一种基于深度学习的智慧视听设备多业务控制方法及系统与流程
本发明涉及智慧视听设备多业务控制技术领域,尤其涉及一种基于深度学习的智慧视听设备多业务控制方法及系统。
背景技术:
随着物联网和人工智能技术的进步,智慧视听设备技术迅速发展。越来越多的智慧视听设备被设计生产出来,实现了各种多媒体视听业务,以满足人们生活中的不同需求。由不同厂商设计生产的设备有着不同的控制和人机交互方式。这些设备可能采用红外、蓝牙、Z-wave等各种控制方式,以语音、动作、触控等方式实现人机交互。智慧视听设备控制和人机交互方式的不统一提高了用户学习使用智慧视听设备的门槛,且易造成用户体验不佳的问题。融合多种业务场景、为这些智慧视听设备提供一种统一、轻松自然的控制和人机交互方式是一个亟待解决的问题。
深度学习是人工智能的子领域。近年来,随着图形处理器(Graphics Processing Unit,GPU)、云计算等技术的进步,深度学习理论研究取得了突破性进展。与此同时,深度学习技术的引入使得计算机视觉、语音识别等领域突飞猛进。这也为智慧视听设备控制技术带来了新的思路。
现有一种基于音频和视频的智能家居自然交互系统[1],使用麦克风和摄像头采集声音和图像信息,使用信息融合模块进行信号处理,然后使用机器学习方法获取有用指令,再使用控制信号发射模块发出控制信号。
该系统使用语音、手势、人脸、动作多种等信息来进行控制,不能为用户提供一种简单统一的交互方式,造成用户掌握系统使用的学习成本高,用户体验不佳等问题。其采用传统机器学习方法来识别语音、图像等多媒体信息,使得其识别率较低,系统健壮性较差。并且其语音、图像识别程序运行于本地,这增加了用户的硬件和能源成本。
技术实现要素:
本发明的目的在于克服现有技术的不足,本发明提供了一种基于深度学习的智慧视听设备多业务控制方法及系统,可控制多种基于不同控制协议、实现多种不同业务的智慧视听设备,为它们提供一种更统一、更自然的人机交互和控制的方式。
为了解决上述问题,本发明提出了一种基于深度学习的智慧视听设备多业务控制方法,所述方法包括:
麦克风阵列以特定频率监听采集用户发出的语音控制信号;
语音预处理模块对语音控制信号进行提取,获得梅尔倒谱系数(Mel-scale Frequency Cepstral Coefficients,MFCC)原始语音特征信息;检测MFCC原始语音特征的对数能量是否大于阈值;若是,则由互联网连接模块发送MFCC原始语音特征信息到远程图形处理器(Graphics Processing Unit,GPU)服务器;
远程GPU服务器接收到MFCC原始语音特征信息,根据MFCC原始语音特征信息获得深度语音特征信息,并将深度特征信息对应的控制信号标识信息发送给互联网连接模块;
互联网连接模块将控制信号标识信息传递给控制信号解析模块,由控制信号解析模块根据控制信号标识信息生成控制信号编码,选择对应的控制信号输出模块,将控制信号编码传递给该控制信号输出模块;
控制信号输出模块根据控制信号编码发送控制信号给智慧视听设备。
优选地,所述语音预处理模块对语音控制信号进行提取,获得MFCC原始语音特征信息的步骤,包括:
对语音控制信号进行端点检测及分割处理;
对分割处理后的语音控制信号进行降噪处理;
对降噪处理后的语音控制信号进行MFCC原始语音特征提取,获得MFCC原始语音特征信息。
优选地,所述远程GPU服务器接收到MFCC原始语音特征信息,对MFCC原始语音特征信息进行深度语音特征提取,获得深度语音特征信息的步骤,包括:
远程GPU服务器接收到MFCC原始语音特征信息,启动深度学习语音识别程序,采用双向长短时记忆循环神经网络(Bidirectional Long Short-Term Memory,biLSTM)算法对MFCC原始语音特征信息进行深度语音特征提取,获得深度语音特征信息。
优选地,所述远程GPU服务器接收到MFCC原始语音特征信息,根据MFCC原始语音特征信息获得深度语音特征信息,并将深度特征信息对应的控制信号标识信息发送给互联网连接模块的步骤,包括:
远程GPU服务器接收到MFCC原始语音特征信息,对MFCC原始语音特征信息进行深度语音特征提取,获得深度语音特征信息,并将深度特征信息对应的控制信号标识信息发送给互联网连接模块;
远程GPU服务器对深度语音特征信息进行分类,得到该深度语音特征信息对应的类别,并检测该类别是否对应一种控制信号标识;若是,返回控制信号标识信息给互联网连接模块。
相应地,本发明还提供一种基于深度学习的智慧视听设备多业务控制系统,所述系统包括:麦克风阵列、语音预处理模块、远程GPU服务器、互联网连接模块、控制信号解析模块、控制信号输出模块;其中,
麦克风阵列以特定频率监听采集用户发出的语音控制信号;
语音预处理模块对语音控制信号进行提取,获得MFCC原始语音特征信息;检测MFCC原始语音特征的对数能量是否大于阈值;若是,则由互联网连接模块发送MFCC原始语音特征信息到远程GPU服务器;
远程GPU服务器接收到MFCC原始语音特征信息,根据MFCC原始语音特征信息获得深度语音特征信息,并将深度特征信息对应的控制信号标识信息发送给互联网连接模块;
互联网连接模块将控制信号标识信息传递给控制信号解析模块,由控制信号解析模块根据控制信号标识信息生成控制信号编码,选择对应的控制信号输出模块,将控制信号编码传递给该控制信号输出模块;
控制信号输出模块根据控制信号编码发送控制信号给智慧视听设备。
优选地,所述语音预处理模块包括:
分割单元,用于对语音控制信号进行端点检测及分割处理;
降噪单元,用于对分割处理后的语音控制信号进行降噪处理;
提取单元,用于对降噪处理后的语音控制信号进行MFCC原始语音特征提取,获得MFCC原始语音特征信息。
优选地,所述远程GPU服务器接收到MFCC原始语音特征信息,启动深度学习语音识别程序,采用biLSTM算法对MFCC原始语音特征信息进行深度语音特征提取,获得深度语音特征信息。
优选地,远程GPU服务器接收到MFCC原始语音特征信息,对MFCC原始语音特征信息进行深度语音特征提取,获得深度语音特征信息,并将深度特征信息对应的控制信号标识信息发送给互联网连接模块;
远程GPU服务器对深度语音特征信息进行分类,得到该深度语音特征信息对应的类别,并检测该类别是否对应一种控制信号标识;若是,返回控制信号标识信息给互联网连接模块。
实施本发明实施例,可使用自然语音控制多种基于不同控制协议、实现多种不同业务的智慧视听设备,为智慧视听设备提供一种统一、自然、高效、低成本的人机交互方式;同时将复杂的深度学习任务部署在远程服务器上,降低了用户的硬件和能源成本,为用户提供高性能、低成本的智慧视听设备语音控制指令识别服务,提高智慧视听设备语音控制指令的识别准确率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
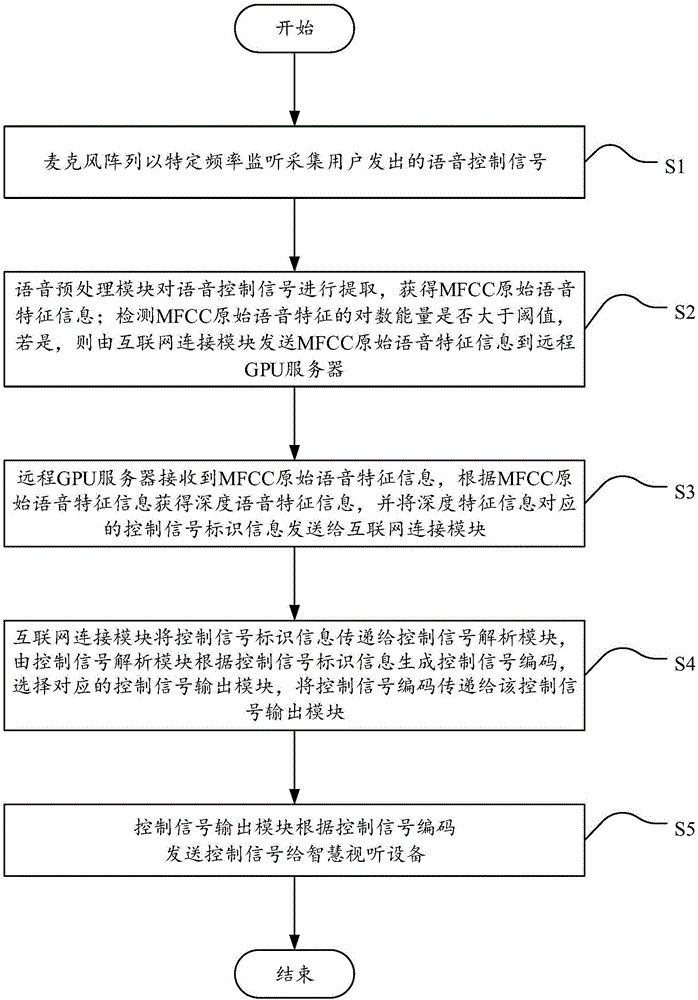
图1是本发明实施例的基于深度学习的智慧视听设备多业务控制方法的流程示意图;
图2是本发明实施例中深度学习语音识别模型的示意图;
图3是本发明实施例的基于深度学习的智慧视听设备多业务控制及系统的结构组成示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
图1是本发明实施例的基于深度学习的智慧视听设备多业务控制方法的流程示意图,如图1所示,该方法包括:
S1,麦克风阵列以特定频率监听采集用户发出的语音控制信号;
S2,语音预处理模块对语音控制信号进行提取,获得MFCC原始语音特征信息;检测MFCC原始语音特征的对数能量是否大于阈值;若是,则由互联网连接模块发送MFCC原始语音特征信息到远程GPU服务器;若否,则返回S1;
S3,远程GPU服务器接收到MFCC原始语音特征信息,根据MFCC原始语音特征信息获得深度语音特征信息,并将深度特征信息对应的控制信号标识信息发送给互联网连接模块;
S4,互联网连接模块将控制信号标识信息传递给控制信号解析模块,由控制信号解析模块根据控制信号标识信息生成控制信号编码,选择对应的控制信号输出模块,将控制信号编码传递给该控制信号输出模块;
S5,控制信号输出模块根据控制信号编码发送控制信号给智慧视听设备。
在语音预处理模块对语音控制信号进行提取,获得MFCC原始语音特征信息的过程中,包括:
对语音控制信号进行端点检测及分割处理;
对分割处理后的语音控制信号进行降噪处理;
对降噪处理后的语音控制信号进行MFCC原始语音特征提取,获得MFCC原始语音特征信息。
具体地,在S3中,远程GPU服务器接收到MFCC原始语音特征信息,启动深度学习语音识别程序,采用biLSTM算法对MFCC原始语音特征信息进行深度语音特征提取,获得深度语音特征信息。
进一步地,远程GPU服务器接收到MFCC原始语音特征信息,对MFCC原始语音特征信息进行深度语音特征提取,获得深度语音特征信息,并将深度特征信息对应的控制信号标识信息发送给互联网连接模块;
远程GPU服务器对深度语音特征信息进行分类,得到该深度语音特征信息对应的类别,并检测该类别是否对应一种控制信号标识;若是,返回控制信号标识信息给互联网连接模块;若否,则返回错误标识给互联网连接模块。
在本发明实施例中,如图2所示,深度学习语音识别模型的主体结构包括由一个正向长短时记忆循环神经网络和一个反向长短时记忆循环神经网络组成的biLSTM、一个Softmax分类器。该深度学习语音识别模型的输入发送自本地互联网连接单元MFCC语音特征,其输出是T+1个类别标识符。这些类别标识符包括T个与本系统支持的控制信号一一对应的类别,以及一个Default类别。如果模型输出Default类别,说明该MFCC语音特征无法对应一种对智慧视听设备的控制信号。深度学习语音识别模型由其训练生成阶段预先产生,而后被部署与远程GPU服务器上为用户提供智慧视听设备语音控制指令识别服务。
在具体实施中,深度学习语音识别模型的训练生成过程如下:
第一步:根据所需支持的智慧视听设备种类和这些设备实现的业务功能,模拟真实的设备使用情境,使用麦克风阵列收集大量语音片段;
第二步:人工标注这些语音片段对应的控制信号类别;
第三步:使用语音预处理模块对所有语音片段提取MFCC语音特征,得到已标记控制语音特征数据集;
第四步:数据集划分,取上述已标记控制语音特征数据集中一定量的数据组成训练数据集,即Training Set,一定量的数据作为验证数据集,即Validation Set;
第五步:随机初始化深度学习语音识别模型中的所有参数;
第六步:以训练数据集为输入,执行深度学习正向传播过程;
第七步:采用时间反向传播(Back Propagation Through Time,BPTT)方法执行深度学习反向传播过程,更新深度学习语音模型中的所有参数;
第八步:若执行周期到达验证周期,则使用验证数据集验证当前的深度学习语音识别模型;
第九步:若达到训练的停止条件则停止训练,否则返回第六步。该停止条件可以是训练次数达到一定值,或验证误差小于一定值。
相应地,本发明实施例还提供一种基于深度学习的智慧视听设备多业务控制系统,如图3所示,该系统包括:麦克风阵列1、语音预处理模块2、远程GPU服务器3、互联网连接模块4、控制信号解析模块5、控制信号输出模块6;其中,
麦克风阵列1以特定频率监听采集用户发出的语音控制信号;
语音预处理模块2对语音控制信号进行提取,获得MFCC原始语音特征信息;检测MFCC原始语音特征的对数能量是否大于阈值;若是,则由互联网连接模块4发送MFCC原始语音特征信息到远程GPU服务器3;
远程GPU服务器3接收到MFCC原始语音特征信息,根据MFCC原始语音特征信息获得深度语音特征信息,并将深度特征信息对应的控制信号标识信息发送给互联网连接模块4;
互联网连接模块4将控制信号标识信息传递给控制信号解析模块5,由控制信号解析模块5根据控制信号标识信息生成控制信号编码,选择对应的控制信号输出模块6,将控制信号编码传递给该控制信号输出模块6;
控制信号输出模块6根据控制信号编码发送控制信号给智慧视听设备。
在本发明实施例中,麦克风阵列1实时采集用户发出的语音信号,并将语音信号发送给语音预处理模块2。
语音预处理模块2负责对语音信号进行端点检测、降噪处理、以及MFCC原始语音特征提取操作。
互联网连接模块4负责与远程GPU服务器3建立网络连接、发送MFCC原始语音特征信息到远程GPU服务器3、接收来自远程GPU服务器3的反馈消息。
控制信号解析模块5负责解析来自远程GPU服务器3的反馈消息,根据消息内容启用对应的控制信号输出模块6,或进行错误处理。
控制信号输出模块6有多个,每个控制信号输出单元安装了支持一种无线通信方式的硬件,负责控制基于该无线通信方式的所有智慧视听设备。这些无线通信方式包括红外、蓝牙、Z-wave等。
远程GPU服务器3为用户提供智慧视听设备语音控制指令识别服务。
进一步地,语音预处理模块2包括:
分割单元,用于对语音控制信号进行端点检测及分割处理;
降噪单元,用于对分割处理后的语音控制信号进行降噪处理;
提取单元,用于对降噪处理后的语音控制信号进行MFCC原始语音特征提取,获得MFCC原始语音特征信息。
远程GPU服务器3接收到MFCC原始语音特征信息,启动深度学习语音识别程序,采用biLSTM算法对MFCC原始语音特征信息进行深度语音特征提取,获得深度语音特征信息。
远程GPU服务器3接收到MFCC原始语音特征信息,对MFCC原始语音特征信息进行深度语音特征提取,获得深度语音特征信息,并将深度特征信息对应的控制信号标识信息发送给互联网连接模块4;
远程GPU服务器3对深度语音特征信息进行分类,得到该深度语音特征信息对应的类别,并检测该类别是否对应一种控制信号标识;若是,返回控制信号标识信息给互联网连接模块4。
具体地,本发明实施例的系统相关功能模块的工作原理可参见方法实施例的相关描述,这里不再赘述。
实施本发明实施例,可使用自然语音控制多种基于不同控制协议、实现多种不同业务的智慧视听设备,为智慧视听设备提供一种统一、自然、高效、低成本的人机交互方式;同时将复杂的深度学习任务部署在远程服务器上,降低了用户的硬件和能源成本,为用户提供高性能、低成本的智慧视听设备语音控制指令识别服务,提高智慧视听设备语音控制指令的识别准确率。
本领域普通技术人员可以理解上述实施例的各种方法中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,该程序可以存储于一计算机可读存储介质中,存储介质可以包括:只读存储器(ROM,Read Only Memory)、随机存取存储器(RAM,Random Access Memory)、磁盘或光盘等。
另外,以上对本发明实施例所提供的基于深度学习的智慧视听设备多业务控制方法及系统进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!