两类,为咳嗽患者和非咳嗽患者。所述的步骤s2中,采用gini系数作为样本的划分准则,gini系数的计算公式为其中n为类别总数,i为当前类别,用于保证抽取的医学检测数据训练样本与总样本的分布趋势相似。所述的步骤s2中,将样本的70%作为标准训练集。与现有技术相比,本发明具有以下优点:(1)采用已知分类的样本进行支持向量机模型训练和验证,采用先保留所有指标,然后分别删除某个指标的方法,验证缺失指标的支持向量机分类准确率,可平行比较得到指标重要程度,对未来的临床诊断具有帮助作用。(2)支持向量机为二分类支持向量机,模型训练简单,复杂度低。(3)采用gini系数作为样本的划分准则,保证抽取的训练数据样本分布正确反映了总数据样本的分布趋势,增强支持向量机训练模型的可靠性。附图说明图1为本发明方法流程图;图2为支持向量机二值分类原理图。具体实施方式下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。实施例如图1所示,一种基于svm的医学检测指标重要性评价方法,包括以下步骤:s1,获取多个样本的各项医学检测指标数据,所述的样本被分为至少两个类别;s2,将样本分为两部分,一部分作为标准训练集,另一部分作为测试集;s3,保留所有指标,对标准训练集建立支持向量机模型,支持向量机模型的输入为各项医学检测指标数据,输出为样本的类别,并用测试集检验该支持向量机模型的分类准确率;s4,使标准训练集仅缺失其中一个指标,建立支持对应的支持向量机模型,并用测试集检验该支持向量机模型的分类准确率,计算该分类准确率与步骤s3得到的分类准确率相比的下降值;s5,更换缺失的指标,重复步骤s4,直到遍历每个指标,利用分类准确率下降值评价对应的指标重要性,分类准确率下降值越大,则对应的指标重要性越大。本实施例将本发明方法应用于咳嗽检测指标重要性评价,实验的硬件环境为intelcorei7-5600ucpu@2.60ghz,内容为12gb。软件环境为winodows7(64位)。编程环境为java。测试数据集为某医院真实收集的咳嗽检测样本,样本个数为60例(其中42例为患者样本,18例为普通人样本)。用于检测的指标属性为7个,分别包括eos%、fev1/fvc、pef、mmef75/25、feno等。数据类别包括患者和非患者二类。样本实验所用部分数据如表1所示。表1咳嗽检测指标数据样本基于数据的机器学习是现代智能技术中的重要方面,研究从观测数据(样本)出发寻找规律,利用这些规律对未来数据或无法观测的数据进行预测。其中,支持向量机方法是一种建立在统计学习理论基础之上,专门针对小样本情况下的机器学习方法。对于分类问题,支持向量机方法根据区域中的样本计算该区域的分类曲面,由该曲面决定该区域中的样本类别。下面以二元分类问题为例,说明支持向量机方法的原理。已知样本x为m维向量,在某个区域内存在n个样本(x1,y1),(x2,y2),...(xn,yn),其中xi∈rn,yi∈{±1},i=1,2,…,n。若存在超平面wtx+b=0其中t表示向量的点积,能将这n个样本分为2类(如图2所示),那么存在最优超平面不仅能将2类样本准确分开,而且能使2类样本到超平面的距离最大。显然上式中的w和b乘以系数后仍能满足方程,那么进行归一化处理之后,对于所有样本xi,式|wtxi+b|的最小值为1,则样本与此最优超平面的最小距离为那么最优超平面应满足条件:yi[wtxi+b]≥1,i=1,2,...,n根据最优超平面的定义可知:w和b的优化条件是使二类样本到超平面最小距离之和2/||w||最大。由于本实施例中的咳嗽患者分类是个典型的二分类问题(包括患者和非患者两类),因此这类二分类问题可以直接用支持向量机进行处理。在实验过程中,通过保留所有咳嗽检测指标、依次删减检测指标的步骤实现针对不同咳嗽检测指标重要性的计算。该支持向量机方法先从原数据集中随机抽取70%数据的train数据集(有42个样本),建立对应的支持向量机模型。然后用余下的测试数据集检验模型的有效性。实验结果如表2所示。由表2可以看出,当对样本数据进行随机的支持向量机建模时,缺少pef或缺少mmef75/25样本属性对模型的分类准确性影响较小。而当在对训练数据进行建模时,如缺少feno属性,则模型分类的准确性则大幅下降。表2咳嗽检测指标数据样本所有检测指标无pef无mef75/25无feno无eos%分类准确率93.2%84.6%89.3%61.7%73.8%通过对已采集的咳嗽数据进行分析和建模,从数据中反映的诊断现象趋于一致性,也与医学专家的专家经验保持一致,因此具有一定的临床可用性。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1