话音简档管理和语音信号产生的制作方法
本申请案主张共同所有的2014年4月30日申请的第61/986,701号美国临时专利申请案和2015年4月29日申请的第14/700,009号美国非临时专利申请案的优先权,以上申请案的内容明确地以全文引用的方式并入本文中。
技术领域
本发明大体上涉及话音简档管理和语音信号产生。
背景技术:
技术的进步已经产生了更小且更强大的计算装置。举例来说,当前存在各种便携式个人计算装置,包括无线计算装置,例如较小、轻重量且易于由用户携带的便携式无线电话、个人数字助理(PDA)和寻呼装置。更具体地说,便携式无线电话,例如蜂窝电话和因特网协议(IP)电话,可经由无线网络传送话音和数据包。另外,许多此类无线电话包括并入其中的其它类型的装置。举例来说,无线电话还可包含数字静态相机、数码摄像机、数字记录器和音频文件播放器。并且,此类无线电话可处理可执行指令,包含软件应用程序,例如可用以接入因特网的网络浏览器应用程序。由此,这些无线电话可包含大量计算能力。
通过数字技术发射话音是普遍的,尤其在长距离和数字无线电电话应用中。可存在确定对可经由信道发送的最少量的信息同时维持经重构语音的感知质量的关注。如果通过取样和数字化来发射语音,那么可使用约六十四千位每秒(kbps)的数据速率来实现模拟电话的语音质量。通过在接收器处使用语音分析,接着译码、发射和重新合成,可实现数据速率的显著减小。
用于压缩语音的裝置可用于许多电信领域中。示范性领域为无线通信。无线通信的领域具有许多应用,包括(例如)无绳电话、寻呼、无线本地回路、例如蜂窝式和个人通信服务(PCS)电话系统的无线电话、移动因特网协议(IP)电话和卫星通信系统。特定应用是用于移动订户的无线电话。
已开发了用于无线通信系统的各种空中接口,包含(例如)频分多址(FDMA)、时分多址(TDMA)、码分多址(CDMA)和时分同步CDMA(TD-SCDMA)。在与其的连接中,已经建立各种国内和国际标准,包含例如高级移动电话服务(AMPS)、全球移动通信系统(GSM)和过渡标准95(IS-95)。示范性无线电话通信系统为码分多址(CDMA)系统。IS-95标准及其衍生标准、IS-95A、ANSI J-STD-008和IS-95B(本文中共同称作IS-95)由电信行业协会(TIA)和其它公认标准机构颁布以指定CDMA空中接口针对蜂窝式或PCS电话通信系统的使用。
IS-95标准随后演进成例如cdma2000和WCDMA的“3G”系统,所述“3G”系统提供更大容量和高速包数据服务。cdma2000的两个变体由TIA发布的文献IS-2000(cdma2000 1xRTT)和IS-856(cdma2000 1xEV-DO)呈现。cdma2000 1xRTT通信系统提供153kbps的峰值数据速率,而cdma2000 1xEV-DO通信系统定义范围介于38.4kbps到2.4Mbps的一组数据速率。WCDMA标准实施于第三代合作伙伴计划“3GPP”文献3G TS 25.211、3G TS 25.212、3G TS 25.213和3G TS 25.214中。国际移动电信高级(IMT-高级)规范陈述“4G”标准。对于高移动性通信(例如,来自火车和汽车),高级IMT规范设定100兆位/秒(Mbit/s)的峰值数据速率用于4G服务,且对于低移动性通信(例如,来自行人和静止用户),高级IMT规范设定1千兆比特/秒(Gbit/s)的峰值数据速率用于4G服务。
使用通过提取关于人类语音生成模型的参数来压缩语音的技术的裝置被称为语音译码器。语音译码器可包括编码器和解码器。编码器将传入语音信号划分成时间块或分析帧。可将每一时间区段(或“帧”)的持续时间选择为足够短,使得可预期信号的频谱包络保持相对固定。举例来说,一个帧长度为二十毫秒,其对应于八千赫兹(kHz)取样速率下的160个样本,但可使用认为适合于特定应用的任何帧长度或取样速率。
编码器分析传入语音帧以提取某些相关参数,且随后将参数量化成二进制表示(例如,一组位或二进制数据包)。经由通信信道(即,有线和/或无线网络连接)将数据包发射到接收器和解码器。解码器处理所述数据包、去量化经处理的数据包以产生参数,并使用经去量化参数来重新合成语音帧。
语音译码器的功能是通过去除语音中固有的自然冗余来将经数字化的语音信号压缩成低位速率信号。可通过用一组参数表示输入语音帧且使用量化来用一组位表示所述参数来实现数字压缩。如果输入语音帧具有若干位Ni,且语音译码器产生的数据包具有若干位No,那么语音译码器所实现的压缩因子是Cr=Ni/No。挑战是在实现目标压缩因子时保留经解码语音的高话音质量。语音译码器的性能取决于:(1)语音模型或上文所描述的分析和合成过程的组合执行得多好,以及(2)在No位每帧的目标位速率下参数量化过程执行得多好。因此,语音模型的目标是在每一帧具有较小一组参数的情况下,捕获语音信号的本质或目标语音质量。
语音译码器通常利用一组参数(包含向量)来描述语音信号。良好的一组参数为感知上准确的语音信号的重构理想地提供低系统带宽。音调、信号功率、谱包络(或共振峰)、振幅和相谱是语音译码参数的实例。
语音译码器可实施为时域译码器,其试图通过利用高时间分辨率处理以一次编码较小语音片段(例如,5毫秒(ms)的子帧)来捕获时域语音波形。对于每一子帧,借助于搜索算法来找出来自码簿空间的高精确代表。或者,语音译码器可实施为频域译码器,其试图用一组参数(分析)来捕获输入语音帧的短期语音谱,并利用对应的合成过程来从谱参数再造语音波形。参数量化器通过根据已知量化技术用代码向量的所存储表示来表示参数而保留所述参数。
一种时域语音译码器是代码激发线性预测性(CELP)译码器。在CELP译码器中,通过找出短期共振峰滤波器的系数的线性预测(LP)分析来去除语音信号中的短期相关性或冗余。将短期预测滤波器应用于传入语音帧生成LP残余信号,用长期预测滤波器参数和后续随机码簿对所述LP残余信号进行进一步模型化和量化。因此,CELP译码将编码时域语音波形的任务划分成编码LP短期滤波器系数和编码LP残余的单独任务。可以固定速率(即,针对每一帧使用相同位数No)或以可变速率(其中针对不同类型的帧内容使用不同的位速率)执行时域译码。可变速率译码器尝试使用将编解码器参数编码到足以获得目标质量的层级所需要的位的量。
例如CELP译码器等时域译码器可依靠每帧的高位数No来保留时域语音波形的准确性。假如每帧的位数No相对较大(例如,8kbps或以上),那么此类译码器可传递极好的话音质量。在低位速率(例如,4kbps和以下)下,归因于受限数目个可用位,时域译码器可未能保持高品质和稳健性能。在低位速率下,受限码簿空间削减在较高速率商业应用中所部署的时域译码器的波形匹配能力。因此,不管随时间的改进,以低位速率操作的许多CELP译码系统经受被表征为噪声的感知上显著的失真。
低位速率下的CELP译码器到替代方案是“噪声激发线性预测性”(NELP)译码器,其在与CELP译码器类似的原理下操作。NELP译码器使用经滤波伪随机噪声信号而非码簿来模型化语音。由于NELP针对经译码语音使用较简单的模型,因此NELP实现比CELP低的位速率。NELP可用于压缩或表示无声语音或静默。
约2.4kbps的速率操作的译码系统在本质上大体上是参数的。就是说,此类译码系统通过以规则间隔发射描述语音信号的音调周期和谱包络(或共振峰)的参数来操作。这些所谓的参数译码器的说明是LP声码器系统。
LP声码器以每音调周期单个脉冲来模型化有声语音信号。此基本技术可经扩增以包含发射关于谱包络的信息等等。尽管LP声码器一般来说提供合理的性能,但它们可能引入表征为蜂音的感知上相当大的失真。
近年来,已出现了作为波形译码器和参数译码器两者的混合的译码器。这些所谓的混合译码器中的说明性混合译码器是原型波形内插(PWI)语音译码系统。PWI译码系统还可被称为原型音调周期(PPP)语音译码器。PWI译码系统提供用于译码有声语音的高效方法。PWI的基本概念是以固定间隔提取代表性音调循环(原型波形),发射其描述,以及通过原型波形之间的内插来重构语音信号。PWI方法可对LP残余信号或所述语音信号操作。
可存在对改善语音信号(例如,经译码语音信号、经重构语音信号或这两者)的音频质量的研究关注和商业关注。举例来说,通信装置可接收具有低于最佳话音质量的语音信号。为了说明,通信装置可在话音呼叫期间从另一通信装置接收语音信号。话音呼叫质量可能由于各种原因而受影响,例如环境噪声(例如,风、道路噪声)、通信装置的接口的限制、通信装置的信号处理、丢包、带宽限制、位速率限制等等。
技术实现要素:
在特定方面,一种装置包含接收器、存储器和处理器。所述接收器经配置以接收远程话音简档。所述存储器电耦合到所述接收器。所述存储器经配置以存储与人相关联的本地话音简档。所述处理器电耦合到所述存储器和所述接收器。所述处理器经配置以基于与所述远程话音简档相关联的语音内容或与所述远程话音简档相关联的识别符而确定所述远程话音简档与所述人相关联。所述处理器还经配置以基于所述确定而选择所述本地话音简档用于简档管理。
在另一方面,一种用于通信的方法包含在存储本地话音简档的装置处接收远程话音简档,所述本地话音简档与人相关联。所述方法还包含基于所述远程话音简档与所述本地话音简档的比较或基于与所述远程话音简档相关联的识别符而确定所述远程话音简档与所述人相关联。所述方法进一步包含在所述装置处基于所述确定而选择所述本地话音简档用于简档管理。
在另一方面,一种装置包含存储器和处理器。所述存储器经配置以存储多个代替语音信号。所述处理器电耦合到所述存储器。所述处理器经配置以从文字到语音转换器接收语音信号。所述处理器还经配置以检测多个使用模式中的使用模式。所述处理器进一步经配置以选择多个人口统计域中的人口统计域。所述处理器还经配置以基于所述语音信号、所述人口统计域和所述使用模式而选择所述多个代替语音信号中的代替语音信号。所述处理器进一步经配置以基于所述代替语音信号而产生经处理语音信号。所述处理器还经配置以将所述经处理语音信号提供到至少一个扬声器。
本发明的其它方面、优点和特征将在审阅全部申请案之后变得显而易见,所述申请案包含以下章节:附图说明、具体实施方式和权利要求书。
附图说明
图1是可操作以替换语音信号的系统的特定说明性方面的框图;
图2是可操作以替换语音信号的系统的另一说明性方面的图;
图3是可操作以替换语音信号的系统可显示的用户接口的特定说明性方面的图;
图4是可操作以替换语音信号的系统的另一说明性方面的图;
图5是可操作以替换语音信号的系统的另一说明性方面的图;
图6是可操作以替换语音信号的系统的另一说明性方面的图;
图7是可操作以替换语音信号的系统的另一说明性方面的图;
图8是可操作以替换语音信号的系统的另一说明性方面的图;
图9是可操作以替换语音信号的系统的另一说明性方面的图;
图10是可操作以替换语音信号的系统可使用的数据库的说明性方面的图;
图11是可操作以替换语音信号的系统的另一说明性方面的图;
图12是可操作以替换语音信号的系统的另一说明性方面的图;
图13是可操作以替换语音信号的系统的另一说明性方面的图;
图14是说明替换语音信号的方法的特定方面的流程图;
图15是说明获取多个代替语音信号的方法的特定方面的流程图且可对应于图11的操作802;
图16是说明替换语音信号的方法的另一方面的流程图;
图17是说明产生用户接口的方法的另一方面的流程图;
图18是说明替换语音信号的方法的另一方面的流程图;以及
图19是根据图1到18的系统和方法的可操作以替换语音信号的装置的特定说明性方面的框图。
具体实施方式
本文所述的原理可例如应用于经配置以执行语音信号替换的头戴装置、手持机或其它音频装置。除非通过其上下文明确限制,否则在本文中使用术语“信号”来指示其一般含义中的任一者,包含如在导线、总线或其它传输媒体上表达的存储器位置的状态(或存储器位置的集合)。除非通过其上下文明确地限制,否则在本文中使用术语“产生”来指示其一般含义中的任一者,例如计算或以其它方式产生。除非通过其上下文明确限制,否则在本文中使用术语“计算”来指示其一般含义中的任一者,例如计算、评估、估计,及/或从多个值中选择。除非通过其上下文明确限制,否则在本文中使用术语“获得”来指示其一般含义中的任一者,例如计算、导出、接收(例如,从另一组件、块或装置)和/或检索(例如,从存储器寄存器或存储元件阵列)。
除非通过其上下文明确地限制,否则使用术语“产生”来指示其一般含义中的任一者,例如计算、产生和/或提供。除非通过其上下文明确地限制,否则使用术语“提供”来指示其一般含义中的任一者,例如计算、产生和/或生成。除非通过其上下文明确地限制,否则使用术语“耦合”来指示直接或间接电或物理连接。如果连接是间接的,那么所属领域的技术人员将充分理解,正“耦合”的结构之间可存在其它块或组件。
术语“配置”可参考如通过其特定上下文指示的方法、设备/装置和/或系统来使用。在本发明描述及权利要求书中使用术语“包括”时,并不排除其它元素或操作。使用术语“基于”(如在“A基于B”中)来指示其普通含义中的任一者,包含情况(i)“至少基于”(例如“A至少基于B”),以及(如果在特定上下文中合适)(ii)“等于”(例如“A等于B”)。在其中A基于B包含至少基于的情况(i)下,此可包含其中A耦合到B的配置。类似地,使用术语“响应于”来指示其普通含义中的任一者,包含“至少响应于”。使用术语“至少一个”来指示其普通含义中的任一者,包含“一或多个”。使用术语“至少两个”来指示其普通含义中的任一者,包含“两个或两个以上”。
除非特定上下文另有指示,否则术语“设备”与“装置”也通用地且可互换地使用。除非另有指示,否则对具有特定特征的设备的操作的任何揭示内容还明确地希望揭示具有类似特征的方法(且反之亦然),且对根据特定配置的设备的操作的任何揭示内容还明确地希望揭示根据类似配置的方法(且反之亦然)。除非特定上下文另有指示,否则术语“方法”、“过程”、“程序”及“技术”通用地且可互换地使用。术语“元件”和“模块”可用于指示较大配置的一部分。通过参考文档的一部分进行的任何并入也应理解为并入了在所述部分内参考的术语或变量的定义,其中此类定义出现在文档中的其它地方,以及并入了在所并入部分中参考的任何图。
如本文所使用,术语“通信装置”是指可用于经由无线通信网路进行话音和/或数据通信的电子装置。通信装置的实例包含蜂窝式电话、个人数字助理(PDA)、手持式裝置、耳机、无线调制解调器、膝上型计算机、个人计算机等。
参考图1,揭示可操作以替换语音信号的系统的特定说明性方面且一般指定为100。系统100可包含经由网络120与一或多个其它装置(例如,移动装置104、桌上型计算机106等)通信的第一装置102。移动装置104可耦合到麦克风146或与其通信。桌上型计算机106可耦合到麦克风144或与其通信。第一装置102可耦合到一或多个扬声器142。第一装置102可包含信号处理模块122和第一数据库124。第一数据库124可经配置以存储代替的语音信号112。
第一装置102可包含与图1中所说明相比更少或更多的组件。举例来说,第一装置102可包含一或多个处理器、一或多个存储器单元或这两者。第一装置102可包含联网或分布式计算系统。在特定说明性方面中,第一装置102可包含移动通信装置、智能电话、蜂窝式电话、膝上型计算机、计算机、平板计算机、个人数字助理、显示装置、电视、游戏控制台、音乐播放器、无线电、数字视频播放器、数字视频光盘(DVD)播放器、调谐器、相机、导航装置或其组合。此类装置可包含用户接口(例如,触摸屏、话音辨识能力或其它用户接口能力)。
在操作期间,第一装置102可接收用户语音信号(例如,第一用户语音信号130、第二用户语音信号132或这两者)。举例来说,第一用户152可参与与第二用户154的话音呼叫。第一用户152可使用第一装置102且第二用户154可使用移动装置104用于所述话音呼叫。在话音呼叫期间,第二用户154可对耦合到移动装置104的麦克风146说话。第一用户语音信号130可对应于第二用户154说出的多个词、一个词或一个词的一部分。移动装置104可经由麦克风146从第二用户154接收第一用户语音信号130。在特定方面,麦克风146可俘获音频信号且模/数转换器(ADC)可将所俘获音频信号从模拟波形转换为由数字音频样本构成的数字波形。数字音频样本可由数字信号处理器处理。增益调节器可通过增加或减小音频信号的振幅电平(例如模拟波形或数字波形)来调节(例如模拟波形或数字波形的)增益。增益调节器可在模拟或数字域中操作。举例来说,增益调节器可在数字域中操作,且可调节模/数转换器所产生的数字音频样本。在增益调节之后,回声消除器可减少可能已因扬声器的输出进入麦克风146而产生的任何回声。数字音频样本可由声码器(话音编码器-解码器)“压缩”。回声消除器的输出可耦合到声码器预处理块,例如滤波器、噪声处理器、速率转换器等。声码器的编码器可压缩数字音频样本且形成发射包(数字音频样本的经压缩位的表示)。发射包可存储于可与移动装置104的处理器共享的存储器中。所述处理器可为与数字信号处理器通信的控制处理器。
移动装置104可经由网络120将第一用户语音信号130发射到第一装置102。举例来说,移动装置104可包含收发器。收发器可调制某一形式(其它信息可附加到发射包)的发射包,并经由天线在空中发送经调制的信息。
第一装置102的信号处理模块122可接收第一用户语音信号130。举例来说,第一装置102的天线可接收某一形式的传入包,其包括发射包。声码器的解码器可能在第一装置102处“未压缩”发射包。所述未压缩波形可被称为经重构音频样本。经重构的音频样本可由声码器后处理块进行后处理,且可由回声消除器用来去除回声。为清楚起见,声码器的解码器和声码器后处理块可被称为声码器解码器模块。在一些配置中,回声消除器的输出可由信号处理模块122处理。替代地,在其它配置中,声码器解码器模块的输出可由信号处理模块122处理。
如由第一装置102接收的第一用户语音信号130的音频质量可低于第二用户154发送的第一用户语音信号130的音频质量。第一用户语音信号130的音频质量可能在向第一装置102的发射期间由于各种原因而劣化。举例来说,第二用户154可能在话音呼叫期间处于有噪声的位置(例如,繁忙的街道、音乐会等)。由麦克风146接收的第一用户语音信号130可包含除第二用户154说出的词之外的声音。作为另一实例,麦克风146可具有俘获声音的有限能力,移动装置104可以丢失一些声音信息的方式处理声音,在对应于第一用户语音信号130的包的发射期间网络120内可存在丢包,或其任何组合。
信号处理模块122可将语音信号(例如,第一用户语音信号130、第二用户语音信号132或这两者)的一部分与代替语音信号112中的一或多者进行比较。举例来说,第一用户语音信号130可对应于第二用户154说出的词(例如,“cat”)且第一用户语音信号130的第一部分162可对应于所述词的一部分(例如,“c”、“a”、“t”、“ca”、“at”或“cat”)。信号处理模块122可基于所述比较而确定第一部分162匹配于代替语音信号112的第一代替语音信号172。举例来说,第一部分162和第一代替语音信号172可表示共同声音(例如,“c”)。所述共同声音可包含音素、双音素、三音素、音节、词或其组合。
在特定方面,甚至当第一部分162和第一代替语音信号172并不表示共同声音(例如样本的有限集合)时,信号处理模块122也可确定第一部分162匹配于第一代替语音信号172。第一部分162可对应于第一样本集合(例如,词“do”)且第一代替语音信号172可对应于第二样本集合(例如,词“to”)。举例来说,与代替语音信号112中的其它代替语音信号相比,信号处理模块122可确定第一部分162与第一代替语音信号172具有较高相似性。
第一代替语音信号172可具有比第一部分162高的音频质量(例如,较高信噪比值)。举例来说,代替语音信号112可对应于先前记录的由第二用户154说出的词或词的部分,如参考图2进一步描述。
在特定方面,信号处理模块122可通过将对应于第一部分162的波形与对应于第一代替语音信号172的另一波形进行比较而确定第一部分162匹配于第一代替语音信号172。在特定方面,信号处理模块122可将对应于第一部分162的特征的子集与对应于第一代替语音信号172的特征的另一子集进行比较。举例来说,信号处理模块122可通过将对应于第一部分162的多个语音参数与对应于第一代替语音信号172的另外多个语音参数进行比较而确定第一部分162匹配于第一代替语音信号172。所述多个语音参数可包含音调参数、能量参数、线性预测译码(LPC)参数、梅尔频率倒谱系数(MFCC)、线谱对(LSP)、线谱频率(LSF)、倒谱、线谱信息(LSI)、离散余弦变换(DCT)参数(例如,系数)、离散傅立叶变换(DFT)参数、快速傅立叶变换(FFT)参数、共振峰频率,或其任何组合。信号处理模块122可使用向量量化器、隐式马尔可夫模型(HMM)或高斯混合模型(GMM)中的至少一者确定所述多个语音参数的值。
信号处理模块122可通过以第一代替语音信号172替换第一用户语音信号130的第一部分162而产生经处理语音信号(例如,第一经处理语音信号116)。举例来说,信号处理模块122可复制第一用户语音信号130且可从所复制用户语音信号移除第一部分162。信号处理模块122可通过在所复制用户语音信号的其中第一部分162被移除的位置处串接(例如,拼接)第一代替语音信号172和所复制用户语音信号而产生第一经处理语音信号116。
在特定方面,第一经处理语音信号116可包含多个代替语音信号。在特定方面,信号处理模块122可拼接第一代替语音信号172与另一代替语音信号以产生中间代替语音信号。在此方面中,信号处理模块122可在其中第一部分162被移除的位置处拼接中间代替语音信号与所复制用户语音信号。在替代方面中,可迭代地产生第一经处理语音信号116。在第一迭代期间,信号处理模块122可通过在其中第二部分从所复制用户语音信号移除的位置处拼接另一代替语音信号与所复制用户语音信号而产生中间经处理语音信号。所述中间经处理语音信号可在后续迭代期间对应于第一用户语音信号130。举例来说,信号处理模块122可从中间经处理语音信号移除第一部分162。信号处理模块122可通过在其中第一部分162被移除的位置处拼接第一代替语音信号172和中间经处理语音信号而产生第一经处理语音信号116。
此些拼接和复制操作可由处理器对音频信号的数字表示执行。在特定方面,第一经处理语音信号116可由增益调节器放大或抑制。第一装置102可经由扬声器142将第一经处理语音信号116输出到第一用户152。举例来说,增益调节器的输出可通过数/模转换器从数字信号转换到模拟信号,且经由扬声器142播放出。
在特定方面,移动装置104可在将第一用户语音信号130发送到第一装置102之前修改与第一用户语音信号130相关联的一或多个语音参数。在特定方面,移动装置104可包含信号处理模块122。在此方面中,所述一或多个语音参数可由移动装置104的信号处理模块122修改。在特定方面,移动装置104可具有对代替语音信号112的存取。举例来说,移动装置104可能已先前从服务器接收代替语音信号112,如参考图2进一步描述。
移动装置104可修改所述一或多个语音参数以辅助信号处理模块122在将第一用户语音信号130的第一部分162与代替语音信号112进行比较时找到匹配。举例来说,移动装置104可确定第一代替语音信号172(例如,对应于来自“catatonic”的“c”)是针对第一用户语音信号130(例如,“cat”)的第一部分162(例如,“c”)的比第二代替语音信号174(例如,对应于来自“cola”的“c”更好的匹配)。移动装置104可修改第一部分162的一或多个语音参数以辅助信号处理模块122确定第一代替语音信号172是比第二代替语音信号174更好的匹配。举例来说,移动装置104可修改音调参数、能量参数、线性预测译码(LPC)参数或其组合,以使得经修改参数更接近第一代替语音信号172的对应参数而非第二代替语音信号174的对应参数。
在特定方面,移动装置104可将一或多个发射参数发送到第一装置102。在特定方面,移动装置104的信号处理模块122可将发射参数发送到第一装置102。所述发射参数可识别移动装置104已确定为针对第一部分162的匹配的特定代替语音信号(例如,第一代替语音信号172)。作为另一实例,所述发射参数可包含特定向量量化器表条目索引号以辅助第一装置102在向量量化器表中定位特定向量量化器。
经修改语音参数、发射参数或这两者可辅助信号处理模块122选择匹配于第一部分162的代替语音信号。产生经处理语音信号(例如,第一经处理语音信号116、第二经处理语音信号118)的效率也可增加。举例来说,当发射参数识别特定代替语音信号(例如,第一代替语音信号172)时,信号处理模块122可不将第一部分162与代替语音信号112中的每一者进行比较,从而导致产生第一经处理语音信号116的增加的效率。
在特定方面,第一装置102的信号处理模块122可使用词预测算法来预测可包含第一部分162的词。举例来说,所述词预测算法可基于在第一用户语音信号130之前的词来预测词。为了说明,所述词预测算法可基于与词和先前词相关的主语-动词协定、词关系、语法规则或其组合而确定所述词。作为另一实例,所述词预测算法可基于先前词中的词的频率而确定所述词,其中所述词包含对应于第一部分162的声音。为了说明,特定词可以在特定对话中频繁地重复。信号处理模块122可基于先前词包含词“cat”大于阈值次数(例如,2)而预测对应于“c”的第一部分162是词“cat”的部分。信号处理模块122可基于所述预测词选择第一代替语音信号172。举例来说,第一代替语音信号172、代替语音信号112中的另一代替语音信号以及第一部分162可全部对应于共同声音(例如,“c”)。信号处理模块122可确定第一代替语音信号172是从“catatonic”产生且另一代替语音信号是从“cola”产生。信号处理模块122可基于确定第一代替语音信号172比另一代替语音信号更接近预测词而选择第一代替语音信号172而非另一代替语音信号172。
在特定方面,信号处理模块122可确定经处理语音信号(例如,第一经处理语音信号116或第二经处理语音信号118)不满足语音信号阈值。举例来说,信号处理模块122可确定第一经处理语音信号116的语音参数的变化不满足阈值语音参数变化。为了说明,语音参数的变化可对应于第一代替语音信号172与第一经处理语音信号116的另一部分之间的转变。在特定方面,信号处理模块122可使用平滑算法修改第一经处理语音信号116以减少语音参数的变化。在另一特定的方面中,信号处理模块122可响应于语音参数的变化不满足阈值语音参数而丢弃第一经处理语音信号116。在此方面中,信号处理模块122可经由扬声器142将第一用户语音信号130输出到第一用户152。
在特定方面,第一装置102可基于接收到用户输入而在输出经处理语音信号(例如,第一经处理语音信号116、第二经处理语音信号118)与用户语音信号(例如,第一用户语音信号130、第二用户语音信号132)之间切换。举例来说,第一装置102可从第一用户152接收指示将激活语音信号替换的第一输入。响应于第一输入,第一装置102可经由扬声器142输出第一经处理语音信号116。作为另一实例,第一装置102可从第一用户152接收指示将去活语音信号替换的第二输入。响应于第二输入,第一装置102可经由扬声器142输出第一用户语音信号130。在特定方面,信号处理模块122可包含用户接口以使得用户(例如,第一用户152)能够管理代替语音信号112。在此方面中,第一装置102可经由信号处理模块122的用户接口接收第一输入、第二输入或这两者。
在特定方面,信号处理模块122可在话音呼叫(例如,第一用户152与第二用户154之间的呼叫)期间接收第一用户语音信号130,且可在所述话音呼叫期间产生第一经处理语音信号116。在另一特定的方面中,信号处理模块122可接收第一用户语音信号130(例如,作为来自第二用户154的消息)且可随后产生第一经处理语音信号116且可存储第一经处理语音信号116用于稍后重放给第一用户152。
在特定方面,信号处理模块122可使用代替语音信号112来替换用户语音信号(例如,第一用户语音信号130、第二用户语音信号132)的对应于特定用户(例如,第二用户154)的一部分,而与哪一装置(例如,桌上型计算机106、移动装置104)发送所述用户语音信号无关。举例来说,信号处理模块122可经由麦克风144、桌上型计算机106和网络120从第二用户154接收第二用户语音信号132。信号处理模块122可通过以代替语音信号112中的第二代替语音信号174替换第二用户语音信号132的第二部分164而产生第二经处理语音信号118。
在特定方面,信号处理模块122可基于用户语音信号(例如,第一用户语音信号130、第二用户语音信号132)产生经修改代替语音信号(例如,经修改代替语音信号176)。举例来说,第一用户语音信号130的第一部分162和第一代替语音信号172可对应于共同声音且可各自对应于由第二用户154使用的不同音调或拐点。举例来说,第一用户语音信号130可对应于第二用户154的惊讶话语,而第一代替语音信号172可对应于平静话语。信号处理模块122可通过基于对应于第一用户语音信号130的语音参数而修改第一代替语音信号172来产生经修改代替语音信号176。举例来说,信号处理模块122可修改第一代替语音信号172的音调参数、能量参数或线性预测译码参数中的至少一者以产生经修改代替语音信号176。信号处理模块122可将经修改代替语音信号176添加到第一数据库124中的代替语音信号112。在特定方面,第一装置102可将经修改代替语音信号176发送到服务器,所述服务器维持与第二用户154相关联的代替语音信号112的副本。
因此,系统100可实现语音信号的替换。与特定用户相关联的用户语音信号的一部分可被与同一用户相关联的较高音频质量代替语音信号替换。
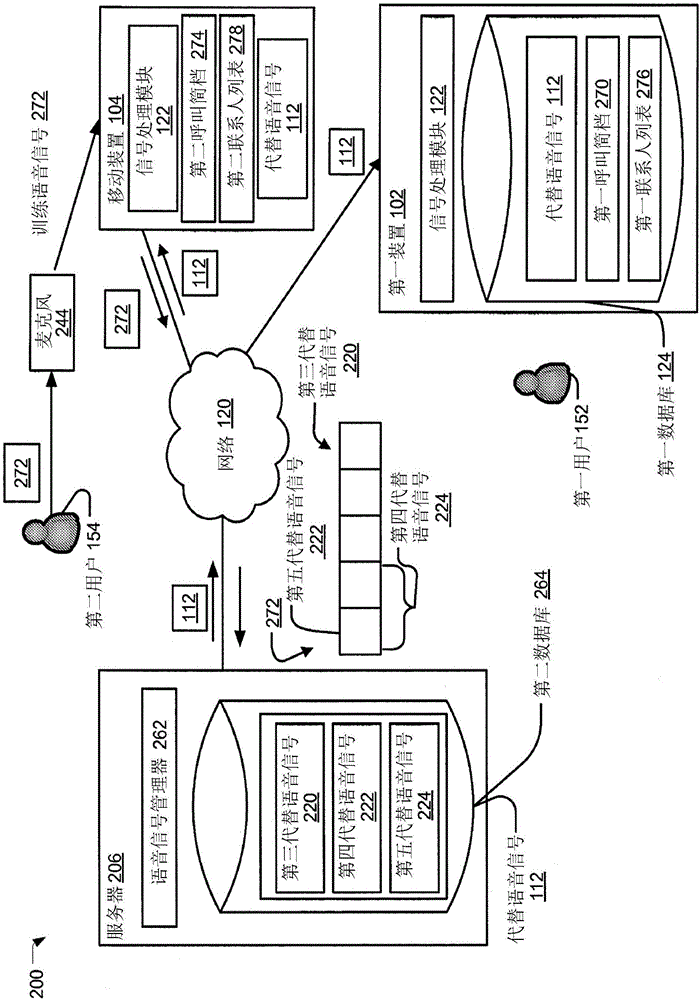
参考图2,揭示可操作以替换语音信号的系统的特定说明性方面且一般指定为200。系统200可包含服务器206,其经由图1的网络120耦合到第一装置102和移动装置104或与它们通信。移动装置104可包含图1的信号处理模块122。服务器206可包含语音信号管理器262和第二数据库264。
图2说明由第一装置102、移动装置104或这两者获取代替语音信号112。在操作期间,第二用户154可将训练语音信号(例如,训练语音信号272)发送到服务器206。举例来说,第二用户154可为新雇员且可被要求阅读文字的脚本作为雇员导向的部分。第二用户154可通过对着移动装置104的麦克风244阅读词的脚本而发送训练语音信号272。举例来说,第二用户154可以用为了在安静环境中阅读所述脚本的目的而设置的声音小室中阅读脚本。移动装置104的信号处理模块122可经由网络120将训练语音信号272发送到服务器206。
语音信号管理器262可从训练语音信号272产生代替语音信号112。举例来说,训练语音信号272可对应于词(例如,“catatonic”)。语音信号管理器262可复制训练语音信号272的特定部分以产生代替语音信号112中的每一者。为了说明,语音信号管理器262可复制训练语音信号272以产生第三代替语音信号220(例如,“catatonic”)。语音信号管理器262可复制训练语音信号272的一部分以产生第四代替语音信号224(例如,“ta”)。语音信号管理器262可复制训练语音信号272的另一部分以产生第五代替语音信号222(例如,“t”)。第四代替语音信号224和第五代替语音信号222可对应于训练语音信号272的重叠部分。在特定方面,可复制训练语音信号272的特定部分以基于所述特定部分对应于音素、双音素、三音素、音节、词或其组合而产生代替语音信号。在特定方面,可复制训练语音信号272的特定部分以基于所述特定部分的大小而产生代替语音信号。举例来说,语音信号管理器262可通过复制训练语音信号272的对应于特定信号样本大小(例如,100毫秒)的一部分而产生代替语音信号。
在特定方面,语音信号管理器262可确定对应于特定代替语音信号的声音的文字表示。举例来说,第五代替语音信号222可对应于特定声音(例如,声音“t”)。语音信号管理器262可基于特定声音与对应于所述文字表示的另一语音信号(例如,先前所产生的第二用户154的代替语音信号、对应于另一用户的另一代替语音信号或合成语音信号)的比较而确定特定声音的文字表示(例如,字母“t”)。
语音信号管理器262可将代替语音信号112存储在第二数据库264中。举例来说,语音信号管理器262可将代替语音信号112作为不变的语音、以压缩格式或以另一格式存储在第二数据库264中。语音信号管理器262可将代替语音信号112的选定特征存储在第二数据库264中。语音信号管理器262可将代替语音信号112中的每一者的文字表示存储在第二数据库264中。
服务器206可将代替语音信号(例如,代替语音信号112)发送到装置(例如,移动装置104、第一装置102、桌上型计算机106)。服务器206可将代替语音信号112周期性地发送到装置(例如,移动装置104、第一装置102、桌上型计算机106)。在特定方面,服务器206可响应于从装置(例如,移动装置104、第一装置102、桌上型计算机106)接收到请求而将代替语音信号112发送到装置。在替代方面中,可周期性地或响应于接收到请求而将代替语音信号112从装置(例如,移动装置104、第一装置102或桌上型计算机106)发送到另一装置(例如,移动装置104、第一装置102或桌上型计算机106)。
在特定方面,服务器206可将与第二用户154相关联的代替语音信号112发送到与第二用户154相关联的一或多个装置(例如,移动装置104、桌上型计算机106)。举例来说,第二用户154可通过在安静环境(例如,在家)对麦克风244说话而将训练语音信号272发送到服务器206,且可在移动装置104处从服务器206接收代替语音信号112。与第二用户154相关联的代替语音信号112可由与第二用户154相关联的所述一或多个装置(例如,移动装置104或桌上型计算机106)上的各种应用程序使用。举例来说,第二用户154可随后在有噪声的环境(例如,在音乐会)中使用移动装置104上的话音激活的应用程序。移动装置104的信号处理模块122可以代替语音信号112中的一者替换从第二用户154接收的用户语音信号的一部分以产生经处理语音信号,如参考图1所描述。经处理语音信号可由移动装置104上的话音激活的应用程序使用。因此,移动装置104的话音激活的应用程序可以在有噪声的环境(例如,在有噪声的音乐会)中使用。
作为另一实例,移动装置104上的电子阅读应用程序可使用代替语音信号112来输出音频。所述电子阅读应用程序可输出对应于电子邮件(e-mail)、电子书(e-book)、文章、话音反馈或其任何组合的音频。举例来说,第二用户154可激活电子阅读应用程序以阅读电子邮件。所述电子邮件的一部分可对应于“cat”。代替语音信号112可指示对应于代替语音信号112中的每一者的文字表示。举例来说,代替语音信号112可包含声音“catatonic”、“ca”和“t”,且可指示每一声音的文字表示。所述电子阅读应用程序可基于电子邮件的部分(例如,“cat”)与所述子集的文字表示(例如,“ca”和“t”)的比较而确定代替语音信号112的子集匹配于电子邮件的部分。所述电子阅读应用程序可输出代替语音信号112的子集。因此,所述电子阅读应用程序可以类似于第二用户154发声的话音来阅读电子邮件。
在特定方面,系统200可包含锁定机制以停用对代替语音信号112的未授权的存取。装置(例如,第一装置102、移动装置104或桌上型计算机106)在(例如,从服务器)接收授权之前不能产生(或使用)代替语音信号112。所述授权可基于第一用户152、第二用户154或这两者是否已经支付特定服务。所述授权可为按使用(例如,按话音呼叫、按应用程序激活)、按时间周期(例如,帐期、周、月等)或其组合而有效。在特定方面,所述授权可在代替语音信号112的每次更新时有效。在特定方面,所述授权可为按应用程序有效的。举例来说,移动装置104可接收在话音呼叫期间使用代替语音信号112的第一授权且接收以电子阅读应用程序使用代替语音信号112的另一授权。在特定方面,所述授权可基于装置是否经许可以产生(或使用)代替语音信号112。举例来说,移动装置104可响应于第二用户154获取许可以在移动装置104上使用电子阅读应用程序而接收在电子阅读应用程序中使用代替语音信号112的授权。
在特定方面,语音信号管理器262可维持经授权存取代替语音信号112的装置、用户或这两者的列表。语音信号管理器262可响应于确定装置未经授权存取代替语音信号112而将锁定请求发送到装置(例如,第一装置102、移动装置104、桌上型计算机106或其组合)。所述装置可响应于所述锁定请求而删除(或停用存取)本地存储的代替语音信号112。举例来说,语音信号管理器262可将锁定请求发送到先前经授权存取代替语音信号112的装置(例如,第一装置102、移动装置104或桌上型计算机106)。
在特定方面,信号处理模块122可在代替语音信号112的每一存取之前确定对应装置(例如,第一装置102)的授权状态。举例来说,信号处理模块122可将授权状态请求发送到服务器206且可从服务器206接收授权状态。信号处理模块122可响应于确定第一装置102未经授权而制止存取代替语音信号112。在特定方面,信号处理模块122可删除(或停用存取)代替语音信号112。举例来说,信号处理模块122可删除代替语音信号112或停用特定应用程序对代替语音信号112的存取。
在特定方面,信号处理模块122可响应于经由信号处理模块122的用户接口接收的第一用户输入而删除代替语音信号112。在特定方面,信号处理模块122可响应于经由信号处理模块122的用户接口接收的第二用户输入而将删除请求发送到服务器206。响应于删除请求,语音信号管理器262可删除(或停用存取)代替语音信号112。在特定方面,语音信号管理器262可响应于确定从与对应于代替语音信号112的用户(例如,第二用户154)相关联的装置(例如,移动装置104或桌上型计算机106)接收到删除请求而删除(或停用存取)代替语音信号112。
在特定方面,移动装置104可包含语音信号管理器262。移动装置104可接收训练语音信号272且移动装置104上的语音信号管理器262可产生代替语音信号112。语音信号管理器262可在移动装置104上存储代替语音信号112。在此方面,移动装置104可将代替语音信号112发送到服务器206。
在特定方面,服务器206可将与第二用户154相关联的代替语音信号112发送到与不同于第二用户154的用户(例如,第一用户152)相关联的一或多个装置(例如,第一装置102)。举例来说,服务器206可基于指示在特定时间周期中满足阈值呼叫频率的呼叫频率的呼叫简档(例如,第一呼叫简档270、第二呼叫简档274)而将代替语音信号112发送到第一装置102。第一呼叫简档270可与第一用户152、第一装置102或这两者相关联。第二呼叫简档274可与第二用户154、移动装置104或这两者相关联。呼叫频率可指示第一用户152、第一装置102或这两者与第二用户154、移动装置104或这两者之间的呼叫频率。为了说明,服务器206可基于第一呼叫简档270指示第一用户152与第二用户154之间的呼叫频率满足阈值呼叫频率(例如,前一周中的3次)将代替语音信号112发送到第一装置102。在特定方面,服务器206可在话音呼叫之前将代替语音信号112发送到第一装置102。举例来说,服务器206可基于呼叫简档(例如,第一呼叫简档270或第二呼叫简档274)在话音呼叫之前将代替语音信号112发送到第一装置102。
作为另一实例,服务器206可基于指示特定用户(例如,第一用户152、第二用户154)、特定装置(例如,第一装置102、移动装置104)或其组合的联系人列表(例如,第一联系人列表276、第二联系人列表278)将代替语音信号112发送到第一装置102。举例来说,服务器206可基于指示特定用户的第二联系人列表278将与第二用户154相关联的代替语音信号112发送到与特定用户(例如,第一用户152)相关联的一或多个装置(例如,第一装置102)。在特定方面,服务器206可在话音呼叫之前将代替语音信号112发送到第一装置102。举例来说,服务器206可基于联系人列表(例如,第一联系人列表276、第二联系人列表278)在话音呼叫之前将代替语音信号112发送到第一装置102。服务器206可响应于接收到训练语音信号272将代替语音信号112发送到第一装置102。
在特定方面,服务器206可响应于从第一装置102接收到对代替语音信号112的请求、响应于从移动装置104接收到将代替语音信号112发送到第一装置102的请求或这两者而发送代替语音信号112。举例来说,第一装置102可响应于经由第一装置102的信号处理模块122的用户接口接收的用户输入而发送对代替语音信号112的请求。作为另一实例,移动装置104可响应于经由移动装置104的信号处理模块122的用户接口接收的用户输入而发送发送代替语音信号112的请求。在特定方面,服务器206可响应于接收到与第一联系人列表276、第二联系人列表278或这两者相关的联系人列表更新通知而将代替语音信号112发送到第一装置102。服务器可从第一装置102接收与第一联系人列表276相关的联系人列表更新通知,且服务器206可从移动装置104接收与第二联系人列表278相关的联系人列表更新通知。举例来说,服务器206可从对应装置的信号处理模块122接收联系人列表更新通知。
在特定方面,服务器206可响应于接收到与第一呼叫简档270、第二呼叫简档274或这两者相关的呼叫简档更新通知而将代替语音信号112发送到第一装置102。服务器206可从第一装置102接收与第一呼叫简档270相关的呼叫简档更新通知,且服务器206可从移动装置104接收与第二呼叫简档274相关的呼叫简档更新通知。举例来说,服务器206可从对应装置的信号处理模块122接收呼叫简档更新通知。
作为另一个实例,服务器206可响应于关于与第二用户154相关联的装置(例如,移动装置104、桌上型计算机106)与第一装置102之间的话音呼叫的呼叫起始通知而将与第二用户154相关联的代替语音信号112发送到第一装置102。举例来说,服务器206可当从移动装置104发出话音呼叫时从移动装置104接收呼叫起始通知。在特定方面,移动装置104的信号处理模块122可将呼叫起始通知发送到服务器206。服务器206可在话音呼叫的开始、在话音呼叫期间或这两者时发送代替语音信号112的至少一个子集。举例来说,服务器206可响应于接收到呼叫起始通知而开始发送代替语音信号112。代替语音信号112的第一子集可由服务器206在话音呼叫的开始发送。代替语音信号112的第二子集可由服务器206在话音呼叫期间发送。
在特定方面,语音信号管理器262可包含使系统管理员能够执行诊断的用户接口。举例来说,用户接口可显示包含与代替语音信号112相关联的上载和下载频率的使用简档。所述使用简档还可包含每装置(例如,第一装置102、移动装置104和/或桌上型计算机106)的上载和下载频率。
因此,系统200可通过图1的系统100实现可用以替换语音信号的代替语音信号的获取。
参考图3,揭示用户接口的说明性方面且一般指定为300。在特定方面,用户接口300可由图1的系统100、图2的系统200或这两者显示。
在操作期间,装置(例如,第一装置102)的信号处理模块122可具有对用户(例如,第一用户152)的联系人列表的存取。信号处理模块122可提供到第一装置102的显示器的用户接口300。举例来说,信号处理模块122可响应于接收到来自第一用户152的请求而提供到第一装置102的显示器的用户接口300。
用户接口300的水平轴线(例如,x轴)可显示来自联系人列表的一或多个用户的识别符(例如,姓名)(例如,“拜奇·柯蒂斯”、“布雷特·迪恩”、“亨利·洛佩斯”、“萨布瑞纳·桑德斯”和“蓝道尔·休斯”)。在特定方面,第一用户152可从联系人列表选择所述一或多个用户且用户接口300可包含沿着水平轴线的选定用户的姓名。在另一方面,信号处理模块122可从联系人列表自动选择用户子集。举例来说,所述用户子集可为如下情况的特定数目(例如,5个)用户:第一用户152与其最频繁地通信,第一用户152与其最近通信,第一用户152与其在特定时间间隔中通信最长持续时间(例如,电话呼叫持续时间的总和),或其组合。
用户接口300可沿着垂直轴线(例如,y轴)指示持续时间。所述持续时间可与对应于所述一或多个用户的语音信号相关联。举例来说,用户接口300可包含对应于第二用户154(例如,“蓝道尔·休斯”的第一条302。第一条302可指示与第二用户154相关联的一或多个语音信号的回放持续时间。举例来说,第一条302可指示训练语音信号272的回放持续时间。在特定方面,第一条302可指示在特定时间间隔(例如,特定日、特定周或特定月)中俘获的与第二用户154相关联的语音信号的回放持续时间。
在特定方面,用户接口300可指示在相异时间间隔中俘获的特定用户的语音信号的持续时间。举例来说,第一条302可指示在第一时间间隔(例如,前一周)中俘获的第二用户154的语音信号的第一持续时间,且与另一用户(例如,“萨布瑞纳·桑德斯”)相关联的第二条314可指示在第二时间间隔(例如,前一月)中俘获的另一用户的语音信号的第二持续时间。举例来说,第一用户152可能在一周以前已下载与第二用户154相关联的代替语音信号,且第一条302可指示在所述下载之后俘获的第二用户154的语音信号的第一持续时间。作为另一实例,第一用户152可能在一个月以前已下载与另一用户A相关联的代替语音信号,且第二条314可指示在所述下载之后俘获的与另一用户(例如,“萨布瑞纳·桑德斯”)的语音信号相关联的第二持续时间。
第一用户152可使用光标306选择第二用户154的姓名(例如,“蓝道尔·休斯”)或第一条302。用户接口300可响应于接收到所述选择而显示添加选项308、删除选项310或这两者。第一用户152可选择删除选项310。举例来说,第一用户152可确定将不产生与第二用户154相关联的额外代替语音信号。为了说明,第一用户152可确定存在与第二用户154相关联的代替语音信号的足够集合,第一用户152可能不期望在近期与第二用户154通信,第一用户152可能想要节省资源(例如,存储器或处理循环),或其组合。响应于接收到删除选项310的选择,信号处理模块122可移除与第二用户154相关联的一或多个语音信号,可从用户接口300移除与第二用户154的语音信号相关联的第一持续时间的指示,或这两者。
在特定方面,与第二用户154相关联的语音信号可存储在第一装置102可存取的存储器中,且信号处理模块122可响应于接收到删除选项310的选择而移除与第二用户154相关联的一或多个语音信号。在特定方面,与第二用户154相关联的所述一或多个语音信号可存储在服务器(例如,图2的服务器206)可存取的存储器中。信号处理模块122可响应于接收到删除选项310的选择而将删除请求发送到服务器206。响应于接收到删除请求,服务器206可移除与第二用户154相关联的语音信号,可使第一装置102不可存取与第二用户154相关联的语音信号,可使第一用户152不可存取与第二用户154相关联的语音信号,或其组合。举例来说,第一用户152可选择删除选项310以使第一装置102不可存取与第二用户154相关联的语音信号。在此实例中,第一用户152可能想要与第二用户154相关联的所述一或多个语音信号保持对其它装置可存取。
替代地,第一用户152可选择添加选项308。响应于接收到添加选项308的选择,信号处理模块122可请求图2的语音信号管理器262提供从与第二用户154相关联的语音信号产生的代替语音信号(例如,代替语音信号112)。语音信号管理器262可使用与第二用户154相关联的语音信号产生代替语音信号112,如参考图2所描述。语音信号管理器262可响应于从信号处理模块122接收到请求而将代替语音信号112提供到信号处理模块122。
在特定方面,信号处理模块122可在接收到删除选项310的选择之后、在接收到添加选项308的选择之后或在从语音信号管理器262接收到代替语音信号112之后复位第一条302(例如,到零)。第一条302可指示与在与第二用户154相关联的语音信号的先前删除之后或在与第二用户154相关联的其它代替语音信号的先前下载(或产生)之后俘获的第二用户154的语音信号相关联的第一持续时间。
在特定方面,信号处理模块122可响应于确定对应于特定用户(例如,“布雷特·迪恩”)的语音信号的持续时间(例如,由第三条316指示)满足自动更新阈值312(例如,1小时)而将对代替语音信号的请求自动发送到语音信号管理器262。
在特定方面,信号处理模块122可周期性地(例如,一周一次)请求对应于与第二用户154相关联的语音信号的代替语音信号112。在另一方面,语音信号管理器262可将代替语音信号112周期性地发送到第一装置102。在特定方面,用户接口300可除周期性更新之外还使得第一用户152能够下载代替语音信号112。
在特定方面,与第二用户154相关联的语音信号可由与第二用户154相关联的装置(例如,移动装置104)处的信号处理模块122、由与第一用户152相关联的装置(例如,第一装置102)、由服务器(例如,图2的服务器206)或其组合俘获。举例来说,第一装置102(或移动装置104)处的信号处理模块122可记录在第二用户154与第一用户152之间的电话呼叫期间的语音信号。作为另一实例,所述语音信号可对应于存储在服务器206处的来自第二用户154的音频消息。在特定方面,移动装置104、第一装置102或这两者可将与第二用户154相关联的语音信号提供到服务器206。在特定方面,用户接口300可使用文字表示、图形表示(例如,条形图、饼图或这两者)或这两者来指示持续时间。
用户接口300可因此使得第一用户152能够监视与用户相关联的语音信号的可用性以用于代替语音信号产生。用户接口300可使得第一用户152能够在产生代替语音信号与保存资源(例如,存储器、处理循环或这两者)之间进行选择。
参考图4,揭示可操作以执行语音信号的“预编码”替换的系统的说明性方面且一般指定为400。系统400可包含经由网络120与第一装置102通信的移动装置104。移动装置104可包含耦合到编码器426或与其通信的信号处理模块422。移动装置104可包含数据库分析器410。移动装置104可包含第一数据库124、参数化数据库424或这两者。
图4说明在将所替换语音信号提供到编码器(例如,编码器426)之前的语音信号的替换。在操作期间,移动装置104可经由麦克风146从第二用户154接收第一用户语音信号130。第一数据库124(例如,“原始”数据库)可包含代替语音信号112。代替语音信号112可包含第一代替语音信号172、第二代替语音信号174和N个代替语音信号478。可如参考图2所描述产生代替语音信号112中的每一者。
参数化数据库424可包含与代替语音信号112相关联的语音参数的集合。举例来说,参数化数据库424可包含第一代替语音信号172的第一语音参数472、第二代替语音信号174的第二语音参数474,以及N个代替语音信号478的N个语音参数476。语音参数472、474和476可比代替语音信号112占据更少的存储空间,因此参数化数据库424可小于第一数据库124。
在特定方面,参数化数据库424可包含与语音参数472、474和476中的每一者相关联的到第一数据库124中的对应代替语音信号的位置的特定参考(例如,索引、数据库地址、数据库指针、存储器地址、统一资源定位符(URL)、统一资源识别符(URI)或其组合)。举例来说,参数化数据库424可包含到第一数据库124中的第一代替语音信号172的第一位置的与第一语音参数472相关联的第一参考。信号处理模块422可使用特定参考来存取与特定语音参数相关联的对应代替语音信号。举例来说,信号处理模块422可使用第一参考来存取与第一语音参数472相关联的第一代替语音信号172。
在特定方面,第一数据库124可包含到参数化数据库424中的对应语音参数的位置的与代替语音信号112中的每一者相关联的特定参考(例如,索引、数据库地址、数据库指针、存储器地址、统一资源定位符(URL)、统一资源识别符(URI)或其组合)。举例来说,第一数据库124可包含到参数化数据库424中的第一语音参数472的第一位置的与第一代替语音信号172相关联的第一参考。信号处理模块422可使用特定参考来存取与特定代替语音信号相关联的对应语音参数。举例来说,信号处理模块422可使用第一参考来存取第一代替语音信号172的第一语音参数472。
在特定方面,数据库分析器410可响应于移动装置104接收到第一用户语音信号130而确定参数化数据库424是否是最新的。举例来说,数据库分析器410可确定参数化数据库424是否包含与代替语音信号112相关联的语音参数(例如,语音参数472、474和476)。为了说明,数据库分析器410可确定参数化数据库424是否包含对应于代替语音信号112的一或多个代替语音信号的语音参数。响应于确定参数化数据库424包含与代替语音信号112相关联的语音参数,数据库分析器410可确定在参数化数据库424的先前更新之后是否对第一数据库124做出了任何修改。为了说明,数据库分析器410可确定第一数据库124的修改时戳是否在参数化数据库424的更新时戳之后。响应于确定在参数化数据库424的先前更新之后未对第一数据库124做出修改,数据库分析器410可确定参数化数据库424是最新的。
响应于确定参数化数据库424不包含与代替语音信号112相关联的语音参数,或在参数化数据库424的先前更新之后对第一数据库124做出了修改,数据库分析器410可产生对应于代替语音信号112的语音参数。举例来说,数据库分析器410可从第一代替语音信号172产生第一语音参数472,从第二代替语音信号174产生第二语音参数474,且从N个代替语音信号478产生N个语音参数476。第一语音参数472、第二语音参数474和N个语音参数476可分别包含第一代替语音信号172、第二代替语音信号174和N个代替语音信号478的音调参数、能量参数、线性预测译码(LPC)参数或其任何组合。
信号处理模块422可包含分析器402、搜索器404、约束分析器406和合成器408。分析器402可基于第一用户语音信号130产生搜索准则418。搜索准则418可包含与第一用户语音信号130相关联的多个语音参数。举例来说,所述多个语音参数可包含第一用户语音信号130的音调参数、能量参数、线性预测译码(LPC)参数或其任何组合。分析器402可将搜索准则418提供到搜索器404。
搜索器404可通过基于搜索准则418搜索参数化数据库424而产生搜索结果414。举例来说,搜索器404可将所述多个语音参数与语音参数472、474和476中的每一者进行比较。搜索器404可确定第一语音参数472和第二语音参数474匹配于所述多个语音参数。举例来说,搜索器404可基于所述比较而选择(或识别)第一语音参数472和第二语音参数474。为了说明,第一用户语音信号130可对应于“bat”。第一代替语音信号172可对应于从“cat”产生的“a”,如参考图2所描述。第二代替语音信号174可对应于从“tag”产生的“a”,如参考图2所描述。
在特定方面,搜索器404可基于与语音参数472、474和476中的每一者相关联的相似性量度而产生搜索结果414。特定相似性量度可指示相关对应语音参数同与第一用户语音信号130相关联的所述多个语音参数的接近程度。举例来说,搜索器404可通过计算第一用户语音信号130的所述多个语音参数与第一语音参数472之间的差而确定第一语音参数472的第一相似性量度。
搜索器404可选择具有满足相似性阈值的相似性量度的语音参数。举例来说,搜索器404可响应于确定第二语音参数474的第一相似性量度和第二相似性量度满足(例如,低于)相似性阈值而选择第一语音参数472和第二语音参数474。
作为另一实例,搜索器404可基于相似性量度而选择最类似于第一用户语音信号130的所述多个语音参数的特定数目(例如,2)个语音参数。搜索器404可在搜索结果414中包含选定语音参数(例如,第一语音参数472和第二语音参数474)。在特定方面,搜索器404可在搜索结果414中包含对应于选定多个语音参数的代替语音信号。举例来说,搜索器404可在搜索结果414中包含第一代替语音信号172和第二代替语音信号174。搜索器404可将搜索结果414提供到约束分析器406。
约束分析器406可基于约束从搜索结果414选择特定搜索结果(例如,选定结果416)。所述约束可包含误差约束、成本约束或这两者。举例来说,约束分析器406可基于误差约束或成本约束从搜索结果414选择第一语音参数472(或第一代替语音信号172)。为了说明,约束分析器406可基于搜索结果414中的每一者产生经处理语音信号。经处理语音信号中的每一者可表示具有被对应搜索结果替换的部分的第一用户语音信号130。约束分析器406可识别具有经处理语音信号的最低误差的特定经处理语音信号。举例来说,约束分析器406可基于经处理语音信号与第一用户语音信号130的比较而确定与经处理语音信号中的每一者相关联的误差量度。在特定方面,约束分析器406可识别具有最低成本的特定经处理语音信号。举例来说,约束分析器406可基于检索与对应搜索结果相关联的代替语音信号、一或多个先前代替语音信号、一或多个后续代替语音信号或其组合的成本而确定与经处理语音信号中的每一者相关联的成本量度。为了说明,可基于对应于所述多个代替信号的存储器位置之间的差而确定检索多个代替信号的成本。举例来说,较低成本可与检索在存储器中更接近于先前检索的代替语音信号定位的后续代替语音信号相关联。约束分析器406可选择对应于特定经处理语音信号的搜索结果作为选定结果416。
合成器408可基于选定结果416产生第一经处理语音信号116。举例来说,如果选定结果416与第一代替语音信号172相关联,那么合成器408可通过以第一代替语音信号172替换第一用户语音信号130的至少一部分而产生第一经处理语音信号116。在特定方面,合成器408可基于第一语音参数472而产生(例如,合成)替换语音信号,且可通过以替换语音信号替换第一用户语音信号130的至少一部分而产生第一经处理语音信号116。
合成器408可将第一经处理语音信号116提供到编码器426。编码器426可通过对第一经处理语音信号116进行编码而产生输出信号430。在特定方面,输出信号430可指示第一代替语音信号172。举例来说,输出信号430可包含对第一数据库124中的第一代替语音信号172的参考、对参数化数据库424中的第一语音参数472的参考,或这两者。移动装置104可经由网络120将输出信号430发送到第一装置102。
系统400可因此实现在对用户语音信号进行编码之前以代替语音信号对用户语音信号的一部分的“预编码”替换。代替语音信号可具有比用户语音信号的所替换部分更高的音频质量。举例来说,第二用户154可在有噪声的环境(例如,在音乐会或繁忙的街道)在移动装置104上说话。代替语音信号可从第二用户154在安静环境中提供的训练信号而产生,如参考图2所描述。信号处理模块422可将比原始用户语音信号更高质量的音频提供到编码器。编码器可对所述较高质量音频进行编码且可将经编码的信号发射到另一装置。
参看图5,揭示可操作以执行语音信号的“编码中”替换的系统的说明性方面且一般指定为500。系统500可包含编码器526、数据库分析器410、第一数据库124、参数化数据库424或其组合。
图5说明在编码器(例如,编码器526)处的语音信号的替换。鉴于图4的方面说明耦合到编码器426的信号处理模块422,编码器526包含信号处理模块422的一或多个组件。在操作期间,移动装置104可接收第一用户语音信号130。在编码器526内,分析器402可产生搜索准则418,搜索器404可产生搜索结果414,约束分析器406可产生选定结果416,且合成器408可产生第一经处理语音信号116,如参考图4所描述。编码器526可通过对第一经处理语音信号116进行编码而产生输出信号430。移动装置104可经由网络120将输出信号430发送到第一装置102。
在特定方面,约束分析器406可产生对应于选定结果416的第一经处理信号,如参考图4所描述。编码器526可通过对第一经处理信号进行编码而产生输出信号430。在此方面中,信号处理模块422可制止产生第一经处理语音信号116。在特定方面,输出信号430可指示第一代替语音信号172,如参考图4所描述。
系统500可因此通过执行以代替语音信号对与用户相关联的用户语音信号的一部分的“编码中”替换而实现在编码器处的经处理语音信号的产生。经处理语音信号可具有比用户语音信号更高的音频质量。举例来说,第二用户154可在有噪声的环境(例如,在音乐会或繁忙的街道)在移动装置104上说话。代替语音信号可从第二用户154在安静环境中提供的训练信号而产生,如参考图2所描述。编码器可对比原始用户语音信号更高质量的音频进行编码且可将经编码的信号发射到另一装置。在特定方面,用户语音信号的所述部分的编码中替换可减少与从用户语音信号产生经编码语音信号相关联的步骤,从而得到与用户语音信号的所述部分的预编码替换相比更快且更高效的信号处理。
鉴于图4到5的方面说明编码器系统中的语音信号的替换,图6和7的方面说明解码器系统中的语音信号的替换。在特定方面,语音信号替换可在编码器系统的本地解码器处发生。举例来说,第一经处理语音信号可由所述本地解码器产生以基于所述第一经处理语音信号与用户语音信号(例如,第一用户语音信号130)的比较而确定信号参数。为了说明,所述本地解码器可模仿在另一装置处的解码器的行为。编码器系统可对信号参数进行编码以发射到另一装置。
参考图6,揭示可操作以在解码器处执行语音信号的“参数”替换的系统的说明性方面且一般指定为600。系统600包含第一装置102。第一装置102可包含第一数据库124、参数化数据库424、数据库分析器410、解码器626或其组合。解码器626可包含、耦合到信号处理模块622或与其通信。
图6说明在接收装置处的语音信号的替换。在操作期间,第一装置102可经由网络120从移动装置104接收第一数据630。第一数据630可包含对应于音频信号的一或多个帧的包数据。所述音频信号可为对应于用户(例如,图1的第二用户154)的用户语音信号。第一数据630可包含与所述音频信号相关联的多个参数。所述多个参数可包含音调参数、能量参数、线性预测译码(LPC)参数或其任何组合。
分析器602可基于第一数据630产生搜索准则612。举例来说,分析器602可从第一数据630提取与所述音频信号相关联的多个语音参数。搜索准则612可包含提取的多个语音参数。分析器602可将搜索准则612提供到搜索器604。
搜索器604可识别图4的语音参数472、474和476的一或多个语音参数。在特定方面,搜索器604可通过将多个语音参数与语音参数472、474和476中的每一者进行比较而识别第一语音参数472和第二语音参数474,如参考图4的搜索器404所描述。搜索器604可在语音参数集合614中包含经识别语音参数(例如,第一语音参数472和第二语音参数474)。搜索器604可将语音参数集合614提供到约束分析器606。约束分析器606可基于约束而选择语音参数集合614的第一语音参数472,如参考图4的约束分析器406所描述。约束分析器606可将第一语音参数472提供到合成器608。
合成器608可通过以第一语音参数472替换第一数据630中的所述多个语音参数而产生第二数据618。解码器626可通过解码第二数据618而产生第一经处理语音信号116。举例来说,第一经处理语音信号116可为基于第一语音参数472而产生的经处理信号。第一装置102可将第一经处理语音信号116提供到扬声器142。
在特定方面,分析器602可确定第一数据630指示第一代替语音信号172。举例来说,分析器602可确定第一数据630包含对第一数据库124中的第一代替语音信号172的参考、对参数化数据库424中的第一语音参数472的参考,或这两者。分析器602可响应于确定第一数据630指示第一代替语音信号172而将第一语音参数472提供到合成器608。在此方面,分析器602可制止产生搜索准则612。
系统600可因此通过以对应于代替语音信号的语音参数对所接收数据的第一多个语音参数的“参数”替换而实现产生经处理语音信号。使用对应于代替语音信号的语音参数产生经处理信号可导致与使用所述第一多个语音参数产生经处理信号相比更高音频的质量。举例来说,所接收的数据可能不表示高质量音频信号。为了说明,所接收的数据可对应于在有噪声的环境(例如,在音乐会)中从用户接收的用户语音信号,且可由另一装置产生而无需执行语音替换。即使另一装置执行语音替换,例如由于丢包、带宽限制和/或位速率限制,由另一装置发送的一些数据可能不会被接收。语音参数可对应于从第二用户154在安静环境中提供的训练信号产生的代替语音信号,如参考图2所描述。解码器可使用语音参数产生比使用所述第一多个语音参数可产生的信号更高质量的经处理信号。
参看图7,揭示可操作以在解码器处执行语音信号的“波形”替换的系统的说明性方面且一般指定为700。系统700可包含第一数据库124、参数化数据库424、数据库分析器410、解码器726或其组合。解码器726可包含、耦合到信号处理模块722或与其通信。
图7说明在接收装置处的语音信号的替换。鉴于图6的方面说明通过以对应于代替语音信号的语音参数替换所接收语音参数而产生经处理语音信号,图7的方面说明基于所接收的语音参数识别代替语音信号且使用代替语音信号产生经处理语音信号。
在操作期间,第一装置102可接收第一数据630。分析器602可基于第一数据630产生搜索准则612,如参考图6所描述。搜索器604可基于搜索准则612识别代替语音信号112的子集(例如,多个代替语音信号714),如参考图4的搜索器404所描述。举例来说,所述多个代替语音信号714可包含第一代替语音信号172和第二代替语音信号174。约束分析器706可基于约束选择所述多个代替语音信号714的第一代替语音信号(例如,第一代替语音信号172),如参考图4的约束分析器406所描述。在特定方面,约束分析器706可基于约束选择第一语音参数472,如参考图4的约束分析器406所描述,且可选择对应于选定第一语音参数472的第一代替语音信号172。
约束分析器706可将第一代替语音信号172提供到合成器708。合成器708可基于第一代替语音信号172产生第一经处理语音信号116。举例来说,合成器708可通过以第一代替语音信号172替换输入信号的一部分而产生第一经处理语音信号116。第一装置102可经由扬声器142输出第一经处理语音信号116。
系统700可因此通过接收对应于用户语音信号的数据且通过以代替语音信号替换用户语音信号的一部分产生经处理信号而实现“波形”替换。经处理信号可具有比用户语音信号更高的音频质量。举例来说,所接收的数据可能不表示高质量音频信号。为了说明,所接收的数据可对应于在有噪声的环境(例如,在音乐会)中从用户接收的用户语音信号,且可由另一装置产生而无需执行语音替换。即使另一装置执行语音替换,例如由于丢包、带宽限制和/或位速率限制,由另一装置发送的一些数据可能不会被接收。代替语音信号可从第二用户154在安静环境中提供的训练信号而产生,如参考图2所描述。解码器可使用代替语音信号产生比使用所接收的数据可产生的信号更高质量的经处理信号。
参考图8,揭示可操作以执行语音信号的“装置中”替换的系统的说明性方面且一般指定为800。系统800可包含第一数据库124、数据库分析器410、信号处理模块422、参数化数据库424、应用程序822或其组合。
在操作期间,信号处理模块422可从应用程序822接收输入信号830。输入信号830可对应于语音信号。应用程序822可包含文档查看应用程序、电子书查看应用程序、文字到语音应用程序、电子邮件应用程序、通信应用程序、因特网应用程序、录音应用程序或其组合。分析器402可基于输入信号830产生搜索准则418,搜索器404可基于搜索准则418产生搜索结果414,约束分析器406可识别选定结果416,且合成器408可通过基于选定结果416以替换语音信号替换输入信号830的一部分而产生第一经处理语音信号116,如参考图4所描述。第一装置102可经由扬声器142输出第一经处理语音信号116。在特定方面,信号处理模块422可响应于从第一用户152接收到用户请求而产生搜索准则418以产生第一经处理语音信号116。
在特定方面,第一数据库124可包含多个代替语音信号集合。代替语音信号的每一集合可对应于特定名人、特定角色(例如,卡通角色、电视角色或电影角色)、特定用户(例如,第一用户152或第二用户154),或其组合。第一用户152可选择代替语音信号的特定集合(例如,代替语音信号112)。举例来说,第一用户152可选择对应名人、对应角色、对应用户或其组合。信号处理模块422可使用代替语音信号的选定集合(例如,代替语音信号112)以产生第一经处理语音信号116,如本文中所描述。
在特定方面,第一装置102可将请求发送到另一装置(例如,图2的服务器206或移动装置104)。所述请求可识别特定名人、特定角色、特定用户或其组合。另一装置可响应于接收到所述请求而将代替语音信号112发送到第一装置102。
系统800可因此通过以代替语音信号替换由应用程序产生的输入语音信号的一部分而实现“装置中”替换。代替语音信号可具有比输入语音信号更高的音频质量。在特定方面,代替语音信号可从第一用户152的训练语音产生。举例来说,由应用程序产生的输入语音信号可发出机器人声音或可对应于默认话音。第一用户152可能偏好另一话音(例如,第一用户152、图1的第二用户154、特定名人、特定角色等的话音)。代替语音信号可对应于优选话音。
虽然图4到8的方面说明本地数据库分析器410,但在特定方面,数据库分析器410或其组件可包含在服务器(例如,图2的服务器206)中。在此方面,移动装置104、第一装置102或这两者可从服务器206接收参数化数据库424的至少一部分。举例来说,服务器206可分析代替语音信号112以产生第一语音参数472、第二语音参数474、N个语音参数476或其组合。
服务器206可将参数化数据库424的至少所述部分提供到移动装置104、第一装置102或这两者。举例来说,移动装置104、第一装置102或这两者可周期性地或响应于接收到图1的第一用户语音信号130、图6的第一数据630、输入信号830、用户请求或其组合而从服务器206请求参数化数据库424的至少所述部分。在替代方面中,服务器206可周期性地将参数化数据库424的至少所述部分发送到移动装置104、第一装置102或这两者。
在特定方面,服务器(例如,图2的服务器206)可包含信号处理模块422。服务器206可从移动装置104接收第一用户语音信号130。服务器206可产生输出信号430,如参考图3和4所描述。服务器206可将输出信号430发送到第一装置102。在特定方面,输出信号430可对应于图6的第一数据630。
参考图9,展示可操作以替换语音信号的系统的特定方面的图且一般指定为900。在特定方面,系统900可对应于第一装置102或可包含在其中。
系统900包含耦合到合成器408的搜索模块922。搜索模块922可包含或具有对耦合到搜索器904的数据库924的存取。在特定方面,数据库924可包含图1的第一数据库124、图4的参数化数据库424或这两者。举例来说,数据库924可存储代替语音信号112和/或对应于代替语音信号112的语音参数的集合(例如,语音参数472、474和/或476)。在特定方面,数据库924可接收且存储代替语音信号112和语音参数集合。举例来说,数据库924可从另一装置(例如,图2的服务器206)接收代替语音信号112和语音参数集合。作为另一实例,数据库924可从服务器206接收代替语音信号112,且搜索器904可使用向量量化器、隐式马尔可夫模型(HMM)或高斯混合模型(GMM)中的至少一者产生语音参数集合。搜索器904可在数据库924中存储所产生语音参数集合。
在特定方面,搜索器904可包含图4的分析器402和搜索器404。合成器408可包含替换器902。替换器902可耦合到搜索器904和数据库924。
在操作期间,搜索器904可接收输入信号930。输入信号930可对应于语音。在特定方面,输入信号930可包含图1和4到5的第一用户语音信号130、图6到7的第一数据630或图8的输入信号830。举例来说,搜索器904可从用户(例如,图1的第一用户152)、另一装置、应用程序或其组合接收输入信号930。应用程序可包含文档查看应用程序、电子书查看应用程序、文字到语音应用程序、电子邮件应用程序、通信应用程序、因特网应用程序、录音应用程序或其组合。
搜索器904可将输入信号930与代替语音信号112进行比较。在特定方面,搜索器904可将输入信号930的第一多个语音参数与语音参数集合进行比较。搜索器904可使用向量量化器、隐式马尔可夫模型(HMM)或高斯混合模型(GMM)中的至少一者确定所述第一多个语音参数。
搜索器904可基于所述比较而确定特定代替语音信号(例如,第一代替语音信号172)匹配于输入信号930。举例来说,搜索器904可基于所述第一多个语音参数与对应于代替语音信号112、约束或这两者的语音参数集合的比较而选择第一代替语音信号172、第一语音参数472或这两者,如参考图4所描述。
搜索器904可将选定结果416提供到替换器902。选定结果416可指示第一代替语音信号172、第一语音参数472或这两者。替换器902可基于选定结果416从数据库924检索第一代替语音信号172。替换器902可通过以第一代替语音信号172替换输入信号930的一部分而产生第一经处理语音信号116,如参考图4所描述。
在特定方面,数据库924可包含与代替语音信号112相关联的标签。举例来说,第一标签可指示对应于第一代替语音信号172的声音(例如,音素、双音素、三音素、音节、词或其组合)。第一标签可包含与所述声音相关联的文字识别符。在特定方面,替换器902可基于选定结果416从数据库924检索第一标签。举例来说,选定结果416可指示第一代替语音信号172且替换器902可从数据库924检索对应第一标签。合成器408可产生包含第一标签的文字输出。
现有语音辨识系统使用语言模型且在例如词或声音等较高阶构造上操作。相比之下,搜索模块922不使用语言模型且可在参数层级或在信号层级操作以执行输入信号930与代替语音信号112的比较以确定选定结果416。
系统900可实现以第一代替语音信号172替换输入信号930的所述部分以产生第一经处理语音信号116。第一经处理语音信号116可具有比输入信号930更高的音频质量。
参看图10,展示数据库的特定方面的图且一般指定为1024。在特定方面,数据库1024可对应于图1的第一数据库124、图4的参数化数据库424、图9的数据库924或其组合。
数据库1024可包含梅尔频率倒谱系数(MFCC)1002、线谱对(LSP)1004、线谱频率(LSF)1006、倒谱1010、线谱信息(LSI)1012、离散余弦变换(DCT)参数1014、离散傅立叶变换(DFT)参数1016、快速傅立叶变换(FFT)参数1018、共振峰频率1020、脉码调制(PCM)样本1022或其组合。
在特定方面,装置(例如,图2的服务器206)的模/数转换器(ADC)可基于训练语音信号(例如,训练语音信号272)产生PCM样本1022。语音信号管理器262可从ADC接收PCM样本1022且可在数据库1024中存储PCM样本1022。语音信号管理器262可基于PCM样本1022产生代替语音信号112,如参考图2所描述。
语音信号管理器262可计算PCM样本1022中的每一者的频谱的表示。举例来说,语音信号管理器262可产生对应于PCM样本1022中的每一者(或代替语音信号112中的每一者)的MFCC 1002、LSP 1004、LSF 1006、倒谱1010、LSI 1012、DCT参数1014、DFT参数1016、FFT参数1018、共振峰频率1020或其组合。
举例来说,MFCC 1002可为对应于特定PCM样本的声音的短期功率谱的表示。语音信号管理器262可基于非线性梅尔频率尺度上的对数功率谱的线性余弦变换而确定MFCC 1002。对数功率谱可对应于特定PCM样本。
作为另一实例,LSP 1004或LSF 1006可为对应于特定PCM样本的线性预测系数(LPC)的表示。LPC可表示特定PCM样本的频谱包络。语音信号管理器262可基于线性预测模型确定特定PCM样本的LPC。语音信号管理器262可基于LPC确定LSP 1004、LSF 1006或这两者。
作为另一个实例,倒谱1010可表示特定PCM样本的功率谱。语音信号管理器262可通过对特定PCM样本的估计频谱的对数应用傅立叶逆变换(IFT)而确定倒谱1010。
作为额外实例,LSI 1012可表示特定PCM样本的频谱。语音信号管理器262可将滤波器应用于特定PCM样本以产生LSI 1012。
语音信号管理器262可将特定离散余弦变换(DCT)应用于特定PCM样本以产生DCT参数1014,可将特定离散傅立叶变换(DFT)应用于特定PCM样本以产生DFT参数1016,可将特定快速傅立叶变换(FFT)应用于特定PCM样本以产生FFT参数1018,或其组合。
共振峰频率1020可表示特定PCM样本的频谱的频谱峰值。语音信号管理器262可基于特定PCM样本的相位信息、通过将带通滤波器应用于特定PCM样本、通过执行特定PCM样本的LPC分析或其组合而确定共振峰频率1020。
在特定方面,MFCC 1002、LSP 1004、LSF 1006、倒谱1010、LSI 1012、DCT参数1014、DFT参数1016、FFT参数1018、共振峰频率1020或其组合可对应于第一语音参数472,且特定PCM样本可对应于第一代替语音信号172。
数据库1024说明代替语音信号的参数的实例,其可由信号处理模块在对匹配代替语音信号的搜索期间使用以将输入语音信号与多个代替语音信号进行比较。信号处理模块可通过以匹配代替语音信号替换输入语音信号的一部分而产生经处理信号。经处理信号可具有比输入语音信号更好的音频质量。
参考图11,揭示系统的特定方面且一般指定为1100。系统1100可执行参考图1到2和4到9的系统100到200和400到900描述的一或多个操作。
系统1100可包含经由网络120耦合到第一装置102或与其通信的服务器1106。服务器1106可包含电耦合到存储器1176的处理器1160。处理器1160可经由收发器1180电耦合到网络120。收发器(例如,收发器1180)可包含接收器、发射器或这两者。接收器可包含天线、网络接口或天线和网络接口的组合中的一或多者。发射器可包含天线、网络接口或天线和网络接口的组合中的一或多者。处理器1160可包含或可电耦合到语音信号管理器262。存储器1176可包含第二数据库264。第二数据库264可经配置以存储与特定用户(例如,图1的第二用户154)相关联的代替语音信号112。举例来说,语音信号管理器262可基于训练信号产生代替语音信号112,如参考图2所描述。代替语音信号112可包含第一代替语音信号172。
存储器1176可经配置以存储一或多个远程话音简档1178。远程话音简档1178可与多个人相关联。举例来说,远程话音简档1178可包含远程话音简档1174。远程话音简档1174可与一个人(例如,图1的第二用户154)相关联。为了说明,远程话音简档1174可包含与第二用户154相关联的识别符1168(例如,用户识别符)。远程话音简档1178中的另一远程话音简档可与另一人(例如,第一用户152)相关联。
远程话音简档1174可与代替语音信号112相关联。举例来说,远程话音简档1174可包含与代替语音信号112相关联的语音内容1170。为了说明,语音内容1170可对应于第二用户154的语音信号或语音模型。语音内容1170可基于从代替语音信号112中的一或多者提取的特征。远程话音简档1174可指示代替语音信号112对应于具有第一回放持续时间的音频数据。举例来说,如参考图2所描述用以产生代替语音信号112的训练信号可具有第一回放持续时间。
第一装置102可包含经由收发器1150电耦合到网络120的处理器1152。处理器1152可电耦合到存储器1132。存储器1132可包含第一数据库124。第一数据库124可经配置以存储本地代替语音信号1112。处理器1152可包含或可电耦合到信号处理模块122。存储器1132可经配置以存储一或多个本地话音简档1108。举例来说,本地话音简档1108可包含与特定用户(例如,图1的第二用户154)相关联的本地话音简档1104。第一装置102可电耦合到或可包含至少一个扬声器(例如,扬声器142)、显示器1128、输入装置1134(例如,触摸屏、键盘、鼠标或麦克风)或其组合。
在操作期间,信号处理模块122可从服务器1106接收远程话音简档1178的一或多个远程话音简档(例如,远程话音简档1174)。信号处理模块122可基于识别符1168、语音内容1170或这两者确定远程话音简档1174与一个人(例如,图1的第二用户154)相关联。举例来说,信号处理模块122可响应于确定识别符1168(例如,用户识别符)对应于第二用户154而确定远程话音简档1174与第二用户154相关联。作为另一实例,信号处理模块122可响应于确定语音内容1170对应于第二用户154而确定远程话音简档1174与第二用户154相关联。信号处理模块122可基于本地代替语音信号1112产生第二语音内容(例如,语音模型)。信号处理模块122可响应于确定语音内容1170与第二语音内容之间的差满足(例如,小于)阈值而确定远程话音简档1174与第二用户154相关联。举例来说,语音内容1170可对应于与代替语音信号112中的一或多者相关联的特征。第二语音内容可对应于第二用户154的语音模型。信号处理模块122可确定指示所述特征是否对应于语音模型的置信度值。信号处理模块122可响应于确定所述置信度值满足(例如,高于)置信度阈值而确定远程话音简档1174与第二用户154相关联。
信号处理模块122可响应于确定本地话音简档1104和远程话音简档1174与同一人(例如,第二用户154)相关联而选择本地话音简档1104用于简档管理。信号处理模块122可响应于选择本地话音简档1104而产生图形用户接口(GUI)1138以实现第一用户152的简档管理,将更新请求1110发送到服务器1106以更新本地话音简档1104,或这两者,如本文中所描述。
在特定实施方案中,信号处理模块122可将简档请求1120发送到服务器1106。简档请求1120可指示本地话音简档1104、远程话音简档1174或这两者。举例来说,简档请求1120可包含与第二用户154相关联的识别符1168。语音信号管理器262可响应于接收到简档请求1120而将远程话音简档1174发送到第一装置102。
在特定方面,信号处理模块122可经由输入装置1134接收指示简档请求1120何时将发送到服务器1106的用户输入1140。信号处理模块122可基于用户输入1140发送简档请求1120。举例来说,信号处理模块122可响应于接收到用户输入1140且在接收到用户输入1140后即刻、在特定时间和/或响应于满足特定条件确定用户输入1140指示简档请求1120将发送到服务器1106而将简档请求1120发送到服务器1106。作为另一实例,信号处理模块122可将简档请求1120的多个实例周期性地发送到服务器1106。在特定方面,信号处理模块122可响应于确定第一装置102的特定应用程序(例如,简档管理应用程序)在经激活模式中而将简档请求1120发送到服务器1106。
信号处理模块122可在选择本地话音简档1104之后产生GUI 1138。在特定实施方案中,GUI 1138可对应于图3的GUI 300。GUI 1138可包含本地话音简档1104的表示、远程话音简档1174的表示或这两者。举例来说,GUI 1138可指示与对应于远程话音简档1174的代替语音信号112相关联的第一回放持续时间。为了说明,图3的第一条302、第二条314或第三条316可分别当远程话音简档1174对应于“蓝道尔·休斯”、“萨布瑞纳·桑德斯”或“布雷特·迪恩”时指示第一回放持续时间。第一条302、第二条314和第三条316中的每一者可与远程话音简档1178的相异远程话音简档相关联。举例来说,第一条302可与远程话音简档1174相关联,第二条314可与远程话音简档1178中的第二远程话音简档相关联,且第三条316可与远程话音简档1178中的第三远程话音简档相关联。
在特定方面,GUI 1138可指示与对应于本地话音简档1104的本地代替语音信号1112相关联的第二回放持续时间。为了说明,图3的第一条302、第二条314或第三条316可分别当本地话音简档1104对应于“蓝道尔·休斯”、“萨布瑞纳·桑德斯”或“布雷特·迪恩”时指示第二回放持续时间。第一条302、第二条314和第三条316中的每一者可与本地话音简档1108中的相异本地话音简档相关联。举例来说,第一条302可与本地话音简档1104相关联,第二条314可与本地话音简档1108中的第二本地话音简档相关联,且第三条316可与本地话音简档1108中的第三本地话音简档相关联。在特定实施方案中,GUI 1138可指示与远程话音简档1174相关联的第一回放持续时间和与本地话音简档1104相关联的第二回放持续时间,其中远程话音简档1174和本地话音简档1104与同一人(例如,图1的第二用户154)相关联。第一用户152可基于GUI 1138确定是否更新本地话音简档1104。举例来说,如果第一用户152确定本地话音简档1104对应于短回放持续时间,那么第一用户152可决定基于远程话音简档1174更新本地话音简档1104。作为另一实例,第一用户152可响应于确定GUI 1138指示远程话音简档1174对应于短回放持续时间,通过制止使用远程话音简档1174更新本地话音简档1104而减少更新频率。减少更新频率可节省资源(例如,功率、带宽或这两者)。
GUI 1138可指示指定与话音简档(例如,本地话音简档1104或远程话音简档1174)相关联的更新请求1110何时将发送的选项。信号处理模块122可将GUI 1138提供到显示器1128举例来说,所述选项可对应于自动更新阈值312或添加选项308。信号处理模块122可经由输入装置1134从第一用户152接收对应于所述选项的用户输入1140。用户输入1140可指示更新请求1110何时将发送。举例来说,第一用户152可增加或减小自动更新阈值312。信号处理模块122可响应于确定第一回放持续时间满足(例如,大于或等于)自动更新阈值312而发送更新请求1110。为了说明,信号处理模块122可响应于确定远程话音简档1174指示对应于代替语音信号112的第一回放持续时间满足自动更新阈值312而发送更新请求1110。信号处理模块122可因此通过当第一回放持续时间未能满足(例如,低于)自动更新阈值312时制止发送更新请求1110而减少更新频率。作为另一实例,第一用户152可选择与话音简档(例如,远程话音简档1174、本地话音简档1104或这两者)相关联的特定条(例如,第一条302)且可选择添加选项308。信号处理模块122可响应于接收到指示添加选项308和第一条302的选择的用户输入1140而将指示话音简档(例如,远程话音简档1174、本地话音简档1104或这两者)的更新请求1110发送到服务器1106。
在特定实施方案中,GUI 1138可包含指定与话音简档(例如,远程话音简档1174、本地话音简档1104或这两者)相关联的更新请求(例如,更新请求1110)将周期性地(例如,每日、每周或每月)发送到服务器1106的选项。信号处理模块122可例如响应于接收到指示更新请求将周期性地发送的用户输入1140而将更新请求1110的多个实例周期性地发送到服务器1106。在特定方面,用户输入1140可指示更新时间阈值。信号处理模块122可确定与话音简档(例如,远程话音简档1174、本地话音简档1104或这两者)相关联的第一更新是在第一时间从服务器1106接收。信号处理模块122可在第二时间确定第一时间与第二时间之间的差。信号处理模块122可响应于确定所述差满足由用户输入1140指示的更新时间阈值而将更新请求1110发送到服务器1106。
在特定实施方案中,GUI 1138可包含指定何时制止发送与话音简档(例如,远程话音简档1174、本地话音简档1104或这两者)相关联的更新请求(例如,更新请求1110)的选项。所述选项可对应于停止更新阈值、资源使用阈值或这两者。举例来说,信号处理模块122可响应于确定与本地代替语音信号1112相关联的第二回放持续时间满足(例如,大于或等于)停止更新阈值而制止将更新请求1110发送到服务器1106。为了说明,第一用户152可指定停止更新阈值以使得当对应于本地代替语音信号1112的第二回放持续时间满足(例如,大于或等于)所述停止更新阈值时信号处理模块122不继续自动更新本地话音简档1104。作为另一实例,信号处理模块122可响应于确定资源使用(例如,剩余电池电力、可用存储器、帐期网络使用或其组合)满足资源使用阈值而制止将更新请求1110发送到服务器1106。举例来说,信号处理模块122可当剩余电池电力满足(例如,小于)电力保留阈值时、当可用存储器满足(例如,小于)存储器保留阈值时、当帐期网络使用满足(例如,大于或等于)网络使用阈值时或其组合时制止将更新请求1110发送到服务器1106。
在特定方面,GUI 1138可包含删除选项310。第一用户152可选择第一条302和删除选项310。信号处理模块122可响应于接收到指示删除选项310和第一条302的选择的用户输入1140而将指示对应话音简档(例如,远程话音简档1174)的删除请求发送到服务器1106。语音信号管理器262可响应于接收到删除请求而删除代替语音信号112。在特定实施方案中,信号处理模块122可响应于接收到指示删除选项310和第一条302的选择的用户输入1140而删除本地代替语音信号1112。
语音信号管理器262可响应于接收到更新请求1110将更新1102发送到第一装置102,如本文中所描述。语音信号管理器262可更新与远程话音简档1178和第一装置102相关联的最后更新发送时间以指示更新1102何时将发送到第一装置102。在特定实施方案中,语音信号管理器262可响应于接收到删除请求在第一时间更新与第一装置102和远程话音简档1178相关联的最后更新发送时间以指示所述第一时间。举例来说,语音信号管理器262可更新最后更新发送时间而无需将更新发送到第一装置102,以使得从对第一装置102的后续更新排除代替语音信号112,如本文中所描述,同时保持代替语音信号112以将与远程话音简档1178相关联的更新提供到另一装置。
信号处理模块122可从服务器1106接收更新1102。更新1102可指示本地话音简档1104、远程话音简档1174或这两者。举例来说,更新1102可包含对应于图1的第二用户154的识别符1168。更新1102可包含对应于代替语音信号112的语音数据。信号处理模块122可将代替语音信号112中的每一者添加到本地代替语音信号1112。举例来说,信号处理模块122可将语音数据添加到本地话音简档1104。作为另一实例,信号处理模块122可基于所述语音数据产生代替语音信号112且可将所产生代替语音信号112中的每一者添加到本地代替语音信号1112。
在特定方面,信号处理模块122可以远程话音简档1174的第二片段1166替换本地话音简档1104的第一片段1164。举例来说,第一片段1164可对应于本地代替语音信号1112中的代替语音信号1172。第二片段1166可对应于代替语音信号112中的第一代替语音信号172。信号处理模块122可从本地代替语音信号1112移除代替语音信号1172且可将第一代替语音信号172添加到本地代替语音信号1112。
第一代替语音信号172和代替语音信号1172可对应于类似声音(例如,音素、双音素、三音素、音节、词或其组合)。在特定方面,信号处理模块122可响应于确定第一代替语音信号172具有比代替语音信号1172更高的音频质量(例如,较高信噪比)而以第一代替语音信号172替换代替语音信号1172。在另一方面,信号处理模块122可响应于确定代替语音信号1172已到期(例如,具有超过到期阈值的时戳)而以第一代替语音信号172替换代替语音信号1172。
在特定实施方案中,语音信号管理器262可在第一时间将与远程话音简档1174相关联的第一更新发送到第一装置102。语音信号管理器262可更新最后更新发送时间以指示第一时间。语音信号管理器262可随后确定与远程话音简档1174相关联的代替语音信号112是在将第一更新发送到第一装置102之后产生的。举例来说,语音信号管理器262可响应于确定对应于代替语音信号112中的每一者的时戳指示在最后更新发送时间之后的时间而选择代替语音信号112。语音信号管理器262可响应于确定代替语音信号112是在将第一更新发送到第一装置102之后产生而将更新1102发送到第一装置102。在此特定实施方案中,更新1102可包含少于全部与远程话音简档1174相关联的代替语音信号。举例来说,更新1102可仅包含服务器1106先前尚未发送到第一装置102的那些代替语音信号112。
在特定方面,更新请求1110可指示是否请求所有代替语音信号或是否仅请求先前尚未发送的代替语音信号。举例来说,信号处理模块122可在第一时间将第一更新发送到第一装置102且可更新最后更新发送时间以指示所述第一时间。第二数据库264可包含在所述第一时间之前产生的与远程话音简档1174相关联的第二代替语音信号。代替语音信号112可在第一时间之后产生。
信号处理模块122可发送更新请求1110以请求与本地话音简档1104相关联的所有代替语音信号。在特定方面,信号处理模块122可响应于确定与本地话音简档1104相关联的语音数据已在第一装置102处删除而发送更新请求1110。语音信号管理器262可接收更新请求1110。语音信号管理器262可响应于确定更新请求1110包含与第二用户154相关联的识别符1168而确定更新请求1110对应于远程话音简档1174。语音信号管理器262可响应于确定更新请求1110指示请求所有对应代替语音信号而发送包含与远程话音简档1174相关联的所有代替语音信号的更新1102。替代地,语音信号管理器262可响应于确定更新请求1110指示仅请求先前尚未发送到第一装置102的那些代替语音信号而发送包含少于全部与远程话音简档1174相关联的代替语音信号的更新1102。举例来说,更新1102可包含具有指示在最后更新发送时间之后的时间(例如,产生时间)的时戳的代替语音信号112。
在特定方面,语音信号管理器262可独立于接收更新请求1110而将更新1102发送到第一装置102。举例来说,语音信号管理器262可周期性地发送更新1102。作为另一实例,语音信号管理器262可确定与具有指示超过最后更新发送时间的时间(例如,产生时间)的时戳的代替语音信号(例如,代替语音信号112)相关联的回放持续时间。语音信号管理器262可响应于确定所述回放持续时间满足自动更新阈值而发送代替语音信号112。
本地代替语音信号1112可用以产生经处理语音信号,如本文中所描述。第一用户152可将指示本地话音简档1104的选择1136提供到第一装置102。举例来说,第一装置102可经由输入装置1134接收选择1136。在特定方面,选择1136可对应于以与本地话音简档1104相关联的第二装置的话音呼叫。举例来说,本地话音简档1104可与图1的第二用户154的用户简档相关联。所述用户简档可指示第二装置。第一用户152可起始话音呼叫或可接受来自第二装置的话音呼叫。信号处理模块122可在接收选择1136之后接收输入音频信号1130。举例来说,信号处理模块122可在话音呼叫期间接收输入音频信号1130。信号处理模块122可将输入音频信号1130的第一部分1162与本地代替语音信号1112进行比较。本地代替语音信号1112可包含第一代替语音信号172。信号处理模块122可确定第一部分1162匹配(例如,类似于)第一代替语音信号172。信号处理模块122可响应于确定第一部分1162匹配于第一代替语音信号172通过以第一代替语音信号172替换第一部分1162而产生第一经处理语音信号116,如参考图1所描述。第一代替语音信号172可具有比第一部分1162更高的音频质量。信号处理模块122可经由扬声器142将第一经处理语音信号116输出到第一用户152。
在特定实施方案中,服务器1106可对应于与本地话音简档1104相关联的装置(例如,图1的移动装置104)。举例来说,本文中描述为由服务器1106执行的操作中的一或多者可由移动装置104执行。在此特定实施方案中,本文中描述为由第一装置102发送到服务器1106的一或多个消息(例如,更新请求1110、简档请求1120或这两者)可发送到移动装置104。类似地,本文中描述为由第一装置102从服务器1106接收的一或多个消息(例如,更新1102、远程话音简档1174或这两者)可从移动装置104接收。
系统1100可通过将经处理语音信号提供给用户而改善用户体验,其中通过以代替语音信号替换输入音频信号的一部分而产生经处理语音信号,且其中代替语音信号具有比输入音频信号的所述部分更高的音频质量。系统1100还可提供GUI以使用户能够管理话音简档。
参考图12,揭示系统的特定方面且一般指定为1200。系统1200可执行参考图1到2、4到9和11的系统100到200、400到900和1100描述的一或多个操作。系统1200可包含图11的系统1100的一或多个组件。举例来说,系统1200可包含服务器1106,其经由网络120耦合到第一装置102或与其通信。第一装置102可耦合到或可包含一或多个麦克风1244。第一装置102可包含图1的第一数据库124。第一数据库124可经配置以存储一或多个本地代替语音信号1214。本地代替语音信号1214可对应于与一个人(例如,第一用户152)相关联的本地话音简档1204。
在操作期间,信号处理模块122可经由麦克风1244从第一用户152接收训练语音信号(例如,输入音频信号1238)。举例来说,信号处理模块122可在话音呼叫期间接收输入音频信号1238。信号处理模块122可基于输入音频信号1238产生代替语音信号1212,如参考图2所描述。信号处理模块122可将代替语音信号1212添加到本地代替语音信号1214。信号处理模块122可将更新1202提供到服务器206。更新1202可包含对应于代替语音信号1212的语音数据。更新1202可包含与第一用户152相关联的识别符、本地话音简档1204或这两者。服务器206可接收更新1202,且语音信号管理器262可基于更新1202的识别符而确定更新1202与远程话音简档1178的远程话音简档1274相关联。
在特定实施方案中,语音信号管理器262可确定没有远程话音简档1178对应于更新1202。作为响应,语音信号管理器262可将远程话音简档1274添加到远程话音简档1178。远程话音简档1274可与更新1202的识别符相关联(例如,包含所述识别符)。语音信号管理器262可在第二数据库264中存储代替语音信号1212且可使所存储的代替语音信号1212与远程话音简档1274关联。举例来说,语音信号管理器262可基于语音数据而产生代替语音信号1212且可在第二数据库264中存储代替语音信号1212、语音数据或这两者。
语音信号管理器262可确定与代替语音信号1212相关联的时戳(例如,产生时戳)且可在第二数据库264、存储器1176或这两者中存储所述时戳。举例来说,所述时戳可指示输入音频信号1238由第一装置102接收的时间、代替语音信号1212由信号处理模块122产生的时间、更新1202由第一装置102发送的时间、更新1202由服务器1106接收的时间、代替语音信号1212存储在第二数据库264中的时间,或其组合。语音信号管理器262可确定与代替语音信号1212相关联的回放持续时间且可在第二数据库264、存储器1176或这两者中存储回放持续时间。举例来说,所述回放持续时间可为输入音频信号1238的回放持续时间。在特定实施方案中,更新1202可指示所述回放持续时间且语音信号管理器262可基于更新1202确定回放持续时间。
在特定方面,第一装置102可响应于从服务器1106或另一装置接收到更新请求1210而将更新1202发送到服务器1106。举例来说,服务器1106可周期性地或响应于检测到事件(例如,话音呼叫的起始)而将更新请求1210发送到第一装置102。信号处理模块122可响应于接收到更新请求1210而发送更新1202。
在特定方面,信号处理模块122可响应于确定第一装置102的用户(例如,第一用户152)已授权将代替语音信号1212(或语音数据)发送到服务器1106而发送更新1202。举例来说,信号处理模块122可经由输入装置1134从第一用户152接收用户输入1240。信号处理模块122可响应于确定用户输入1240指示第一用户152已授权将代替语音信号1212发送到服务器1106而将更新1202发送到服务器1106。
在特定方面,信号处理模块122可确定第一装置102的用户(例如,第一用户152)已授权将代替语音信号1212(或语音数据)发送到与特定用户简档(例如,图1的第二用户154的用户简档)相关联的一或多个装置。更新1202可指示代替语音信号1212经授权与其共享的一或多个装置、特定用户简档或其组合。信号处理模块122可在第二数据库264、存储器1176或这两者中存储指示所述一或多个装置、特定用户简档或其组合的授权数据。信号处理模块122可响应于确定所述授权数据指示特定装置而将包含与代替语音信号1212相关联的数据的更新发送到特定装置,如参考图11所描述。
在特定方面,信号处理模块122可产生GUI 1232,其指示选择何时将更新1202当时到服务器1106的选项。信号处理模块122可将GUI 1232提供到显示器1128。信号处理模块122可经由输入装置1134从第一用户152接收用户输入1240。信号处理模块122可响应于接收到用户输入1240而发送更新1202。在特定方面,用户输入1240可指示更新1202(例如,代替语音信号1212或语音数据)将周期性地(例如,每小时、每日、每周或每月)发送或可指示更新阈值(例如,4小时)。作为响应,信号处理模块122可周期性地或基于更新阈值而将更新1202的多个实例周期性地发送到服务器1106。
系统1200可使得装置能够将与用户相关联的代替语音信号提供到另一装置。另一装置可基于对应于用户的输入音频信号而产生经处理语音信号。举例来说,另一装置可通过以代替语音信号替换输入音频信号的一部分而产生经处理语音信号。代替语音信号可具有比输入音频信号的所述部分更高的音频质量。
参考图13,揭示系统的特定方面且一般指定为1300。系统1300可执行参考图1到2、4到9和11到12的系统100到200、400到900和1100到1200描述的一或多个操作。
系统1300可包含图11的系统1100、图12的系统1200或这两者的一或多个组件。举例来说,系统1300包含第一装置102和处理器1152。第一装置102可耦合到麦克风1244、扬声器142或这两者。处理器1152可耦合到或可包含信号处理模块122。信号处理模块122可耦合到模式检测器1302、域选择器1304、文字到语音转换器1322或其组合。
系统1300的一或多个组件可包含在以下各项中的至少一者中:交通工具、电子阅读器(e-reader)装置、移动装置、声学俘获装置、电视、通信装置、平板计算机、智能电话、导航装置、膝上型计算机、可穿戴式装置或计算装置。举例来说,扬声器142中的一或多者可包含在交通工具或移动装置中。移动装置可包含电子阅读器装置、平板计算机、通信装置、智能电话、导航装置、膝上型计算机、可穿戴式装置、计算装置或其组合。存储器1132可包含在以下各项中的至少一者可存取的存储装置中:交通工具、电子阅读器装置、移动装置、声学俘获装置、电视、通信装置、平板计算机、智能电话、导航装置、膝上型计算机、可穿戴式装置或计算装置。
在操作期间,信号处理模块122可经由麦克风1244从第一用户152接收训练语音信号1338。在特定实施方案中,训练语音信号1338可为独立于文字的且可在第一装置102的一般或“正常”使用期间接收。举例来说,第一用户152可激活信号处理模块122的“始终接通”俘获模式,且信号处理模块122可在第一用户152在麦克风1244附近说话时在后台接收训练语音信号1338。信号处理模块122可基于训练语音信号1338产生代替语音信号1212,如参考图2和12所描述。代替语音信号1212可包含第一代替语音信号1372。信号处理模块122可将代替语音信号112、与代替语音信号112相关联的语音数据或这两者添加到本地代替语音信号1214,如参考图12所描述。
模式检测器1302可经配置以检测多个使用模式(例如,阅读模式、对话模式、振鸣模式、命令与控制模式或其组合)中的使用模式1312。使用模式1312可与训练语音信号1338相关联。举例来说,模式检测器1302可当接收到训练语音信号1338时基于信号处理模块122的使用模式设定1362而检测使用模式1312。为了说明,信号处理模块122可响应于检测到第一装置102的第一应用程序(例如,阅读器应用程序或另一阅读应用程序)被激活而将使用模式设定1362设定为阅读模式。信号处理模块122可响应于检测到进行中的话音呼叫或第一装置102的第二应用程序(例如,音频聊天应用程序和/或视频会议应用程序)被激活而将使用模式设定1362设定为对话模式。
信号处理模块122可响应于确定第一装置102的第三应用(例如,振鸣应用程序)被激活而将使用模式设定1362设定为振鸣模式。在特定方面,信号处理模块122可响应于确定训练语音信号1338对应于振鸣而将使用模式设定1362设定为振鸣模式。举例来说,信号处理模块122可提取训练语音信号1338的特征且可基于所提取特征和分类器(例如,支持向量机(SVM))而确定训练语音信号1338对应于振鸣。所述分类器可通过分析话音语音持续时间、有声语音的速率、语音停顿的速率、有声语音间隔(例如,对应于音节)之间的相似性量度或其组合而检测振鸣。
信号处理模块122可响应于确定第一装置102的第四应用程序(例如,个人助理应用程序)被激活而将使用模式设定1362设定为命令与控制模式。在特定方面,信号处理模块122可响应于确定训练语音信号1338包含命令关键词(例如,“激活”)而将使用模式设定1362设定为命令与控制模式。举例来说,信号处理模块122可使用语音分析技术以确定训练语音信号1338包含命令关键词。阅读模式、对话模式、振鸣模式或命令与控制模式中的一者可对应于“默认”使用模式。使用模式设定1362可对应于默认使用模式,除非被超越。在特定方面,信号处理模块122可将使用模式设定1362设定为由用户输入指示的特定使用模式。模式检测器1302可将使用模式1312提供到信号处理模块122。
域选择器1304可经配置以检测多个人口统计域(例如,语言域、性别域、年龄域或其组合)中的人口统计域1314。人口统计域1314可与训练语音信号1338相关联。举例来说,域选择器1304可基于与第一用户152相关联的人口统计数据(例如,特定语言、特定性别、特定年龄或其组合)而检测人口统计域1314。在特定方面,存储器1132可包含与第一用户152相关联的用户简档中的人口统计数据。作为另一实例,域选择器1304可通过使用分类器分析训练语音信号1338而检测人口统计域1314。为了说明,分类器可将训练语音信号1338分类为特定语言、特定性别、特定年龄或其组合。人口统计域1314可指示所述特定语言、特定性别、特定年龄或其组合。域选择器1304可将人口统计域1314提供到信号处理模块122。
信号处理模块122可使使用模式1312、人口统计域1314或这两者与代替语音信号1212中的每一者关联。信号处理模块122可确定与代替语音信号1212相关联的分类1346。分类1346可包含指示代替语音信号1212何时由信号处理模块122产生的时间和/或日期的时戳。分类1346可指示当训练语音信号1338由第一装置102接收时激活的应用程序(例如,阅读应用程序)或所述应用程序的组件(例如,特定故事)。分类1346可指示对应于训练语音信号1338的词、短语、文字或其组合。信号处理模块122可使用语音分析技术将训练语音信号1338分类为一或多种感情(例如,愉悦、愤怒、悲伤等)。分类1346可指示所述一或多种感情。信号处理模块122可使分类1346与代替语音信号1212中的每一者关联。
本地代替语音信号1214可包含由信号处理模块122基于第二训练语音信号产生的一或多个额外代替语音信号(例如,第二代替语音信号1374),如参考图2所描述。第二代替语音信号1374可与第二使用模式、第二人口统计域、第二分类或其组合相关联。
信号处理模块122可从文字到语音转换器1322接收语音信号1330。举例来说,第一用户152可激活文字到语音转换器1322且文字到语音转换器1322可将语音信号1330提供到信号处理模块122。信号处理模块122可基于用户模式设定1362而检测特定使用模式,如本文中所描述。信号处理模块122还可选择特定人口统计域。举例来说,信号处理模块122可从第一用户152接收指示特定用户简档的用户输入。信号处理模块122可基于对应于特定用户简档的人口统计数据而选择特定人口统计域。作为另一实例,用户输入可指示特定语言、特定年龄、特定性别或其组合。信号处理模块122可选择对应于特定语言、特定年龄、特定性别或其组合的特定人口统计域。
信号处理模块122可基于所检测特定使用模式、选定特定人口统计域或这两者而选择本地代替语音信号1214的特定代替语音信号(例如,第一代替语音信号1372或第二代替语音信号1374)。举例来说,信号处理模块122可将语音信号1330的一部分与本地代替语音信号1214中的每一者进行比较。第一代替语音信号1372、第二代替语音信号1374和语音信号1330的所述部分中的每一者可对应于类似声音。信号处理模块122可基于确定特定使用模式对应于(例如,匹配)使用模式1312、特定人口统计域对应于(例如,至少部分地匹配)人口统计域1314或这两者而选择第一代替语音信号1372。因此,使用模式和人口统计域可用以确保语音信号1330的所述部分被在类似上下文中产生的代替语音信号(例如,第一代替语音信号1372)替换。举例来说,当语音信号1330对应于振鸣模式时,语音信号1330的所述部分可被对应于较高音频质量振鸣且不对应于较高音频质量对话语音的代替语音信号替换。
在特定方面,本地代替语音信号1214可与分类相关联。分类中的每一者可具有优先级。信号处理模块122可通过按优先级次序将语音信号1330的所述部分与本地代替语音信号1214进行比较而选择第一代替语音信号1372。举例来说,信号处理模块122可至少部分地基于确定由分类1346指示的第一时戳在由与第二代替语音信号1374相关联的第二分类指示的第二时戳之后而选择第一代替语音信号1372。作为另一实例,信号处理模块122可至少部分地基于确定特定应用程序(例如,电子阅读器应用程序)被激活且所述特定应用程序由分类1346指示且不由第二分类指示而选择第一代替语音信号1372。
信号处理模块122可通过以第一代替语音信号1372替换语音信号1330的所述部分而产生第一经处理语音信号116。信号处理模块122可在存储器1132中存储第一经处理语音信号116。或者或另外,信号处理模块122可经由扬声器142将第一经处理语音信号116输出到第一用户152。
在特定方面,训练语音信号1338可从特定用户(例如,第一用户152)接收且第一经处理语音信号116可输出到同一用户(例如,第一用户152)。举例来说,第一经处理语音信号116可类似于第一用户152的语音而发声。
在另一方面,训练语音信号1338可从特定用户(例如,父母)接收且第一经处理语音信号116可输出到另一用户(例如,所述父母的孩子)。举例来说,所述父母可激活电子阅读器应用程序且在第一天阅读特定故事。训练语音信号1338可对应于所述父母的语音。信号处理模块122可基于训练语音信号1338产生代替语音信号1212,如参考图2和12所描述。信号处理模块122可使使用模式1312(例如,阅读模式)与代替语音信号1212中的每一者关联。信号处理模块122可使人口统计域1314(例如,成年人、女性和英语)与代替语音信号1212中的每一者关联。信号处理模块122可使分类1346(例如,特定故事、电子阅读器应用程序、对应于第一天的时戳、对应于语音信号的文字,和对应于训练语音信号1338的一或多种感情)与代替语音信号1212中的每一者关联。
另一用户(例如,孩子)可在第二天激活文字到语音转换器1322。举例来说,所述孩子可选择特定故事且可选择父母的用户简档。为了说明,所述孩子可选择父母先前阅读的特定故事的后续部分。文字到语音转换器1322可基于特定故事的文字产生语音信号1330。信号处理模块122可接收语音信号1330。信号处理模块122可检测特定用户模式(例如,阅读模式)且可选择对应于父母的用户简档的特定人口统计域(例如,成年人、女性和英语)。信号处理模块122可确定特定分类(例如,特定故事)。信号处理模块122按优先级次序将语音信号1330的一部分与本地代替语音信号1214进行比较。信号处理模块122可基于确定使用模式1312匹配特定使用模式、分类1346匹配特定分类或这两者而选择第一代替语音信号1372。信号处理模块122可通过以第一代替语音信号1372替换语音信号1330的所述部分而产生第一经处理语音信号116。信号处理模块122可经由扬声器142将第一经处理语音信号116输出给孩子。第一经处理语音信号116可类似于父母的语音而发声。孩子因此能够当父母没空(例如,在外地)时听到以父母的话音阅读的特定故事的后续章节。
系统1300可因此实现基于从用户接收的音频信号而产生对应于用户的语音的代替语音信号。代替语音信号可用以产生类似于用户的语音而发声的经处理语音信号。举例来说,可通过以代替语音信号替换语音信号的由文字到语音转换器产生的一部分而产生经处理语音信号。
参看图14,展示替换语音信号的方法的特定说明性方面的流程图且一般指定为1400。方法1400可由图1的信号处理模块122、图4的信号处理模块422、图6的信号处理模块622、图7的信号处理模块722或其组合执行。
方法1400包含在1402处获取多个代替语音信号。举例来说,第一装置102可获取代替语音信号112,如参考图2进一步描述。
方法1400还可包含在1404在装置处接收与用户相关联的用户语音信号。所述用户语音信号可在话音呼叫期间接收。举例来说,第一装置102可在与移动装置104的话音呼叫期间接收第一用户语音信号130,如参考图1进一步描述。
方法1400可进一步包含在1406处将用户语音信号的一部分与同用户相关联的所述多个代替语音信号进行比较。所述多个代替语音信号可存储在数据库中。举例来说,图1的信号处理模块122可将第一用户语音信号130的第一部分162与存储在第一数据库124中的代替语音信号112进行比较,如参考图1进一步描述。
方法1400还可包含在1408处基于所述比较而确定用户语音信号的所述部分匹配于所述多个代替语音信号中的第一代替语音信号。举例来说,图1的信号处理模块122可确定第一部分162匹配于第一代替语音信号172,如参考图1所描述。
方法1400可进一步包含在1410处响应于所述确定通过以第一代替语音信号替换用户语音信号的所述部分而产生经处理语音信号。所述经处理语音信号可在话音呼叫期间产生。举例来说,信号处理模块122可响应于所述确定通过以第一代替语音信号172替换第一部分162而产生第一经处理语音信号116。在特定方面,信号处理模块122可使用平滑算法来减少对应于第一代替语音信号172与第一经处理语音信号116的另一部分之间的转变的语音参数变化,如参考图1进一步描述。
方法1400还可包含在1412处经由扬声器输出经处理语音信号。举例来说,图1的第一装置102可经由扬声器142输出第一经处理语音信号116。
方法1400可进一步包含在1414处基于用户语音信号的多个语音参数而修改第一代替语音信号,且在1416处在数据库中存储经修改第一代替语音信号。举例来说,信号处理模块122可基于第一用户语音信号130的多个语音参数修改第一代替语音信号172以产生经修改代替语音信号176,如参考图1进一步描述。信号处理模块122可在第一数据库124中存储经修改代替语音信号176。
因此,方法1400可实现通过以与用户相关联的代替语音信号替换与同一用户相关联的用户语音信号的一部分而产生经处理语音信号。经处理语音信号可具有比用户语音信号更高的音频质量。
图14的方法1400可由现场可编程门阵列(FPGA)装置、专用集成电路(ASIC)、处理单元(例如,中央处理单元(CPU))、数字信号处理器(DSP)、控制器、另一硬件装置、固件装置或其任何组合实施。作为一实例,图14的方法1400可由执行指令的处理器执行,如相对于图19所描述。
参看图15,展示获取多个代替语音信号的方法的特定说明性方面的流程图且一般指定为1500。在特定方面,方法1500可对应于图14的操作1402。方法1500可由图2的语音信号管理器262执行。
方法1500可包含在1502处接收与用户相关联的训练语音信号。举例来说,图2的服务器206可接收与第二用户154相关联的训练语音信号272,如参考图2进一步描述。
方法1500还可包含在1504处从训练语音信号产生多个代替语音信号,且在1506处在数据库中存储所述多个代替语音信号。举例来说,语音信号管理器262可从训练语音信号272产生代替语音信号112,如参考图2进一步描述。语音信号管理器262可在第二数据库264中存储代替语音信号112。
因此,方法1500可实现可用以替换用户语音信号的一部分的代替语音信号的获取。
图15的方法1500可由现场可编程门阵列(FPGA)装置、专用集成电路(ASIC)、处理单元(例如,中央处理单元(CPU))、数字信号处理器(DSP)、控制器、另一硬件装置、固件装置或其任何组合实施。作为一实例,图15的方法1500可由执行指令的处理器执行,如相对于图19所描述。
参看图16,展示替换语音信号的方法的特定说明性方面的流程图且一般指定为1600。方法1600可由图1的信号处理模块122、图4的信号处理模块422、图6的信号处理模块622、图7的信号处理模块722或其组合执行。
方法1600可包含在1602在装置处基于输入语音信号产生搜索准则。举例来说,分析器402可基于第一用户语音信号130产生搜索准则418,如参考图4所描述。作为另一实例,分析器602可基于第一数据630产生搜索准则612,如参考图6所描述。
方法1600还可包含在1604处通过基于搜索准则搜索数据库而产生搜索结果。所述数据库可存储与多个代替语音信号相关联的语音参数的集合。举例来说,搜索器404可通过基于搜索准则418搜索参数化数据库424而产生搜索结果414,如参考图4所描述。作为另一实例,搜索器604可基于搜索准则612产生多个语音参数的集合614,如参考图6所描述。作为另一个实例,搜索器704可基于搜索准则612产生所述多个代替语音信号714。参数化数据库424可包含语音参数472、474和476。
方法1600可进一步包含在1606处基于约束而选择搜索结果中的特定搜索结果。所述特定搜索结果可与所述多个代替语音信号中的第一代替语音信号相关联。举例来说,约束分析器406可基于约束而选择搜索结果414中的选定结果416,如参考图4所描述。选定结果416可包含第一代替语音信号172、第一语音参数472或这两者。作为另一实例,约束分析器606可选择多个语音参数的集合614中的第一多个语音参数472,如参考图6所描述。作为另一个实例,约束分析器706可选择所述多个代替语音信号714中的第一代替语音信号172,如参考图7所描述。
方法1600还可包含在1608处通过以替换语音信号替换用户语音信号的一部分而产生经处理语音信号。所述替换语音信号可基于特定搜索结果而确定。举例来说,合成器408可通过以替换语音信号替换第一用户语音信号130的一部分而产生第一经处理语音信号116,如参考图4所描述。作为另一实例,合成器608可通过以替换语音信号替换第一数据630的输入信号的一部分而产生第一经处理语音信号116,如参考图6所描述。作为另一个实例,合成器708可通过以替换语音信号替换第一数据630的输入信号的一部分而产生第一经处理语音信号116,如参考图7所描述。
因此,方法1600可实现通过以代替语音信号替换输入语音信号的一部分而产生经处理语音信号。经处理语音信号可具有比输入语音信号更高的音频质量。
图16的方法1600可由现场可编程门阵列(FPGA)装置、专用集成电路(ASIC)、处理单元(例如,中央处理单元(CPU))、数字信号处理器(DSP)、控制器、另一硬件装置、固件装置或其任何组合实施。作为一实例,图16的方法1600可由执行指令的处理器执行,如相对于图19所描述。
参看图17,展示产生用户接口的方法的特定说明性方面的流程图且一般指定为1700。方法1700可由图1的信号处理模块122、图4的信号处理模块422、图6的信号处理模块622、图7的信号处理模块722或其组合执行。
方法1700可包含在1702在装置处产生用户接口。所述用户接口可指示与用户的一或多个语音信号相关联的持续时间。所述用户接口可包含添加选项。举例来说,图1的信号处理模块122可产生用户接口300,如参考图3所描述。用户接口300的第一条302可指示与用户(例如,“蓝道尔·休斯”)的一或多个语音信号相关联的持续时间,如参考图3所描述。用户接口300可包含添加选项308,如参考图3所描述。
方法1700还可包含在1704处将用户接口提供到显示器。举例来说,图1的信号处理模块122可将用户接口300提供到第一装置102的显示器,如参考图3所描述。
方法1700可进一步包含在1706处响应于接收到添加选项的选择而产生对应于所述一或多个语音信号的多个代替语音信号。举例来说,信号处理模块122可响应于接收到图3的添加选项308的选择而产生对应于所述一或多个语音信号的多个代替语音信号112。为了说明,信号处理模块122可响应于接收到添加选项308的选择而将请求发送到语音信号管理器262,且可从语音信号管理器262接收所述多个代替语音信号112,如参考图3所描述。
因此,方法1700可实现代替语音信号的管理。方法1700可实现对与用户相关联的语音信号的监视。方法1700可实现与选定用户相关联的代替语音信号的产生。
图17的方法1700可由现场可编程门阵列(FPGA)装置、专用集成电路(ASIC)、处理单元(例如,中央处理单元(CPU))、数字信号处理器(DSP)、控制器、另一硬件装置、固件装置或其任何组合实施。作为一实例,图17的方法1700可由执行指令的处理器执行,如相对于图19所描述。
参看图18,展示替换语音信号的方法的特定说明性方面的流程图且一般指定为1800。方法1800可由图1的信号处理模块122、图4的信号处理模块422、图6的信号处理模块622、图7的信号处理模块722或其组合执行。
方法1800可包含在1802处在存储本地话音简档的装置处接收远程话音简档,所述本地话音简档与人相关联。举例来说,第一装置102的信号处理模块122可接收与第二用户154相关联的远程话音简档1174,如参考图11所描述。第一装置102可存储与第二用户154相关联的本地话音简档1104。
方法1800还可包含在1804处基于远程话音简档与本地话音简档的比较或基于与远程话音简档相关联的识别符而确定远程话音简档与所述人相关联。举例来说,信号处理模块122可基于与远程话音简档1174相关联的语音内容和与本地话音简档1104相关联的语音内容的比较而确定远程话音简档1174与第二用户154相关联,如参考图11所描述。作为另一实例,信号处理模块122可响应于确定远程话音简档1174包含与第二用户154相关联的识别符1168而确定远程话音简档1174与第二用户154相关联,如参考图11所描述。
方法1800可进一步包含在1806在装置处基于所述确定而选择本地话音简档用于简档管理。举例来说,第一装置102的信号处理模块122可基于确定远程话音简档1174对应于第二用户154而选择本地话音简档1104,如参考图11所描述。简档管理的实例可包含(但不限于)基于远程话音简档1174更新本地话音简档1104,以及通过产生包含远程话音简档1174的表示、本地话音简档1104的表示或这两者的GUI而将话音简档信息提供到用户。
方法1800可因此实现响应于从另一装置接收到人的远程话音简档而选择所述人的本地话音简档用于简档管理。举例来说,可将本地话音简档与远程话音简档进行比较。作为另一实例,可基于远程话音简档而更新本地话音简档。
图18的方法1800可由现场可编程门阵列(FPGA)装置、专用集成电路(ASIC)、处理单元(例如,中央处理单元(CPU))、数字信号处理器(DSP)、控制器、另一硬件装置、固件装置或其任何组合实施。作为一实例,图18的方法1800可由执行指令的处理器执行,如相对于图18所描述。
参考图19,描绘装置(例如,无线通信装置)的特定说明性方面的框图且一般指定为1900。在各种方面中,装置1900可具有比图19中说明的组件更多或更少的组件。在说明性方面中,装置1900可对应于图1的第一装置102、移动装置104、桌上型计算机106或图2的服务器206。在说明性方面中,装置1900可执行本文参考图1到18所描述的一或多个操作。
在特定方面,装置1900包含处理器1906(例如,中央处理单元(CPU)。处理器1906可对应于图11的处理器1152、处理器1160或这两者。装置1900可包含一或多个额外处理器1910(例如,一或多个数字信号处理器(DSP))。处理器1910可包含语音和音乐译码器-解码器(编解码器)1908和回声消除器1912。语音和音乐编解码器1908可包含声码器编码器1936、声码器解码器1938或这两者。
装置1900可包含存储器1932和编解码器1934。存储器1932可对应于图11的存储器1132、存储器1176或这两者。装置1900可包含经由射频(RF)模块1950耦合到天线1942的无线控制器1940。装置1900可包含耦合到显示控制器1926的显示器1128。图1的扬声器142、一或多个麦克风1946或其组合可耦合到编解码器1934。编解码器1934可包含数/模转换器1902和模/数转换器1904。在说明性方面中,麦克风1946可对应于图1的麦克风144、麦克风146、图2的麦克风246、图12的麦克风1244或其组合。在特定方面,编解码器1934可从麦克风1946接收模拟信号,使用模/数转换器1904将所述模拟信号转换为数字信号,且将所述数字信号提供到语音和音乐编解码器1908。语音和音乐编解码器1908可处理所述数字信号。在特定方面,语音和音乐编解码器1908可将数字信号提供到编解码器1934。编解码器1934可使用数/模转换器1902将数字信号转换为模拟信号且可将模拟信号提供到扬声器142。
存储器1932可包含图1的第一数据库124、图2的第二数据库264、图4的参数化数据库424、图11的本地话音简档1108、远程话音简档1178、输入音频信号1130、图13的分类1346、使用模式设定1362,或其组合。装置1900可包含信号处理模块1948、图2的语音信号管理器262、图4的数据库分析器410、图8的应用程序822、图9的搜索模块922、图13的模式检测器1302、域选择器1304、文字到语音转换器1322,或其组合。信号处理模块1948可对应于图1的信号处理模块122、图4的信号处理模块422、图6的信号处理模块622、图7的信号处理模块722或其组合。在特定方面,语音信号管理器262、数据库分析器410、图8的应用程序822、图9的搜索模块922、图13的模式检测器1302、域选择器1304、文字到语音转换器1322和/或信号处理模块1948的一或多个组件可包含在处理器1906、处理器1910、编解码器1934或其组合中。在特定方面,语音信号管理器262、数据库分析器410、图8的应用程序822、图9的搜索模块922、图13的模式检测器1302、域选择器1304、文字到语音转换器1322和/或信号处理模块1948的一或多个组件可包含在声码器编码器1936、声码器解码器1938或这两者中。
信号处理模块1948、语音信号管理器262、数据库分析器410、应用程序822、搜索模块922、模式检测器1302、域选择器1304、文字到语音转换器1322或其组合可用以实施本文所描述的语音信号替换技术的硬件方面。或者或另外,可实施软件方面(或组合的软件/硬件方面)。举例来说,存储器1932可包含可由处理器1910或装置1900的其它处理单元(例如,处理器1906、编解码器1934或这两者)执行的指令1956。指令1956可对应于语音信号管理器262、数据库分析器410、应用程序822、搜索模块922、模式检测器1302、域选择器1304、文字到语音转换器1322、信号处理模块1948或其组合。
在特定方面,装置1900可包含在系统级封装或芯片上系统装置1922中。在特定方面,处理器1906、处理器1910、显示控制器1926、存储器1932、编解码器1934和无线控制器1940包含在系统级封装或芯片上系统装置1922中。在特定方面,输入装置1134和电力供应器1944耦合到芯片上系统装置1922。此外,在特定方面,如图19中所说明,显示器1128、输入装置1134、扬声器142、麦克风1946、天线1942和电力供应器1944在芯片上系统装置1922外部。在特定方面,显示器1128、输入装置1134、扬声器142、麦克风1946、天线1942和电力供应器1944中的每一者可耦合到芯片上系统装置1922的组件,例如接口或控制器。
装置1900可包含移动通信装置、智能电话、蜂窝式电话、膝上型计算机、计算机、平板计算机、个人数字助理、显示装置、电视机、游戏控制台、音乐播放器、无线电、数字视频播放器、数字视频光盘(DVD)播放器、调谐器、相机、导航装置或其任何组合。
在说明性方面中,处理器1910可操作以执行参考图1到18描述的方法或操作的全部或一部分。举例来说,麦克风1946可俘获对应于用户语音信号的音频信号。ADC 1904可将所俘获的音频信号从模拟波形转换为由数字音频样本组成的数字波形。处理器1910可处理数字音频样本。增益调节器可调节数字音频样本。回声消除器1912可减少可能已由扬声器142的输出进入麦克风1946产生的任何回声。
处理器1910可将用户语音信号的一部分与多个代替语音信号进行比较。举例来说,处理器1910可将数字音频样本的一部分与所述多个语音信号进行比较。处理器1910可确定所述多个代替语音信号中的第一代替语音信号匹配用户语音信号的所述部分。处理器1910可通过以第一代替语音信号替换用户语音信号的所述部分而产生经处理语音信号。
声码器编码器1936可压缩对应于经处理语音信号的数字音频样本,且可形成发射包(例如,数字音频样本的经压缩位的表示)。所述发射包可存储于存储器1932中。RF模块1950可调制某一形式的发射包(例如,其它信息可附加到发射包)且可经由天线1942发射经调制数据。作为另一实例,处理器1910可经由麦克风1946接收训练信号且可从训练信号产生多个代替语音信号。
作为另一实例,天线1942可接收包含接收包的传入包。接收包可由另一装置经由网络发送。举例来说,接收包可对应于用户语音信号。声码器解码器1938可去压缩所述接收包。经去压缩的波形可被称作经重构音频样本。回声消除器1912可将回声从经重构音频样本移除。
处理器1910可将用户语音信号的一部分与多个代替语音信号进行比较。举例来说,处理器1910可将经重构音频样本的一部分与所述多个语音信号进行比较。处理器1910可确定所述多个代替语音信号中的第一代替语音信号匹配用户语音信号的所述部分。处理器1910可通过以第一代替语音信号替换用户语音信号的所述部分而产生经处理语音信号。增益调节器可放大或抑制经处理语音信号。DAC 1902可将经处理语音信号从数字波形转换为模拟波形且可将经转换信号提供到扬声器142。
与所描述的方面结合,设备可包含用于接收远程话音简档的装置。举例来说,所述用于接收远程话音简档的装置可包含信号处理模块1948、处理器1906、处理器1910、RF模块1950、经配置以接收远程话音简档的一或多个其它装置或电路,或其任何组合。
所述设备还可包含用于存储与人相关联的本地话音简档的装置。举例来说,所述用于存储的装置可包含存储器1932、信号处理模块1948、处理器1906、处理器1910、经配置以存储本地话音简档的一或多个其它装置或电路,或其任何组合。
所述设备可进一步包含用于基于根据与远程话音简档相关联的语音内容或远程话音简档的识别符确定所述远程话音简档与所述人相关联而选择本地话音简档用于简档管理的装置。举例来说,所述用于选择本地话音简档的装置可包含信号处理模块1948、处理器1906、处理器1910、经配置以选择本地话音简档的一或多个其它装置或电路,或其任何组合。
所述用于接收的装置、所述用于存储的装置和所述用于选择的装置可集成到以下各项中的至少一者中:交通工具、电子阅读器装置、声学俘获装置、移动通信装置、智能电话、蜂窝式电话、膝上型计算机、计算机、编码器、解码器、平板计算机、个人数字助理、显示装置、电视机、游戏控制台、音乐播放器、无线电、数字视频播放器、数字视频光盘播放器、调谐器、相机或导航装置。
所属领域的技术人员将进一步了解结合本文所揭示的方面描述的各种说明性逻辑块、配置、模块、电路和算法步骤可实施为电子硬件、由处理器执行的计算机软件或两者的组合。上文已大体在其功能性方面描述各种说明性组件、块、配置、模块、电路和步骤。此功能性是实施为硬件还是处理器可执行指令取决于特定应用和强加于整个系统的设计约束。所属领域的技术人员可针对每一特定应用以不同方式来实施所描述的功能性,此些实施决策不应被解释为会导致脱离本发明的范围。
应注意虽然前述实例中的一或多者描述与特定个人相关联的远程话音简档和本地话音简档,但此些实例仅用于说明性目的且不视为限制性的。在特定方面,装置可存储“通用”(或默认)话音简档。举例来说,当通信基础设施或环境不支持交换与个别个人相关联的话音简档时可使用通用话音简档。因此,在某些情形中可在装置处选择通用话音简档,包含但不限于当与特定呼叫者或被呼叫者相关联的话音简档不可用时,当替换(例如,较高质量)语音数据不可用于特定使用模式或人口统计域时等等。在一些实施方案中,通用话音简档可用以补充与特定个人相关联的话音简档。为了说明,当与特定个人相关联的话音简档不包含用于特定声音、使用模式、人口统计域或其组合的替换语音数据时,可改为基于通用话音简档而导出替换语音数据。在特定方面,装置可存储多个通用或默认话音简档(例如,用于对话对振鸣、英语对法语等的单独通用或默认话音简档)。
结合本文中所揭示的方面描述的方法或算法的步骤可以直接用硬件、用由处理器执行的软件模块、或用这两者的组合实施。软件模块可驻留在随机存取存储器(RAM)、快闪存储器、只读存储器(ROM)、可编程只读存储器(PROM)、可擦除可编程只读存储器(EPROM)、电可擦除可编程只读存储器(EEPROM)、寄存器、硬盘、可移除式磁盘、压缩光盘只读存储器(CD-ROM)或此项技术中已知的任何其它形式的非暂时性储存媒体中。示范性存储媒体耦合到处理器,使得处理器可从存储媒体读取信息并将信息写入到存储媒体。在替代方案中,存储媒体可与处理器成一体式。处理器及存储媒体可以驻留在专用集成电路(ASIC)中。ASIC可驻存在计算装置或用户终端中。在替代方案中,处理器及存储媒体可以作为离散组件驻留在计算装置或用户终端中。
提供对所揭示方面的先前描述以使得所属领域的技术人员能够制造或使用所揭示的方面。所属领域的技术人员将容易明白对这些方面的各种修改,且在不脱离本发明的范围的情况下,本文中所界定的原理可应用于其它方面。因此,本发明并不希望限于本文展示的方面,而应被赋予与如通过所附权利要求书界定的原理及新颖特征一致的可能的最广范围。
- 还没有人留言评论。精彩留言会获得点赞!