提高语音可懂度的共振峰增强装置和方法与流程
本发明涉及语音增强;语音处理,具体讲,涉及提高发音部位肌肉萎缩患者语音可懂度的共振峰增强方法。
背景技术:
肌肉萎缩是指因营养障碍导致的肌肉纤维变细甚至消失等导致的肌肉体积缩小问题,引发的原因有:神经源性肌肉萎缩、肌源性肌萎缩、废用性肌萎缩和其他原因等。此外还与神经系统有密切关系,脊髓疾病也常导致肌肉萎缩,如史蒂芬·霍金所患的帕金森症,还有老年痴呆症、多发性硬化症、肌萎缩性脊髓侧索硬化症(ALS)等,这使得病患的发音受到影响。
此外,随着国内的计划生育政策的实施,老年人人口逐渐上升,老龄化问题严重,这在发达国家中更为明显。随着年龄的增长,老年人身体的肌肉日渐萎缩,发音的声道部分的肌肉也逐渐难以控制,因此导致语音清晰度下降、可懂度低,与他人的交流变得困难。
现有的语音增强的方法,都是针对被噪声等干扰的正常人的语音进行处理[1-2],但是这与肌肉萎缩患者的语音特点并不相同。因为肌肉萎缩患者的声道部位存在问题,所以导致语音缺陷,例如从频谱上看存在共振峰残缺或不明显等问题,这与噪声造成的对语音的破坏不甚相同,因此处理办法也不太一样。
此外,有研究表明,肌肉萎缩或者患有神经退行性疾病的病人等无法很好控制发生部位肌肉群的人群进行发声恢复训练时,如果能在训练过程中听到保持了说话人音色的并且发声清晰的语音,对其进行恢复训练可以起到很大的辅助作用。
在语音处理中,时域是难以理解的,因此将语音信号变换到频域并在频域进行处理是最主要的方式。其中,共振峰反映了发音人的声道特性以及音色,因此对共振峰进行调整最为主要和有效。
[1]DTS有限责任公司.用于自适应话音可懂度处理的系统[P].中国专利,102498482B,2014-10-15.
[2]三星电子株式会社.使用共振峰增强对话的方法和装置[P].中国专利,1619646A,200-05-25.
技术实现要素:
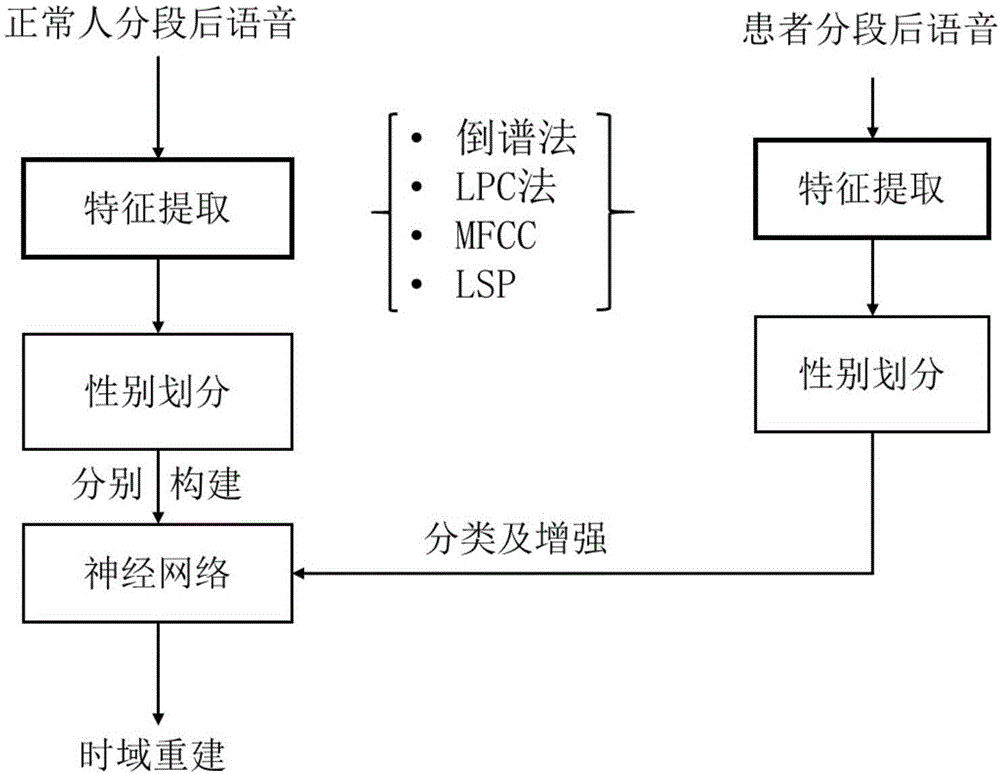
为克服现有技术的不足,本发明旨在提出针对肌肉萎缩患者的发音特点,增强或者恢复发音人语音信息,并保留发音人音色。这一方面可以帮助肌肉萎缩患者训练发声,进行语音发声辅助,同时也可以提高其与其他人的交流。本发明采用的技术方案是,提高语音可懂度的共振峰增强方法,首先对比肌肉萎缩患者的发音特点与正常人发音特点并得到两者的主要差别,采用倒谱法、线性预测编码LPC法、梅尔频率倒谱系数MFCC或线谱对LSP中的一种或多种在不同谱下提取特征参数;其次,用大量正常人语音特征参数作为参考库,此处提取特征参数的方法与提取肌肉萎缩患者语音特征参数的方法保持一致;第三,将肌肉萎缩患者的语音特征参数提取后,进行简单的性别划分;第四,将患者语音特征参数通过已训练好的神经网络进行分类,并与对应性别库内信息做比较,得到最相近的语音段,并以此为参照,对肌肉萎缩患者的语音特征参数进行调整;最后,将调整后的语音信息恢复到时域并进行合成,输出成完整的语音。
在共振峰增强部分,首先将时域信号变换到频域,并提取频域特征参数,这里提到的频域可以是频率也可以是梅尔频率Mel-frequency、倒谱率Cepstrum。
提高语音可懂度的共振峰增强装置,由信号收音装置、预处理器、分段处理器、共振峰增强处理器、合成器、播放器构成;其中:
信号收音装置将患者语音信号收音并进行存储,收音包括语音信号和背景噪声;
预处理器采用谱减法对存储的语音信号进行降噪处理,并将降噪后的语音进行预加重处理;
分段处理器对预处理后的语音信号采用短时平均过零率和短时能量检测进行语音段非语音段的划分,并将每个词或字或音素进行分段,将每段依次存储,并依次输出;
共振峰增强处理器通过LPC梅尔倒谱系数来提取语音的共振峰参数,将此共振峰参数与已计算的性别划分阈值进行比较并进行性别划分,划分后通过相应性别下已训练完善的神经网络进行分类,分类后通过对应音素的预先存储的语音库,找到最相近的共振峰参数,以此共振峰参数为标准调整待处理的共振峰参数,将调整后的共振峰参数变换到时域输出,并适当调整时域幅值;
合成器将已处理的语音信号按序合成;
播放器将合成后的语音信号通过播放器播放并以视图方式呈现。
在一个具体实例中,共振峰增强处理器内部逻辑是:
分帧器对语音信号进行分帧,以15-30ms为帧长,10ms为帧移;
LPC系数提取器提取每帧的LPC系数;
倒谱系数转换器通过LPC系数转换为倒谱系数;
梅尔频率转换器将倒谱系数按梅尔尺度进行非线性变换,转换为LPC梅尔谱系数;
共振峰计算器将LPCCMCC系数计算出共振峰值,取前三个共振峰的中心频率及带宽为共振峰参数;
性别分类器将共振峰计算器计算得到的共振峰中心频率和一个阈值相比较进行性别划分,不同的性别进入不同的音素分类器。
音素分类器为正常人语音LPC梅尔倒谱系数训练后的神经网络,将共振峰计算器计算后的共振峰中心频率及相应带宽通过分类器,得到音素的分类,进入不同的共振峰比较器;
共振峰比较器为正常人语音不同音素下的数据库,将通过性别分类器的共振峰参数通过对应的音素数据库,找到中心频率及带宽偏差最小的共振峰参数,此处主要以共振峰中心频率为主要依据,在保持第二共振峰频率F2偏差最小的情况下,找第一共振峰频率F1偏差尽量小的值,最后保持第三共振峰频率F偏差3尽量小;
共振峰增强滤波器取出音素库中被选中的共振峰参数以及通过共振峰计算器计算的共振峰参数,以音素库中被选中的共振峰参数为基准调节共振峰计算器计算的共振峰参数的带宽及幅值,得到处理后共振峰参数。
时域转换器将处理后共振峰参数变换到时域信号,并进行幅度调整。
本发明的特点及有益效果是:
本发明针对肌肉萎缩患者的发音特点,通过对其语音信号进行频域和时域上的修复,使得在保留说话人音色的同时提高语音的可懂度和质量,并可以作为患者进行语音恢复训练的辅助办法。
附图说明:
图1一种针对发音部位肌肉萎缩导致语音可懂度低的共振峰增强办法。
图2共振峰增强框图。
图3是根据本发明总体构思的实施例的提高可懂度的共振峰增强框图。
图4是图3的预处理器320的框图。
图5是图3的分段处理器330的框图。
图6是图3的共振峰增强处理器340的框图。
图7是图3合成器350的框图。
图8是图3播放器360的框图。
具体实施方式
现有的语音增强的方法多是针对噪声环境如信道噪声、收音噪声等下的语音信息的增强,其主要针对通过算法减少噪声分量、提高语音分量来提高可懂度等。但是,肌肉萎缩患者语音的主要问题在于由于对声道、口腔肌肉的控制能力降低,导致浊音共振峰缺失、清音不突出等问题。这仅仅通过降噪提高SNR并不能很好的提升语音信息、提高可懂度,因为很难区分不清晰的部分是否是噪声。甚至当患者语音的信噪比很高时也存在可懂度低的问题。
本发明旨在针对肌肉萎缩患者的发音特点,增强或者恢复发音人语音信息,并保留发音人音色。这一方面可以帮助肌肉萎缩患者训练发声,进行语音发声辅助,同时也可以提高其与其他人的交流。
现有的语音增强算法用于提高语音的SNR来提升可懂度,这对高SNR但说话人存在发声问题导致可懂度低的语音信号并无太大帮助。
本发明通过分析肌肉萎缩患者与正常人的发音特点和语音特征参数,并与以大量正常人语音为基础进行特征提取并以此特征参数进行训练的神经网络及库进行对比,对肌肉萎缩患者语音的特征参数进行调节,使得在保证发音人音色的特点下提高语音的可懂度。具体实施方法如下:
首先对比肌肉萎缩患者的发音特点与正常人发音特点并得到两者的主要差别,这主要在频域部分进行,可以采用倒谱法、LPC法、MFCC和LSP等从不同谱下提取特征参数;因为每种方法得到的参数有些差别,具体选哪种还凭借实验员一定的经验。可以取:每种方法计算的参数有一个权重,然后权重求和。
其次,用大量正常人语音特征参数作为参考库,此处提取特征参数的方法与提取肌肉萎缩患者语音特征参数的方法保持一致;
第三,将肌肉萎缩患者的语音特征参数提取后,进行简单的性别划分;第四,将患者语音特征参数通过已训练好的神经网络进行分类,并与对应性别库内信息做比较,得到最相近的语音段,并以此为参照,对肌肉萎缩患者的语音特征参数进行调整;最后,将调整后的语音信息恢复到时域并进行合成,输出成完整的语音。
LPC法:线性预测编码(linear predictive coding,LPC)。
MFCC法:梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)。
LSP法:线谱对(Line Spectrum Pairs,LSP)。
倒谱法:Cepstrum法。
下面结合附图和具体实施方式进一步详细说明本发明。
如图1所示,为一种针对发音部位肌肉萎缩导致语音可懂度低的共振峰增强办法。首先可以通过麦克风等进行语音信号的接收,其次进行降噪、预加重等预处理,并将语音段提取分段。然后进行共振峰增强,最后进行语音合成并播放或以视图形式展示共振峰增强前后的语音来进行比较。
在共振峰增强部分,首先将时域信号变换到频域,并提取频域特征参数。这里提到的频域可以是频率也可以是梅尔频率(Mel-frequency)、倒谱率(Cepstrum)等。提取特征的方法可以采用LPC法、倒谱法、MFCC法、LSP法等。将得到的特征参数首先进行初步的性别区分,因为女性普遍比男性的频率高。再通过学习算法构建的神经网络进行分类,得到此片段下的语音是哪种音素。然后与此音素下的正常人语音库进行比较,找到最接近的语音特征,以此为标准,调整需处理信号的频域特征参数。最后将其变换到时域,并进行适当的幅度调整保证语音的质量。
现在将详细描述本发明总体构思的实施例,其例子表述在附图中,其中相同的标号始终表示相同的部件。下面参照附图描述实施例以解释本发明的总体构思。
图3是根据本发明总体构思的实施例的提高可懂度的共振峰增强框图。
参照图3,信号收音装置310将患者语音信号收音并进行存储,收音包括语音信号和背景噪声。
预处理器320采用谱减法对存储的语音信号进行降噪处理,并将降噪后的语音进行预加重处理。
分段处理器330对预处理后的语音信号采用短时平均过零率和短时能量检测进行语音段非语音段的划分,并将每个词或字或音素进行分段,将每段依次存储,并依次通过后续的处理器。
共振峰增强处理器340通过LPC梅尔倒谱系数(LPCCMCC)来提取语音的共振峰参数,将此共振峰参数与已计算的性别划分阈值进行比较并进行性别划分,划分后通过相应性别下已训练完善的神经网络进行分类,分类后通过对应音素的预先存储的语音库,找到最相近的共振峰参数,以此共振峰参数为标准调整待处理的共振峰参数,将调整后的共振峰参数变换到时域输出,并适当调整时域幅值。
合成器350将已处理的语音信号按序合成。
播放器360将合成后的语音信号通过播放器播放并以视图方式呈现。
图4是图3的预处理器320的框图。
预处理器320分为降噪器410和预加重器420。
图5是图3的分段处理器330的框图。
过零检测器510通过短时平均过零率分析进行第一步分段,用于将语音从静音区分割出来,若过零率有突然的下降且小于某一阈值,则认为此处为静音区,并将此处到前一处静音区之间被分为一段语音。
能量检测器520通过短时能量可将清音和浊音划分出来,用于语音进一步分段。
图6是图3的共振峰增强处理器340的框图。
分帧器621对语音信号进行分帧,以15-30ms为帧长,10ms为帧移。
LPC系数提取器622提取每帧的LPC系数。
倒谱系数转换器623通过LPC系数转换为倒谱系数。
梅尔频率转换器624将倒谱系数按梅尔尺度进行非线性变换,转换为LPC梅尔倒谱系数。
共振峰计算器625将LPC梅尔倒谱系数计算出共振峰值,取前三个共振峰的中心频率及带宽为共振峰参数640。
性别分类器626将625计算得到的共振峰中心频率和一个阈值相比较进行性别划分,不同的性别进入不同的音素分类器。
音素分类器627为正常人语音LPCMCC系数训练后的神经网络,将625计算后的共振峰中心频率及相应带宽通过分类器,得到音素的分类,进入不同的比较器。
共振峰比较器628为正常人语音不同音素下的数据库,将通过626的共振峰参数通过对应的音素数据库,找到中心频率及带宽偏差最小的共振峰参数650。此处主要以共振峰中心频率为主要依据,在保持第二共振峰频率F2偏差最小的情况下,找第一共振峰频率F1偏差尽量小的值,最后保持第三共振峰频率F3偏差尽量小。
共振峰增强滤波器629以音素库中被选中的共振峰参数为基准调节共振峰计算器计算的共振峰参数的带宽及幅值,得到处理后共振峰参数。用对语音得到的共振峰假设为f和语音库中的所有共振峰f’进行比较,当两个偏差最小时,选中这个f’,以这个f’为基准,调节f,得到处理后的f。
共振峰增强滤波器629取出音素库中被选中的共振峰参数650以及通过625计算的共振峰参数640,以650为基准调节640共振峰的带宽及幅值,得到处理后共振峰参数660。
时域转换器630将660变换到时域信号670,并进行幅度调整。
图7是图3合成器350的框图。
语段生成器710将每帧信号逐步合成成完整语音段。
语音合成器720将每段语音按序合成成完整语音。
图8是图3播放器360的框图。
视图器810将处理前后的时域语音信号进行显示。
语音播放器820将处理后语音播放。
- 还没有人留言评论。精彩留言会获得点赞!