识别生理声音的方法以及系统与流程
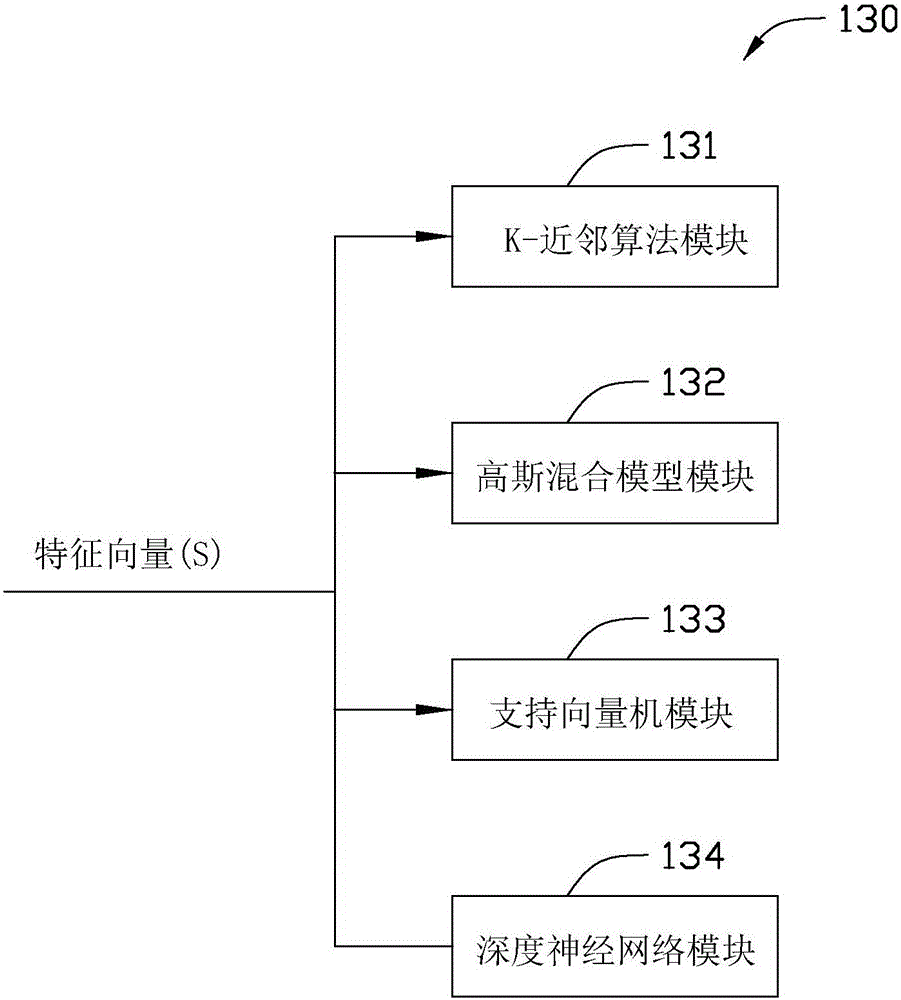
本发明涉及一种用于识别生理声音的方法,特别针对一种提取与分类生理声音特征的方法。本发明也涉及一种用于识别生理声音的系统。
背景技术:
:非侵入性听诊对心脏、肺、骨髓、小肠、血管病的分析已经成为疾病医疗诊断的非常有用的工具。传统的电子听诊器于1992年才被发明。现代的电子听诊器能够提升信号的质量以及提供心脏音信号的可视化应用,例如心音图(phonocardiogram,PCG)。心音图(PCG)以及心电图(Electrocardiography,ECG)可以应用于心脏的基础测试。通过仪器的机械振动记录电信号可以获得心音图(PCG)(听诊器放置在胸部的特定位置进行数据收集)。在心脏的任意两面放置两个电极,并将两个电极连接到心电图机的正极与负极,形成标准心电图并记录身体任意两个地方的心电的电压变化。心电图通常在心电图测纸上所示或者监控,反映整个心脏跳动的节律以及心肌的薄弱部分。第一心音(S1)发生在心脏收缩期,由于心室收缩血液流经大血管并引起二尖瓣和三尖瓣关闭。第一心音(S1)持续时间相对长,音调低。第二心音(S2)发生在心脏舒张期,由于心室壁扩张所引起主动脉瓣和肺动脉瓣迅速关闭,且房室瓣打开引起血液从心房流向心室。第二心音(S2)持续时间相比第一心音(S1)更短。临床上,异常的第三心音以及第四心音有时候也会被发现。第三心音的频率以及幅度较低,由心室壁扩张所引起。第四心音由于心房收缩以及心室壁的舒张时血流快速充盈心室所引起。大量的心脏疾病都能够通过听诊有效诊断。在一些严重的心脏疾病(例如心脏瓣膜功能失常、心脏衰竭等),心脏听诊已经成为早期诊断中成功、可靠、低成本的方式。然而,心脏听诊的准确性同医生的经验息息相关。一些疾病展示了明显的发生方式(例如,第一心音(S1)以及第二心音(S2)发生之间或者第二心音(S2)之后等)。因此,如何自动提取以及初步判断第一心音(S1)与第二心音(S2)的发生时间成为重要课题。这个课题能够有效帮助医生初步证实疾病的发生。常规情况下,第一心音(S1)以及第二心音(S2)的时间顺序成为判断的素材。而且心率不齐的情况下,时间顺序不再可靠。如果第一心音(S1)与第二心音(S2)之间的声纹对比较为合理,心律不齐病例的判断需要提高质量。关于心音的提取研究可以分为两大类:心电信号相关性以及心电信号非相关性。心电信号的相关性研究包括心电图基于瞬时能量的提取(Malarvilietal.,2003)以及QRS波群和T波群的提取(E1-Segaieretal.,2005)。虽然如此,在低质量的心电信号,不大可能总是清晰的测出T波。在这种情况下,第二心音(S2)可以用非监督分类器进行分类(Carvalhoetal.,2005),虽然这些方式必须视乎硬件装置以及被测试者的舒服程度。心电信号非相关性的方法可以分为非监督类方法以及监督类方法。非监督类的方式包括使用归一化平均香农能量(normalizedaverageShannonEnergy,Liangetal.1997)以及高频率的方式(Kumaretal.2006)作为小波分析。监督类的方式包括神经网络分类器(Hebdenetal.,1996)以及决策树(Stasisetal.,1996)用于分类。除此之外,最先进的提取方式往往根据第一心音(S1)与第二心音(S2)之间的规律间距的特征。一般来说,平均的心跳速率(Olmezetal.,2003,Kumaretal.,2006)能够在研究中假定。然而,这些假定并不能应用在心律不齐患者的心脏音。在实际临床案例中,对于心音图以及心电图同时同步进行记录与分析相对较为困难。另外,当无脉搏性电气活动出现的时候,由于电流活动的维持心电图不能判定心率已经停止。因此,如何根据独有的心音图(PCG)进行诊断成为重要以及主流的研究课题。主流的检测手段通常包括判断第一心音(S1)以及第二心音(S2)的时间间隔特征。但是这种特征在一些情况诸如心率不齐变得不再可靠,极大地降低了检测的准确性。因此,前案中缺陷需要得到解决。技术实现要素:有鉴于此,有必要提供一种识别生理声音的系统,包括一接收模块,一特征提取模块,一分类器。接收模块用于接收生理声音;特征提取模块用于提取所述生理声音中至少一特征;分类器用于分类所述至少一特征以识别至少一种种类。所述接收模块是一生理记录装置将生理声音的模拟信号转化为数字信号。所述生理记录装置是一电听诊器。所述特征提取模块包括语音活动检测(VAD)模块以及梅尔频率倒頻谱系数(MFCC)模块。语音活动检测(VAD)模块用于从生理声音中检测至少一声音片段;梅尔频率倒頻谱系数(MFCC)模块用于转移所述至少一声音片段到至少一种梅尔频率倒頻谱系数(MFCC)特征向量中。所述系统进一步包括K-平均算法模块,用于从至少一种梅尔频率倒頻谱系数向量中找出至少一代表点。所述分类器包括监督分类器。所述监督分类器包括K-近邻算法(KNN)模块,高斯混合模型(GMM)模块,支持向量机(SVM)模块或者深度神经网络(DNN)模块。所述生理声音包括心音、肺音、肠鸣音、血管回音、气管呼吸音、支气管呼吸音以及手足呼吸音。所述心音包括第一心音(S1),第二心音(S2)以及两者的混合模型。所述系统进一步包括一比较模块,用于对比正常生理声音以及/或者异常生理声音中至少一种类别以评估疾病风险。所述系统进一步包括自动体外心脏除颤器,动态心电图监护仪,心肺复苏器(CPR),心脏起搏器,埋藏式心脏复律除颤器(ICD),心电图(EKG)或者超声波装置。当系统在非危险情况识别第一心音(S1)和第二心音(S2)时,系统合并成心率检测装置。当系统在危险情况识别第一心音(S1)和第二心音(S2)时,系统区分脉搏状态和无脉搏,从而准确决定使用哪种装置。另外一方面,本发明提供一种使用如上所述系统的识别生理声音的方法,包括:使用接收模块,接收生理声音;使用特征提取模块,从生理声音中提取至少一特征;使用分类器,分类至少一特征以识别至少一种类别。所述从生理声音中提取至少一特征包括:使用语音活动检测(VAD)模块从生理声音中检测至少一声音片段;以及使用梅尔频率倒頻谱系数(MFCC)模块转移所述至少一声音片段到至少一MFCC特征向量。所述方法进一步包括:通过K-平均算法模块从至少一MFCC特征向量中找出至少一代表点。所述分类器包括监督分类器。所述监督分类器包括K-近邻算法(KNN)模块,高斯混合模型(GMM)模块,支持向量机(SVM)模块或者深度神经网络(DNN)模块。所述生理声音包括心音、肺音、肠鸣音、血管回音、气管呼吸音、支气管呼吸音以及手足呼吸音。所述心音包括第一心音(S1),第二心音(S2)或者二者的混合模型。所述方法进一步包括:使用比较模块对比正常生理声音以及/或者异常生理声音中至少一种类别以评估疾病风险。本发明的优点在于识别生理声音的系统以及方法能够准确识别特征性的生理声音,并且能够排除杂讯。从下述的详细实施方式搭配附图,本发明的其他目的、优势和新颖特征将变得更加的显著。附图说明图1显示了本发明中识别生理声音的系统的组成模块图;图2显示了本发明的分类器包括K-近邻算法(KNN)模块、高斯混合模型(GMM)模块、支持向量机(SVM)模块以及深度神经网络(DNN)模块;图3是一个深度神经网络(DNN)模型;图4显示了一个流程图,描述了图1中识别生理声音的方法:S201到S206分别代表步骤201到步骤206;图5是本发明中第一心音(S1)和第二心音(S2)的光谱图(上方位置)和波形图(下方位置);图6显示了心音的精确结果,使用本发明的分类器KNN模块、高斯混合模型(GMM)模块、支持向量机(SVM)模块和深度神经网络(DNN)模块。图7显示了使用语音活动检测(VAD)模块处理的规则心音的能量差异声音片段(实体方框部分所示);图8显示了使用语音活动检测(VAD)模块处理的不规则心音的能量差异声音片段(实体方框部分所示);图9显示了使用语音活动检测(VAD)模块处理的正常肺音的能量差异声音片段(实体方框部分所示);图10显示了使用语音活动检测(VAD)模块处理的哮鸣肺的能量差异声音片段(实体方框部分所示);图11显示了使用语音活动检测(VAD)模块处理的湿啰肺音的能量差异声音片段(实体方框部分所示)。具体实施方式本发明提供一种识别生理声音的系统与方法。如图1和2所示,识别生理声音的系统100包括接收模块110,特征提取模块120,分类器130以及对比模块140。所述特征提取模块120包括语音活动检测(voiceactivitydetector,VAD)模块121,梅尔频率倒頻谱系数(Mel-FrequencyCepstrum,MFCC)模块122,K-平均算法模块123;分类器130包括K-近邻算法模块(K-nearestneighbor,KNN)模块131,高斯混合模型(Gaussianmixturemodel,GMM)模块132,支持向量机(supportvectormachine,SVM)模块133或者深度神经网络(deepneuralnetwork,DNN)模块134。准备1特征提取(1)VAD模块121VAD模块121又称为语音活动检测或者语音检测,通常被使用于判断一段声音信号是否存在人声的语音处理技术。语音活动检测(VAD)模块121的主要应用在语音编码和语音识别。VAD模块121也常用在分类问题前做为预处理,以提高后期辨识的准确性。这种预处理在此的目的用于找出第一心音(S1)和第二心音(S2)的位置,同时进一步侦测此声音片段是第一心音(S1)还是第二心音(S2)。理想状态下,通过听诊器采集的心脏音讯号通常远大于杂讯的讯号,所以我们可以根据声音能量的差异确定此片段是否是我们所需要的心脏音。经过VAD模块121处理之后的结果如图3所示。以能量的差异作为判定心脏音的所在位置。首先,针对每段声音信号計算該段語音的最大标准差,如公式(1)计算。公式(1)中m代表音框,n代表频域,μ代表平均值。接下来计算该段声音每个音框是否有心脏音,如公式(2)所示。fi代表第i个音框,1代表有心脏音以及0代表静止的声音,stdi代表第i个音框的标准差,α以及β代表参数。(2)MFCC模块122通常来说,人体在不同频率域的区间下有着不同的感知敏感度。正常情况下是对于低频率有更高的分辨率,意味着在低频时可以分辨较小的频率差异。此外还需要考虑临界频带现象。在1kHz频率下的临界频带宽度约为100Hz。1kHz频率以上的临界频带宽度成指数增长。因此,我们可以根据人类听觉特征,在频率域中以梅尔量度(Melscale)划分频率带,将属于一条频率带中的频率成分合在一起看成一个能量强度,然后将这些频带强度以离散余弦变换(DiscreteCosineTransform,DCT)计算之后转化为倒频谱,此为梅尔频率倒頻谱(MelFrequencyCepstrum,MFC)。因为梅尔频率倒频谱系数MFCC是依据人耳听觉模型所产生的参数,所以成功地被应用于语音识别以及分类问题中。MFCC模块122利用下列6个连续的步骤计算MFCC:预强,加窗口,快速傅立叶变换(FastFourierTransform,FFT),梅尔滤波器组,非线性转换以及离散余弦变换(DiscreteCosineTransform,DCT)。一般来说,经过以上六个步骤之后可以获取十三个维度的語音特征,包括一个对数能量参数以及十二个倒频谱参数。但在实际运用于音讯分析上,通常会再添加差分倒频谱函数,以显示倒频谱参数如何随着时间进行变化。它的意义为倒频谱参数相对于时间的斜率,也就是代表倒频谱参数在时间上的动态变化。因此,如果加上速度以及加速度的成分之后可以得到39维的语音特征,其计算方法如下所示:c[i]代表第i个维度的倒频谱参数,t代表音框的时间指标。(3)K-平均算法模块123K-平均算法模块123主要目标用于从大量高维度的数据点中找出具有代表性的数据点。这些数据点称为群中心。再根据群中心进行数据压缩(利用少数的数据点代表大量的数据以达到压缩数据功能)以及分类(以少数的代表点来代表特定的类别,可以降低数据量和计算量,避免杂讯带入的负面干扰)。演算法的计算步骤如下所示:A.初始化:将训练资料随机分成K群,任意地选择K个值作为初始的群中心yk,k=1,2,...,KB.递归演算:a.将每一个数据x,对所有K个群中心计算与其之间的距离,并使其归属到距离最短的群中心。k*=argkmind(x,yk),x∈Ck公式(5)b.所有归属于Ck数据的x形成一个群。再重新计算其群中心yk。c.如果新的一组群中心与原先一组的群中心相同,没有改变,则该训练结束。否则就以新的一组群中心替代原先的群中心。回到a步骤持续进行递迴演算。准备2分类器(1)KNN模块131K-近邻算法(KNN)模块131背后的本义是“物以类聚”。换句话说,同一类的物件应该会聚集在一起。用数学的语言来说,如果同一类别的物件若以高维度空间中的点来表示,这些点之间的距离应该会变得比较相近。因此,对于一个未知类别的一笔数据,我们只要找出来在训练数据中和此笔数据最相邻的点,就可以判定此笔数据的类别应该和最接近的点的类别是一樣的。K-近邻算法(KNN)模块131的分类步骤主要是将一个测量数据x分类到类別C中的其中一类。这些步骤的具体实施方式如下:A.决定要使用测量数据x,对训练数据中的最相邻的数据点K。使用合适的距离公式计算距离。B.当测量数据x,于某特定类别中有相对较多数的代表(在K个最近距离中于某类别中的个数占最多),则判定x为该类别。整个分类器所预先需要的信息是:最相邻的K数据点的个数,选择计算距离的公式,以及训练数据。假定我们的训练集为成对的(xi,zi),i=1,...,n。xi代表第i个训练数据的向量,而zi是对应的分类指标(例如zi=j代表第i个训练数据向量是第j类別ωi的样本)。将测试数据向量x与训练数据向量y之间的距离定义为d(x,y)。在此部分使用欧几里得尺度(Euclideanmetric)作为距离计算公式,如公式6所示。(2)高斯混合模型(GMM)模块132高斯分类器是一种常规的分类器,应用贝叶斯定理(Bayes'theorem)作为基本的概念。这也是高斯分类器被称为贝叶斯分类器(NaiveBayesclassifier)的原因。该高斯分类器的概念是利用已知的类型数据计算其概率分布,并在已知类型的概率分布中找出未知类型数据的概率,其中概率最高的类型就会被选作未知数据的类型,而平均值以及标准差作为决定整个模型的两个参数。单一高斯分布是根据一个平均值和一个标准差描述其分布的形状。然而,信号通常是以更加复杂的方式分布。因此,如果只使用一个高斯分布通常无法近似于该信号。而高斯混合模型是使用多个高斯分布来模拟信号。正因为如此,信号的分布能够更好的得到模拟。而且,随着混合高斯曲线的数量提升之后,分布的形状变得更加的相似以及复杂程度变得相对提高。高斯混合模型包括3个参数:平均向量μi,共变异矩阵∑i,加权值ωi。为了简化表示高斯模型,以λ来表示,表示的公式如公式(7)所示。λ={ωi,μi,∑i},i=1,...,K公式(7)特征向量z的混合概率密度函数利用公式(8)表达其中pi(z)为特征向量z的第i个高斯分布概率密度函数。其中因为最大概率值为1,所以(7)式中高斯混合模型的混合概率密度函数的加权值ωi必须符合公式(10)所述的条件才会成立。当有一笔数目为N,维度为d的特征向量z,要将此训练样本训练成符合高斯混合模型λ时,即是希望求得适当高斯混合模型λ的三个参数μi、∑i以及ωi(i=1,…,K)。使得训练过后的模型能充分代表特征向量z的分布。也就是找出一组适当的模型参数,使得特征向量z以及高斯混合模型λ的相似性p(z|λ)为最大,如公式(11)所示。因为公式(8)是非线性的等式,解决过程中复杂的计算公式是难以避免的。一般来说,可以应用最大期望(expectation-maximization,EM)演算法找出高斯混合模型的最佳参数。(3)SVM模型133支持向量机(SVM)模块133广泛使用在统计分类以及迴归分析。根据实验证实SVM模块133有强大的分类能力。SVM模块133的中心概念是将训练数据映射到高维特征平面,以及建立一個最佳超平面(在高维度中的平面且于大间隔中拥有边界)。大部分的SVM模型主要应用在二元分类的问题上,但也可以结合多个二元分类,建构出多重类别的分类方法。而这些情况又被分为线性数据以及非线性数据两种情形。假定一个子集{xi,i=1,...,n}以及子集被分配到ω1或者ω2其中一类,对应标记为yi=±1,其希望能找到一个超平面g(x)(g(x)=wTx+w0),使所有yi=+1的数据点都落在g(x)>0的范围内。通过执行这样操作,即可利用g(x)的正负号来区别。其进一步希望找到与所示两条边界有最大距离的平面,称为最佳超平面。为了使H1与H2之间的距离最大化,需利用公式(12)解决:限制条件如公式(13)所描述yi(wTxi+wo)≥1,i=1,...,n公式(13)当数据不是线性和可分离的时候,利用核函数如(14),将数据投射到更高维度特征空间。常见的核函数包括线性、多项式、高斯径向基函数核,可依照分类问题特性选择不同的核函数。在此部分中使用高斯径向基函数核为核函数,如公式(15)所示:K(x,y)=exp(-||x-y||/2σ2)公式(15)(4)DNN模块134类神经网络(Neuralnetwork,NN)是一种模仿生物神经网络结构和功能的数学模型,使计算机能自我学习并且可利用经验法则来进行推理,所以相比于逻辑推论计算更具有优势。而此演算法有下述的一些特征:1.平行处理(parallelprocessing),2.容错技术(fault-tolerant),3.结合式记忆(combinedmemory),4.解决最佳化问题,5.执行超大规模集成电路(very-large-scaleintegration,VLSI)以及6.处理一般演算法较难处理的问题。到目前为止,许多学者通过设计不同的类神经网络模型来解决不同的问题。常见的网络模型包括反向传播网络(back-propagationnetwork),霍普菲尔德网络(Hopfieldnetwork)以及径向基函数网络(radialbasisfunctionnetwork)。DNN模块134的操作通常采用输出层来作为下一隐藏层的输入。概念在于利用隐藏层数目的提升来增强系统。附图3表示的深度神经网络(DNN)模块134通常含有5个层级。输入层与第一隐藏层的输出之间的关系用公式(16)表述a2=f(W1x)公式(16)x代表输入,W1代表权重,f代表激励函数。此部份使用了sigmoid函数,a2是第二层级的输出。当获取第一隐藏层级的输出之后,相对关系可以用关系式(17)所示。L代表DNN模块134的层级数目。ai+1=f(Wiai),i=2,…,L-1公式(17)除此之外,因为参数的原始值会影响到计算结果,DNN模块134通常使用受限玻尔兹曼机(restrictedBoltzmannmachines,RBM)来执行原始参数的预测,再使用反向传播演算法(Back-propagation)来调整参数,如公式18所示。J(aL,y)=loss(aL,y)公式(18)公式(18)中,y代表标签,aL代表第L层的输出。此部分损失函数(lossfunction)应用了softmax函数。具体的演算法可能参照参考文献(Bengio,2009),Mohamedetal.,2013)。最后,频繁的使用”退出”(dropout)可能避免过度训练以及获得更佳的效率。准备3评估方式评估方式用对比模块140进行操作。该评估方式使用在模式识别与信息检索常会使用的精确性(precision),召回率(recall)和F-量测(F-measure)作为评估该系统的好或者坏的标准(Martinetal.,1997)。考虑到四种情况如表1所述,每一种解释都在公式(19)-(21)中所示。表1项目评估矩阵F-量测通常也被称为F1量测,代表精确性以及召回率的权重均等。召回率通常被称为真阳性率(truepositiverate)或者敏感性(sensitivity),精确性被称为阳性预测值。在分类研究中,准确度(accuracy)通常被用作评估模型,其定义如公式(22)所示。实施例1心脏音的实验全集以及实验步骤识别生理声音的方法中的流程图如图1,2和4所示。步骤201是使用接收模块110来接收生理声音。接收音频的地方通常集成在房室瓣的听诊器区域以及第二大动脉瓣膜听诊器区域。接收模块110通常是一电子听诊器,这个实验中所使用的数据通常是通过电子听诊器来收集实际的声音数据。该目标在于利用心脏音找出第一心音(S1)以及第二心音(S2)的音频轨迹。首先,使用数字手机用于记录心脏音,同时将记录的心脏音转化为模拟的信号。通过解码芯片的解码,模拟音频的信号能够被分解为两个路径。一路径用于转移过滤的声音为数字信号,并且通过耳咽管释放数字信号。另外一条路径主要是用于将非处理的模拟信号储存于建成的记忆平台。另外这些非处理的模拟信号用于研究中的分析。步骤202是使用语音活动检测(VAD)模块121的特征提取模块120提取生理声音的至少一声音片段。因为心脏音集中在低频率,采样频率设置在5kHz。训练数据由17位健康男女性所录制而成。通过人工选择提取第一心音(S1)以及第二心音(S2)之后,我们可以获得完整的322个第一心音(S1)以及313個第二心音(S2);而测试数据則來自3位男性以及1位女性,经过特征提取模块120的处理语音活动检测(VAD)模块121处理之后,共切割出122个心脏音讯号,其中66个是第一心音(S1),另外56个是第二心音(S2)。步骤203是使用特征提取模块120的梅尔频率倒頻谱系数(MFCC)模块122将至少一声音片段转移到至少一个MFCC特征向量中。通过梅尔频率倒頻谱系数(MFCC)模块122提取的MFCC特征向量,从13个维度扩张到39个维度。步骤204使用特征提取模块120的K-平均算法模块123,从至少一个MFCC特征向量找出至少一代表点。在心脏音的片段中,K-平均算法模块123使用2个中央向量来代表心脏音和杂讯部分。步骤205通过分类器130用于辨识与分类所述至少一种特征到至少一种类别,其特征在于分类器130包括K-近邻算法(KNN)模块131,高斯混合模型(GMM)模块132,支持向量机(SVM)模块133或者深度神经网络(DNN)模块134。欧几里得尺度是K-近邻算法(KNN)模块131的距离计算公式。高斯径向基函数核作为核函数。高斯混合模型(GMM)模块132中第一心音(S1)模型以及第二心音(S2)模型各自独立使用8个混合数字。深度神经网络(DNN)模块134设置了3隐藏层,每层有100个神经元。丢弃率为70%。步骤206通过比较模块140,对比正常生理声音或者异常生理声音的至少一种类别以评估疾病风险。通过接收模块110记录正常性音或者异常性音。经过人工选择之后提取第一心音(S1)和第二心音(S2),第一心音(S1)和第二心音(S2)被训练为训练数据。实施例2通过不同的分类器获取心脏音中的准确结果在MFCC特征提取的训练数据中,第一心音(S1)和第二心音(S2)的光谱以及波形图通过图5中观测以及显示。首先,心脏音的频率主要贡献在低频率部分,高度的区分于声音频率低于8kHz的频率段,因此,采样频率调整为5kHz中。心脏音的基线大约为15ms,所以音框尺寸设置为15ms,并且相互重叠了10ms。经过语音活动检测(VAD)模块121调整如公式(2)所示的α以及β的参数之后,使用VAD模块121进行数据训练,手动剪切声频文件通常作为匹配测试数据的目的,该测试数据由VAD模块121的训练数据进行处理。分类器部分,使用K-近邻算法(KNN)模块131,高斯混合模型(GMM)模块132,支持向量机(SVM)模块133以及深度神经网络(DNN)模块134。然而,使用K-近邻算法(KNN)模块131的想法相对来说较为简单,仅仅使用特征作为距离的判断标准。高斯混合模型(GMM)模块132是发生模型。每个种类在高斯模型下分别地进行训练。单独模型中测试数据的概率也可以进行计算。支持向量机(SVM)模块133,使用线性或者非线性(反映)方式以分解训练数据并且获取训练模型。将测试数据引入模型中来获取检测结果。最终,深度神经网络(DNN)模块134在近年来成为最先进的识别方法,同时也模仿了人脑的多层次学习来获取训练模型,检测结果可以通过引入测试数据之后获得。表2.KNN实验结果精确性召回率F-量测准确度S185%77.3%81%-S275.8%83.9%79.7%-平均值---80.3%表3.GMM实验结果精确性召回率F-量测准确度S189.2%87.9%88.6%-S286%87.5%86.7%-平均值---87.7%表4.SVM实验结果精确性召回率F-量测准确度S196.7%89.4%92.9%-S288.5%96.4%92.3%-平均值---92.6%表5.DNN实验结果精确性召回率F-量测准确度S196.8%90.9%93.8%-S290%96.4%93.1%-平均值---93.4%从表2到表5以及图6是根据使用指定的系统结果提取的第一心音(S1)以及第二心音(S2)的实验结果。根据实验结果,支持向量机(SVM)模块133以及深度神经网络(DNN)模块134所示了非常高的识别率。深度神经网络(DNN)模块134准确度达到了93.4%。第一心音(S1)在四种分类器中拥有较高的F-量测。实施例3识别正常心脏音以及异常心脏音为了评估正常以及异常心脏音之间的差异如图7所示,记录三对正常的第一心音(S1)以及三对正常的第二心音(S2)。使用5K的采样频率作为记录因素,同时5K的采样频率以每个样本0.2ms进行。第一心音(S1)的每个样本相对来说是1466,6266,10109941,1588889以及20564,以及第二心音(S2)的每个样本分别是2995,7796,11608,177421,以及22242。第一心音(S1)的第一心率是每分钟60/[(|6266-1466|)x0.2x0.001]=62.5每分钟心跳次数(BeatPerMinute,BPM),以及第一心音的第二心率为64.2BPM。第一心率以及第二心率之间的模块差异是1.7(64.2BPM-62.5BPM),该值远小于第一心率3.125的5%(62.5BPMx5%)。相反的,如图8所示,可以记录三对异常的第一心音(S1)以及三对异常的第二心音(S2)。第一心音(S1)的每个采样分别是1162,8269,11775,17555,第二心音(S2)分别是2661,9630,13344,and18957。第一心音(S1)的第二心率是42.8BPM,第三心率是51.9BPM。第二心率以及第三心率之间的模块差异为9.1,比第二心率2.14的5%要更大。如图1所示,接收模块110,接收正常与异常心脏音,所述特征提取模块120的语音活动检测(VAD)模块121用于提取每对第一心音(S1)与第二心音(S2)的两个声音片段,并且计算每个心率和常规性。两个心率之间的模块差异度比前心率小于5%,心率可以判定为正常,如果所述两个心率之间的模块差异度大于前心率的5%,心率被判定为异常。以上方法可以用识别两个心率循环中的正常以及异常的心率。如图1以及2所示,结合深度神经网络(DNN)模块134声波分析法,以及语音活动检测(VAD)模块121,梅尔频率倒頻谱系数(MFCC)模块112的方法,用于识别第一心音(S1)与第二心音(S2)。由于所述方法以及系统不需要借助于第一心音(S1)以及第二心音(S2)之间的时间间隔信息。所述心率失常问题可以得到有效解决。K-平均算法模块123用于代表心脏音以及噪音。分类法中会自动对比精准率,召回率,F-量测以及准确率,每个实验中实验结果中第一心音(S1)以及第二心音(S2)都会展示出优异的提取结果,第一心音(S1)所示出较高的准确度。在实际的临床使用中,第一心音(S1)以及第二心音(S2)的概念都会成对或者单独的出现在语音活动检测(VAD)模块121中所提取的心脏音中。所述第一心音(S1)的特征有更好的识别率,并且根据程序检测来获取第二心音(S2)。同时,第三心音以及第四心音拥有相同的概念,可以通过上述的本发明实施例中得到识别。实施例4识别正常以及异常肺音如图1以及图4所示,处理相同的步骤来识别正常以及异常的肺音。获取音频的位置位于左胸区域的第六肋间区域。识别不同生理声音的关键步骤是使用特征提取模块120的语音活动检测(VAD)模块121来检测生理声音的声音片段,因为不同的生理声音有其自己的声音片段。如附图9所示,正常肺音的能量差异通过语音活动检测(VAD)模块121处理成每个片段。如图1以及10所示,呼吸喘鸣声的能量差异通过语音活动检测(VAD)模块121处理成每个片段。呼吸喘鸣声(医学术语上称为高调干罗音)是一种呼吸的过程中在呼吸道产生的连续、沙哑、口哨音般的声音。气喘发作的人群通常会有鸣音。如图1以及11所示,湿啰肺音的能量差异通过语音活动检测(VAD)模块121处理成声音片段。湿啰肺音音由小呼吸道的“迅猛打开“所引起,水肿,流出物或者呼吸时候的断气引起肺泡破裂。湿啰肺音在肺炎或者肺水肿中可以听诊到。虽然本发明的大量特征以及优点已在先前的资料中阐述,连同本发明结构和特征的具体方式,所述揭露仅仅用于阐述。本发明细节当可作些许之变动,特别是识别生理声音例如像心脏音、肺音、肠鸣音、血管回音、气管呼吸音、支气管呼吸音以及手足呼吸音,故本发明值保护范围当视后附之申请专利范围所界定者为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1