改进神经网络语言模型的方法和装置及语音识别方法和装置与流程
本发明涉及语音识别系统,具体涉及改进语音识别系统的神经网络语言模型的方法、改进语音识别系统的神经网络语言模型的装置、语言识别方法以及语音识别装置。
背景技术:
语音识别系统一般包含声学模型(AM)和语言模型(LM)两个部分。声学模型是统计语音特征对音素单元概率分布的模型,语言模型是统计词序列(词汇上下文)出现概率的模型,语音识别过程是根据两个模型的概率得分的加权和得到得分最高的结果。
作为语言模型中最为经典的方法,统计回退语言模型,如ARPA LM,几乎应用于所有的语音识别系统中。这类模型是一种离散式的非参数化的模型,即直接用词序列的频率来统计出概率。
近几年,神经网络语言模型(NN LM)作为一种新方法被引入语音识别系统,极大地提高了识别性能,其中,深度神经网络(DNN)和递归神经网络(RNN)是两种最具代表性的技术。
上述神经网络LM是一种参数化的统计模型,对语音识别系统词汇的量化采用位置指示向量作为词汇特征,该词汇特征为神经网络LM的输入,而输出为在某词序列历史的条件下,系统词典中每个词作为下一个词出现的概率。每个词汇的特征为位置指示向量,即在以语音识别系统词典大小为维数的向量中将对应某词汇在系统词典中的位置的元素标为“1”,而其他元素均为“0”。
技术实现要素:
本发明者们发现,位置指示向量仅包含了词汇在系统词典中的位置信息,因此,以往的神经网络语言模型对词序列出现概率的学习和预测能力还存在进一步改进的余地。
为了进一步改进神经网络语言模型对词序列出现概率的学习和预测能力,本发明提出了将其他信息加入位置指示向量中,从而提高神经网络语言模型对词序列出现概率的学习和预测能力的方法和装置。也就是说,本发明提供了改进语音识别系统的神经网络语言模型的方法和装置,并进一步提供了语音识别方法和语音识别装置。具体地,提供了以下技术方案。
[1]一种改进语音识别系统的神经网络语言模型的装置,具备:
词分类单元,其对上述语音识别系统的词典中的词进行分类;
语言模型训练单元,其基于分类的结果训练基于类的语言模型;和
向量拼接单元,其将上述基于类的语言模型的输出向量与上述神经网络语言模型的位置指示向量拼接,作为上述神经网络语言模型的输入向量。
根据上述[1]的改进语音识别系统的神经网络语言模型的装置,可以将基于类的语言模型的向量作为附加特征加入神经网络语言模型的输入向量,能够提高神经网络语言模型对词序列出现概率的学习和预测能力。
[2]根据上述[1]的改进神经网络语言模型的装置,其中,
上述词分类单元,基于预定的标准对上述词典中的词进行分类。
[3]根据上述[2]的改进神经网络语言模型的装置,其中,
上述预定的标准包括词性、语义和语用信息。
根据上述[2]和[3]的改进神经网络语言模型的装置,可以以多个标准对词典中的词进行分类,由此,能够提高对词典中的词分类的多样性。并且,根据不同的分类标准,可相应地得到不同的基于类的语言模型,由此,能够提高基于类的语言模型的多样性。
[4]根据上述[3]所述的改进神经网络语言模型的装置,其中,
上述词分类单元,基于词性以预定的分类方式对上述词典中的词进行分类。
根据上述[4]的改进神经网络语言模型的装置,在以词性为标准对词典中的词进行分类时,能够进一步以例如100种词性和315种词性的分类方式对词典中的词进行分类,能够进一步提高对词典分类的多样性。并且,根据不同的分类方式,可相应地得到不同的基于类的语言模型,由此,能够进一步提高基于类的语言模型的多样性。
[5]根据上述[1]-[4]的任一项的改进神经网络语言模型的装置,其中,
上述语言模型训练单元,以预定的阶数训练基于类的语言模型。
根据上述[5]的改进神经网络语言模型的装置,能够以预定的阶数训练基于类的语言模型,例如,可以以3-gram、4-gram训练基于类的语言模型,根据不同的阶数,可相应地得到不同的基于类的语言模型,由此,能够提高基于类的语言模型的多样性。
[6]根据上述[1]-[4]的任一项的改进神经网络语言模型的装置,其中,
上述基于类的语言模型包括APRA语言模型、NN语言模型和RF语言模型。
[7]根据上述[6]的改进神经网络语言模型的装置,其中,
上述NN语言模型包括DNN语言模型和RNN语言模型。
根据上述[6]和[7]的改进神经网络语言模型的装置,基于类的语言模型例如可以是APRA语言模型、DNN语言模型、RNN语言模型和RF语言模型,根据不同类型的语言模型,可相应地得到不同的基于类的语言模型,由此,能够提高基于类的语言模型的多样性。
[8]一种语音识别装置,具备:
语音输入单元,其用于输入待识别的语音;
文本句识别单元,其利用声学模型将上述语音识别为文本句;和
得分计算单元,其利用语言模型计算上述文本句的得分;
所述语言模型包括由上述[1]-[7]的任一项的装置改进后的语言模型。
根据上述[7]的语音识别装置,使用了由上述[1]-[7]的任一项的装置改进后的语言模型,由此,可以将基于类的语言模型的向量作为附加特征加入神经网络语言模型的输入向量,能够提高神经网络语言模型对词序列出 现概率的学习和预测能力。另外,能够提高基于类的语言模型的多样性。
[9]根据上述[8]所述的语音识别装置,还具备:
平均值计算单元,其计算利用两个以上的语言模型分别计算出的得分的加权平均值,作为上述文本句的得分。
根据上述[9]的语音识别装置,计算利用两个以上的语言模型分别计算出的得分的加权平均值,作为上述文本句的得分,由此,能够进一步提高识别准确率。具体地,由于分类标准多种多样(例如词性、语义、语用信息等),同一分类标准也有不同的分类方式(例如,对于词性分类有100种词性分类和315种词性分类等),同一分类标准也有不同上下文阶数(例如3-gram、4-gram等)的语言模型,语言模型也有多种选择(例如APRA语言模型、DNN语言模型、RNN语言模型和RF语言模型等),因此能够提高对词典中的词分类的多样性,与此相应,也能提高训练出的基于类的语言模型的多样性,得到多种以基于类的语言模型的得分为附加特征而改进了的神经网络语言模型,再将这些神经网络语言模型进行融合时可进一步提高识别准确率,提高识别性能。
[10]一种改进语音识别系统的神经网络语言模型的方法,包括:
对上述语音识别系统的词典中的词进行分类;
基于分类的结果训练基于类的语言模型;和
将上述基于类的语言模型的输出向量与上述神经网络语言模型的位置指示向量拼接,作为上述神经网络语言模型的输入向量。
根据上述[10]的改进语音识别系统的神经网络语言模型的方法,可以将基于类的语言模型的向量作为附加特征加入神经网络语言模型的输入向量,能够提高神经网络语言模型对词序列出现概率的学习和预测能力。
[11]根据上述[10]的改进神经网络语言模型的方法,其中,
对上述词典中的词进行分类的步骤包括:
基于预定的标准对上述词典中的词进行分类。
[12]根据上述[11]的改进神经网络语言模型的方法,其中,
上述预定的标准包括词性、语义和语用信息。
根据上述[11]和[12]的改进神经网络语言模型的方法,可以以多个标准对词典中的词进行分类,由此,能够提高对词典中的词分类的多样性。并且,根据不同的分类标准,可相应地得到不同的基于类的语言模型,由此,能够提高基于类的语言模型的多样性。
[13]根据上述[12]的改进神经网络语言模型的方法,其中,
对上述词典中的词进行分类的步骤包括:
基于词性以预定的分类方式对上述词典中的词进行分类。
根据上述[13]的改进神经网络语言模型的方法,在以词性为标准对词典中的词进行分类时,能够进一步以例如100种词性和315种词性的分类方式对词典中的词进行分类,能够进一步提高对词典分类的多样性。并且,根据不同的分类方式,可相应地得到不同的基于类的语言模型,由此,能够进一步提高基于类的语言模型的多样性。
[14]根据上述[10]-[13]的任一项的改进神经网络语言模型的方法,其中,
上述基于分类的结果训练基于类的语言模型的步骤包括:
以预定的阶数训练基于类的语言模型。
根据上述[14]的改进神经网络语言模型的方法,能够以预定的阶数训练基于类的语言模型,例如,可以以3-gram、4-gram训练基于类的语言模型,根据不同的阶数,可相应地得到不同的基于类的语言模型,由此,能够提高基于类的语言模型的多样性。
[15]根据上述[10]-[13]的任一项的改进神经网络语言模型的方法,其中,
上述基于类的语言模型包括APRA语言模型、NN语言模型和RF语言模型。
[16]根据上述[15]的改进神经网络语言模型的方法,其中,
上述NN语言模型包括DNN语言模型和RNN语言模型。
根据上述[15]和[16]的改进神经网络语言模型的方法,基于类的语言模型例如可以是APRA语言模型、DNN语言模型、RNN语言模型和RF语 言模型,根据不同类型的语言模型,可相应地得到不同的基于类的语言模型,由此,能够提高基于类的语言模型的多样性。
[17]一种语音识别方法,包括:
输入待识别的语音;
利用声学模型将上述语音识别为文本句;和
利用语言模型计算上述文本句的得分;
所述语言模型包括由上述[10]-[16]的任一项的方法改进后的语言模型。
根据上述[17]的语音识别方法,使用了由上述[10]-[16]的任一项的方法改进后的语言模型,可以将基于类的语言模型的向量作为附加特征加入神经网络语言模型的输入向量,能够提高神经网络语言模型对词序列出现概率的学习和预测能力。另外,能够提高基于类的语言模型的多样性。
[18]根据上述[17]所述的语音识别方法,其中,
利用语言模型计算上述文本句的得分的步骤包括:
计算利用两个以上的语言模型分别计算出的得分的加权平均值,作为上述文本句的得分。
根据上述[18]的语音识别方法,计算利用两个以上的语言模型分别计算出的得分的加权平均值,作为上述文本句的得分,由此,能够进一步提高识别准确率。具体地,由于分类标准多种多样(例如词性、语义、语用信息等),同一分类标准也有不同的分类方式(例如,对于词性分类有100种词性分类和315种词性分类等),同一分类标准也有不同上下文阶数(例如3-gram、4-gram等)的语言模型,语言模型也有多种选择(例如APRA语言模型、DNN语言模型、RNN语言模型和RF语言模型等),因此能够提高对词典中的词分类的多样性,与此相应,也能提高训练出的基于类的语言模型的多样性,得到多种以基于类的语言模型的得分为附加特征而改进了的神经网络语言模型,再将这些神经网络语言模型进行融合时可进一步提高识别准确率,提高识别性能。
附图说明
通过以下结合附图对本发明具体实施方式的说明,能够更好地了解本发明上述的特点、优点和目的。
图1是根据本发明的一个实施方式的改进语音识别系统的神经网络语言模型的方法的流程图。
图2是对本发明的一个实施方式的改进语音识别系统的神经网络语言模型的方法进行说明的框图。
图3是对本发明的一个实施方式的改进语音识别系统的神经网络语言模型的方法进行说明的框图。
图4是根据本发明的另一实施方式的语音识别方法的流程图。
图5是根据本发明的另一实施方式的改进语音识别系统的神经网络语言模型的装置的框图。
图6是根据本发明的另一实施方式的语音识别装置的框图。
具体实施方式
下面就结合附图对本发明的各个优选实施例进行详细的说明。
改进语音识别系统的神经网络语言模型的方法
图1是根据本发明的改进语音识别系统的神经网络语言模型的方法的流程图。
如图1所示,首先,在步骤S100中,对语音识别系统的词典中的词进行分类。
关于对语音识别系统的词典中的词进行分类的方法,参照图2的框图进行说明。
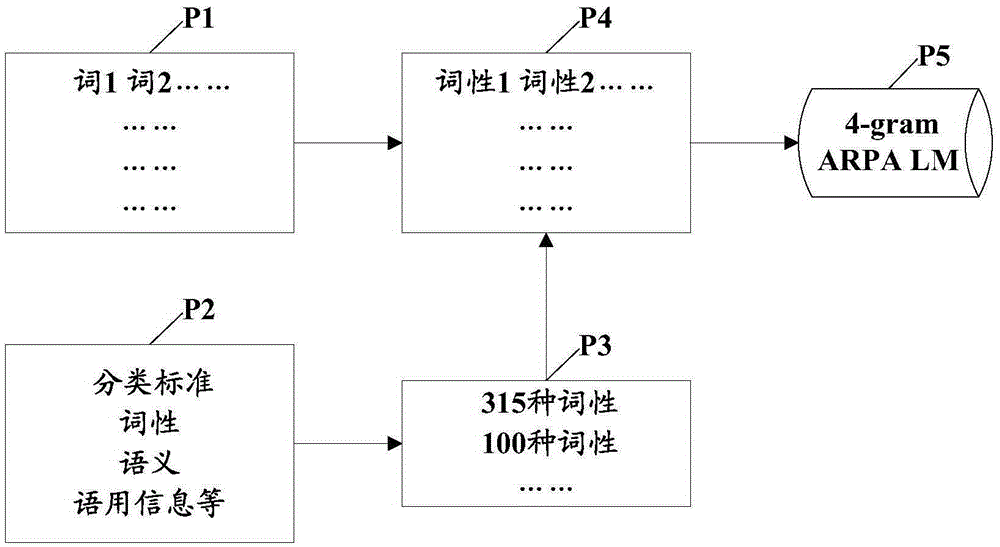
在图2中,P1示出词典中的词1、词2……。
如P2所示,作为对语音识别系统的词典中的词进行分类的标准,可列举词性、语义和语用信息等,本实施方式对此没有任何限制。在本实施方式中,以词性为例进行说明。
在以同一分类标准对词典中的词进行分类时,也会存在不同的分类方 式,例如如图2中的P3所示,在如本实施方式那样以词性为标准对词典中的词进行分类时,存在315种词性的分类和100种词性的分类。
在本实施方式中,以315种词性的分类方式为例进行说明。
在确定了对词典中的词进行分类的方式之后,P1中的词1、词2……就会与315种词性对应地被分类成P4中的词性1、词性2……,完成对词典中的词的分类。
另外,对语音识别系统的词典中的词进行分类的标准不限于上述列举的标准,并且在任一种标准下都可能对应不同的分类方式。
返回图1,在步骤S100中对语言识别系统的词典中的词进行分类后,进入S110。
在S110中,基于分类的结果训练基于类的语言模型。
参照图2对基于分类的结果训练基于类的语言模型的步骤进行说明。
在基于P4中的分类结果来训练基于类的语言模型时,可以以不同的阶数(n-gram)训练基于类的语言模型,例如可以训练3-gram语言模型、4-gram语言模型等。另外,作为训练出的语言模型的类型(type),例如可列举APRA语言模型、DNN语言模型、RNN语言模型和随机场(RF)语言模型,也可以是其他语言模型。
如图2的P5所示,在本实施方式中,以4-gram ARPA语言模型为例,将其作为基于类的语言模型。
返回图1,在步骤S110中基于分类的结果训练基于类的语言模型后,进入S120。
在S120中,将上述基于类的语言模型的输出向量与上述神经网络语言模型的位置指示向量拼接,作为上述神经网络语言模型的输入向量。
以下,参照图3的框图,对S120的处理的一例进行说明,在图3中以与词(t)对应的位置指示向量和基于类的语言模型的输出向量为例进行说明。
R1表示词典,本实施方式中,词典R1例如含有10000个词。
如R2、R3所示,词典中的10000个词“……词(t-n+1)……词(t-1) 词(t)词(t+1)……”被以315种词性进行分类,得到对应的R3中的“……词性(t-n+1)……词性(t-1)词性(t)词性(t+1)……”。
R4的4-gram ARPA LM为上述S110中训练出的基于类的语言模型,其以315种词性为分类方式。
R6表示位置指示向量。
以下,参照图3,以位置指示向量R6为例对位置指示向量进行说明。
位置指示向量是常规神经网络语言模型的每个词汇的特征,维数与词典中词汇的数量相同,将对应某词汇在词典中的位置的元素标为“1”,而其他元素均为“0”,由此,位置指示向量包含了词汇在词典中的位置信息。
在本实施方式中,词典R1包含10000个词汇,所以位置指示向量R6的维数为10000维,在图3中,R6中的每一个格代表一个维数,图3中仅示出了一部分维数。
位置指示向量R6中的黑实心格R61与词汇在词典中的位置相对应,黑实心格代表“1”,一个位置指示向量中仅存在一个黑实心格。除了黑实心格R61之外,R6中还存在9999个空心格,空心格代表“0”,在此,仅示出了一部分空心格。
图5中的黑实心格与R2中的词(t)的位置相对应,所以位置指示向量R6包含了词(t)在词典R1中的位置信息。
R5表示基于类的语言模型的输出向量。
以下,参照图3,以基于类的语言模型的输出向量R5为例对基于类的语言模型的输出向量进行说明。在以下说明中,将基于类的语言模型的输出向量R5简称为输出向量R5。
输出向量R5也是一个多维向量,其表示语言模型R4的概率输出。
如上所述,在训练语言模型R4时,以315种词性进行了分类。
输出向量R5的维数与分类的结果对应,是315维的向量,并且每一维的位置代表315种词性中的某个具体词性,每一维的数值代表是315种词性中的某个具体词性的概率。
并且,在R4为n-gram语言模型时,能够根据前n-1个词的词性来算 出第n个词是某个词性的概率。
在本实施方式中,作为例子,语言模型R4是4-gram语言模型,所以能够根据前3个词(即,词(t)词(t-1)词(t-2))的词性来算出第4个词(即,词(t+1))是315种词性中的某个词性的概率,即能够算出上述词(t)的下一个词是哪个词性的概率。
在图3中,R5中的每一格代表一个维数,也就是说每一个格对应于315种词性种的某个词性,每一个格的数值代表下个词是某个具体词性的概率,是0以上且1以下的值,所以用灰实心格进行示出。图3中仅示出了一部分的维数。
以上,以R4为4-gram语言模型为例进行了说明,特别地,在R4为1-gram语言模型时,在输出向量R5中,与当前的词(t)的词性对应的位置(即,R5中的某个格)的数值成为1,其余格的位置均为0。
在得到了与词(t)对应的位置指示向量R6和输出向量R5后,将位置指示向量R6与输出向量R5拼接,将拼接后的向量作为神经网络语言模型的输入向量来训练神经网络语言模型,由此得到R7的神经网络语言模型。
此处,“拼接”是指位置指示向量R6与输出向量R5的维数的相加,在如上述那样位置指示向量R6为10000维,输出向量R5为315维的情况下,拼接后的向量成为10315维的向量。
在本实施例中,在拼接后的10315维的向量中,包含词(t)在词典R1中的位置信息和词(t+1)是315种词性中的某个词性的概率的信息。
在本实施方式中,将基于类的语言模型的向量作为附加特征加入神经网络语言模型的输入向量,能够提高神经网络语言模型对词序列出现概率的学习和预测能力。
另外,在本实施方式中,分类标准多种多样(例如词性、语义、语用信息等),同一分类标准也有不同的分类方式(例如,对于词性分类有100种词性分类和315种词性分类等),同一分类标准也有不同上下文阶数(例如3-gram、4-gram等)的语言模型,语言模型也有多种选择(例如APRA 语言模型、DNN语言模型、RNN语言模型和RF语言模型等),因此能够提高对词典中的词分类的多样性,与此相应,也能提高训练出的基于类的语言模型的多样性,得到多种以基于类的语言模型的得分为附加特征而改进了的神经网络语言模型,在将这些神经网络语言模型进行融合时可进一步提高识别准确率,提高识别性能。
语音识别方法
图4是在同一发明构思下的本发明的语音识别方法的流程图。下面就结合该图,对本实施方式进行描述。对于那些与前面实施例相同的部分,适当省略其说明。
在本实施方式中,在S200中,输入待识别的语音,然后进入S210。
在S210中,利用声学模型将上述语音识别为文本句,然后进入S220。
在S220中,利用通过上述第一实施方式的方法改进后的语言模型计算上述文本句的得分。
由此,由于使用了提高了对词序列出现概率的学习和预测能力的神经网络语言模型,所以能够提高语言识别方法的识别准确率。
在S220中,也可以利用两个以上的语言模型分别计算得分,将计算出的得分的加权平均值作为文本句的得分。
其中,该两个以上的语言模型只要其中至少一个是通过上述第一实施方式的方法改进后的语言模型即可,可以全部是改进后的语言模型,也可以一部分是改进后的语言模型,而另一部分是ARPA语言模型等公知的各种语言模型。
由此,含有不同附加特征的神经网络语言模型能够进一步融合,可进一步提高语言识别方法的识别准确率。
关于S220中所使用的改进后的语言模型,使用按照上述的改进神经网络语言模型的方法改进后的神经网络语言模型即可,其改进的过程已在改进神经网络语言模型的方法中详细叙述,在此省略详细的说明。
改进语音识别系统的神经网络语言模型的装置
图5是在同一发明构思下的本发明的改进语音识别系统的神经网络语言模型的装置的框图。下面就结合该图,对本实施方式进行描述。对于那些与前面实施方式相同的部分,适当省略其说明。
以下,有时将“改进语音识别系统的神经网络语言模型的装置”简称为“改进语言模型的装置”。
本实施方式提供一种改进语音识别系统的神经网络语言模型的装置10,包括:词分类单元100,其对上述语音识别系统的词典1中的词进行分类;语言模型训练单元110,其基于分类的结果训练基于类的语言模型;和向量拼接单元120,其将上述基于类的语言模型的输出向量与上述神经网络语言模型的位置指示向量拼接,作为上述神经网络语言模型2的输入向量。
如图5所示,词典分类单元100对语音识别系统的词典中的词进行分类。
关于词典分类单元100对语音识别系统的词典中的词进行分类的方法,参照图2的框图进行说明。
在图2中,P1示出词典中的词1、词2……。
如P2所示,作为对语音识别系统的词典中的词进行分类的标准,可列举词性、语义和语用信息等,本实施方式对此没有任何限制。在本实施方式中,以词性为例进行说明。
在以同一分类标准对词典中的词进行分类时,也会存在不同的分类方式,例如如图2中的P3所示,在如本实施方式那样以词性为标准对词典中的词进行分类时,存在315种词性的分类和100种词性的分类。
在本实施方式中,以315种词性的分类方式为例进行说明。
在确定了对词典中的词进行分类的方式之后,P1中的词1、词2……就会与315种词性对应地被分类成P4中的词性1、词性2……,完成对词典中的词的分类。
另外,对语音识别系统的词典中的词进行分类的标准不限于上述列举 的标准,并且在任一种标准下都可能对应不同的分类方式。
返回图5,在词分类单元100对语音识别系统的词典中的词进行分类之后,语言模型训练单元110基于分类的结果训练基于类的语言模型。
参照图2对语言模型训练单元110基于分类的结果训练基于类的语言模型进行详细说明。
在基于P4中的分类结果来训练基于类的语言模型时,可以以不同的阶数(n-gram)训练基于类的语言模型,例如可以训练3-gram语言模型、4-gram语言模型等。另外,作为训练出的语言模型的类型(type),例如可列举ARPA语言模型、DNN语言模型、RNN语言模型和随机场(RF)语言模型,也可以是其他语言模型。
如图2的P5所示,在本实施方式中,以4-gram ARPA语言模型为例,将其作为基于类的语言模型。
返回图5,在语言模型训练单元110基于分类的结果训练基于类的语言模型后,向量拼接单元120将上述基于类的语言模型的输出向量与上述神经网络语言模型的位置指示向量拼接,作为上述神经网络语言模型2的输入向量。
以下,参照图3的框图,对向量拼接单元120所执行的处理的一例进行说明,在图3中以与词(t)对应的位置指示向量和基于类的语言模型的输出向量为例进行说明。
R1表示词典,本实施方式中,词典R1例如含有10000个词。
如R2、R3所示,词典中的10000个词“……词(t-n+1)……词(t-1)词(t)词(t+1)……”被以315种词性进行分类,得到对应的R3中的“……词性(t-n+1)……词性(t-1)词性(t)词性(t+1)……”。
R4的4-gram ARPA LM为由语言模型训练单元110训练出的基于类的语言模型,其以315种词性为分类方式。
R6表示位置指示向量。
以下,参照图3,以位置指示向量R6为例对位置指示向量进行说明。
位置指示向量是常规神经网络语言模型的每个词汇的特征,维数与词 典中词汇的数量相同,将对应某词汇在词典中的位置的元素标为“1”,而其他元素均为“0”,由此,位置指示向量包含了词汇在词典中的位置信息。
在本实施方式中,词典R1包含10000个词汇,所以位置指示向量R6的维数为10000维,在图3中,R6中的每一个格代表一个维数,图3中仅示出了一部分维数。
位置指示向量R6中的黑实心格R61与词汇在词典中的位置相对应,黑实心格代表“1”,一个位置指示向量中仅存在一个黑实心格。除了黑实心格R61之外,R6中还存在9999个空心格,空心格代表“0”,在此,仅示出了一部分空心格。
图3中的黑实心格与R2中的词(t)的位置相对应,所以位置指示向量R6包含了词(t)在词典R1中的位置信息。
R5表示基于类的语言模型的输出向量。
以下,参照图3,以基于类的语言模型的输出向量R5为例对基于类的语言模型的输出向量进行说明。在以下说明中,将基于类的语言模型的输出向量R5简称为输出向量R5。
输出向量R5也是一个多维向量,其表示语言模型R4的概率输出。
如上所述,在训练语言模型R4时,以315种词性进行了分类。
输出向量R5的维数与分类的结果对应,是315维的向量,并且每一维的位置代表315种词性中的某个具体词性,每一维的数值代表是315种词性中的某个具体词性的概率。
并且,在R4为n-gram语言模型时,能够根据前n-1个词的词性来算出第n个词是某个词性的概率。
在本实施方式中,作为例子,语言模型R4是4-gram语言模型,所以能够根据前3个词(即,词(t)词(t-1)词(t-2))的词性来算出第4个词(即,词(t+1))是315种词性中的某个词性的概率,即能够算出上述词(t)的下一个词是哪个词性的概率。
在图3中,R5中的每一格代表一个维数,也就是说每一个格对应于315种词性种的某个词性,每一个格的数值代表下个词是某个具体词性的 概率,是0以上且1以下的值,所以用灰实心格进行示出。图3中仅示出了一部分的维数。
以上,以R4为4-gram语言模型为例进行了说明,特别地,在R4为1-gram语言模型时,在输出向量R5中,与当前的词(t)的词性对应的位置(即,R5中的某个格)的数值成为1,其余格的位置均为0。
在得到了与词(t)对应的位置指示向量R6和输出向量R5后,将位置指示向量R6与输出向量R5拼接,将拼接后的向量作为神经网络语言模型的输入向量来训练神经网络语言模型,由此得到R7的神经网络语言模型。
此处,“拼接”是指位置指示向量R6与输出向量R5的维数的相加,在如上述那样位置指示向量R6为10000维,输出向量R5为315维的情况下,拼接后的向量成为10315维的向量。
在本实施例中,在拼接后的10315维的向量中,包含词(t)在词典R1中的位置信息和词(t+1)是315种词性中的某个词性的概率的信息。
在本实施方式中,根据改进语言模型的装置10,将基于类的语言模型的向量作为附加特征加入神经网络语言模型的输入向量,能够提高神经网络语言模型对词序列出现概率的学习和预测能力。
另外,在本实施方式中,根据改进语言模型的装置10,分类标准多种多样(例如词性、语义、语用信息等),同一分类标准也有不同的分类方式(例如,对于词性分类有100种词性分类和315种词性分类等),同一分类标准也有不同上下文阶数(例如3-gram、4-gram等)的语言模型,语言模型也有多种选择(例如APRA语言模型、DNN语言模型、RNN语言模型和RF语言模型等),因此能够提高对词典中的词分类的多样性,与此相应,也能提高训练出的基于类的语言模型的多样性,得到多种以基于类的语言模型的得分为附加特征而改进了的神经网络语言模型,在将这些神经网络语言模型进行融合时可进一步提高识别准确率,提高识别性能。
语音识别装置
图6是在同一发明构思下的本发明的语音识别装置的框图。下面就结合该图,对本实施方式进行描述。对于那些与前面实施方式相同的部分,适当省略其说明。
本实施方式提供一种语音识别装置20,具备:语音输入单元200,其用于输入待识别的语音3;文本句识别单元210,其利用声学模型将上述语音识别为文本句;和得分计算单元220,其利用语言模型计算上述文本句的得分;所述语言模型包括由上述实施方式中的改进语音识别系统的神经网络语言模型的装置改进后的语言模型。
在本实施方式中,从语音输入单元200输入待识别的语音,然后文本句识别单元210利用声学模型将上述语音识别为文本句。
在由文本句识别单元210识别出文本句后,得分计算单元220利用通过上述改进语言模型的方法改进后的语言模型计算上述文本句的得分,根据得分生成识别结果。
由此,根据本实施方式的语音识别装置20,由于使用了提高了对词序列出现概率的学习和预测能力的神经网络语言模型,所以能够提高语言识别方法的识别准确率。
另外,得分计算单元220也可以利用两个以上的语言模型分别计算得分,将计算出的得分的加权平均值作为文本句的得分。
其中,该两个以上的语言模型只要其中至少一个是上述的改进后的语言模型即可,可以全部是改进后的语言模型,也可以一部分是改进后的语言模型,而另一部分是ARPA语言模型等公知的各种语言模型。
由此,含有不同附加特征的神经网络语言模型能够进一步融合,可进一步提高语言识别方法的识别准确率。
关于得分计算单元220所使用的改进后的语言模型,使用按照上述的改进神经网络语言模型的方法改进后的神经网络语言模型即可,其改进的过程已在改进神经网络语言模型的方法中详细叙述,在此省略详细的说明。
以上虽然通过一些示例性的实施方式详细地描述了本发明的改进语音识别系统的神经网络语言模型的方法、改进语音识别系统的神经网络语言 模型的装置、语言识别方法以及语音识别装置,但是以上这些实施方式并不是穷举的,本领域技术人员可以在本发明的精神和范围内实现各种变化和修改。因此,本发明并不限于这些实施方式,本发明的范围仅由所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!