一种基于短时能量和分形维数的语音端点检测方法与流程
本发明涉及语音识别技术领域,特别是涉及一种基于短时能量和分形维数的语音端点检测方法。
背景技术:
在语音识别中,端点检测是一项非常重要的工作。所谓端点具体是指从一段语音信号中确定出语音的起始位置和结束位置。端点检测不仅能在语音识别中减少数据的采集量,节约处理时间,还能排除无声段或噪声段的干扰,提高语音识别系统的性能,而且在语音编码中还可以降低噪声和静音段的比特率,提高编码的效率。如何准确的找出语音信号的端点尤其是低信噪比的环境下,噪声能量可能淹没说话人的语音信号,这样对后续的训练识别产生较大影响。那么一种鲁棒性较高的方法就显的尤为重要。
传统的端点检测方法是利用短时能量和过零率的双门限双参数法进行端点判决。首先在语音的短时能量包络上选取一个高的门限进行一次粗判决,高于该门限阈值的认定是语音段,而语音的起始结束位置则应该位于低于该高门限之外的包络线上;然后再利用过零率确定一个低的门限,在第一次粗判决的高门限起点向左、终点向右继续搜寻出语音段的真正起始位置,之所以再次使用过零率来二次判决是由于汉语音节由平均短时能量较大的韵母音节和频率较高即过零率较大的辅音声母两部分构成的。
在没有噪声干扰或者高信噪比情况下,上述端点检测方法可以准确的找出说话者语音端的起止位置。但是当噪声严重时,例如,信噪比降低至10dB时,上述端点检测方法就无法准确地检测出端点的位置。
由此可见,当信噪比较低时,如何准确检测出语音信号的端点位置是本领域技术人员亟待解决的问题。
技术实现要素:
本发明的目的是提供一种基于短时能量和分形维数的语音端点检测方
法,用于当信噪比较低时,如何准确检测出语音信号的端点位置。
为解决上述技术问题,本发明提供一种基于短时能量和分形维数的语音端点检测方法,包括:
对源语音信号进行预处理得到每一帧语音信号;
利用分形维数的理论计算所述每一帧语音信号对应的分形维数值,并计算所述每一帧语音信号的短时能量值,以得到所述短时能量值与所述分形维数值的比值;
判断所述每一帧语音信号所对应的比值是否大于或等于第一阈值,如果是,则大于或等于所述第一阈值的帧为话音帧;
在所述话音帧两侧方向上提取所述源语音信号包含的起始端点和结束端点。
优选地,所述在所述话音帧两侧方向上提取所述源语音信号包含的起始端点和结束端点具体包括:
依次判断所述话音帧左侧的帧的比值是否低于第二阈值,如果否,则继续判断,直到找到比值低于所述第二阈值的帧,并将该帧作为所述起始端点;
依次判断所述话音帧右侧的帧的比值是否低于第二阈值,如果否,则继续判断,直到找到比值低于所述第二阈值的帧,并将该帧作为所述结束端点;
其中,所述第二阈值小于所述第一阈值。
优选地,所述第一阈值为1.6。
优选地,所述第二阈值为1.16。
优选地,所述预处理包括预加重处理、分帧处理和加窗处理。
优选地,所述加窗处理中采用海明窗函数进行处理。
优选地,所述分形维数为关联维数,则对应的所述分形维数值为关联维数值。
本发明所提供的基于短时能量和分形维数的语音端点检测方法,包括对源语音信号进行预处理得到每一帧语音信号;利用分形维数的理论计算每一帧语音信号对应的分形维数值,并计算每一帧语音信号的短时能量值,以得到短时能量值与分形维数值的比值;判断每一帧语音信号所对应的比值是否大于或等于第一阈值,如果是,则大于或等于第一阈值的帧为话音帧;在话音帧两侧方向上提取源语音信号包含的起始端点和结束端点。本方法将分形维数的理论应用在端点检测上,将每一个帧的短时能量值与分形维数值的比值与第一阈值比较,从而筛选出话音帧,然后在话音帧的两侧方向上提取起始端点和结束端点。因此本方法可以在信噪比较低的语音信号中有效地提取到端点。
附图说明
为了更清楚地说明本发明实施例,下面将对实施例中所需要使用的附图做简单的介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明提供的一种基于短时能量和分形维数的语音端点检测方法的流程图;
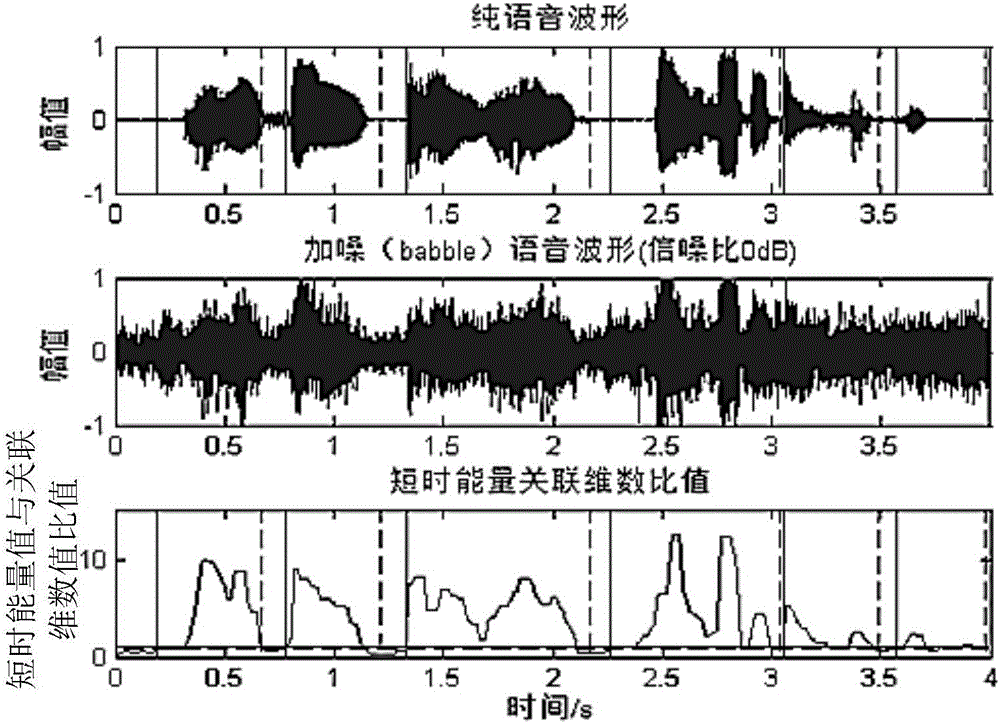
图2为本发明实施例提供的一种在纯语音波形中加入babble噪声后的端点检测示意图;
图3为本发明实施例提供的一种在纯语音波形中加入pink噪声后的端点检测示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下,所获得的所有其他实施例,都属于本发明保护范围。
本发明的核心是提供一种基于短时能量和分形维数的语音端点检测方法。
为了使本技术领域的人员更好地理解本发明方案,下面结合附图和具体实施方式对本发明作进一步的详细说明。
图1为本发明提供的一种基于短时能量和分形维数的语音端点检测方法的流程图。如图1所示,该方法包括:
S10:对源语音信号进行预处理得到每一帧语音信号。
这里的源语音信号的持续时间长短没有规定,在对源语音信号进行计算之前,首先要进行预处理,这里的预处理主要是将源语音信号进行分帧处理,但是并不是说只能进行分帧处理。在具体实施中,预处理可以包括预加重处理、分帧处理和加窗处理。通过预加重处理不仅能够提升高频部分,去除口唇辐射的影响,同时也衰减了低频部分。通过预加重处理还可以降低基频对共振峰检测的干扰,有利于检测出共振峰。加窗处理是将分帧处理后的信号进行过渡连接,作为优选地实施方式,加窗处理中采用海明窗函数进行处理。需要说明的是,加窗处理还可以采用其它方式,并不代表只有这一种方式。
本实施例中每一帧信号的持续时间可以设定为10ms-30ms,但是并不局限于这个范围。
S11:利用分形维数的理论计算每一帧语音信号对应的分形维数值,并计算每一帧语音信号的短时能量值,以得到短时能量值与分形维数值的比值。
分形理论是用分形维度和数学方法对客观事物进行描述,更加趋近复杂系统的真实属性与状态的描述,更加符合客观事物的多样性与复杂性。由于语音信号具有分形特性,因此可以将分形理论运用于端点检测中。在具体实施中,分形维数有多种方法,例如计盒维数,信息维数、关联维数等。不同的维数方法在计算维数上各有不同,考虑到关联维数反映了集合中点的分布信息,所以计算出的结果波动相对较小。所以作为优选地实施方式,分形维数为关联维数,则对应的分形维数值为关联维数值。
关联为数值的计算公式如下:
其中,p为第Ni个点落入容量为δ的盒子里的概率,i为正整数,m表示采样点的序号,N表示帧的总数量,1≤m≤l,1≤i≤N,l为每一帧的长度,xi和xj为第i和第j个重构相空间矢量,H(di,j,P)是Heaviside阶跃函数。
短时能量信号的计算公式为:
其中,yi(m)为第i帧中第m个采样点的能量值。
S12:判断每一帧语音信号所对应的比值是否大于或等于第一阈值。如果是,进入步骤S13。其中,比值大于或等于第一阈值的帧为话音帧。
S13:在话音帧两侧方向上提取源语音信号包含的起始端点和结束端点。
可以理解的是,每一帧语音信号都能得到一个比值,步骤S12中筛选出比值大于第一阈值的帧。这样的帧可能存在多个,则我们需要进一步判断每个帧对应的起始端点和结束端点。
本实施例中的两侧方向指的是话音帧的左侧和右侧,左侧为当前话音帧之前的帧的方向,而右侧为当前话音帧之后的帧的方向。例如在一段语音信号中,有10个帧,分别为第一个帧,第二个帧,第三个帧、第四个帧,第五个帧,第六个帧、第七个帧,第八个帧,第九个帧、第十个帧。如果第三个帧为话音帧,第八个帧为话音帧的话,则第三个帧的左侧就是第二个帧,第三个帧的右侧就是第四个帧。
本实施例提供的基于短时能量和分形维数的语音端点检测方法,包括对源语音信号进行预处理得到每一帧语音信号;利用分形维数的理论计算每一帧语音信号对应的分形维数值,并计算每一帧语音信号的短时能量值,以得到短时能量值与分形维数值的比值;判断每一帧语音信号所对应的比值是否大于或等于第一阈值,如果是,则大于或等于第一阈值的帧为话音帧;在话音帧两侧方向上提取源语音信号包含的起始端点和结束端点。本方法将分形维数的理论应用在端点检测上,将每一个帧的短时能量值与分形维数值的比值与第一阈值比较,从而筛选出话音帧,然后在话音帧的两侧方向上提取起始端点和结束端点。因此本方法可以在信噪比较低的语音信号中有效地提取到端点。
作为优选地实施方式,在话音帧两侧方向上提取源语音信号包含的起始端点和结束端点具体包括:
依次判断话音帧左侧的帧的比值是否低于第二阈值,如果否,则继续判断,直到找到比值低于第二阈值的帧,并将该帧作为起始端点;
依次判断话音帧右侧的帧的比值是否低于第二阈值,如果否,则继续判断,直到找到比值低于第二阈值的帧,并将该帧作为结束端点;
其中,第二阈值小于第一阈值。
还以上文中10个帧为例说明,如果第三个帧为话音帧,第八个帧为话音帧的话,则对于第三个帧来说,需要依次判断第三个帧的左侧的帧,由于是依次判断,因此,首先要判断第三个帧左侧的第一个帧,即第二个帧,如果第二个帧的比值小于第二阈值,则第二个帧就是起始端点,否则再判断第一个帧。对于第三个帧的右侧来说,首先是判断第四个帧的比值是否小于第二阈值,如果不小于,则继续判断第五个帧的比值,直到找到比值低于第二阈值的帧。可以理解的是,如果没有找到一个帧的比值低于第二阈值,则该话音帧就是起始端点。
对于第八个帧来说,与第三个帧的执行过程相同,本实施例不再赘述。
作为优选的实施方式,第一阈值为1.6。作为优选的实施方式,第二阈值为1.16。
可以理解的是,第一阈值和第二阈值需要根据具体情形设定,这里选取1.6和1.16只是一种具体实施方式。
为了验证本发明提供的端点检测方法的可靠性,进行了相关的仿真实验。实验运行环境为win7系统的32位pc机,软件为matlabR2013a,当然使用其他分形维数如计盒维数、信息维数也是可以的。由于使用不同分形维数所用时间性能检测结果上略有不同,实验采用关联维数在上述环境下运行时间为5到10分钟左右,比传统的端点检测时间稍长,但在抗噪的鲁棒性表现良好。本次实验采样频率设置为8000Hz,帧长为200个样点,帧移为100个样点,窗函数设置为海明窗。
图2为本发明实施例提供的一种在纯语音波形中加入babble噪声后的端点检测示意图。如图2所示,实线为起始端点,虚线为结束端点。如图2所示,在相同环境下,通过本发明提供的端点检测方法能够在噪声中检测到端点,且与纯语音波形中的端点位置相同,表明该方法可靠性较高。
图3为本发明实施例提供的一种在纯语音波形中加入pink噪声后的端点检测示意图。
以上对本发明所提供的基于短时能量和分形维数的语音端点检测方法进行了详细介绍。说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也落入本发明权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!