一种动画口型与语音实时匹配的方法与流程
本发明涉及通过分析语音的音节为语音实时匹配动画人物的口型,可为录制好的语音或实时语音,匹配动画人物的口型进行实时聊天、直播、录播,使得使用者可以使用不同形象的动画人物进行交互,具体为一种动画口型与语音实时匹配的方法。
背景技术:
社交娱乐中的趣味性越来越成为吸引人们的一个要素,本发明可以为录制好的语音或实时语音,匹配动画人物的口型进行实时聊天、直播、录播,使得使用者可以使用不同形象的动画人物进行交互,大大提升社交娱乐中的趣味性。
技术实现要素:
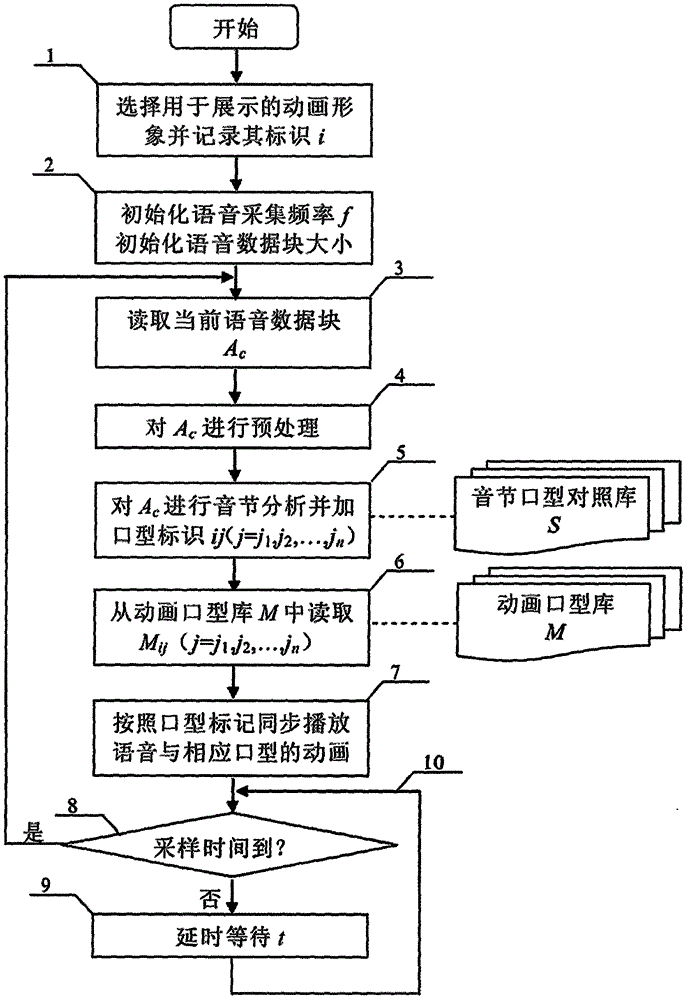
本发明采用的技术方案为:首先建立动画口型库M、音节口型对照库S;然后按照一定的周期与大小读取语音数据,为了音节分析的准确性,先对语音数据进行去噪及增强处理,然后进行音节分析并根据所述音节口型对照库S对语音数据添加口型标记,最后依据口型标记从所述动画口型库M中获取相应图片并同步播放。本发明的技术方案总流程图如图1所示。
本发明包括动画口型库M、音节口型对照库S及以下步骤:
(1)选择用于展示的动画形象并记录其标识i;
(2)初始化语音采集频率f,初始化语音数据块大小;
(3)读取当前语音数据块Ac;
(4)对所述当前语音数据块Ac进行预处理;
(5)对所述当前语音数据块Ac进行音节分析,并根据所述音节口型对照库S对所述当前语音数据块Ac添加口型标识ij(j=j1,j2,...,jn),生成添加了口型标识的语音数据块Ac’;
(6)从所述动画口型库M中读取Mij(j=j1,j2,...,jn);
(7)按照口型标记同步播放语音与相应口型的动画图片;
(8)判断采样时间是否到,若是则转步骤(3),否则转步骤(9);
(9)延时等待t时长;
(10)转步骤(8)。
所述动画口型库M是与不同音节口型对应的动画图片集合。
所述语音采集频率f与语音数据块大小是可变的;
对所述当前语音数据块Ac的预处理操作包括去噪及信号增强。
对所述当前语音数据块Ac进行音节分析并添加口型标识ij(j=j1,j2,...,jn),是对语音进行元音、辅音及停顿的分析,并对不同音节按照所述音节口型对照库S添加该音节对应的口型标识。
本发明具有以下优点:
(1)可以用不同的动画形象为语音匹配口型进行实时视频聊天、直播、录播,提升了聊天、直播、录播的趣味性;
(2)可以通过语音驱动自动制作多人物形象与角色的简单动画作品。
附图说明
图1是一种动画口型与语音实时匹配的方法的总流程图。
具体实施方式
下面结合附图,通过一个为实时语音流匹配动画口型的具体实施例来进一步阐述本发明。具体实施例仅用于说明本发明而不用于限制本发明要求保护的范围。
有n个动画人物,每个动画人物有m种口型,因此共有m×n个动画口型。
其中,ij为Mij的标识,i=1,2,...,n,j=1,2,...,m。
音节与口型的对应关系是多对一的关系,音节口型对照库用对应列表描述。
参照图1,在步骤1中,使用者选择第i个动画人物作为播出的动画形象,记录i,其中i=1,2,...,n;
步骤2中,初始化语音采集频率f和初始化语音数据块大小,对于实时语音流,f=25次/秒,语音数据块大小即为当前40ms的语音数据大小;
步骤3中,读取当前40ms的语音数据块Ac;
步骤4中,对Ac用小波变换进行预处理;
步骤5中,对Ac进行元音、辅音、停顿的音节分析,然后根据所述音节口型对照库S通过查表法选择对应的口型,并对所述语音数据块Ac添加口型标识ij(j=j1,j2,...,jn),生成添加了口型标识的语音数据块Ac’;
步骤6中,从所述动画口型库M中读取Mij(j=j1,j2,...,jn);
步骤7中,按照口型标记同步播放语音与相应口型的动画,f=25次/秒,在处理效率不足时可以降低图片播放频率,但是必须满足25次/秒≥f≥15次/秒,因此动画可以达到非常连贯的动画效果,由于语音的处理与分析延时40ms,因此动画播出比读取到语音延时40ms,但是最终的动画与语音是同步播放;
步骤8中,判断采样时间40ms是否到,若是则转步骤3,若否则转步骤9;
步骤9中,延时等待t=5ms,考虑到采样延时,在实时语音的情况下,动画与语音同步播出比语音产生延时最多45ms;
步骤10中,转步骤8。
尽管已经参照本发明的特定示例性实施例详细阐述了本发明,但是本领域技术人员应理解,在不脱离由权利要求及其等同物定义的本发明的精神和范围的情况下,可在形式和细节上进行各种改变。
- 还没有人留言评论。精彩留言会获得点赞!