一种方言语境的多语言翻译方法与流程
一种方言语境的多语言翻译系统及方法,用于方言和个性化语音的翻译,属于计算机语言翻译技术领域。
背景技术:
在世界各国文化、经济、军事等各领域的交往中,语言的沟通显得尤为重要,为了准确的表达两种语言的意义长期以来在各种外事交往中主要还是以人翻译为主。近年来随着计算机及数字技术的快速发展,用计算机及数字技术做翻译工作已取得了很大的进步,各种优秀的计算机翻译系统不断涌现,特别在文字翻译方面已较完美。但在用计算机翻译系统做同声翻译方面由于各母语系下方言较多语境不同或个人发音的偏好导致误译率较高,不能准确表达源语音的意义。
在众多的语言翻译系统及翻译设备中都只能将源母语系中的相对标准的基语音翻译为目标语系的标准基语音。但在现实应用环境中由于需翻译的源语音在很多情况下为非标准语音,世界上各大母语系中每种母语系都有若干的地方方言,这导致计算机化的语言翻译系统因语境的不同有很高的误译率。
专利号为200820234990.5的专利,是通过提取方言语音的字、词句作为特征与标准基语音进行直接对比来找到方言语音对应的标准基语音,一旦说方言的人发音不准确,就容易造成翻译不准确,从而找不到对应的标准基语音,而且所要翻译的每句方言都需要存储,造成存储成本、运行硬件成本高及计算机运算速度慢等问题。
技术实现要素:
本发明的目的在于:解决现有技术中的语言翻译工具不能准确的翻译方言,增加翻译的误译率的问题,提供了一种方言语境的多语言翻译方法。
本发明采用的技术方案如下:
一种方言语境的多语言翻译方法,其特征在于包括以下步骤:
步骤1、建立母语系下各种方言语音的特征码组成的特征码库;
步骤2、根据特征码与标准基语音特征码的差异产生方言的特征补偿码,组成特征补偿码库;
步骤3、用特征补偿码与其对应的源语音复合产生出对应母语系下的标准基语音;
步骤4、标准基语音转换成目标语言的语音或文本。
进一步,特征码库的建立方法包括以下步骤:
步骤1.1、获得母语系下各种方言语音样本;
步骤1.2、对方言语音样本进行预处理去掉冗余部分,通过带通滤波器进行预滤波处理后再通过一个高通滤波器进行预加重,对预加重后的方言语音样本减噪后乘以汉明窗后进行端点检测;
步骤1.3、将乘以汉明窗预处理后的方言语音样本进行频谱分析,然后进行特征提取,特征提取频谱分析后的方言语音样本的共振峰,基音周期特征,mfcc及lpcc参数特征码;
步骤1.4将获取的共振峰,基音周期特征,mfcc及lpcc参数特征码进行去冗余后对多个方言语音文件进行特征码的概率分布统计,找出其共同特性做为该方言语音的特征码要素;
步骤1.5将具有特征码要素的代码采用压缩方式重新编码为64字节的方言语音的特征码,将该特征码赋予检索号编入特征码库。
进一步,步骤1.3中对频谱分析后的方言语音的共振峰的提取步骤包括:
对频谱分析后的方言语音经过同态滤波后得到平滑的谱再对该谱求离散傅里叶变换,然后用dft谱来提取语音信号的共振峰参数。
进一步,步骤1.3中对频谱分析后的方言语音的基音周期特征的提取步骤包括:
对频谱分析后的方言语音采用平均幅度差函数法来提取基音周期特征。
进一步,步骤1.3中对频谱分析后的方言语音的mfcc参数的提取步骤包括:
将频谱分析后的方言语音进行短时傅里叶变换得到其频谱,再求频谱幅度的平方得能量谱,用三角滤波均衡器进行带通滤波,滤波器的个数与临界带数相近,设滤波器数为m,滤波后得到的输出为:x(k),k=l,2,…,m,对滤波器组的输出取对数,然后作2m点逆傅里叶变换即可得到mfcc参数。
进一步,步骤1.3中对频谱分析后的方言语音的lpcc参数的提取步骤包括:
将频谱分析后的方言语音进行z变换后对数模函数的反z变换,通过信号的傅里叶变换,取模的对数,再求反傅里叶变换得到lpcc参数。
进一步,步骤2中特征补偿码库的建立采用以下步骤:
步骤2.1、获取母语系下的标准基语音样本,提取标准基语音的特征码;
步骤2.2、对母语系下方言语音特征码与标准基语音特征码进行分析比较,得出有泛意的各自概率分布差异频谱;
步骤2.3、将该差异频谱进行反码叠加运算得出方言语音的特征补偿码;
步骤2.3、方言语音的特征补偿码与特征码复合,复合后再与标准基语音的特征码经过n次校验纠正,经过对方言语音特征补偿码的n次校验纠正后复合得出标准基语音特征码在允许误差范围内,该特征补偿码即为该方言语音的特征补偿码,将该特征补偿码赋予检索号编入特征补偿码库。
进一步,步骤3中的特征补偿码获取步骤:通过源语音的特征补偿码与特征补偿码库进行相似性检索得到对应的特征补偿码。
进一步,步骤3中的特征补偿码获取是通过用户手动设置。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
1、本发明可通过匹配出源语音与标语基语音的特征补偿码,再用源语音与特征补偿码进行复合,能准确的翻译出方言或个性化语言,大大减少了现有翻译设备的误译率,准确率可高达95%以上;
2、本发明适用不同场合下的方言语音翻译,显著提高了计算机化的语言同声翻译应用范围;
3、本发明通过提取最能代表的各方言或个性化语音的特征,使得生成的特征补偿码适用于对应的方言或个性化语音,避免了发音出现偏差时,造成复合的标准基语音不准确的问题;
4、本发明对存储硬件、运行硬件的要求低,从而节约了硬件成本,使得运算速度快。
附图说明
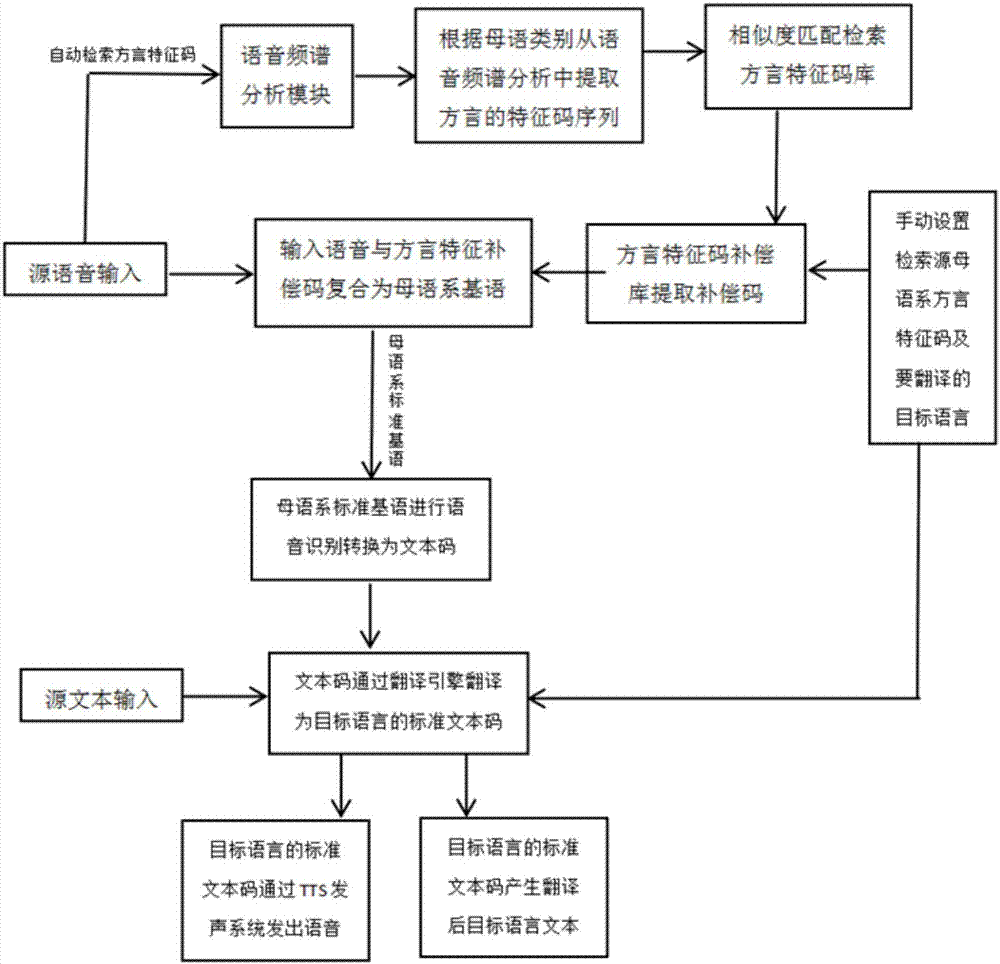
图1为本发明中系统建立特征码库与特征补偿码库的示意图;
图2为本发明中进行未知语种翻译时特征补偿码的获取的框架示意图;
图3为本发明中进行指定语种翻译时特征补偿码的获取的框架示意图;
图4为本发明中特征码库的实施例1的示意图,从左往右依次为时域图、语谱图共振峰、基音周期图、音强图;
图5为本发明中特征码库的实施例2的示意图,从左往右依次为时域图、语谱图共振峰、基音周期图、音强图;
图6为本发明中特征码库的实施例3的示意图,从左往右依次为时域图、语谱图共振峰、基音周期图、音强图;
图7为本发明中特征码库的实施例4的示意图,从左往右依次为时域图、语谱图共振峰、基音周期图、音强图;
图8为本发明中特征码库的实施例5的示意图,从左往右依次为时域图、语谱图共振峰、基音周期图、音强图;
图9为本发明中特征码库的实施例6的示意图,从左往右依次为时域图、语谱图共振峰、基音周期图、音强图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
一种方言语境的多语言翻译方法,具体的实现方法如下:
首先应建立母语系下各方言语音(即可以是世界各母语系下的各方言或个性化语音,也可以是指定的母语系下的各方言或个性化语音)的特征码库和特征补偿码库。特征码库的建立采用以下步骤:
用同一段有代表性的文字进行语音朗读,朗读者为某母语系下各种方言男、女声语音,该方言语音朗读者应对该方言具有一定的代表性与泛意性。
将方言语音朗读者朗读的文本采样后录入为方言语音文件保存,语音文件的参数为:采样率11025hz,单声道,采样精度16位,文件长度1~30s,每种方言语音文件分别录制男女声各有代表性的文字语音文件至少各50个,录制的方言语音文件越多,最后对方言语音特征码的概率分布统计越准确。
对方言语音的预处理:去掉冗余部分,通过带通滤波器进行预滤波处理后再通过一个高通滤波器进行预加重,对预加重后的信号减噪后乘以汉明窗后进行端点检测。
将乘以汉明窗预处理后的方言语音进行频谱分析,然后进行特征提取,特征重点是采用最能代表方言语音特征的共振峰,基音周期特征,mfcc及lpcc参数进行分析及特征提取。
共振峰的提取:对频谱分析后的方言语音经过同态滤波后得到平滑的谱再对该谱求离散傅里叶变换(dft),然后用dft谱来提取语音信号的共振峰参数。
基音周期特征的提取:对频谱分析后的方言语音采用平均幅度差函数(amdf)法来提取基音周期特征。
mfcc的提取:将频谱分析后的方言语音进行短时傅里叶变换得到其频谱,再求频谱幅度的平方得能量谱,用三角滤波均衡器进行带通滤波,滤波器的个数与临界带数相近,设滤波器数为m,滤波后得到的输出为:x(k),k=l,2,…,m,对滤波器组的输出取对数,然后作2m点逆傅里叶变换即可得到mfcc参数。
lpcc的提取:将频谱分析后的方言语音进行z变换后对数模函数的反z变换,通过信号的傅里叶变换,取模的对数,再求反傅里叶变换得到lpcc参数。
将获取的共振峰,基音周期特征,mfcc及lpcc参数特征码进行去冗余后对多个方言语音文件进行有方言语音特征码的概率分布统计,重点是对元音的发音,第一共振峰和第二共振峰,基音曲线,lpcc和mfcc的概率分布统计,找出共同特性做为该方言语音的特征码要素。
将具有特征码要素的代码采用压缩方式重新编码为64字节的方言语音的特征码,将该特征码赋予检索号编入特征码库,即特征码库。
特征码库的具体建立如下:
实施例1
本实施例采用美国人说英语样板语音“thisisatestsampleformyself”。采样频率11025hz,采样深度16bit,单声道,时长2.157秒。实际分析的时域图,语谱图共振峰,基音周期图,音强图,如图4所示;提取共振峰,基音周期特征,mfcc及lpcc参数特征码进行去冗余后对方言语音文件进行有方言语音特征码的概率分布统计,将具有特征码要素的代码采用压缩方式重新编码为64字节的方言语音的特征码,将该特征码赋予检索号编入特征码库,即编入频谱特征码库。
实施例2
本实施例采用英国人说英语样板语音“thisisatestsampleformyself”。采样频率11025hz,采样深度16bit,单声道,时长2.267秒。实际分析的时域图,语谱图共振峰,基音周期图,音强图,如图5所示;提取共振峰,基音周期特征,mfcc及lpcc参数特征码进行去冗余后对方言语音文件进行有方言语音特征码的概率分布统计,将具有特征码要素的代码采用压缩方式重新编码为64字节的方言的特征码,将该特征码赋予检索号编入特征码库,即编入频谱特征码库。
实施例3
本实施例采用印度人说英语样板语音“thisisatestsampleformyself”。采样频率11025hz,采样深度16bit,单声道,时长1.956秒。实际分析的时域图,语谱图共振峰,基音周期图,音强图,如图6所示;提取共振峰,基音周期特征,mfcc及lpcc参数特征码进行去冗余后对方言语音文件进行有方言语音特征码的概率分布统计,将具有特征码要素的代码采用压缩方式重新编码为64字节的方言语音的特征码,将该特征码赋予检索号编入特征码库,即编入频谱特征码库。
实施例4
本实施例采用中国人说河南话样板语音“请输入标准语音文本作语音采样的样板”。采样频率11025hz,采样深度16bit,单声道,时长4.27秒。实际分析的时域图,语谱图共振峰,基音周期图,音强图,如图7所示;提取共振峰,基音周期特征,mfcc及lpcc参数特征码进行去冗余后对方言语音文件进行有方言语音特征码的概率分布统计,将具有特征码要素的代码采用压缩方式重新编码为64字节的方言语音的特征码,将该特征码赋予检索号编入特征码库,即编入频谱特征码库。
实施例5
本实施例采用中国人说四川话样板语音“请输入标准语音文本作语音采样的样板”。采样频率11025hz,采样深度16bit,单声道,时长4.928秒。实际分析的时域图,语谱图共振峰,基音周期图,音强图,如图8所示;提取共振峰,基音周期特征,mfcc及lpcc参数特征码进行去冗余后对方言语音文件进行有方言语音特征码的概率分布统计,将具有特征码要素的代码采用压缩方式重新编码为64字节的方言语音的特征码,将该特征码赋予检索号编入特征码库,即编入频谱特征码库。
实施例6
本实施例采用中国人说普通话样板语音“请输入标准语音文本作语音采样的样板”。采样频率11025hz,采样深度16bit,单声道,时长3.96秒。实际分析的时域图,语谱图共振峰,基音周期图,音强图,如图9所示;提取共振峰,基音周期特征,mfcc及lpcc参数特征码进行去冗余后对方言语音文件进行有方言语音特征码的概率分布统计,将具有特征码要素的代码采用压缩方式重新编码为64字节的方言语音的特征码,将该特征码赋予检索号编入特征码库,即编入频谱特征码库。
方言语音的特征码库建立后,为能将源语音复合为该母语系的标准基语音,应建立母语系下的方言语音复合所需的特征补偿码库。与特征码库对应的特征补偿码库的建立,使得翻译系统在实际应用时能减少硬件成本。频谱特征补偿码库的建立采用以下步骤:
用同一段有代表性的文字进行语音朗读,朗读者为某母语系下各种标准男,女声语音,该语音朗读者应为该母语系标准基语音。
对标准基语音提取标准基语音的特征码,其中,标准基语音的特征码的提取与建立方言语音特征码库时特征码的提取方法相同。
方言语音的特征补偿码与特征码复合,复合后再与标准基语音的特征码经过n次校验纠正,经过对方言语音特征补偿码的n次校验纠正后复合得出标准基语音特征码在允许误差范围内,该特征补偿码即为该方言语音的特征补偿码,将该特征补偿码赋予检索号编入特征补偿码库。可用于后期实时的方言或个性化语境的语言翻译系统。
建立好特征码库和特征补偿码库后,用特征补偿码与其对应的源语音复合产生出对应母语系下的标准基语音;特征补偿码的获取有两种方式:
特征补偿码获得步骤:通过源语音的特征补偿码与特征补偿码库进行相似性检索得到对应的特征补偿码。即在未知语种的情况下,对源语音进行特征码提取,再与标准基语音生成源语音的特征补偿码,源语音的特征补偿码与特征补偿码库进行最大相似性检索得到对应的特征补偿码,得到的特征补偿码再与源语音进行复合产生出对应母语系下的标准基语音。
特征补偿码获取是通过用户手动设置。即适用已知语种的情况下,源语音直接与给定的特征补偿码复合产生出对应母语系下的标准基语音。
标准基语音转换成目标语言的语音或文本,并输出语音或文本。
本发明可根据用户需求翻译指定语种的方言,也可翻译未知语种的方言。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!