一种疾病数据分析处理模型的构建方法、系统及应用与流程
本发明属于疾病数据分析处理领域,更具体地,涉及一种疾病数据分析处理模型的构建方法、系统及应用。
背景技术:
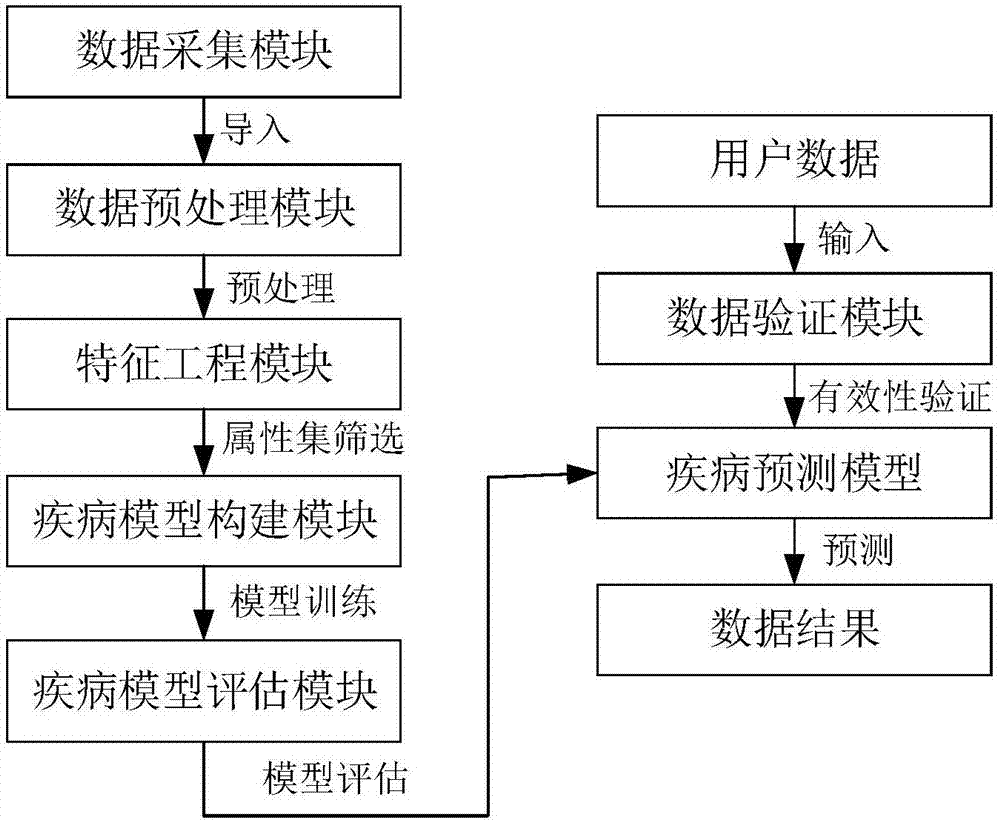
:随着计算机技术和医学工程的飞速发展和广泛应用,医学界已积累了海量的医学数据,但人们对于这些数据的研究并没有达到预想的期望,应用在医学辅助诊断上也是极少,而新时代下人们对自己的健康状况愈发关注,对疾病的认识从过去单纯的疾病诊断到关心疾病的预测和预防,如何充分的结合医疗大数据与计算机技术使其能辅助人们更加直观的观测影响疾病的因素以及更加快速的诊断疾病和预测疾病是当今研究的热点。通常我们使用数据挖掘将海量数据中有用信息挖掘出来、发现规律以及其中的相互关系,提供给决策者们使用,这些对医学决策及医学研究都有巨大的价值和意义。但疾病数据带来的数学挖掘挑战巨大:要处理的疾病数据维度高、数据结构复杂,要求模型有更强大的学习适应能力。近年来,深度学习得到广泛应用,由于其强大的自动特征提取和复杂函数的表达能力,非常适合处理疾病数据分析所面临的新问题。深度学习方法从人工神经网络模型发展而来,通过组合多个非线性处理层对原始数据进行逐层特征提取,从数据中获得不同空间的特征表达并用于分类预测。如何在疾病数据的挖掘当中,更好的刻画数据的丰富内在信息与提高预测的准确率,是目前疾病数据处理分析的重要课题。技术实现要素:针对现有技术的以上缺陷或改进需求,本发明提供了一种疾病数据分析处理模型的构建方法、系统及应用,由此解决在疾病数据挖掘中,如何更好的刻画数据丰富内在信息与提高预测准确率的技术问题。为实现上述目的,按照本发明的一个方面,提供了一种疾病数据分析处理模型的构建方法,包括:(1)对采集的疾病原始数据进行数据格式的统一得到目标数据,并对所述目标数据中的各数据形式按照属性进行归一化处理,生成大容量结构化样本矩阵;(2)通过随机森林对所述大容量结构化样本矩阵进行属性集选择,筛选出目标属性集构成训练样本矩阵;(3)对所述训练样本矩阵中的非失衡数据采取误差反向传播算法训练,对所述训练样本矩阵中的失衡数据采取代价敏感的误差反向传播算法训练得到疾病预测模型,并采取正确率和F值对所述疾病预测模型进行评估;(4)利用无监督网络模型来拟合所述训练样本矩阵中的无标签数据,在代价误差满足预设误差要求后得到数据验证模型,用于确定用户数据的有效性。优选地,步骤(3)包括:(3.1)以5折交叉验证将所述训练样本矩阵中的数据随机划分成若干组训练集数据和测试集数据,选取其中一组训练集数据和测试集数据;(3.2)构建无监督学习过程的无监督网络模型,其中,所述无监督网络模型的隐层数初始值为1,隐层的初始节点数为2;(3.3)使用逐层贪婪训练法优化所述无监督网络模型,采取最小化代价函数的误差反向传播算法和参数调整策略修改所述无监督网络模型的网络参数,对所述无监督网络模型进行训练;(3.4)连接所述无监督网络模型的输入层和隐层的编码层,固定相对应的网络参数,在最外层增加一层sigmoid分类器层构成有监督网络模型;(3.5)对所述有监督网络模型进行全局优化,采取最小化代价函数的误差反向传播算法和参数调整策略调整所述有监督网络模型的网络参数,对所述有监督网络模型进行训练,得到所述有监督网络模型在选取的训练集数据和测试集数据的预测结果;(3.6)若得到所述有监督网络模型在选取的5组训练集数据和测试集数据的预测结果,则执行步骤(3.7),否则,选取下一组训练集数据和测试集数据,并返回执行步骤(3.3);(3.7)取所述有监督网络模型在5组训练集数据和测试集数据上的平均预测结果;(3.8)增加隐层的节点数,并判断隐层的当前节点数是否达到3倍的输入层节点数,若没有达到,则返回执行步骤(3.2),若达到,则取所有平均预测结果中最好的前若干个平均预测结果对应的节点数作为隐层节点数;(3.9)增加隐层数以及有监督训练次数,对所述无监督网络模型以及所述有监督网络模型进行训练,直至所述有监督网络模型在5组训练集数据和测试集数据上的平均预测结果没有得到提升,得到目标网络模型;(3.10)通过所述训练样本矩阵中含特征数据的训练集对所述目标网络模型进行训练,得到疾病预测模型。优选地,步骤(3.3)包括:将随机加入噪声的无标签训练集数据作为所述无监督网络模型的输入数据,通过逐层优化训练所述无监督网络模型,采取最小化二次代价函数的误差反向传播算法和Momentum优化器训练所述无监督网络模型,并以所述无监督网络模型能够从含噪声的无标签训练集数据中还原出原始的无标签训练集数据为优化目标。优选地,步骤(3.5)包括:将不含噪声的无标签训练集数据作为所述有监督网络模型的输入数据,通过全局优化训练所述有监督网络模型,对所述训练样本矩阵中的非失衡数据采取最小化二次代价函数的误差反向传播算法,对所述训练样本矩阵中的失衡数据采取代价敏感的误差反向传播算法,然后结合Momentum优化器训练所述有监督网络模型,并以所述有监督网络模型能够从不含噪声的无标签训练集数据和测试集数据中计算出对应的标签结果为优化目标。优选地,步骤(3.10)包括:取5折交叉验证结果中预测错误次数超过预设次数的相同数据作为特征数据,将所述特征数据固定在训练集数据中,通过含特征数据的训练集数据对所述目标网络模型进行训练,得到疾病预测模型。优选地,步骤(4)包括:(4.1)以加入噪声的无标签训练样本矩阵数据作为所述无监督网络模型的输入数据,通过逐层初始化训练优化所述无监督网络模型,采取最小化二次代价函数的误差反向传播算法和Momentum参数调整策略修改所述无监督网络模型的网络参数,训练以所述无监督网络模型能够从含噪声的无标签训练样本矩阵数据中还原出原始的无标签训练样本矩阵数据为训练目标,得到所述无监督网络模型的初始参数,接着以不含噪声的无标签训练样本矩阵数据作为所述无监督网络模型的输入数据,通过全局优化训练所述无监督网络模型,采取最小化二次代价函数的误差反向传播算法和Momentum参数调整策略修改所述无监督网络模型的网络参数,以所述无监督网络模型能够从不含噪声的无标签训练样本矩阵数据中还原出原始的无标签训练样本矩阵数据为训练目标得到训练好的无监督网络模型;(4.2)将不含噪声的无标签训练集数据通过所述训练好的无监督网络模型前向计算后得到第一目标结果,将所述第一目标结果通过反转运算获得第一还原结果,将所述第一还原结果与所述大容量结构化样本矩阵内相对应的原始数据进行偏差情况分析构成一维的标准偏差向量;(4.3)用户数据在经过预处理后,通过所述训练好的无监督网络模型进行前向计算得到第二目标结果,将所述第二目标结果通过反转运算获得第二还原结果,将所述第二还原结果与对应的原始数据进行偏差情况分析得到用户偏差向量;(4.4)通过对比所述用户偏差向量与所述标准偏差向量确定用户数据的有效性,以构成数据验证模型。优选地,步骤(2)包括:(2.1)采用Bootstrap抽样方法从所述大容量结构化样本矩阵中抽取数据作为袋内数据,未抽取到的数据作为袋外数据,采用袋内数据训练随机森林,其中,随机森林的每棵决策树采用信息熵增益方法构建,训练过程中以高度拟合袋内数据为目标;(2.2)对于训练好的随机森林中的每一棵决策树,使用相应的袋外数据来计算决策树的袋外数据误差error1,随机对袋外数据中的所有样本的各属性加入高斯噪声干扰,并再次计算决策树的袋外数据误差error2;(2.3)由得到各属性的重要度,其中,n为决策树数目;(2.4)剔除属性重要度小于预设重要度值的属性得到新属性集,并用新属性集训练新随机森林,然后返回执行步骤(2.1),直至得到袋外误差满足预设误差值的属性集构成训练样本矩阵。优选地,在步骤(3)中采取正确率和F值评估所述疾病预测模型,其中,F值同时考虑了准确率和召回率。按照本发明的另一方面,提供了一种疾病数据分析处理模型的构建系统,包括:数据采集模块,用于对采集的疾病原始数据进行数据格式的统一得到目标数据;数据预处理模块,用于对所述目标数据中的各数据形式按照属性进行归一化处理,生成大容量结构化样本矩阵;特征工程模块,用于通过随机森林对所述大容量结构化样本矩阵进行属性集选择,筛选出目标属性集构成训练样本矩阵;疾病模型构建模块,用于对所述训练样本矩阵中的非失衡数据采取误差反向传播算法训练,对所述训练样本矩阵中的失衡数据采取代价敏感的误差反向传播算法训练得到疾病预测模型;疾病模型评估模块,用于采取正确率和F值对所述疾病预测模型进行评估;数据验证模块,用于利用无监督网络模型来拟合所述训练样本矩阵中的无标签数据,在代价误差满足预设误差要求后得到数据验证模型,用于确定用户数据的有效性。按照本发明的另一方面,提供了一种疾病数据分析处理模型的应用方法,包括:通过数据验证模型确定待检测用户数据的有效性,并在所述待检测用户数据有效时,通过疾病预测模型对所述待检测用户数据进行疾病分析处理。总体而言,通过本发明所构思的以上技术方案与现有技术相比,能够取得下列有益效果:(1)本发明对进入模型训练的数据首先进行特征筛选,利用随机森林法筛选出模型训练的属性集,通过该方法能够检验出不相关或者冗余属性,使模型能够表达出更高的准确率,此外属性的重要度结果也有利于相关医生更加直观的了解到影响疾病的各个因素情况。(2)对于模型的构建,针对不同数据情况采用不同的误反向传播算法,能够适用于不平衡数据的学习。(3)本发明提出的基于特征数据训练法能够避免模型单一的学习数据集的某些特征,使得模型能够更加全面的概括已有数据特征,表现出更好的表达能力和泛化能力。(4)本发明提出的数据验证模型,能够利用模型自动学习数据特征的能力验证用户数据的有效性,该方法是基于已有数据的学习训练来评判新数据的有效性,当学习数据量越大,模型所学习到的数据分布越准确,该判断方法的准确率也会越高。附图说明图1为本发明实施例提供的一种疾病数据分析处理模型的构建方法的流程示意图;图2为本发明实施例提供的一种疾病数据分析处理模型的构建系统的结构示意图;图3为本发明实施例提供的一种第一次各个属性重要度计算结果图;图4为本发明实施例提供的一种第二次各个属性重要度计算结果图;图5为本发明实施例提供的一种降噪自编码器无监督学习网络的结构图;图6为本发明实施例提供的一种降噪自编码器有监督学习网络的结构图;图7为本发明实施例提供的一种引入特征数据后最优模型在训练集上的结果对比图;图8为本发明实施例提供的一种引入特征数据后最优模型在测试集上的结果对比图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。如图1所示为本发明实施例提供的一种疾病数据分析处理模型的构建方法的流程示意图,在图1所示的方法中包括以下步骤:(1)对采集的疾病原始数据进行数据格式的统一得到目标数据,并对目标数据中的各数据形式按照属性进行归一化处理,生成大容量结构化样本矩阵;其中,疾病原始数据包括连续型数据、描述型数据和诊断结果。其中,在数据归一化处理中,首先对数据进行尺度变换:例如对于输入数据归一化到区间[0,1]内,对于输出数据采用One-Hot形式编码,最终生成大容量结构化样本矩阵。(2)通过随机森林对大容量结构化样本矩阵进行属性集选择,筛选出目标属性集构成训练样本矩阵;在本发明实施例中,采用随机森林法筛选出疾病预测模型训练所需的属性集构成训练样本矩阵。基本原理是根据构建好的随机森林在袋外数据误差和加入噪声的袋外数据误差之间的变化情况计算属性重要度。具体地,步骤(2)的实现过程包括:(2.1)采用Bootstrap抽样方法从大容量结构化样本矩阵中抽取数据作为袋内数据,未抽取到的数据作为袋外数据,采用袋内数据训练随机森林,其中,随机森林的每棵决策树采用信息熵增益方法构建,训练过程中以高度拟合袋内数据为目标;(2.2)对于训练好的随机森林中的每一棵决策树,使用相应的袋外数据来计算决策树的袋外数据误差error1,随机对袋外数据中的所有样本的各属性加入高斯噪声干扰,并再次计算决策树的袋外数据误差error2;(2.3)由得到各属性的重要度,其中,n为决策树数目;(2.4)剔除属性重要度小于预设重要度值的属性得到新属性集,并用新属性集训练新随机森林,然后返回执行步骤(2.1),直至得到袋外误差满足预设误差值的属性集构成训练样本矩阵。其中,预设重要度值以及预设误差值可以根据实际需要进行确定。(3)对训练样本矩阵中的非失衡数据采取误差反向传播算法训练,对训练样本矩阵中的失衡数据采取代价敏感的误差反向传播算法训练得到疾病预测模型,并采取正确率和F值对疾病预测模型进行评估;在本发明实施例中,疾病预测模型的构建可以基于降噪自编码器网络结构,降噪自编码器是基于自编码器模型改进的一种正则化自编码器模型。降噪自编码器是采用BP神经网络结构(输入层与输出层节点相同)的无监督学习方式,经过训练后能将加入噪声的输入数据还原,此时网络很好的学习到了输入数据的关键特征,其编码层得到的网络参数可以用于深层有监督网络模型参数的初始化,如此训练出来的深层有监督网络模型具备更好的鲁棒性。其中,降噪自编码器的计算过程为:对原始数据X加噪得到输入层数据输入层数据经过编码器的映射后得到编码表达Y,通过解码器将Y反向映射回来得到数据O,通过误差反向传播算法和参数调整策略修改网络参数使得代价函数越来越小。传统的自编码器通常为欠完备自编码器,隐藏层维数的设置需要比输入层小,而正则化自编码器可以通过任意架构的网络模型来学习数据的特征特性,这些特性包括稀疏表示以及对噪声或输入缺失的鲁棒性等。降噪自编码便是一种正则化的自编码器,其通过往训练样本中加入一定的噪声,并在训练过程中学习如何去除这种噪声,从而获得鲁棒性更好的模型。模型的训练基于特征数据训练法训练,模型的隐藏层层数和对应节点数采用实验的方式确定,从单一隐藏层入手,一层层的扩展,进而观察隐藏层层数对结果的影响。首先以5折交叉验证将样本矩阵通过7:3比例随机划分成5组训练集数据和测试集数据来训练模型,从而得出交叉验证过程中的较好网络结构,之后再通过含特征数据训练集再次训练较好网络结构模型,从中筛选出最佳结果构成最终的疾病预测模型。模型的训练分无监督学习和有监督学习两个过程,有监督学习网络的训练过程中非失衡数据采取误差反向传播算法训练,失衡数据采取代价敏感的误差反向传播算法训练。具体地,步骤(3)的实现过程包括:(3.1)以5折交叉验证将训练样本矩阵中的数据随机划分成若干组训练集数据和测试集数据,选取其中一组训练集数据和测试集数据;(3.2)构建无监督学习过程的无监督网络模型,其中,无监督网络模型的隐层数初始值为1,隐层的初始节点数为2;(3.3)使用逐层贪婪训练法优化无监督网络模型,采取最小化代价函数的误差反向传播算法和参数调整策略修改无监督网络模型的网络参数,对无监督网络模型进行训练;(3.4)连接无监督网络模型的输入层和隐层的编码层,固定相对应的网络参数,在最外层增加一层sigmoid分类器层构成有监督网络模型;(3.5)对有监督网络模型进行全局优化,采取最小化代价函数的误差反向传播算法和参数调整策略调整有监督网络模型的网络参数,对有监督网络模型进行训练,得到有监督网络模型在选取的训练集数据和测试集数据的预测结果;(3.6)若得到有监督网络模型在选取的5组训练集数据和测试集数据的预测结果,则执行步骤(3.7),否则,选取下一组训练集数据和测试集数据,并返回执行步骤(3.3);(3.7)取有监督网络模型在5组训练集数据和测试集数据上的平均预测结果;(3.8)增加隐层的节点数,并判断隐层的当前节点数是否达到3倍的输入层节点数,若没有达到,则返回执行步骤(3.2),若达到,则取所有平均预测结果中最好的前若干个平均预测结果对应的节点数作为隐层节点数;(3.9)增加隐层数以及有监督训练次数,对无监督网络模型以及有监督网络模型进行训练,直至有监督网络模型在5组训练集数据和测试集数据上的平均预测结果没有得到提升,得到目标网络模型;(3.10)通过训练样本矩阵中含特征数据的训练集对目标网络模型进行训练,得到疾病预测模型。其中,步骤(3.3)的具体实现过程包括:将随机加入噪声的无标签训练集数据作为无监督网络模型的输入数据,通过逐层优化训练无监督网络模型,采取最小化二次代价函数的误差反向传播算法和Momentum优化器训练无监督网络模型,并以无监督网络模型能够从含噪声的无标签训练集数据中还原出原始的无标签训练集数据为优化目标。其中,步骤(3.5)的具体实现过程包括:将不含噪声的无标签训练集数据作为有监督网络模型的输入数据,通过全局优化训练有监督网络模型,对训练样本矩阵中的非失衡数据采取最小化二次代价函数的误差反向传播算法,对训练样本矩阵中的失衡数据采取代价敏感的误差反向传播算法,然后结合Momentum优化器训练有监督网络模型,并以有监督网络模型能够从不含噪声的无标签训练集数据和测试集数据中计算出对应的标签结果为优化目标。其中,代价敏感的误差反向传播算法改造原有代价函数,在代价函数中加入误分类代价,使得网络分类代价敏感化,能够适应不平衡数据下的学习。其中,步骤(3.10)的具体实现过程包括:取步骤(3.5)中5折交叉验证结果中预测错误次数超过预设次数的相同数据作为特征数据,将特征数据固定在训练集数据中,而其余训练集数据和测试集数据依旧采用随机抽取,通过含特征数据的训练集数据对目标网络模型进行训练,适当的提高训练迭代次数,训练过程根据步骤(3.2)~步骤(3.5)相同的方法训练,并从中选取最优结果得出最终疾病预测模型,此种方法使模型能够更加全面的概括已有数据特征,表现出更好的准确率。其中,在步骤(3)中采取正确率和F值评估所述疾病预测模型,F值同时考虑了准确率和召回率,因此能够衡量不平衡数据下模型的表现。(4)利用无监督网络模型来拟合训练样本矩阵中的无标签数据,在代价误差满足预设误差要求后得到数据验证模型,用于确定用户数据的有效性。在本发明实施例中,构建数据验证模型时,利用疾病预测模型构建过程中的最优结果的无监督网络模型来充分拟合已有的训练样本矩阵,此时需要利用全体无标签训练样本矩阵数据训练降噪自编码器网络模型,达到一个较小的代价误差后使用训练好的降噪自编码器网络模型来进行用户数据有效性的验证。训练好的降噪自编码器可以得到训练样本矩阵数据的偏差值分布,待验证的用户数据通过训练好的降噪自编码器模型计算后可以得到待验证数据的偏差值分布,如果待验证数据的分布接近于训练样本矩阵数据的分布,则待验证数据的偏置值分布将接近于训练样本矩阵数据的偏差值分布,否则说明待验证数据的分布与训练样本矩阵数据的分布相差较大。具体地,步骤(4)的实现过程包括:(4.1)以加入噪声的无标签训练样本矩阵数据作为无监督网络模型的输入数据,通过逐层初始化训练优化无监督网络模型,采取最小化二次代价函数的误差反向传播算法和Momentum参数调整策略修改无监督网络模型的网络参数,训练以无监督网络模型能够从含噪声的无标签训练样本矩阵数据中还原出原始的无标签训练样本矩阵数据为训练目标,得到无监督网络模型的初始参数,接着以不含噪声的无标签训练样本矩阵数据作为无监督网络模型的输入数据,通过全局优化训练所述无监督网络模型,采取最小化二次代价函数的误差反向传播算法和Momentum参数调整策略修改无监督网络模型的网络参数,以无监督网络模型能够从不含噪声的无标签训练样本矩阵数据中还原出原始的无标签训练样本矩阵数据为训练目标得到训练好的无监督网络模型;(4.2)将不含噪声的无标签训练集数据通过训练好的无监督网络模型前向计算后得到第一目标结果,将第一目标结果通过反转运算获得第一还原结果,将第一还原结果与大容量结构化样本矩阵内相对应的原始数据进行偏差情况分析构成一维的标准偏差向量;(4.3)用户数据在经过预处理后,通过训练好的无监督网络模型进行前向计算得到第二目标结果,将第二目标结果通过反转运算获得第二还原结果,将第二还原结果与对应的原始数据进行偏差情况分析得到用户偏差向量;(4.4)通过对比用户偏差向量与标准偏差向量确定用户数据的有效性,以构成数据验证模型。如图2所示为本发明实施例提供的一种疾病数据分析处理模型的构建系统的结构示意图,包括:数据采集模块,用于对采集的疾病原始数据进行数据格式的统一得到目标数据;数据预处理模块,用于对目标数据中的各数据形式按照属性进行归一化处理,生成大容量结构化样本矩阵;特征工程模块,用于通过随机森林对大容量结构化样本矩阵进行属性集选择,筛选出目标属性集构成训练样本矩阵;疾病模型构建模块,用于对训练样本矩阵中的非失衡数据采取误差反向传播算法训练,对训练样本矩阵中的失衡数据采取代价敏感的误差反向传播算法训练得到疾病预测模型;疾病模型评估模块,用于采取正确率和F值对疾病预测模型进行评估;数据验证模块,用于利用无监督网络模型来拟合训练样本矩阵中的无标签数据,在代价误差满足预设误差要求后得到数据验证模型,用于确定用户数据的有效性。本发明还提供了一种疾病数据分析处理模型的应用方法,包括:通过数据验证模型确定待检测用户数据的有效性,并在待检测用户数据有效时,通过疾病预测模型对待检测用户数据进行疾病分析处理。以下结合附图及实施例对本发明进行详细说明。本实施例所使用的数据为UCI心脏病数据集中Cleveland数据库的完整数据,该数据库包含297条完整数据(14维数据,其中第14列为诊断结果),其中不患病数据160组,患病数据137组,属于非失衡型数据。以下将会使用本发明提出的方法进行分析处理。首先获取模型训练所需的疾病原始数据并统一数据格式。训练所需的疾病原始数据具体包括连续型数据、描述型数据和诊断结果。将连续型数据、描述型数据和诊断结果读取后按照属性归纳后形成原始疾病数据的大容量结构化样本矩阵,其中连续型数据直接将数值导入(如年龄、血压),描述型数据若是数值型则直接导入(如是否有高血糖:0无、1有),若是语言描述型则按照类别通过数字0~n标签(如胸痛类型:1典型心绞痛、2非典型心绞痛、3无心绞痛),诊断结果按数字0~1标签(如0不患病、1患病)。采取以上步骤,本实例最终采集生成297*14维的原始心脏病数据,生成的主要信息结构如表1所示。表1采集生成的数据信息结构采集到的疾病原始数据需要对其进行预处理,这里定义连续型数据和描述型数据为输入数据(第1-13列),定义诊断结果为输出数据(第14列)。对数据进行尺度变换:对于输入数据的每个属性列数据采用线性变换y=(x-xmin)/(xmax-xmin)归一化到区间[0,1]内,其中x为某列数据中的一条数据,xmin为该列数据的最小值;xmax为该列数据的最大值,y代表转换后的结果。对于输出数据采用One-Hot形式编码:不患病结果编码为01,患病结果编码为10,最终生成大容量结构化样本矩阵。经过预处理过后的数据需要计算每一个属性的重要度来选取合适的属性集作为模型训练的输入数据,此外计算出来的特征重要度排序有利于相关医生更加直观的了解到影响疾病的各个因素影响。步骤1:首先以大容量结构化样本矩阵为数据,采用Bootstrap抽样方法抽取297组数据作为袋内数据,未抽取到的数据作为袋外数据。采用袋内数据训练出最佳结构的随机森林,随机森林的每棵决策树采用信息熵增益方法构建,训练以其高度拟合袋内数据为目标;步骤2:对于训练好的随机森林中的每一棵决策树,使用相应的袋外数据来计算它的袋外数据误差,记为error1;随机地对袋外数据所有样本的各属性列加入高斯噪声干扰,再次计算它的袋外数据误差,记为error2;步骤3:n为决策树数目,若给某列属性随机加入噪声之后,袋外数据的误差大幅度增大,则说明这个属性对于样本的分类结果影响较大,也就是代表它的重要度比较高;通过上述步骤,首先以大容量结构化样本矩阵为数据,设置200棵决策树,计算出原始13个属性的各个重要度如图3所示。此时,随机森林在袋外数据的误差为15.56%。步骤4:根据上述结果,从中剔除重要度较低的属性,从而得到一个新的属性集,用新的属性集数据训练新的随机森林,并重复步骤1~步骤3计算属性集中每个属性的重要度;步骤5:重复以上步骤,最后得到每个属性集和它们建立起来的随机森林,综合选择袋外误差较低的属性集作为最后选定的训练属性集构成训练样本矩阵。从图3中可以看出第2、6、7项属性对结果影响较小,我们去除这三个属性列数据得到10个属性集,在根据上述步骤再计算这10个属性的重要度如图4所示。此时,随机森林在袋外数据的误差为20%,误差率增大,并且从图4中可以看出此时各项属性的重要度相当,没有可以剔除的属性列,所以特征工程模块这里最终选取原13列数据作为训练样本矩阵。进行疾病预测模型的训练,本实例的具体训练步骤包括:步骤11:构建无监督学习过程的降噪自编码器模型,具体结构如图5所示,模型输入层的节点数根据特征工程选定的属性集决定,本实施例选定了13个疾病属性则输入层节点数为13,输出层根据数据结果的One-Hot编码形式确定节点数,这里输出层节点数为2,初始隐藏层数为1,隐藏层节点数从数值2到3倍的输入层节点数之间迭代,网络模型基于人工神经网络的基本原理构建,网络模型的每个节点采取线性映射函数f(WX+b)建立该节点的数学模型,其中激活函数f()采取sigmoid函数,权重W采取随机正太分布值预设,偏置值b采取置0法预设。训练过程中输入层的输入值需在原始数据上加入噪声,这里设置每个输入值有0.5的概率被置为0。步骤22:以5折交叉验证将训练样本矩阵通过7:3比例随机划分成5组训练集数据和测试集数据,无监督学习过程的训练数据为无标签训练集数据,其中输入数据为随机加入噪声的无标签训练集数据,期望输出数据为无标签训练集数据,训练的最终目标以网络模型能够从含噪声的无标签训练集数据中以较小误差还原出原始的无标签训练集数据为目标。通过逐层优化训练上述网络结构,采取最小化二次代价函数的误差反向传播算法和Momentum优化器训练模型得出较优的网络初始参数。其中以二次代价函数的误差反向传播算法的具体步骤如下:设逐层优化训练过程中,每次优化的网络的输入层有N个神经元,隐藏层有m个神经元,输出层有l个神经元,定义二次代价函数为:其中n为批次训练样本数,dk代表输出层第k个神经元的期望输出结果,ok为输出层第k个神经元的实际计算结果,wjk和bjk分别表示连接隐藏层第j个神经元与输出层第k个神经元的连接权重和偏置值,vij和cij分别表示连接输入层第i个神经元与隐藏层第j个神经元的连接权重和偏置值,xi表示输入层第i个神经元的输出。计算权值和偏置值调整量:使用Momentum优化器调整参数:其中η为学习率,γ为动量参数,t为调整次数初值为1,rt在t=0处值为0。步骤33:根据无监督学习网络训练得到的网络结构和参数构建有监督学习过程的网络结构,具体结构如图6所示。具体为连接无监督学习网络的输入层和隐层的编码层,固定连接输入层和隐层编码层相对应的网络参数,在最外层增加一层sigmoid分类器层构成最终的有监督学习网络,分类器的每个节点依旧采取线性映射函数f(WX+b)建立数学模型连接编码层最后一层的各个输出,其中激活函数f采取sigmoid函数,权重W采取随机正太分布值预设,偏置值b采取置0法预设。步骤44:该训练步骤同样采用步骤22的数据训练,不同的是此时输入数据为不含噪声的无标签训练集数据,期望输出数据为无标签训练集数据的标签结果,训练的最终目标以网络模型能够通过不含噪声的无标签训练集数据和测试集数据中计算出准确的对应标签结果为目标。进行全局优化上述网络结构,取5组训练集数据和测试集数据的较好平均预测结果的节点数作为该隐层节点数。训练过程与步骤22不同的是,对于最终构成的有监督学习网络,训练过程中非失衡数据依旧采取步骤22中的误差反向传播算法训练,失衡数据采取代价敏感的误差反向传播算法训练,代价函数均采用二次代价函数。其中以二次代价函数的代价敏感误差反向传播算法的具体步骤如下:在误差函数中加入误分类代价,代价函数变为:其中K[j,i]是把i类事物误分为j类的误分类代价因子,其中K[j,i]的定义为如下:其中C(j,i)是把i类事物误分为j类的误分类代价,存在两种情况:“将病人(定义1)误诊为健康人(定义0)”和“将健康人(定义0)误诊为病人(定义1)”,即C(j,i)存在两种情况:C(0,1)和C(1,0),具体代表“将病人误诊为健康人”和“将健康人误疹为病人”的不同代价,代价值可以根据实际需要进行确定。C(i)为i类事物被错分类的期望代价,当i=0时,C(0)=P1,0C(1,0);当i=1时,C(1)=P0,1C(0,1),Pj,i是模型训练过程中把i类事物错分成j类的概率。其余步骤与步骤22方法类似,不同之处在于此时隐藏层数较多,但同样采用步骤22中对代价函数求导的方式求出各层权值和偏置值调整量。步骤55:经上述步骤将得到隐藏层数为1的较优网络结构,继续增加隐藏层数和适当增加有监督训练次数,重复上述步骤训练,直到有监督网络模型的分类结果没有得到提升为止。最后,将得到分类效果较优的几个有监督网络模型。根据以上步骤,我们需要根据交叉验证的实验选取较优的网络结构。首先对预处理过后的297组数据采取5折交叉验证法按照7:3的比例随机划分训练集和测试集,其中训练集包含210组数据,测试集包含87组数据。由于本组数据为非失衡数据,所以采用模型评估模块中的正确率作为判断依据。设置无监督学习和有监督学习迭代20次,批次训练数据量为10,学习率0.5,动量参数0.5,噪声系数0.5。首先对单隐藏层结构进行分析,令节点数在2~39之间变换,得出较优结果如表2所示,Accuracy1和Accuracy2分别代表5折交叉验证训练集的平均准确率和测试集的平均准确率。表2单隐藏层训练结果INPUTHIDDEN1OutputAccuracy1Accuracy21317285.71%85.52%1332285.52%85.75%当隐藏层个数为1时,以上情况为实验的较好结果。然后,进行一个具有两层隐藏层的DAE模型的实验,固定第一个隐藏层节点数如表2所示,令第二隐藏层节点数在2~39之间变换,将有监督学习的迭代次数增至35次,记录较好结果的模型结构,实验结果如表3所示。表3双隐藏层训练结果INPUTHIDDEN1HIDDEN2OutputAccuracy1Accuracy2131710288.10%84.83%13175288.29%85.29%133236286.19%84.14%由表3可知,DAE网络隐藏层结构继续增加到两层的时候,第一隐藏层节点数为17的网络模型的综合表现有所提升,但第一隐藏层节点数为32的网络模型结果并没有太大提升,故本次固定隐层结构为17-10以及17-5,继续增加隐藏层到三层,令其第三隐层节点数在2~39之间变换,将有监督学习的迭代次数增至50次,记录较好结果的模型结构,实验结果如表4所示。表4三个隐藏层训练结果由表4可知,DAE网络隐藏层结构继续增加到三层的时候,唯有第二隐藏层节点数为10的模型在整体表现上有所提升。继续增加隐藏层到四层的时候,固定前三层网络的结构为17-10-9,令第四隐藏层节点数在2~39之间变换,将有监督学习的迭代次数增至65次,记录较好结果的模型结构,实验结果如表5所示。表5四个隐藏层训练结果由表5可知,DAE网络隐藏层结构继续增加到四层的时候,模型的整体表现并没有提高,所以实验终止,最后经过交叉验证得到的较优网络模型有三个,分别为13-17-10-2、13-17-5-2以及13-17-10-9-2。步骤66:通过步骤11-44我们可以得出几个较优的网络结构模型,我们取5折交叉验证结果中预测错误次数较多的相同数据作为特征数据,这里的错误次数可以根据挑选出的数据占总数据的20%左右为依据。将这些特征数据固定在训练集数据中而其余训练集数据和测试集数据依旧采用随机抽取,固定网络结构为步骤55得到的较优网络结构,适当的提高训练迭代次数,再次根据步骤11-44相同的方法训练较优模型结构,并从中选取最优结果得出最终疾病预测模型,此种方法能够使模型能够更加全面的概括已有数据特征,表现出更好的准确率。根据步骤66的方法,首先分析上述训练过程的5组交叉验证的结果,抽取65组特征数据将其放入训练集的210组数据中,其余145组数据采用随机抽取的方法。采用此种方法再来训练上述三个网络模型,其中13-17-10-2的网络模型所得结果最好,故最终选定13-17-10-2结构为最终的疾病预测模型结构。其中,该结构在无特征数据情况下的最优结果如表6所示。表6随机抽取数据的最佳训练结果随机数组数训练集准确率测试集准确率087.62%88.51%190.48%85.06%286.67%85.06%388.10%87.36%488.10%88.51%而该结构在步骤66提出的基于特征数据训练法的最优结果为表7所示。表7基于特征数据训练结果随机数组数训练集准确率测试集准确率098.10%95.40%195.71%93.10%296.19%93.10%394.76%94.25%495.71%93.10%可以看出在引入特征数据后,训练结果的准确率大大提升,最好的模型在训练集210组数据上错误4个,在测试集87组数据上错误4个,分别达到98.10%、95.40%的准确率,故选择该组模型为最终的疾病预测模型。其改善结果对比如图7和图8所示。采取正确率和F值评估所训练好的模型。其中F值同时考虑到了少数类的准确率和召回率,因此能够衡量不平衡数据下模型的表现。正确率计算公式为F值计算公式为其中各参数如混淆矩阵所示,其中β的取值为1。表8模型评估混淆矩阵本实施例数据为非失衡型数据,所以在上述模型构建模块中应用到的模型评估方法为正确率方法。用户数据在经过训练好的疾病预测模型计算前将会通过数据验证模型进行有效性验证,具体步骤如下:步骤1’:采用模型构建模块中的最优结果的无监督学习网络,本实施例为13-17-10-17-13结构,以全体训练样本矩阵为训练数据,首先以加入噪声的无标签训练样本矩阵数据作为无监督网络模型的输入数据,通过逐层初始化训练所述无监督网络模型得到网络的初始参数,训练以网络模型能够从含噪声的无标签训练集数据中还原出原始的无标签训练集数据为优化目标,得到无监督网络模型的初始参数,接着以不含噪声的无标签训练样本矩阵数据作为所述无监督网络模型的输入数据,通过全局优化训练所述无监督网络模型,训练以网络模型能够从不含噪声的无标签样本矩阵数据中以较小误差还原出原始的无标签样本矩阵数据为最终目标;接着将不含噪声的无标签训练样本矩阵通过训练好的无监督学习网络前向计算后得到计算结果,将计算结果通过数据预处理模块的反转运算x还原结果=o输出结果(xmax-xmin)+xmin,获得最终还原的结果,将最终还原结的结果与大容量结构化样本矩阵内的相应的原始数据进行偏差情况分析,偏差情况分析采用公式计算,选取每个属性的偏差量最大值构成一维的标准偏差向量;根据步骤1’,采用13-17-10-17-13结构,通过高度拟合的方式学习现有完整的297组无标签数据,设置迭代次数1000次,整体均方误差小于0.02为目标训练模型。训练结束后,计算原始297组数据的标准偏差向量如表9所示。表9标准偏差向量123456789101112130.08000.050.11010.01000.63000步骤2’:用户数据首先经过上述相同的预处理过程后通过上述训练好的无监督学习网络进行前向计算得到计算结果,将计算结果同样通过数据预处理模块的反转运算获得最终还原的结果,将最终还原的结果与对应的原始数据进行偏差情况分析得到用户偏差向量。步骤3’:对比用户偏差向量与标准偏差向量,这里可以选择适当的容错比例,如1.5倍容错率就是将标准偏差向量乘以1.5后再进行对比,通过对比判断用户数据有效性。通过步骤1’得出标准偏差向量后,可以通过步骤2’-步骤3’计算用户偏差情况进行对比,取容错率为1进行对比。为了验证该效果的有效性,进行3组实验,该3组实验分别对原始正常数据进行不同程度的干扰,其中第一组数据通过往连续型数据所在列添加干扰,第二组数据通过往描述型数据所在列添加干扰,第三组数据往连续型数据以及描述型数据都添加干扰。数据从患病以及不患病数据中随机抽取。第一组实验,从297组数据中随机抽取10组数据,随机将每组数据1至2个连续型数据的30%或200%替换原始数据,通过上述步骤计算偏差值如表10所示。表10数据有效验证第一组表10中加粗的数据代表偏差值大于标准偏差值,可以看出每组数据均有部分值超过标准偏差值,如第1组数据的第一列属性为1.17大于该属性的标准偏差值0.08。可以判断出这些数据存在一定的错误。第二组实验,从297组数据中随机抽取10组数据,随机将每组数据的2至3个描述型数据进行同数据范围内的随机替换,通过上述步骤计算偏差值如表11所示。表11数据有效验证第二组表11中加粗的数据代表偏差值大于标准偏差值,可以看出每组数据均有部分值超过标准偏差值,如第3组数据的第3和第8列属性分别为1和0.02,大于第3和第8列属性的标准偏差值:0和0.01。可以判断出这些数据存在一定的错误。第三组实验,从297组数据中随机抽取10组数据,随机将连续型数据和描述型数据都进行一定的干扰替换,通过上述步骤计算偏差情况如表12所示。表12数据有效验证第三组表12中加粗的数据代表偏差值大于标准偏差值,可以看出每组数据均有部分值超过标准偏差值,如第2组数据的第4和第8列属性分别为1.15和0.07,大于第4和第8列属性的标准偏差值:0.05和0.01。可以判断出这些数据存在一定的错误。对比三组实验数据可知,本发明提出的心脏病数据的有效性验证方法能够一定程度上的检验出错误数据,其中对于连续型数据的检测敏感度大于描述型数据(表现在还原的偏差值更大)。本发明方法是基于已有数据的学习训练来评判新数据的有效性,当学习数据量越大,模型所学习到的数据分布越准确,该判断方法的准确率也会越高,用此方法能够辅助判断心脏病数据的有效性。本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1